LoRA를 통한 CLIP 모델 PEFT
PEFT LoRA를 사용하는 법과 라이브러리 없이 custom으로 만든 lora.py에 대한 글을 작성하였다. peft 라이브러리만 필요한 경우라면 중간까지만 읽어도 무방하다. 직접 만든 이유는 원래 peft를 잘 사용하고 있었는데, peft lora 라이브러리가 호환이 안되어, 현재 서버(캐글서버)에서 깔려있는 라이브러리와 호환이 되지않았다. 버전을 맞춰줘도 좋지만 이참에 모델 구조를 하나하나 조금더 이해하고 구현해보자는 생각에 직접 lora코드를 짜보기로 생각했다.
PEFT LoRA를 이용하는 법은 다음과 같다.
LoraConfig
from peft import LoraConfig config = LoraConfig( r=8, lora_alpha=16, target_modules=["q", "v"], lora_dropout=0.01, bias="none" task_type="SEQ_2_SEQ_LM", )
peft를 install 후, 위와 같이 LoraConfig arguments를 설정한다.
LoRA Dimension r
= low-rank decomposition
, (단,r << min(d,k))A는 랜덤 가우시안이나, kaiming_HE initializer를 통해서 초기화 되고,
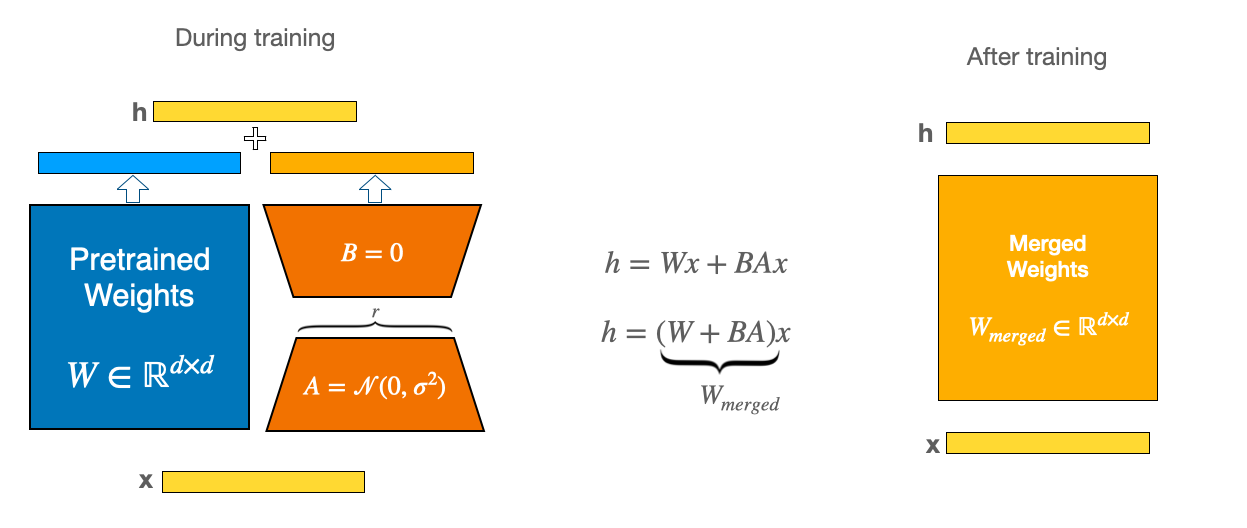
B는 0으로 초기화 된다. 따라서 학습되기전에는 원래 모델과 동일한 인퍼런스 결과를 내놓게 된다.
(default r = 8)
Alpha Parameter for LoRA Scaling
∆W is scaled by α / r where α
r이 커질수록 number of parameters가 linear하게 커지므로, 의 스케일 값을 일정하게 유지하기 위해 α 값을 추가하였다.
(default α = 8)
Modules to Apply LoRA to target_modules
loralib은 nn.Linear, nn.Embedding, nn.Conv2d만 지원한다.
import re pattern = r'\((\w+)\): Linear' linear_layers = re.findall(pattern, str(model.modules)) target_modules = list(set(linear_layers))
Dropout Probability for LoRA Layers
(default lora_dropout = 0)
type : 'none','all' or 'lora_only'
Bias Type for Lora bias
Task Type task_type
CAUSAL_LM, FEATURE_EXTRACTION, QUESTION_ANS, SEQ_2_SEQ_LM, SEQ_CLS, TOKEN_CLS.
Other Arguments
fan_in_fan_out, modules_to_save, layers_to_transform and layers_pattern are less frequently used.
LoRA 구현
먼저 내가 LoRA를 적용하고 싶은 모델들을 탐색했다.
CLIP,GPT2,Mistral 7B, stable-diffusion, multilingual-encoder,bert 등등..
먼저 로라를 소개하자만 아래와 같다.
LoRA에 관한 발표 피피티
LoRA paper : https://arxiv.org/abs/2106.09685
LoRA official code : https://github.com/microsoft/LoRA
목표
모델 탐색
SentenceTransformer의 다국어 버전, CLIP, GPT-2, BERT 등 다양한 모델에 LoRA 적용성능 관측
YouTube 이미지 텍스트 pair 데이터를 사용하여, LoRA 적용 모델의 성능 변화 관찰최적화
LoRA의 'rank' 값에 따른 성능 최적화 탐색
LoRA 구현 과정
모델구조를 확인하고 일단 논문에 나온대로 attention layer에만 LoRA를 적용하기로 생각했다. gpt와 오피셜 깃허브의 힘을 받아서 만들어보았다. 새벽에 시작해서 학습 완료되는 코드까지 12시간 넘게 걸린것 같다. 그것도 gpt와 오피셜 깃허브의 힘을 받았다. 그러던 와중에 친구가 서버를 빌려줘서 쾌적하게 실험을 할 수 있었다.
LoRA code 구현
## lora.py
class LoRA_Config:
def __init__(self, r, lora_alpha, lora_dropout, merge_weights, target_modules):
self.r = r
self.lora_alpha = lora_alpha
self.lora_dropout = lora_dropout
self.merge_weights = merge_weights
self.target_modules = target_modulesLoRA 적용을 위해 필요한 설정값을 포함하는 LoRA_Config 클래스를 정의했다.
## lora.py
class LoRALayer(nn.Module):
def __init__(self, original_layer, config: LoRA_Config):
super(LoRALayer, self).__init__()
self.original_layer = original_layer
input_dim = original_layer.weight.size(1)
output_dim = original_layer.weight.size(0)
# Initialize and then apply kaiming_uniform_
lora_A_tensor = torch.empty(input_dim, config.r)
torch.nn.init.kaiming_uniform_(lora_A_tensor)
self.lora_A = nn.Parameter(lora_A_tensor)
self.lora_B = nn.Parameter(torch.zeros(config.r, output_dim))
self.scaling = config.lora_alpha/config.r
if config.lora_dropout > 0:
self.dropout = nn.Dropout(p=config.lora_dropout)
else:
self.dropout = lambda x: x # No-op
def forward(self, x):
# Apply dropout before the matrix multiplication
A_dropout = self.dropout(self.lora_A)
B_dropout = self.dropout(self.lora_B)
W_prime = self.original_layer.weight + self.scaling*A_dropout @ B_dropout
return F.linear(x, W_prime, self.original_layer.bias)
# 실패한 코드이다.
# def forward(self,x):
# delta_W = self.dropout(self.lora_B(self.lora_A(x)))
# W = self.original_layer(x)
# return self.scaling*delta_W + W
# 에러뜬 이유
# self.lora_A와 self.lora_B는 nn.Parameter 객체로 정의되어 있으며,
# 이들은 직접적으로 호출 가능한 객체가 아닙니다. 대신 이 파라미터들을 행렬곱 (matrix multiplication) 연산에 사용해야 합니다. PyTorch에서는 torch.matmul 함수 또는 @ 연산자를 사용하여 행렬곱을 수행할 수 있습니다. 처음 init에서 잘 설정해야됨
def __repr__(self):
return f'{self.__class__.__name__}(\n (original_layer): {self.original_layer},\n (lora_A): Parameter of size {self.lora_A.size()},\n (lora_B): Parameter of size {self.lora_B.size()}\n)'
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
#for param in model.parameters():
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad: # True이면 learnable parameter에 추가
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable: {100 * trainable_params / all_param:.2f} %"
)
return trainable_params, all_param코드해설
기본 LoRALayer를 만들때 nn.Module을 상속받게하면 학습되고 합쳐지는데 문제없을거라고 판단했다.
각 LoRALayer는 기존 layer값과 config값을 받는다.
그후에는 lora_a,lora_b를 만들고 초기화 시킨다. 공식깃허브대로함.
그리고 dropout은 작동할수도 안할수도있어서 0이상인 경우에만 작동하고 아니면 lambda x :x로 지나가게 만들었다. 이건 공식 깃허브 보고 알았다.
그다음에 weight값을 scaling을 해주고 기존 가중치 값과 합친다음에 F.linear(x,W,bias)이렇게 만들었다. 이 구조는 직접적인 선형변환을 적용하기 위해서 추가한것이다. lowrank를 넣어주기위해 새로운 w를 구하고 그걸 다시 모델이 nn.linear로 인식해서 통과하도록 만들었다.
그리고 model에 표시되게 repr을 만들어주었다.
모든 atten 레이어에 적용하는 코드는 다음과 같다.
# 추가로 레이러 마다 적용해하는 함수
def apply_lora_to_model(model, config):
for name, module in model.named_modules():
hierarchy = name.split('.')
if len(hierarchy) > 1: # Ensure the module is not the top-level module
parent_module = model
for submodule_name in hierarchy[:-1]: # Navigate to the parent module
parent_module = getattr(parent_module, submodule_name)
layer_name = hierarchy[-1]
for target_module in config.target_modules:
if target_module in layer_name:
original_layer = getattr(parent_module, layer_name)
if isinstance(original_layer, nn.Linear):
setattr(parent_module, layer_name, LoRALayer(original_layer, config))
print(f"Replaced {name} with LoRALayer")
return model
# Apply LoRA modifications to the model
model = apply_lora_to_model(model, lora_config)
# 추가로 로라 레이어만 활성화시키는 함수
def mark_only_lora_as_trainable(model: nn.Module, bias: str = 'none') -> None:
for n, p in model.named_parameters():
if 'lora_' not in n:
p.requires_grad = False
if bias == 'none':
return
elif bias == 'all':
for n, p in model.named_parameters():
if 'bias' in n:
p.requires_grad = True
elif bias == 'lora_only':
for m in model.modules():
if isinstance(m, LoRALayer) and \
hasattr(m, 'bias') and \
m.bias is not None:
m.bias.requires_grad = True
else:
raise NotImplementedError
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
#for param in model.parameters():
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad: # True이면 learnable parameter에 추가
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
)
return trainable_params, all_param위 처럼 모델 레이어를 탐색하면서 설정해놓은 low rank를 적용할 레이어에만 새로 추가 시키고, 그 레이어만 requires_grad를 True로 만든다.
최종 코드
# from peft import get_peft_model#, LoraConfig, TaskType
from transformers import CLIPModel,AutoProcessor, AutoTokenizer
from lora import LoRA_Config,LoRALayer
model_name ="openai/clip-vit-base-patch32"
tokenizer = AutoTokenizer.from_pretrained(model_name)
preprocessor = AutoProcessor.from_pretrained(model_name)
model = CLIPModel.from_pretrained(
model_name,
# load_in_8bit=True,
# device_map='auto',
)
# Check the original number of parameters
origin_num = sum(p.numel() for p in model.parameters())
print("Original number of parameters:", origin_num)
# Configuration for LoRA
lora_config = LoRA_Config(
r=16,
lora_alpha=64,
lora_dropout=0.03,
merge_weights=False,
target_modules=["q_proj", "v_proj", "k_proj", "out_proj"],
)
# Apply LoRA to the model
model = apply_lora_to_model(model, lora_config)
mark_only_lora_as_trainable(model,bias='lora_only')
_,basic_model_params_num = print_trainable_parameters(model)
### output이 아래처럼 나오면 성공!
trainable params: 1328640 || all params: 157005953 || trainable: 1.42 %wandb 실험 모습
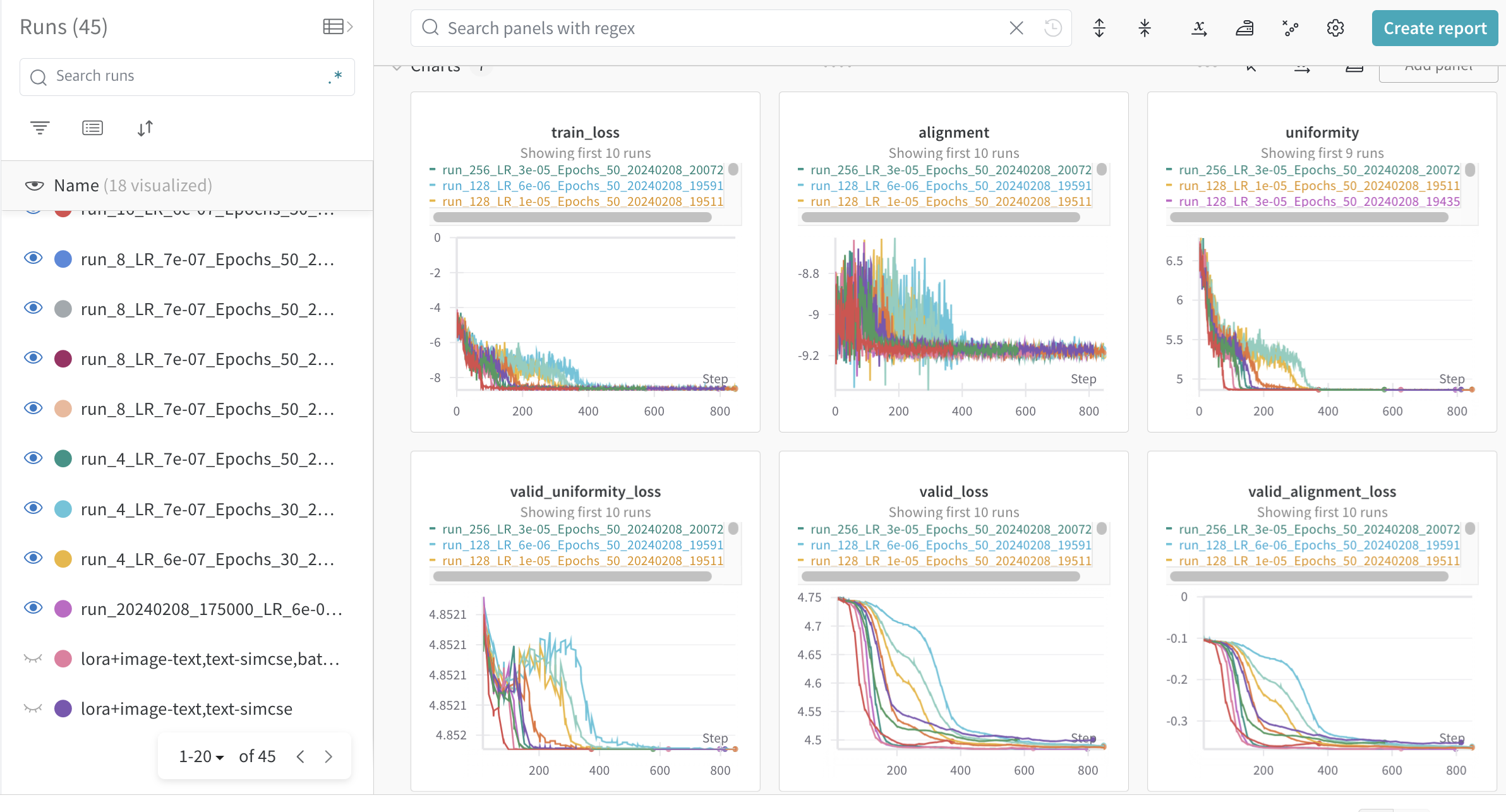
논문 실험 결과(gpt,RoBERTa)
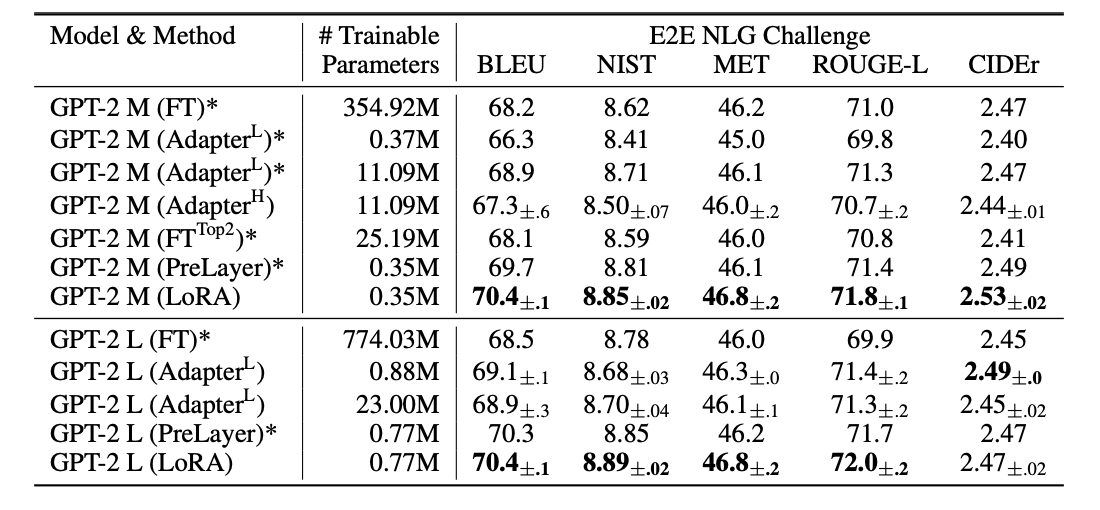
다른 peft방법과 비교한 결과 LoRA의 성능
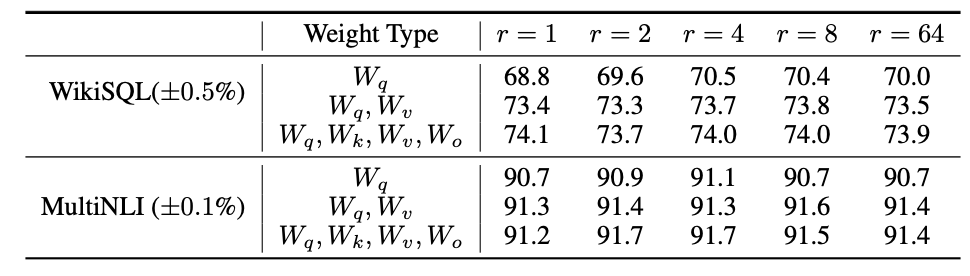
gpt2를 사용하였을때 두개의 벤치마크에대한 성능. rank가 1~4가 적당해 보인다.
위 표를 따라서 당연하게 query,key,value,output weight에 대해서 LoRA를 구성하였고, 기본모델은 CLIP이라 image encoder, text encoder 두개로 구성되어 기존 언어모델과는 다르게 interinstic dimension이 상대적으로 더 클것이라고 판단해서 rank를 더 크게 설정하였다.
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning 논문 링크
rank 실험 결과
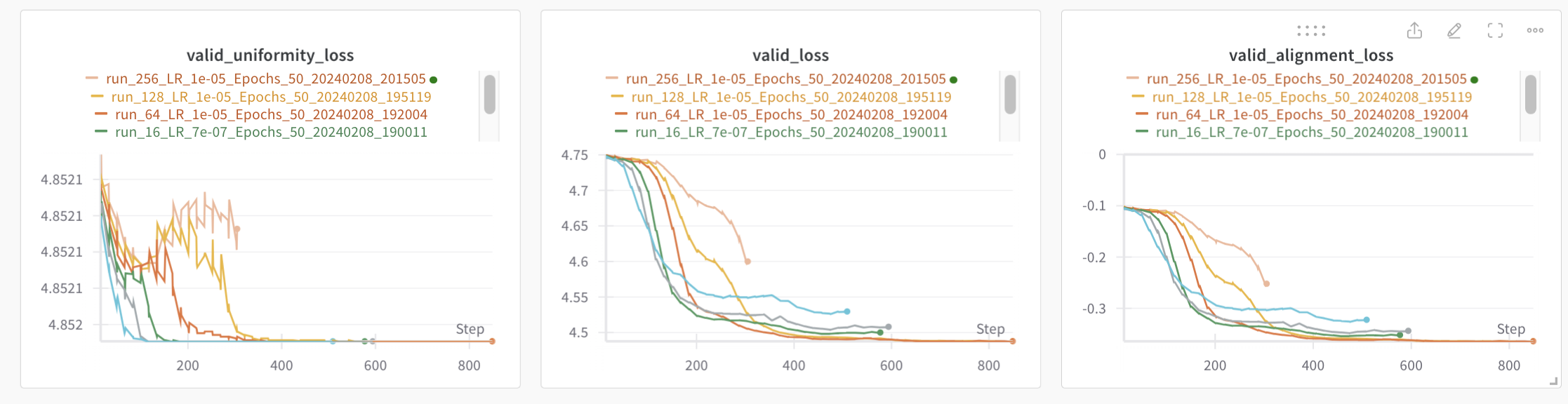
rank를 4부터 2배씩 늘려 256까지 실험해보았다.
rank가 64일때부터 uniformity가 적절하게 학습이 안되는 경향이 보였고, rank가 커질수록 그 정도가 심해졌다.
결론
재까지 2000여개의 이미지와 텍스트 파일인
youtube thumbnail의 데이터로만 관측한 결과
rank값이 많아질수록 더 높은 성능을 보이고 있지만,어느순간부터 더 늘려도 안되는 순간이 오지않을까?라고 생각했었는데 rank 64쯤부터라고 판단된다.
기존 attention layer는 벡터를 쿼리 키 벨류로 각각 isomorphic하게 선형변환을 시킨다고 생각이든다. 그런데 lora는 projection시켜서 주요한 차원으로 압축시키고, 그걸 다시 원래의 차원으로 확장시킨다. 여기서 요지는 주요한 차원축을 통해 적절하게 학습시키면 새로운 데이터에 대해 파인튜닝 가능하다는것이다.
Reference
PEFT: https://pypi.org/project/peft/
LoRA: https://arxiv.org/abs/2106.09685
Microsoft LoRA: https://github.com/microsoft/LoRA/blob/main/README.md
LoRA config: https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora/config.py
https://medium.com/@manyi.yim/more-about-loraconfig-from-peft-581cf54643db