youtube mutimodal retrieval 모델을 만들기 위해서 CLIP 모델을 LoRA와 SimCSE,SimCLR 등을 읽고 적용해서 유튜브 데이터셋으로 파인튜닝한 과정을 코드와 설명을 올립입니다.
데모버전을 streamlit으로 배포하였으니 한번 아래 버튼을 눌러 체험해보세요!
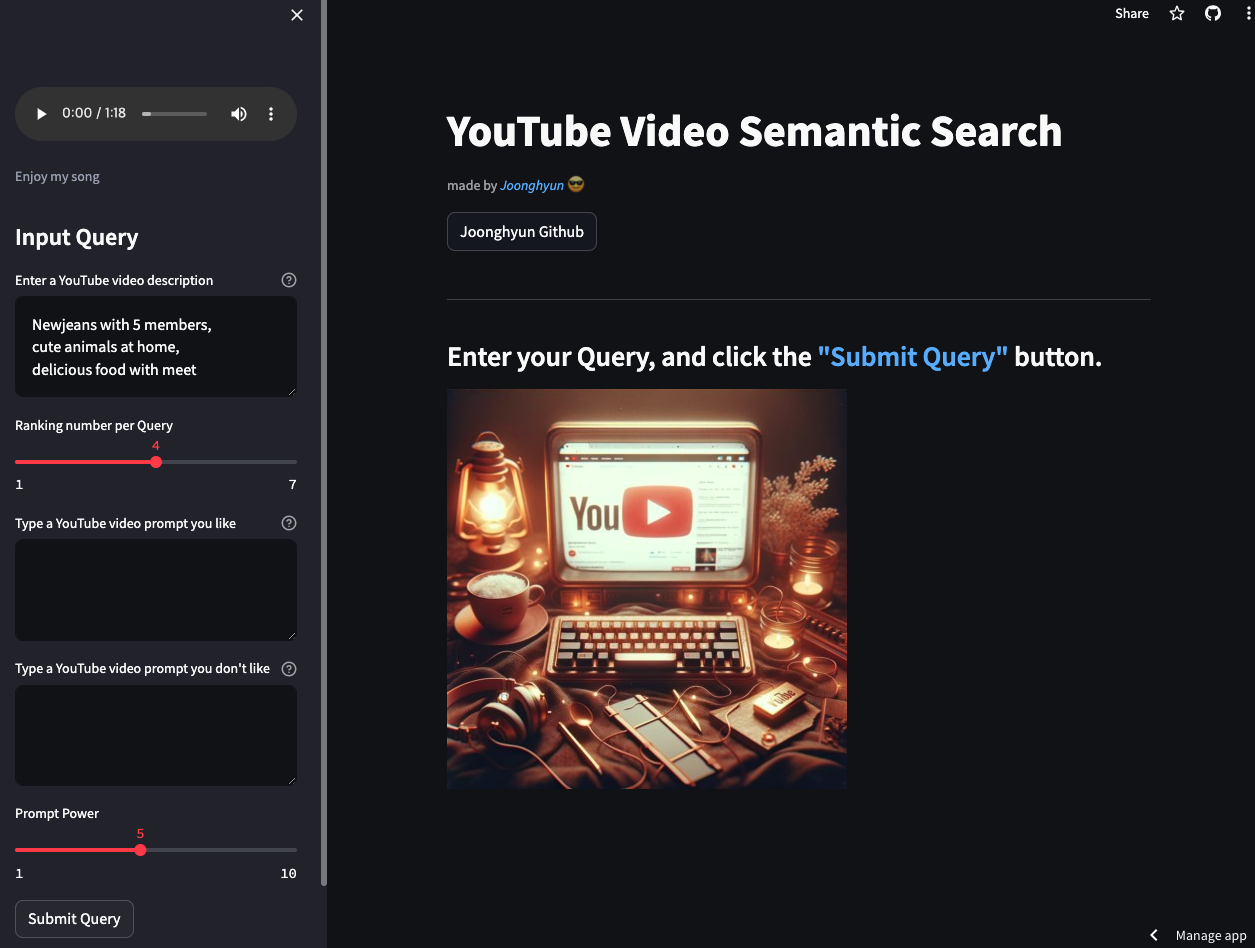
DEMO 클릭
huggingface space에 모델을 올려놓았습니다.
Huggingface space 클릭
먼저 contrastive learning을 위해서 하나의 데이터셋을 augmentation시켜서 그와 유사한 데이터셋을 만들었습니다. SimCLR, SimCSE를 읽고, 그 실험 결과들을 근거로 아래와 같이 코드를 작성하였습니다.
Dataset
import matplotlib.pyplot as plt
import pandas as pd
from torchvision import datasets
from torchvision import transforms
from torch.utils.data.sampler import SubsetRandomSampler
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader
import os
import json
from PIL import Image
from tqdm import tqdm
import clip
import requests
from transformers import CLIPProcessor, CLIPModel,AutoProcessor, AutoTokenizer
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch32")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class image_title_dataset(Dataset):
def __init__(self, list_image_path,list_txt,transforms):
# Initialize image paths and corresponding title
self.image_path = list_image_path
# Tokenize text using CLIP's tokenizera
self.title = tokenizer(text=list_txt, padding=True, return_tensors="pt")
self.transform = transforms
def __len__(self): #split 할때 여기가 중요함.
return len(self.image_path)
def __getitem__(self, idx):
# tokenize text token make as (batch_size,77)
total_length = self.title['input_ids'].shape[0]
rest_token_num = 77-self.title['input_ids'].shape[1]
dummy = torch.ones(total_length,rest_token_num)*49407
text_token_tensor = torch.concat((self.title['input_ids'],dummy),dim=1)
text_token_tensor = text_token_tensor.type(torch.int32)
# Preprocess image using CLIP's preprocessing function
image = Image.open(self.image_path[idx])
image = processor(images=image, return_tensors="pt")['pixel_values']
image = torch.tensor(image)
if self.transform != None:
image = self.transform(image).squeeze() # torch.tensor([3,224,224])
title = text_token_tensor[idx] #.unsqueeze(dim=0) # torch.tensor([77])
return image,title
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
)
# define transforms
CJ_value = 0.2 # colorGitter 값 정의
train_transform = transforms.Compose([transforms.Resize((256,256)),
transforms.RandomCrop(224),
transforms.ColorJitter(brightness=CJ_value, contrast=CJ_value, saturation=CJ_value, hue=CJ_value),
# transforms.ToTensor(),
normalize])
# train_transform = None
youtube_dataset = image_title_dataset(img_list,text_list,train_transform)
# 이미지는 transforms# 이걸 다르게 가져가보자.
# 텍스트는 category 값을 추가한 new_list를 가져가자.
youtube_dataset2 = image_title_dataset(img_list,new_list,train_transform)
plt.figure(figsize=(16, 16))
num=1477
for i in range(4):
a,b = youtube_dataset[num+i]
a = a.numpy().transpose(1,2,0)
plt.subplot(4, 2, 2*i + 1)
plt.title(text_list[num+i])
plt.imshow(a)
plt.axis("off")
a,b= youtube_dataset2[num+i]
a = a.numpy().transpose(1,2,0)
plt.subplot(4, 2, 2*i + 2)
plt.title(new_list[num+i])
plt.imshow(a)
plt.axis("off")SimCLR에서 color jiter를 통해서 image끼리의 positive pair를 만들어주었습니다.

train valid split
from sklearn.model_selection import train_test_split
# Split the train dataset into train and validation sets
train_dataset, valid_dataset = train_test_split(youtube_dataset, test_size=0.2, random_state=42)
print(len(train_dataset),len(valid_dataset))
train_dataset2, valid_dataset2 = train_test_split(youtube_dataset2, test_size=0.2, random_state=42)
print(len(train_dataset2),len(valid_dataset2))domain shift 문제가 나타날 수도 있는데, 왜냐하면 test set은 youtube의 large open domain set이기 때문에, target domain을 알 수 없어,few shot 성능을 높이는 loss function을 사용하였습니다.
DataLoader
# dataloader settings
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=SHUFFLE,num_workers=0, collate_fn=None, pin_memory=True,drop_last=True)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=SHUFFLE,num_workers=0, collate_fn=None, pin_memory=True,drop_last=True)
train_dataloader2 = DataLoader(train_dataset2, batch_size=batch_size, shuffle=SHUFFLE,num_workers=0, collate_fn=None, pin_memory=True,drop_last=True)
valid_dataloader2 = DataLoader(valid_dataset2, batch_size=batch_size, shuffle=SHUFFLE,num_workers=0, collate_fn=None, pin_memory=True,drop_last=True)Model
CLIP + LoRA(PEFT)
from peft import get_peft_model, LoraConfig, TaskType
from transformers import CLIPProcessor, CLIPModel,AutoProcessor, AutoTokenizer
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
config = LoraConfig(
# task_type=TaskType.FEATURE_EXTRACTION,
# inference_mode=False,
r=4,
lora_alpha=16, # alpha/r 이다. 가중치 조정하는 하이퍼 파라미터라고 생각하면된다.
# 내생각에는 rank가 2처럼 작은경우 조금더 높은값으로 조정하기 위해있는게 아닐까 추측한다.
lora_dropout=0.1,
# transformer의 clip에서는 아래와 같이 이름이 붙여져있다.
target_modules=["q_proj", "v_proj","k_proj","out_proj"],
# PEFT를 적용할 모듈
bias="none", # Bias usage
# 여기를 붙이면 파라미터가 급격하게 늘어나는데 왜그런걸까? : encoder파라미터 저장.
# modules_to_save=["encoder"], #save module list
)
# lora_model = get_peft_model(model, config)
lora_model = get_peft_model(model, config)
_,lora_model_params_num = print_trainable_parameters(lora_model)
print('파라미터 늘어난 비율 : ',lora_model_params_num/basic_model_params_num)
### output
------------------------------------------------------------------------
>>> trainable params: 491520 || all params: 151768833 || trainable%: 0.32
>>> 파라미터 늘어난 비율 : 1.0032491322740509
------------------------------------------------------------------------LoRA를 사용하면 learnable parameter 수가 Fully F.T하는것 보다 효율적으로 학습할 수 있습니다. 다만, intrinsic dimension이 존재한다는 가정 깔려있습니다.
"LoRA: Low-Rank Adaptation of Large Language Models" : 링크
"Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning" : 링크
Objective function
번째 데이터와 개의 batch_size pair 대해서 위와 같이 표현 할 수있다.
는 데이터의 임베딩에 해당하고, 는 각 데이터에 가한 augmentation에 해당한다. 는 하이퍼파라미터 temperature값이다.
여기서 나오는 sim은 similarity의 약자이고, cosine similarity를 사용하였습니다.
Notation
i번째 image embedding : 는 row vector
i번째 text embedding :
(단, 는 1로 normalize)
코드 상에서는 cosine similarity를 사용해서 normalize하였습니다.
Image Text Alignment & Uniform
먼저 위 Object function에서 Uniform식이 아래와 같이 되기 위해서는 convex function라고 가정하고, jensen's inequality를 사용한 결과입니다.
땨라서 가 됩니다.
위 식을 분산과 평균 관점에서 다시 바라보았습니다.
가 한개의 임베딩 값이라고 하고, 이 값들은 각 평균과 분산을 갖는다고 하면, 적절한 임베딩은 어느 한 차원으로 쏠리지 않고 적절하게 분산되어서 표현되는것 입니다.
이것에 대한 솔루션으로는 PCA whitening과 batch normalization이가 생각이 납니다. 무엇을 사용해야할지는 알기 위해 수식을 전개해 보았습니다.
만 생각해보면,
가 되어서 뜻을 해석해보면 임베딩의 평균값을 낮추고, 분산의 곱을 낮추는 식이다. 또한, 위 식은 symmetric matrix이기 때문에 항상 diagonalizable하고, 그 eigen vector는 orthogonal 합니다.
그러한 경우를 eigen decompositoin해서 생각해보자.
라고 할때, 를 라고 생각해보자. 이때 는 에 대한 eigen vector입니다.
이때, 즉, orthogonal하므로,
의 어느 한값이 크다는 것은 데이터가 골고루 퍼져있기보단, 한 방향으로 치우쳐져있는것이다. 따라서 위 eigen value값을 골고루 만드느것이 여기서 나온 Uniform의 목적입니다.
Flatten Embedding
위 목적을 이루기 위해서 어떻게 해야할까요??
만약에 가 normalize 되어있다고 한다면, 의 값은 sum of eigen value이고, constant할것이다. 왜냐하면 diagonal element가 모두 1이기 때문에.
그렇다면 largest eigen value의 값을 줄이고, smallest한 eigen value의 값을 키우면 됩니다.
만약에 , A의 값들이 모두 양수이고, 가 양수라면 sum()를 largest eigen value의 upper bound와 비례한다고 놓을 수 있다. 그래서 위 sum을 줄이는것이, flatten embedding을 하면서 negative pair끼리의 임베딩을 할 수 있습니다.
SimCSE 논문의 아이디어를 인용하였습니다.
https://arxiv.org/abs/2104.08821
Flatten different Embeddings
하지만 나는 그렇게 조건을 줄 수 없기에, 다른 방식을 생각해야 했습니다. 이유, 다른 임베딩끼리의 표현이기 때문에..
그래서 위처럼 negative pair loss와 Uniform를 하나의 식으로 보지않고, 따로 볼 생각입니다.
이제 I와 T에 대해서 생각해 봅시다.
negative pair loss
직관적인 의미를 보자면, 이미지와 텍스트의 평균 값을 줄이고, 각 이미지와 텍스트 임베딩의 서로 다른 분산 임베딩을 줄이는 것입니다. 먼저 이걸로, negative pair끼리의 dot product값을 줄여, cosine similarity를 줄일 수 있습니다.
Objective function code
from abc import ABC
from abc import abstractmethod
# static method
class MyLoss(ABC):
# def __init__(self) -> None:
# super().__init__()
@abstractmethod
def Li(self) -> None:
"""Define layers in ther model."""
raise NotImplementedError
import torch
import torch.nn.functional as F
class SimLoss(MyLoss): # what i want to similar
def __init__(self,hi:torch.tensor
,ht:torch.tensor
,temp:float
):
self.hi = hi # batch_size * dim
self.ht = ht # batch_size * dim
self.temp = temp
def sim(self,Ie,Te):
dot_product = torch.dot(Ie,Te)
norm_I = torch.norm(Ie)
norm_T = torch.norm(Te)
return dot_product/(norm_I*norm_T) if norm_T*norm_I !=0 else 0
def Li(self):
batch_size = self.hi.shape[0]
L_image_total=0
alignment_image = 0
uniformity_image = 0
for k in range(batch_size):
L_image_alignment =0
L_image_uniformity=0
L_image_alignment = torch.exp(self.sim(self.hi[k],self.ht[k])/self.temp)
for j in range(batch_size):
L_image_uniformity += torch.exp(self.sim(self.hi[k],self.ht[j])/self.temp)
# L_image = -torch.log(L_image_alignment/L_image_uniformity)
alignment_image+=-torch.log(L_image_alignment)
uniformity_image+=torch.log(L_image_uniformity/batch_size)
L_image_total +=alignment_image+uniformity_image
L_image_total/=batch_size
L_text_total=0
alignment_text = 0
uniformity_text = 0
for k in range(batch_size):
L_text_alignment =0
L_text_uniformity=0
L_text_alignment = torch.exp(self.sim(self.hi[k],self.ht[k])/self.temp)
for j in range(batch_size):
L_text_uniformity += torch.exp(self.sim(self.hi[k],self.ht[j])/self.temp)
# L_text = -torch.log(L_text_alignment/L_text_uniformity)
alignment_text+=-torch.log(L_text_alignment)
uniformity_text+=torch.log(L_text_uniformity/batch_size)
L_text_total +=alignment_text+uniformity_text
L_text_total/=batch_size
Loss = (L_image_total+L_text_total)/2
return Loss,alignment_image,uniformity_image,alignment_text,uniformity_textTrain
Experiments
0%| | 0/15 [00:00<?, ?it/s]
##################
Epoch : 0
##################
0 's batch &loss : 0.1842 alignment1,2 : -0.088 -0.087 anisotropy : 0.359
lr : 1.2352941176470589e-05
10 's batch &loss : 0.1743 alignment1,2 : -0.088 -0.087 anisotropy : 0.349
lr : 3.5882352941176474e-05
20 's batch &loss : 0.154 alignment1,2 : -0.082 -0.082 anisotropy : 0.319
lr : 4.944045828160822e-05
####################
validation!!
7%|▋ | 1/15 [02:48<39:23, 168.80s/it]
valid_loss : 0.11913358100822993 valid_alignment -0.07925071428571429 valid_anisotropy 0.2775714285714285
!! 중간 생략 !!
93%|█████████▎| 14/15 [38:31<02:44, 164.59s/it]
valid_loss : -1.340464472770691 valid_alignment 0.31172999999999995 valid_anisotropy -1.964
####################
##################
Epoch : 14
##################
0 's batch &loss : -1.3409 alignment1,2 : 0.312 0.312 anisotropy : -1.965
lr : 2.0051537954535784e-05
10 's batch &loss : -1.3403 alignment1,2 : 0.311 0.312 anisotropy : -1.964
lr : 1.4550932728463223e-05위 결과를 그래프로 나타내 보면 다음과 같이 수렴함을 알 수 있다.
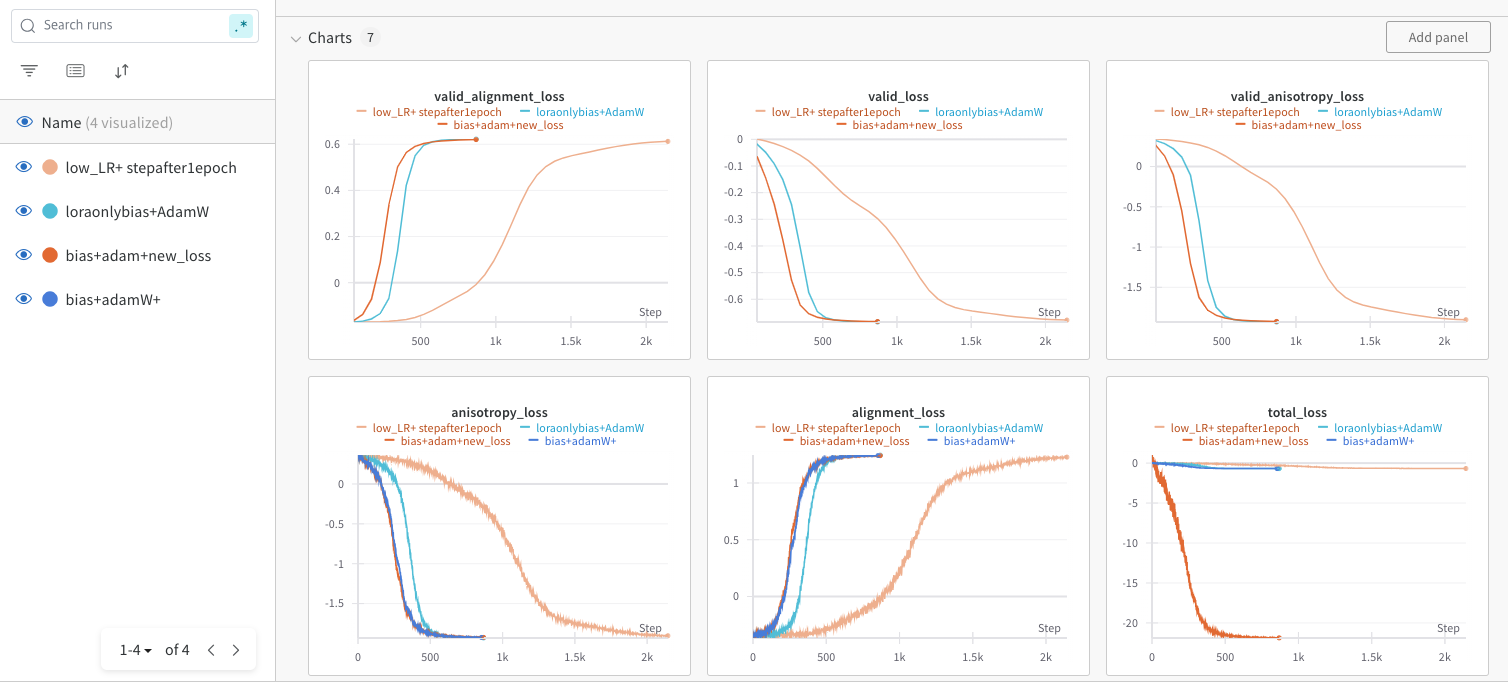
valid loss와 전체 Loss가 비슷하게 떨어지는것으로보아 overfitting은 만이 없음을 알수있다. 다만 이것이 학습이 어떤식으로 작용했는지는 확인해야한다. 그래서 validation으로 youtube set을 확인해야함.!
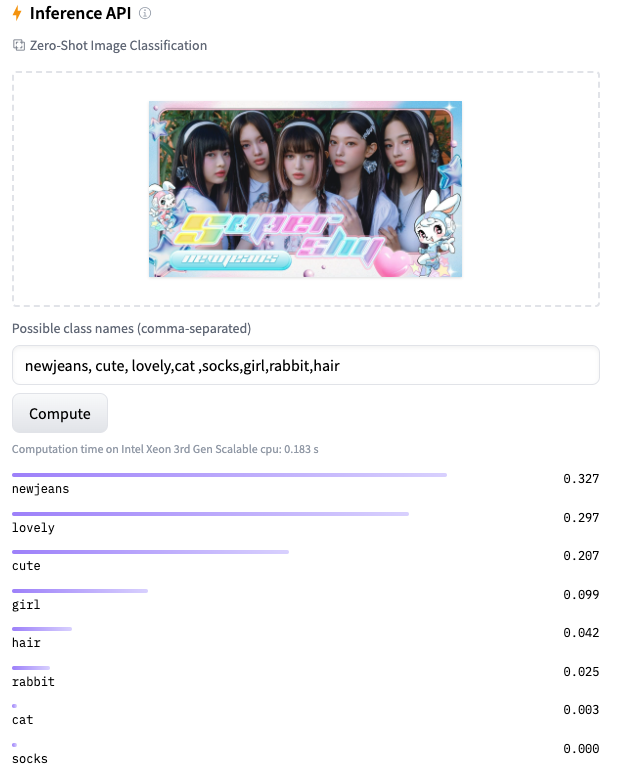
결론 : newjeans is lovely and cute!
Reference
CLIP : https://arxiv.org/abs/2103.00020
LoRA : https://arxiv.org/abs/2106.09685
SimCSE : https://arxiv.org/abs/2104.08821
SimCLR : https://arxiv.org/abs/2002.05709
XCLIP : https://arxiv.org/abs/2208.02816