ORM 최적화
블로그 글 추가 및 수정 필요
QuerySet API
LazyLoading, Caching, EagerLoading(Resolve N+1 Problem)
QuerySet의 구조와 동작 원리
select_related(), prefetch_related() 차이점
settings.py 파일에
LOGGING 설정
어떤 요청을 받았을 때, 실행되는 핸들러 메소드(GET) 가 있다면
통신한 SQL문을 로그로 찍어줌
장고 공식 문서에 logging 검색후 문서 참고해서 나만의 로그 설정 가능
decorators.py
시작부터 끝까지 몇초까지 걸렸는지
models
publisher book 1:M
book Store M:M
각각 정보를 호출할 때 성능을 테스트
N+1 레스트풀 하게 하였는가?, ㅁㄴㅁㅇㅁㄴㅇ?
한번 호출 했는데 N번의 서브 쿼리가 계속 호출되는~?
(역참조, 정참조에서 발생하는 문제)
해결법
1. select_related 함수를 사용
2. prefetch_related
데이터베이스에 여러번 조건을 바뀌면서 요청을 보내서
데이터베이스에 요청이 많아지는
LazyLoading
queryset -all() - 실제로 데이터 베이스에 호출을 하지 않는다.
실제로 all() 함수를 사용하면 어떤일이 발생 하는가?
내부적으로 쿼리셋이라는 자료형을 반환
자료형 안에 보면 query라는 속성이 있다.
query라는 속성 안에 SQL문을 저장한다.
django github 소스를 보면..?
query라는 속성 안에 SQL문을 저장한다.
어떤 값을 보내는지 print문으로 확인하면
SQL 문이 저장되어 있다.
exclude 조건과 annotate 조건을 queryset.query에 저장되어 있다.
그러면 진짜로 DB에 요청은 언제 보내는가?
Queryset Evaluation 쿼리셋이 평가 되었을 때 - 쿼리셋을 slicing 했을때 Iteration, repr(), len(), list(), bool() ...
len - 쿼리의 길이를 재다
bool - 쿼리셋을 이프문에 넣고 값이 비여있는지..?
list - 리스트를 슬라이싱 했을 떄
Iteration - 반복문 돌렸을 떄
똑같은 요청을 보내면 ex queryset2[0] 3번? 3번 count 됨
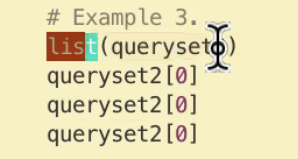
장고에서 내부적으로 구현된 캐싱 떄문에 1번 호출
호출했던 결과를 어디에 저장하고 그다음 부터 쿼리셋에 정의되어있는 0번쨰를 꺼내온다.
캐싱 기능
데이터베이스에 요청하고 가져온 결과 값을 _result_cache에 저장하게 됨
장고 소스를 보면 디폴트로 None 으로 저장되어 있음
모든 경우를 다 result_cache에 저장 하지 않는다.
어떤 경우는 언제냐?
특정 경우 for문 돌린 후에, 리스트, 등등..
사용자에게 쓰레드 할당
쓰레드에게 요청의 시작과 끝나는 시점까지 캐시를 가지고 있다.
하나의 쓰레드 안에서 가지고 있는 기능
데이터베이스의 변경 사항이 있다고 해서 저장되어 있는 캐시 기능을 바로 지우지 않는다.
디비가 변경되었다면 사용자가 다시 요청을 해야 한다.
싱데이터는 쓰레드의 로컬메모리에 저장이 된다고 생각
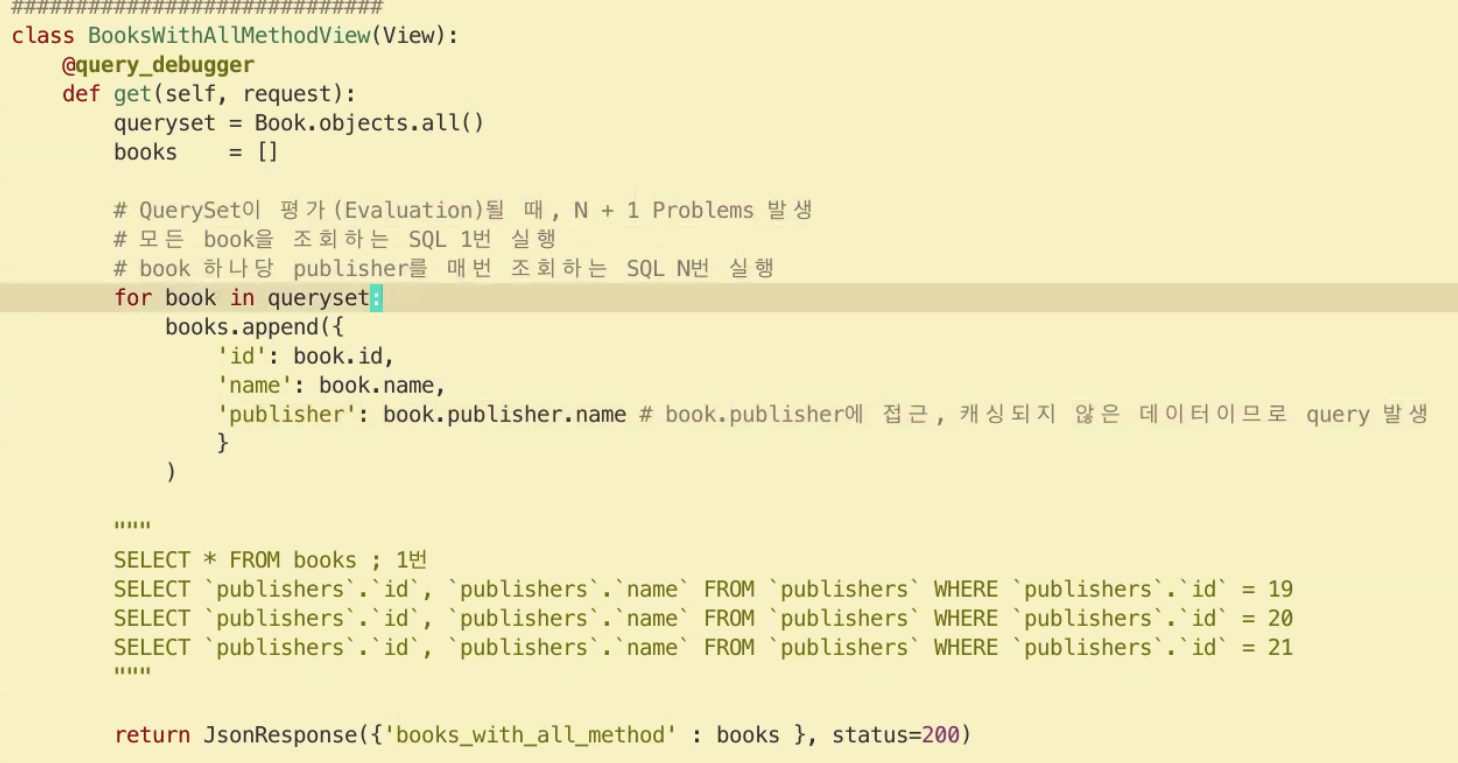
루트 쿼리 1
그 이후로 추가 코드로 n번을 요청
그래서 N+1
publisher에 매번 요청 했기 떄문에
select_related('publisher') 에 넣음
all()함수 쿼리문에 publisher를 한번에 가져오는 조인 쿼리로 가져와서 문제를 해결
books 정보 참조하는 publishers만
쿼리에 계속 셀렉트 문에 inner join 문이 합쳐져서 하나의 쿼리로
테이블 조인해서 가져 온다?
book.publisher.name 정참조
queryset = Sore.objects.all() 역참조
문제점 store 정보를 다 가져와서 추가 쿼리
prefetch 추가로 쿼리를 구현한다.
prefetch_related_lookups
prefetch_realated 사용할 정보 저장
2개의 요청
루트쿼리 1개
쿼리한에 있던 스토어 정보를 가져오고
스토어 정보 안에서 store id를 뽑아오고
prefetch_related_lookups 에서 book정보를 가져오는 추가 쿼리 작성
그 이후에는 result_cache 를 이용
만약 면접에서 seleted , prefetch
셀렉트 는 테이블 한번에 조인해서 가져오는 queryset.query속성에 sql이 합쳐진다. selectreated 가 실행되어 발생

루트쿼리는 루트쿼리로 날리고 ~~.all()
그 이후 prefetch_related 사용하게 되면 추가 쿼리 발생 (books, tags)
그럼 총 3번의 쿼리를 날리게 됨
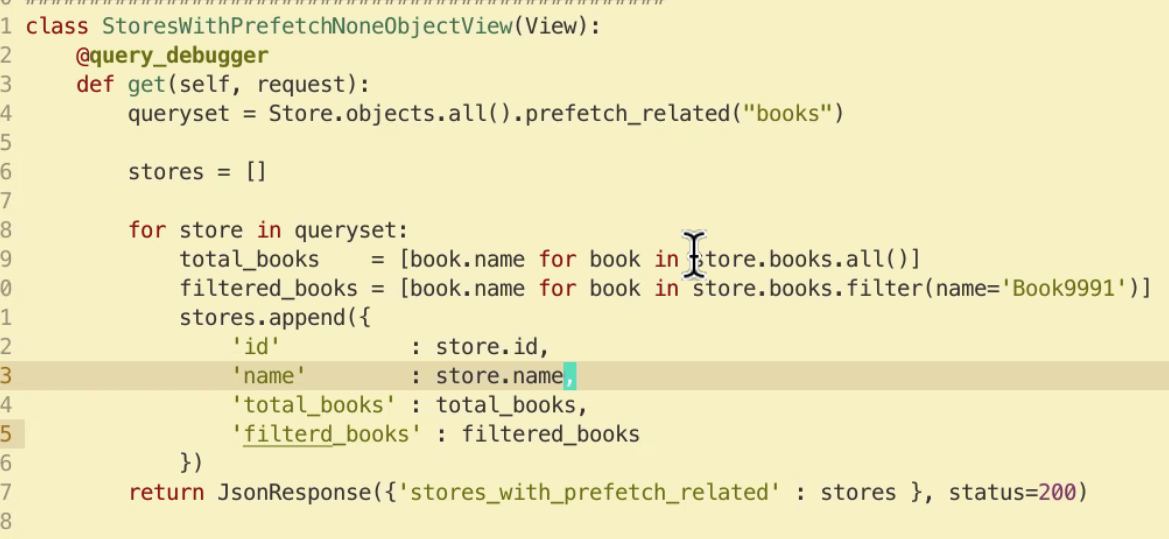
prefetch 사용해도 문제가 발생하는 부분?
filter만 추가했을 뿐인데 요청이 많아짐
앞에 있는 all()
모든 정보를 가져온 값만 캐싱을 했기 때문에
filter를 호출하는 경우는 기존의 캐싱했던 값들과 조건이 다름
sql문으로 봣을대 where절이 바뀌기 떄문에 그러므로 쿼리를 계속 날리게 됨

prefetch_related () 안에 Prefetch( ) 를 사용 내가 값을 캐싱해놓고 싶은 테이블을 넣어 주고 조건을 줌
total_books , filtered_books 라는 속성이 생김

그 속성을 이용할 수 있다.

두개 다 같은 정보를 가져옴 (똑같다 .
loadtest 툴이 있다.
-n 5 5번 요청
단순히 기능만 개발하는 개발자인지
배포할떄 이슈 발생까지 생각하는 개발자인지
데이터 베이스 부하까지 생각하는 개발자로......
API 호출될때마다 쓰레드가 생성되어 처리된다고하셨는데
파이썬은 GIL에 의해서 여러개의 쓰레드가 하나의 프로세서에서만 사용이 가능하다고 알고있습니다..
그러면 멀티프로세서자원을 활용하려면 어떻게?
파이썬에는 글로벌 락이라는게 있다.
쓰레드가 여러개가 돈다고 하더라고 동시에 처리할 수 없다.
파이썬에서는 어플리케이션을 배포 할떄 멀티 쓰레드 보다는
멀티 프로세싱을 이용하여 배포 해야한다.
nodejs는 싱글
