Router Architecture overview
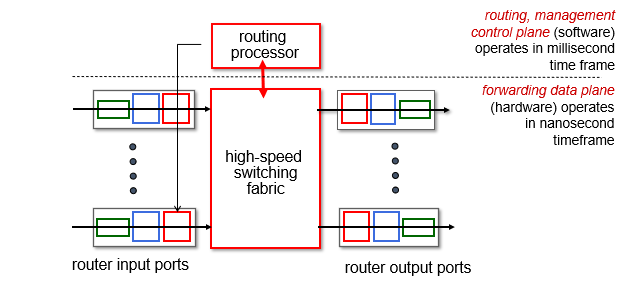
패킷은 인풋 포트에서 아웃풋 포트로 이동하는데, 이 과정에서 switching fabric을 만난다. 또한 routing processor 가 있는데 이는 cpu처럼 control하는 역할이다.
input function fabric
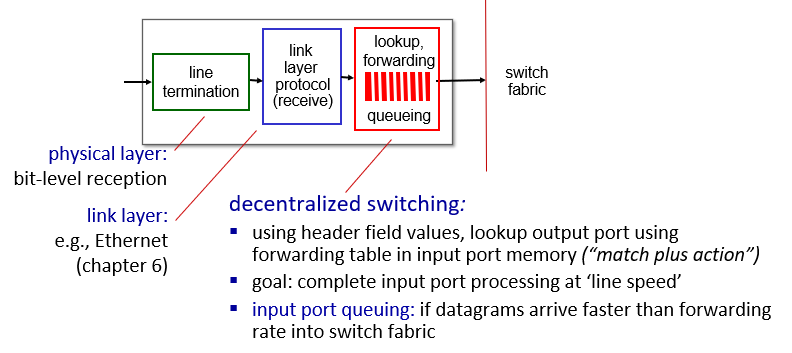
인풋에서 가장 중요한 기능은 lookup, forwarding 기능이다. 여기서는 헤더필드값을 이용해서 포워딩 할 아웃풋 포트를 찾아주는데 이는 match plus action이다.
Forwarding table example
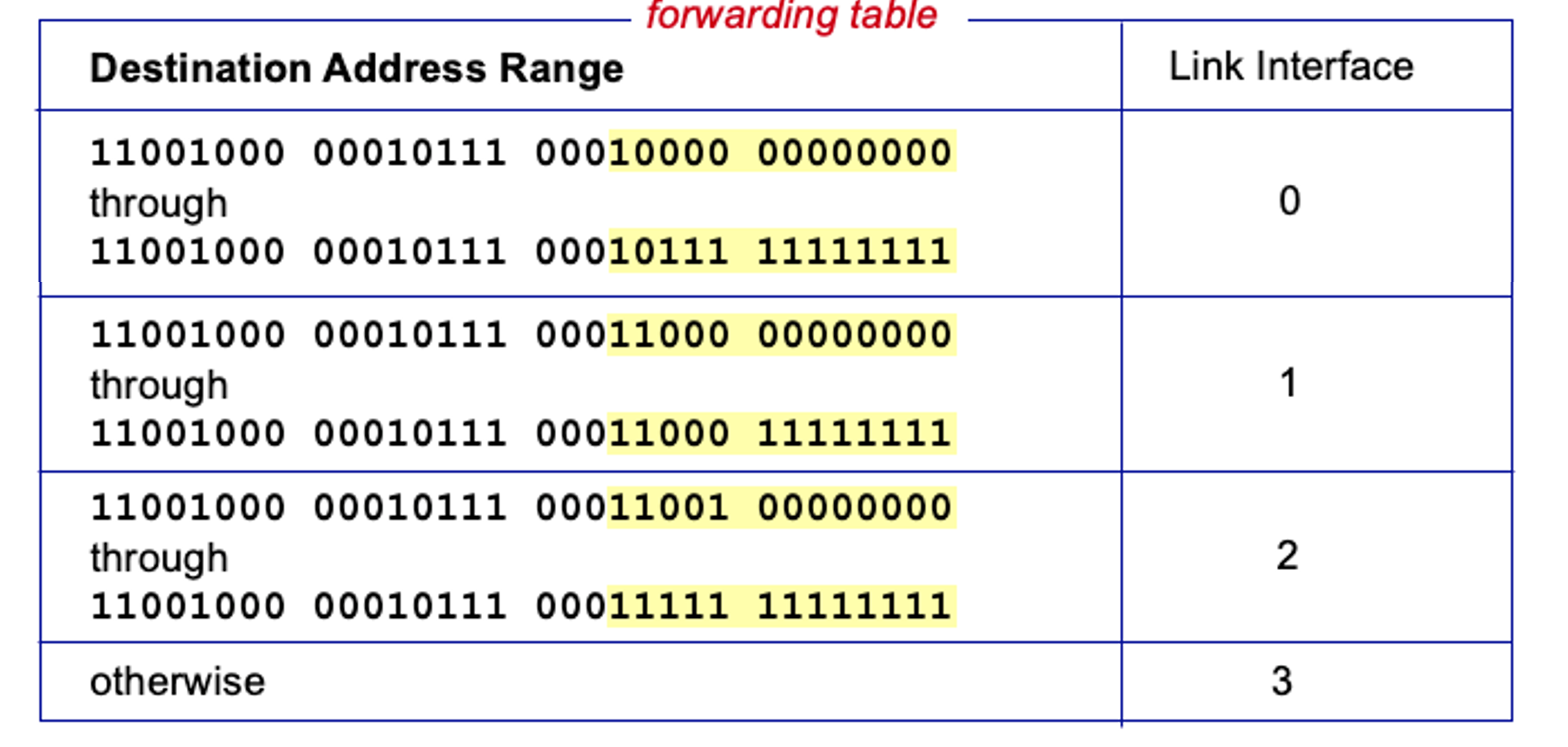
목적지 주소 범위를 정해두고 이를 기반으로 목적지를 찾는다.
포워딩 테이블에서는 목적지까지의 주소들이 적혀있다. 이 목적지 주소는 40억개가 넘는다. 이 테이블은 이걸 다 가지는게 아니라 그루핑을 통해서 분류하고 관리한다.
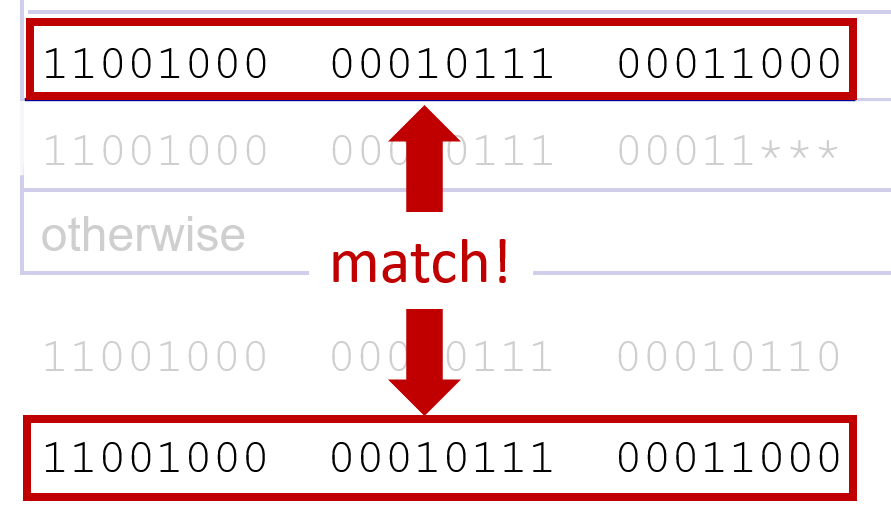
Longest prefix matching
패킷이 하나 들어오면 longest prefix match로 찾아야한다. 즉 제일 길게 매치되는 쪽으로 보내야한다는 거다.
하지만 이 방식은 시간이 오래 걸린다. 이를 줄일 수 있는 방법이 TCAM이다.
Tenary 메모리를 사용해서 이 안에 주소를 넣으면 한사이클만에 목적지가 가야하는 포트의 메모리를 뽑아낼 수 있다고 한다. 이를 이용하면 100만개의 테이블 엔트리가 있어도 찾아낼 수 있다한다.
하지만 발열이 심하다.
아무튼 이 기술로 인해 라우터 하나가 초당 조단위의 패킷을 처리해줄 수 있다.
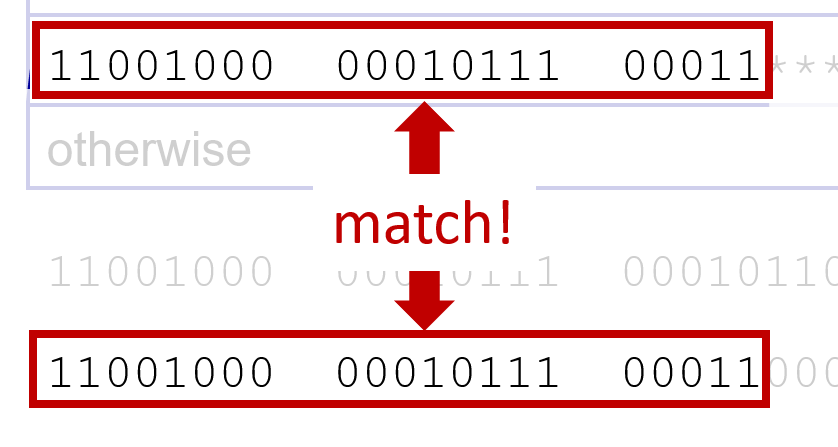
예시

두번째의 경우는 첫번째 prefix가 맞는 경우랑, longest prefix가 다르다. 이때는 longest를 따른다.
Switching fabric
switching rate가 가장 중요한데, 이는 인풋포트에서 아웃풋포트로 이동할 수 있는 Maximun rate이다. N input이 Rate R로 들어오면 스위칭 레이트는 NR이다.
스위칭페브릭은 즉, NR만큼 처리할 수 있어야 하는것이다.
비싼 라우터들은 Non blocking switching fabric을 가지지만 이는 비싸서 모든 라우터가 가지지는 않는다.
스위칭 fabric의 주요 3타입
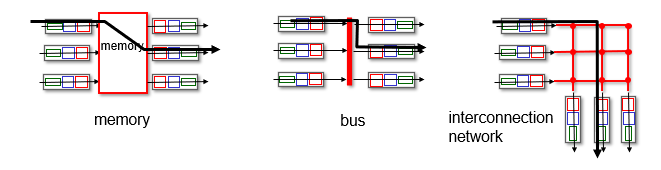
Switching via Memory
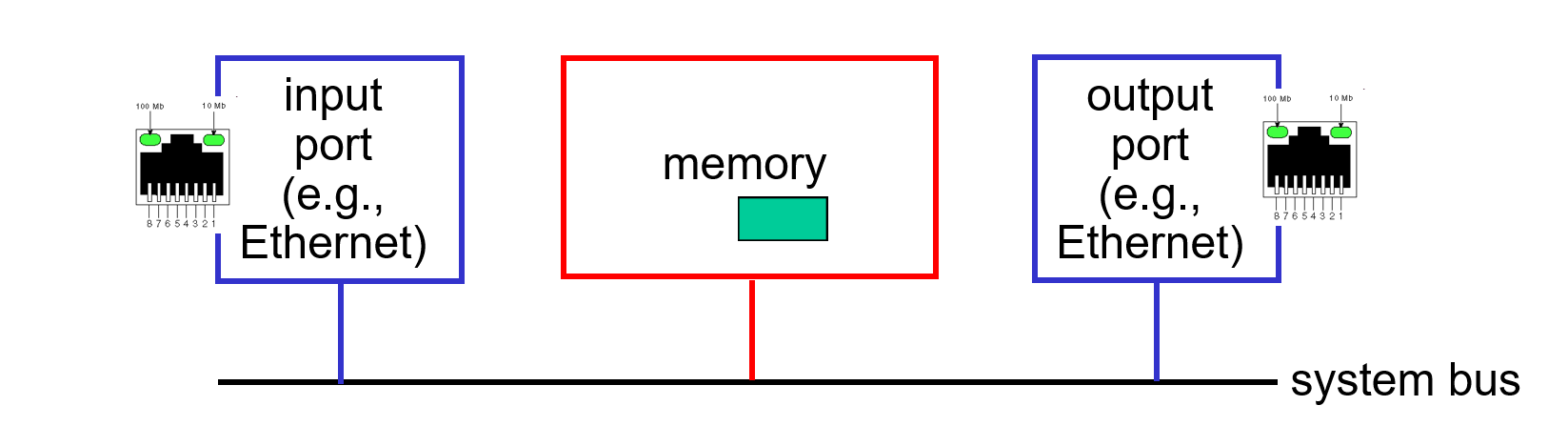
과거에는 cpu의 직접 컨트롤로 memory를 통해 스위칭이 이루어졌다.
이때의 네트워크는 또 다른 IO장치의 일부로 봐도 무방하다.
Switching via bus
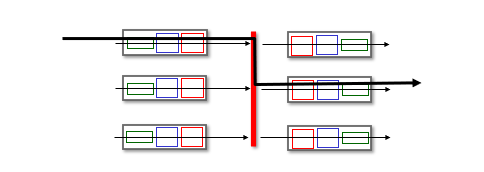
버스구조
이더넷이 바로 버스구조이다. 포트들을 각각 물려있는 pc라고 보면, 이 pc간의 통신을 위해서는 버스들에 데이터를 올려야한다. 이 구조는 버스 contention,
즉 동시에 여러 패킷이 들어와서는 안된다. 하나씩만 들어와야하고 이에 버스 access에 필요한 컨트롤이 필요해진다. 이 컨트롤을 잘 조절해서 최대의 속도로 n개의 링크가 이를 처리하는 기능이 필요하다.
Swtiching via interconnetcion network
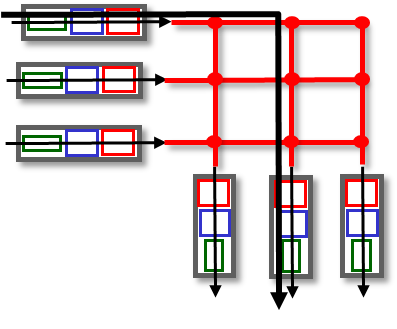
인터커넥션은 3*3 크로스바 형테이다
1 2 3
4 5 6
7 8 9
n input, n output, n*n그리드로 구성되어 있다
이런식으로 구성되어서 9개의 접점이 생기고 동시에 3개의 path가 생긴다 따라서 n * n이면 n개의 루트가 생긴다.
하지만 크로스포인트가 n*n만큼 생기는건 좀 과하다.
따라서 n개의 path를 유지하면서 포인트 개수를 줄이면서 가는 방법을 고민했다.
그래서 나온 것이 멀티스테이지 스위치이다.
이제는 스테이지 구조로 나눠서 제어를 한다.
44 스위치가 4개, 22 스위치가 4개 사용하면 8*8 스위치를 만들어낼 수 있다.
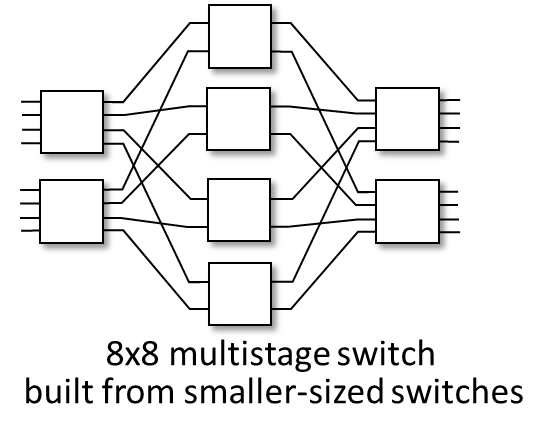
이러한 아이디어는 여러 switching fabric을 병렬연결해서 사용하는 아이디어로 이어졌다.
이러한 인터커넥션이 제대로 작동하려면 모든 패킷의 크기가 같아야한다. 각 크로스포인트를 동일하게 유지해야 정확하게 전달이 되기 떄문이다. 따라서 패킷사이즈가 다르면 안된다.
이에 라우터들이 패킷사이즈를 맞추기 위해서 일을 따로 해야한다.
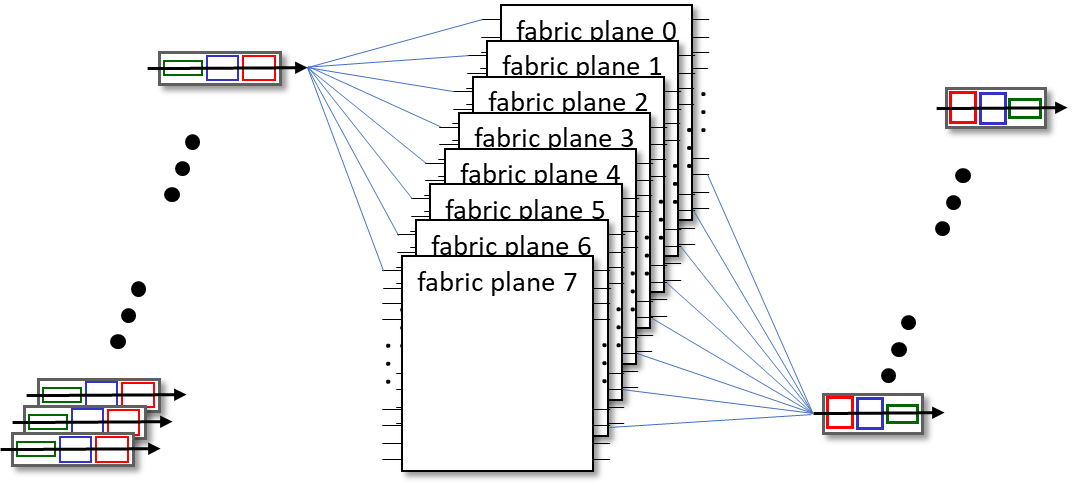
fabric 늘리기
스위칭패브릭 스피드를 늘리는 가장 단순한 방법은 스위칭 패브릭을 여러장 쓰는것이지만, 이 성능증가로 인한 부담은 아웃풋포트가 가져야한다.
아웃풋에 동시에 8개씩 오고 그런다. 즉, 올라간 input과 switching 속도를 output이 r로는 처리하지 못하게 되는것이다. 이에 큐잉이 생기게 된다.
input port queueing
만약 스위치 패브릭이 인풋포트보다 느리면, 큐잉이 발생할 수 있다. 이때 input port에 발생하는 queueing은 Head of the Line Blocking이다.
앞에 큰 패킷이 막아서 뒤에 패킷들은 점점 더 긴 시간만큼 기다려야하는 상황이다.
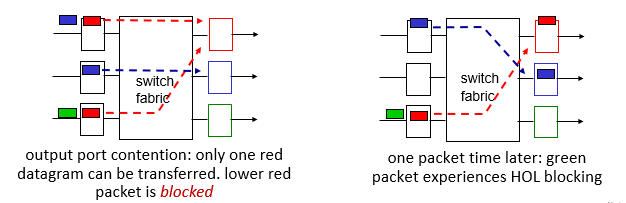
그림을 보면 붉은 패킷들에 의해서 HOL이 발생한것을 볼 수 있다. 다음 순간 위에 있던 붉은 패킷은 이동하고, 가운데 있던 blue 패킷도 이동했지만, 맨 아래에 있던 red 패킷이 아직 이동하지 못했고, 이에 green 패킷 역시 대기하는 HOL상황이다.
이를 해결하려면 결국 패브릭을 여러게 써야한다. 스위치는 아무리 빨라봐야 HOL때문에 58%밖에 못쓴다는 연구결과가 있다.
Output Port Queuing
switching fabric이 NR로 공급을 해준다고 하자. 이때, output 포트에서는 R 만큼만 나갈 수 있고, 이에 비트들은 버퍼에 쌓이게 된다.
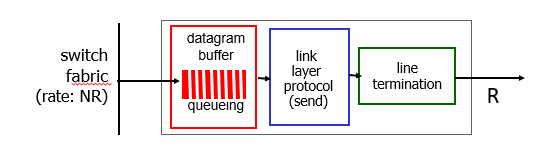
이 버퍼가 가득차게 되면 queueing이 발생해버린다.
이는 얼핏보면 NR만큼 보내는 switch fabric 잘못같지만, congestion 원리를 생각하면 그렇지 않다. 이는 결과적으로 input이 너무 많아서 그런것이다.
이에 output 포트는 2가지 정책이 있다.
drop policy
가장 간단한 방식은 drop tail 즉 선착순으로 살려주고 나머지는 컷하는 방식이다.
scheduling discipline
스케쥴링 알고리즘을 적용해서 누구를 먼저 내보낼지 정한다 가령 특정 패킷들에게 우선권을 줘서 처리할 수 있다.
하지만 network neutrality에 따르면 이런 패킷우선권을 주면 안되고 모드가 평등하게 받아야한다. 하지만 실제로는 라우터, ISP 운영자에 따라서 이는 너무 쉽게 바뀔 수 있는 방식이다.
How Much Buffering?
버퍼링이 많으면 좋지 않을까?
버퍼링에 적당량은 수십년간 해결되지 않았다.
버퍼가 꽉 차야 congestion을 하게 되는방식은 너무 오래걸리고 낭비가 심히다.
그렇다고 무작정 버퍼를 늘리면 딜레이, RTT가 늘어난다.
이는 네트워크 속도가 중요한 작업에서는 쓰면 안되고, 큰 딜레이는 TCP에서 감지하기 어렵고 대응하기 어렵다.
최근 권장 사양

하지만 최근에는 RTT * Capacity / 루트n 이다.
하나의 링크를 공유하는 유저수가 늘어날수록 필요한 메모리는 줄어든다? 왜? 커넥션 개수가 늘어나는데 왜 줄어드는가?
인터넷 트래픽은 쭉 나오는게 아니라 한번에 몰려오고 또 텅 비는 busty한 특성이 있다. 이를 대비하기 위해 메모리가 필요한것이다. 이런 버스티한 특성이 더 모일수록 더 랜덤해진다.
타임 디비전처럼 엄격하게 해봐야 안쓰는시간이 더 많다. 그래서 랜덤하게 쓰는게 더 낫다. 그때그때 보내는데 충돌만 안나게 스스로 조절해서 잘 한다
버스티한 트래픽이 모이면 더 버스티해서 랜덤하게 쓰는게 낫다는 주장이다.
버퍼 매니지먼트
Drop
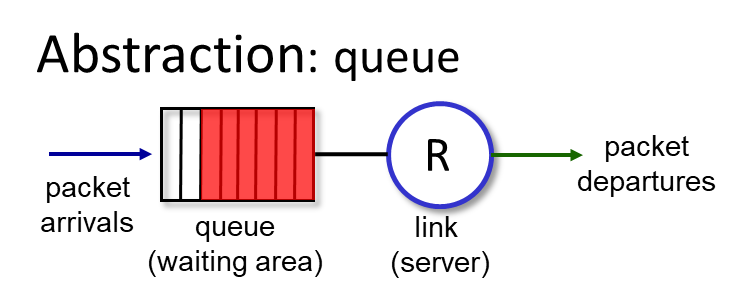
버퍼가 가득차면 drop해야하는데,
Tail drop – 아무런 폴리시가 없는 무지성 드랍
Priority – 우선권을 주고, 우선권이 떨어지면 밀리는 차별화 정책
또한 이 상황에선 marking을 통해서 congestion을 보내준다. (ECN, RED)
marking
이미 네트워크의 도움을 받아서 Congestion Cotrol하는 케이스들 (ECN, RED).
마킹은 로스가 생기기 전에, 메모라가 꽉 차기 전에 표지를 해서 미리 대비를 하자. 즉, 누구에게 로스를 주는게 아니라 누군가의 트래픽을 조금 억제시키는 식이다.
RED

Random Early Detection이다.
각 패킷이 도착할때 마다 큐 사이즈를 측정해서 avg를 구한다. 그리고 possibility를 계산해서 통계적 확률에 의거 넘을 거 같으면 마킹한다. 혹은 임계치를 정해두고 임계치를 넘어도 마킹한다.
확률적으로 하지 않고 임계치 넘었다고 들어오는 패킷마다 전부 마킹을 하면 막히게 된다. 따라서 확률적 마킹이 좋다. 또한 글로벌 싱크로나이제이션의 문제 (확 내려갔다 확 올라갔다) 도 피할 수 있다.
Packet Scheduling
FCFS
FIFO 방식이다. 들어온 순서대로 나간다.
Priority Queue
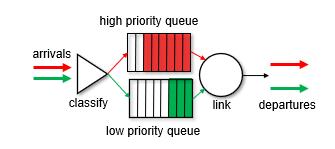
중요도에 따라서 순서를 바꿔준다.
아래의 예시를 보면 우선순위에 따라 처리되는것을 볼 수 있다.
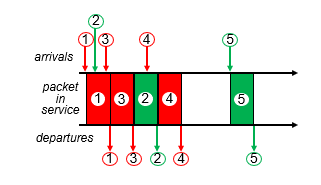
그럼 priority는 누가 정하는가?
이는 Network operator, ISP에 의해 결정된다.
RoundRobin
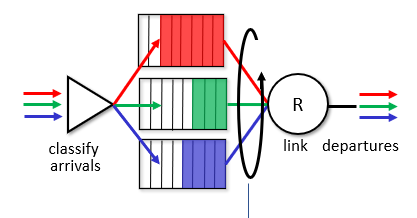
프라이어리티 처리에서는 불공평한 진행이 있다. 특히 minor priority가 기근상태면 열약한 서비스를 받게 된다.
라운드 로빈은 페어니스를 목표로 한다. work conserving 방식이라고 한다.
클래스별로 구분을 하고 서비스 할 패킷이 있으면 쉼 없이 클래스를 바꿔가면서 제공을 해야한다. 하지만 클래스에 차등화를 둔다면 또 차등화된 서비스제공이 된다.
Weighted fair queueing
fairness에 무게를 주는 방식, 즉 Round Robin 스케쥴링이다.
순환하듯이 우선순위 패킷을 정해서 데려가는 방식이다.
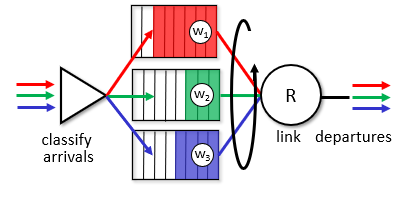
이상적인 작동
각 클래스가 웨이트 i를 나눠가지고 이 웨이트들의 합은 j가 된다. 이러한 경우에는 아무리 클래스가 낮아도 자기 웨이트만큼은 보장을 받기 때문에 프라이어리티 보단 낫고 보장을 받을 수 있다.
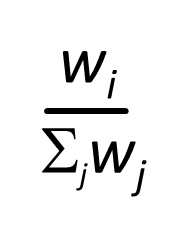
이러면 어떤 시간에도 클래스 i는 wi를 가지기에 보낼 수 있음을 보장받는다.
