들어가며
현재 프로젝트 팀원들은 각자의 할 일을 열심히 하며 별 신경쓰지는 않지만, 현재 배포되어 있는 lambda의 초 회 응답속도가 평균 4~5초가 걸린다.
과연 서비스 중인 사이트의 응답속도가 4~5초 걸리는 경우가 얼마나 있을까.
이는 내가 사용하는 lambda의 고질적인 문제인 cold start이기는 하지만, 4~5초가 소요된다는 것은 너무 어처구니 없는 사실이다.
따라서 오늘은 lambda의 cold start를 해결하기 위해 여러가지 테스트 및 최적화를 수행하고자 한다.
cold start 현상 파악
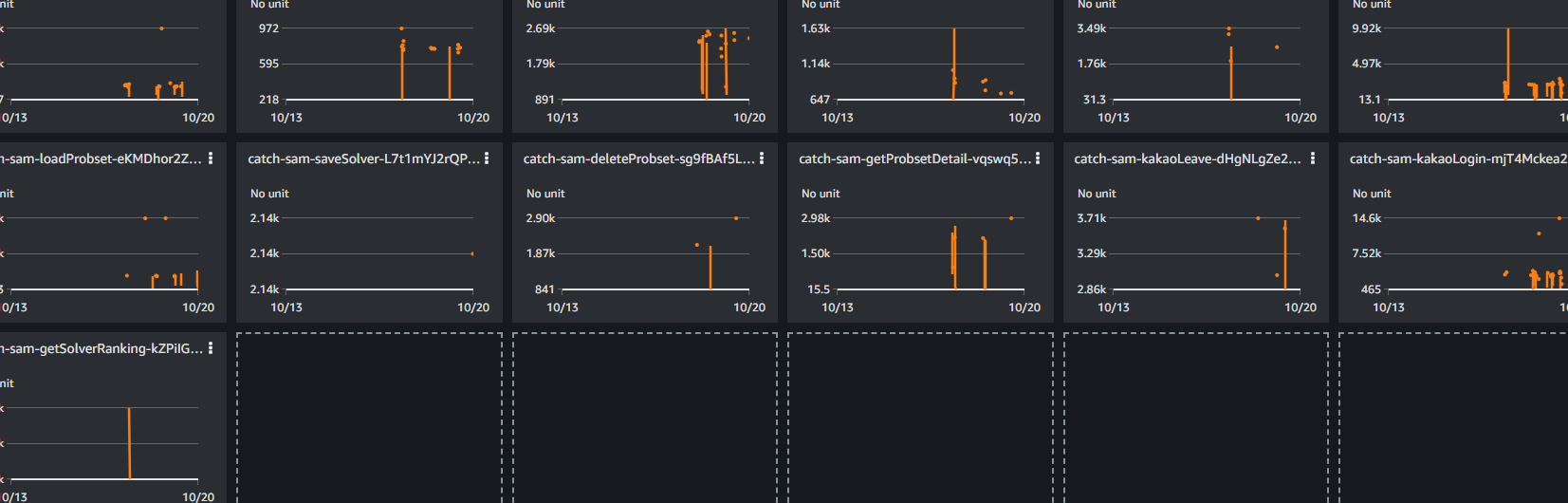 현재 배포되어 있는 lambda의 실행시간(duration)의 최대치를 확인해보았다.
현재 배포되어 있는 lambda의 실행시간(duration)의 최대치를 확인해보았다.
전체적으로 10k, 3k, 9k 등에서 시작해서 떨어지는 양상을 보이는데, 이는 cold start의 첫 invocation이 반영된 응답시간이다. 하지만, 10k 혹은 9k와 같이 너무 비정상적인 요소들은 rds의 초기화 문제이므로, 지금은 해결되어 무시해도 괜찮다.
항목에 따라 문제 해결하기
아래 목록들은 지금까지 lambda 사용법을 검색하며 여기저기서 수집할 수 있었던 내용들을 토대로 하고 있다.
예약된 동시성
가장 단순하게 cold start를 해결할 수 있는 방법이지만, 요금이 꽤나 든다.  공식 문서의 요금 예시에 따르면, 위의 예시와 다른 하나의 예시가 단 하루 내의 동시성 설정 (7개와 100개)임에도 불구하고 대량 $20이상의 요금이 청구된다는 것을 알려준다. 당연하겠지만 우리는 저 정도의 load까지는 상정하고 있지 않기 때문에, 막연하게 예약된 동시성을 사용하여 해결하지는 않도록 한다.
공식 문서의 요금 예시에 따르면, 위의 예시와 다른 하나의 예시가 단 하루 내의 동시성 설정 (7개와 100개)임에도 불구하고 대량 $20이상의 요금이 청구된다는 것을 알려준다. 당연하겠지만 우리는 저 정도의 load까지는 상정하고 있지 않기 때문에, 막연하게 예약된 동시성을 사용하여 해결하지는 않도록 한다.
가령, 20개의 lambda를 각 1개씩 256MB로 설정하여 예약된 동시성을 둔다면, 컴퓨팅 요금만 제외하고도 약 월 $56가 추산된다. 이렇게는 처리할 수 없다.
최대 메모리 설정
lambda 실행 과정
모든 함수에서 사용하는 메모리가 최대 메모리에 근접하거나 이를 넘고자 한다면, 당연하게 응답시간이 늦춰질 수 밖에 없다.
하지만 이를 정확하게 분석하기 위해서는 동작방식을 조금 알고 있어야 한다. 구체적으로 lambda는
- 코드를 다운받아 구성하는 단계
- 코드를 실행시킬 환경을 시작하는 단계
- 패키지 내의 전역 코드를 실행하는 단계
- 핸들러에 포함된 코드를 실행하는 단계
이렇게 4단계를 거치게 된다. 이 중에서 1,2,3 단계를 실행한 다음 4단계를 실행하는 것을 Cold start 라고 일컫고 이렇게 생성된 컨테이너는 AWS 물리 서버 내에 약 5분간 켜져 있게 된다.
lambda를 호출하면 cold start된 생성된 컨테이너가 있는지 확인하고 있다면 4단계만을 실행하게 된다. 이것을 Warm start 라고 하며 비즈니스 로직을 빠르게 수행하게 된다.
분석
캐치캐치 서버에 배포된 lambda들을 분석하고자 한다. 임상적으로 amplify로 배포된 임시 사이트에서 모든 lambda로의 요청은 cold start 기준 4~5초, warm start 기준 400ms 정도가 소요되었다.
lambda optimization을 서칭하다가 발견한 툴을 사용해보았다. aws-lambda-power-tuning 이라는 이름으로 배포된 이 코드는, aws step function으로 배포되어 실행 시 input으로 들어온 lambda arn을 다양한 메모리 옵션으로 invoke시키며 응답 속도와 비용 사이의 최적점을 알려줄 수 있는 기능을 한다. 대략 0~100번의 병렬/직렬 호출을 통해 평균적인 데이터를 만들어 준다.
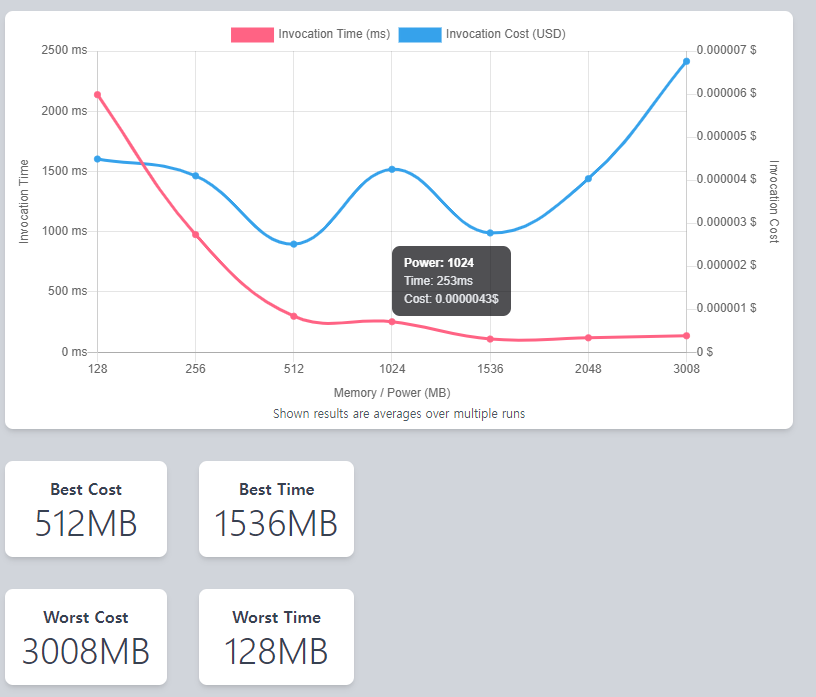
하지만 이 툴을 완벽하게 사용하기는 어려웠다.
왜냐하면, lambda로 실행한 컨테이너를 직접 관리할 수 없었기 때문이다. 물론 코드를 재배포 하는 등으로 기동중인 컨테이너를 모두 중단시킬 수 있겠지만 그렇게한다면 위 툴을 사용하는 이유가 무색하게 메모리를 바꿀 때 마다 실행시켜야 하고, 적어도 모든 함수를 4단계 (128~1024)에 실행하기 위해서는 많은 시간이 소요되기 때문이었다.
그리고 지표로도 memory가 원인이 아님을 알 수 있었다. 위 툴을 사용하고 남은 로그를 보기 위해 cloudwatch의 log insights를 확인했다.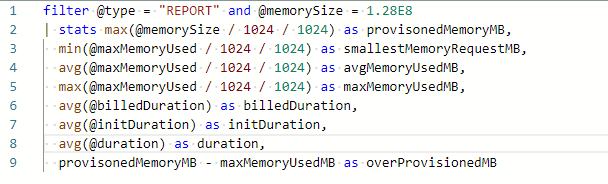 aws-lambda-power-tuning 으로 lambda를 실행하였기에 로그가 쌓여있었다. 이를 따로 분석하고자 위와 같은 필터를 사용하여 확인한 결과
aws-lambda-power-tuning 으로 lambda를 실행하였기에 로그가 쌓여있었다. 이를 따로 분석하고자 위와 같은 필터를 사용하여 확인한 결과




위에서 아래로까지 각각 128MB, 256MB, 512MB, 1024MB의 세팅으로 실험된 결과를 나타낸다. 대략적으로 알 수 있는 사실이 몇 개 보인다.
- initDuration (cold start) 시간은 평균적으로 1초가 소요되었다.
- 최대 메모리 사용량은 122~132의 범위로 나타난다.
- 128MB billed duration 평균이 1997ms인 것에 대비해 256MB는 771ms이다. 비율로만 환산해봐도, 2.59(소요시간비) : 2(메모리 비) 이기 때문에 256MB로 높이는 것은 효율적으로 확인되었다.
- 물론 최적으로 생각한다면 140MB 정도로 옵션을 지정하는 것이 좋다.
가장 중요한 것은, cold start의 시간이 어떤 상황에서든 1초가 소요된다는 것이다. 그러므로 본 챕터에서는 기본적으로 모든 lambda 함수의 memory를 2배로 증량하고 실행시키는 것으로 마무리 짓겠다.
Cold start 줄이기
라인별 소요 시간 측정하기
그렇다면 어떻게 cold start를 줄일 수 있을까. 가장 정확한 방법은, 코드의 전역부터 시간을 측정하여 반환하는 것이다. 이를 배포된 lambda에서 시시각각 코드를 업데이트 해가며 debug를 하면 수월하게 작업할 수 있다. 우선, lambda의 code 섹션에 들어가서 handler가 위치한 부분의 전역에서 시작과 끝을 지정한 다음 로그를 남겼다.
우선, lambda의 code 섹션에 들어가서 handler가 위치한 부분의 전역에서 시작과 끝을 지정한 다음 로그를 남겼다. 정확하게 1초가 소요되는 모습을 확인했고, 각 부분마다 타이머를 설정하여 초기화 로직 중 어느 부분이 가장 시간이 걸리는지 확인해 보도록 하자.
정확하게 1초가 소요되는 모습을 확인했고, 각 부분마다 타이머를 설정하여 초기화 로직 중 어느 부분이 가장 시간이 걸리는지 확인해 보도록 하자.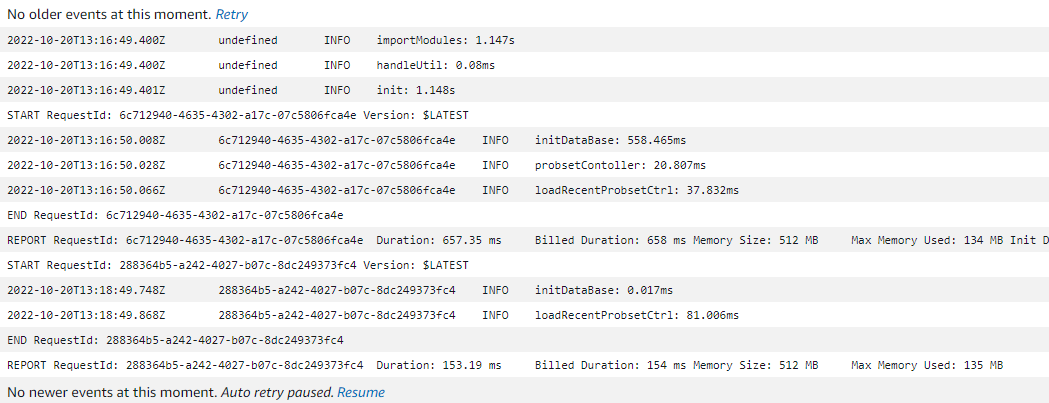 결과에 따르면 모듈을 import 하는데에 1초가 걸리고, 데이터베이스를 초기화 하는데 0.5초가 걸린다고 한다. 조금 의심스러워 더 자세히 로그를 남겨보았다.
결과에 따르면 모듈을 import 하는데에 1초가 걸리고, 데이터베이스를 초기화 하는데 0.5초가 걸린다고 한다. 조금 의심스러워 더 자세히 로그를 남겨보았다.

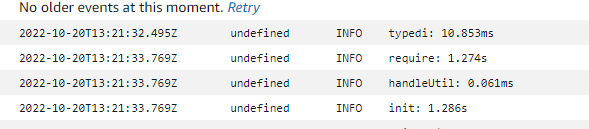 놀랍게도, 내가 작성한 코드에서 1초나 되는 시간이 허비되었다. 초기화 코드에서 시간이 많이 걸려서 세세하게 분석해보았다.
놀랍게도, 내가 작성한 코드에서 1초나 되는 시간이 허비되었다. 초기화 코드에서 시간이 많이 걸려서 세세하게 분석해보았다.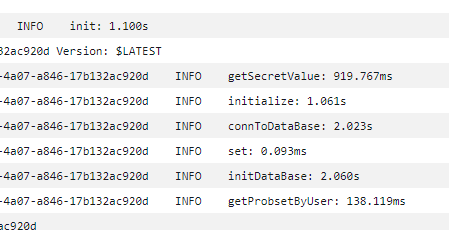 가장 큰 문제 세가지를 확인할 수 있었다.
가장 큰 문제 세가지를 확인할 수 있었다.
- AWS Secret Manager를 사용하기에 인터넷으로부터 값을 가져오는데 1초 정도 시간이 소요된다.
- DB 커넥션을 맺는 데에 1초 정도 시간이 소요된다.
- 위에서 언급했듯이, 구현한 모듈을 파고파면서 로딩하기 때문에 1초 정도 시간이 소요된다.
놀라운 것은, 이 3가지 요소들이 추측하건데 평균적이라는 것이다. 즉 모든 cold start가 3초가 소요되는 말도 안되는 상황이 벌어진 것이다.
해결책
lambda-warmer (거창하지만 스케쥴러 콜)
둘의 문제점을 해결할 수 있는 수단은 막연하게 떠오르거나, 쉽게 찾을 수 있었다. 각각
- AWS Secret Manager 대신 env를 사용한 변수 세팅
- DynamoDB로 이전 (하지만, typeorm을 지원하는지는 미지수), redis로 connection 캐싱
이었지만, 구현한 모듈이 1초가 걸리는 상황은 정말 해결할 방법이 떠오르지 않았다.
그도 그럴것이 (지금 생각해보면) 서버리스를 도입하고자 했던 놈이 연결성이 짙은 RDS와 TYPEDI, TYPEORM 같은 것들을 무책임하게 골라오지 않았던가. 사실 서버리스에 대한 깊은 사례를 찾지 못한 나의 불찰이라고 생각한다.
미리 알았더라면, serverless를 정말 serverless하게 사용하던가, (각 handler 별로 폴더를 따로 한 후 모듈을 모두 세분화 하고 연결성을 모두 끊어버리기) k8s를 도입하여 ec2 인스턴스를 관리하도록 했을 것 같다.
탓은 이쯤이면 되었다. 문제를 해결하기 위해서 검색을 이리저리 해보았지만, 옛날에 봤던 스케쥴링으로 호출하기라는 무식한 방법 따위만이 검색결과로 떴을 뿐이었다.
하지만 그 중에서도 꽤나 그럴싸한 라이브러리를 발견했는데, 이것이 lambda-warmer이다.
라이브러리의 구성은 정말정말 간단했다. sam template 혹은 cloudformation으로 스택을 만들 때 스케쥴러를 구성하는 것은 똑같지만
코드 상에서 event에 심어진 변수를 통해 warmer call 이라는 것을 판단하는 .. 라이브러리도 아닌 그냥 구현된 코드였다.
하지만 그럴싸하다고 생각했던 것은, 다른 사람들은 일방적으로 invoke 하는 것만 알려주고 그 뒷처리를 말하진 않았기 때문이었다. (혹은 내가 못 봤을 것이다.) 아무튼, 코드를 다음과 같이 수정하여 문제를 해결할 수 있었다.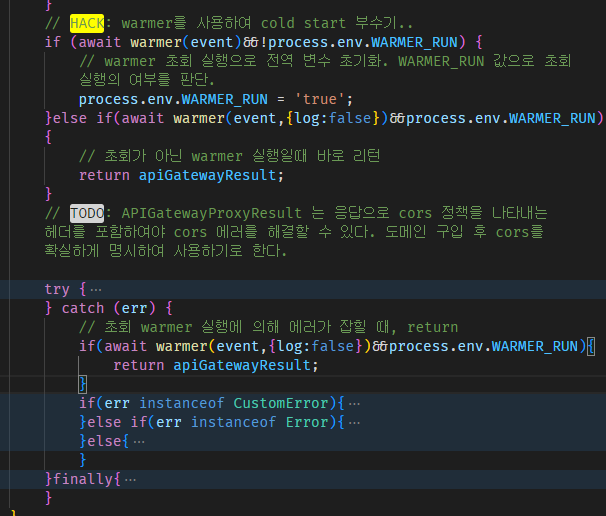
조금 지저분해졌지만, 핸들러를 감싸는 warpper라는 최상위 함수에서 아래 로직을 수행하여 warmer call을 잡기로 한다.
환경변수로 warmer run을 사용하여 핸들러를 실행했을 때 발생하는 에러처리도 함께할 수 있도록 구현을 해두었다.
warmer call이지만 handler를 실행하는 이유는, 초회 호출일 때 함수가 초기화되지 않는 문제를 해결하기 위함이다. 초회 호출임에도 불구하고 핸들러에 접근하지 않은 채 return을 수행해버리면 DB등의 전역값들이 연결되지 않기 때문이다. 핸들러를 호출하고 당연시 발생될 에러를 다시한번 필터링해서 잡아주는 코드를 포함시켰다.
아, 가장 상단의 log는 false로 두는 것을 추천한다.
요금은?
중요한 것은, 모든 함수를 유지하기 위해 실행을 하며 실행 단위로 과금이 발생하는 lambda의 경우 예상 치를 상정해야 한다는 것이다.
현재 프로젝트 시점으로, 동시성을 3개로 유지한다고 생각했을 때 월 단위의 과금은 다음과 같다.
- warmer call 평균 실행 시간 : 1,000ms 가정
- lambda 평균 memorySize : 256MB (실제론 160MB이지만, 최대치 상정 및 계산용이 위해)
- 1달(초) : 24시간 * 3,600초 * 31일 = 2,674,800초
- 1달 간 유지되는 lambda 동시성 수 : 등록 lambda 함수 20개 * 함수당 3개의 동시성 = 60개
- 5분 간격의 invoke 시 하나의 lambda 한 달 호출 수 : 2,674,800 / 300 = 8,928회
- 한 달 간 함수 총 호출 수 : 60 * 8,928 = 535,680회
- 총 컴퓨팅(GB-s) : 545,680 * 256 / 1024(MB) = 133,920(GB-s)
- 컴퓨팅 요금 : 133,920 * 0.0000166667 USD(처음 6십억GB-초/월) = $2.236464
- 호출 요금 : 535,680회 / 1백만 * $0.2 = $0.1 (1백만 건당 $0.2)
동시성을 유지하기 위해서만 실행하는 것은 정말 얼마 들지 않는 것으로 보인다. 실제로도 1000ms 의 실행 시간도 거의 평균적으론 200ms에서 그치는 것으로 확인되었다.
물론 이 밖에도 EventBridge, CloudWatch 쪽에서 주장하는 금액이 있을테지만 직접적인 lambda 보다는 작을 것이기 때문에 지속적으로 billing을 확인하는 것으로 마무리하도록 한다. 과정을 완료 한 다음, 사이트에서 확인해 보니 첫 요청이지만 1초 내외의 반응성을 보여주고 있다 .. ㅎㅎ
과정을 완료 한 다음, 사이트에서 확인해 보니 첫 요청이지만 1초 내외의 반응성을 보여주고 있다 .. ㅎㅎ
결론
하지만 위 방법은 동시성이 3개로 고정되어 있다는 것을 잘 염두해두어야 한다. 동시성이 3개일 때 요청이 오래걸릴 수 있는 조건은 두 경우이다.
- 4명 이상의 사람들이 거의 worst case 기준 1초 안에 같은 요청을 할 때
- best case 기준 (대략 50ms)을 동시성 3개가 감당하지 못할 때. (대략 1초당 30명의 요청)
상황을 방지하기 위해서는, 동시성의 개수와 invocation 그리고 duration 지표를 적절히 조합한 새로운 수치를 대시보드에 그려야 할 것 같다.
(avg(duration) * sum(invocation)) / (time(ms) * 3(currency)) 정도면 괜찮을 것 같다.
