순수 JPA
이건 내가 현재 프로젝트 진행중인 코드의 일부분이다.
package Focus_Zandi.version1.web.repository;
import Focus_Zandi.version1.domain.Followers;
import Focus_Zandi.version1.domain.Member;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Repository;
import org.springframework.transaction.annotation.Transactional;
import javax.persistence.EntityManager;
import javax.persistence.Query;
import java.util.ArrayList;
import java.util.List;
@Repository
@RequiredArgsConstructor
@Transactional
public class FollowersRepository {
private final EntityManager em;
private final MemberRepository memberRepository;
public void makeFollow(Followers followers) {
em.persist(followers);
}
public void unFollow(long followeeId, Member follower) {
String jpql = "delete from Followers m where m.followeeId =:followeeId and m.member = :follower";
Query query = em.createQuery(jpql)
.setParameter("followeeId", followeeId)
.setParameter("follower", follower);
query.executeUpdate();
}
public List<String> findFollowers(Member member) {
List<Long> list = em.createQuery("select f.followeeId from Followers f where f.member = :member", Long.class)
.setParameter("member", member)
.getResultList();
List<String> followedMembers = new ArrayList<>();
for (Long aLong : list) {
Member member1 = memberRepository.findById(aLong);
followedMembers.add(member1.getUsername());
}
return followedMembers;
}
}
Entity Manager를 통해서 직접 쿼리문을 작성하고, 이를 기반으로 쿼리를 날리는것을 볼 수 있다.
이러한 방식을 순수 JPA라고 한다.
지금까지 해오던 방식이라서 크게 어려운것은 없을거라 생각된다.
JPARepository
public interface MemberRepository extends JpaRepository<Member, Integer> {
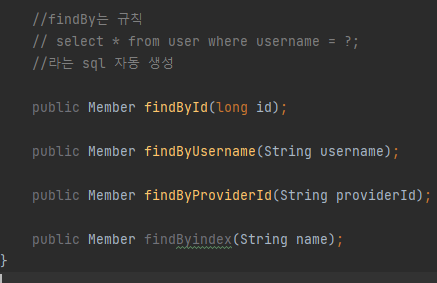
//findBy는 규칙
// select * from user where username = ?;
//라는 sql 자동 생성
public Member findById(long id);
public Member findByUsername(String username);
public Member findByProviderId(String providerId);
}
이는 JpaRepository를 상속받은 MemberRepository이다.
JpaRepository는 규약에 따라서 쿼리문을 생성해준다.
JPA 쿼리메소드 기능
조회: find…By ,read…By ,query…By get…By,
[링크](https://docs.spring.io/spring-data/jpa/docs/current/reference/html/
#repositories.query-methods.query-creation)
COUNT: count…By 반환타입 long
EXISTS: exists…By 반환타입 boolean
삭제: delete…By, remove…By 반환타입 long
DISTINCT: findDistinct, findMemberDistinctBy
LIMIT: findFirst3, findFirst, findTop, findTop3
링크
이러한 기능은 엔티티의 필드명을 기반으로 작동한다. 따라서 필드명과 일치하지 않는다면 오류가 발생한다.
하지만 이러한 방식은 간단한 쿼리만 조회할 수 있다.
복잡한 쿼리는 직접 짜거나, 다음과 같은 방식을 활용한다.
JpaNamedQuery
실무에서는 사용할 일이 거의 없다고 한다.
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString(of = {"id", "username", "age"})
@NamedQuery( name="Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
이런식으로 엔티티에 어노테이션으로 미리 쿼리문을 작성해두고 이를 호출해서 사용하는 방식이다
public List<Member> findByUsername(String username) {
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", username)
.getResultList();
return resultList;
}이렇게 순수 JPA에 넣는 방식 이외에도 JPA상속에서도 사용할 수 있게 된다.
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param("username") String username);근데 굳이 이 기능을 쓸 필요가 있을까?
@Query
Repository에 쿼리를 바로 정의하는 기능이다.
@Query("select m from Member m where m.username = :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);기존의 em.createQuery에서 쿼리를 짜는것처럼 짜서 바로 작동하게 할 수 있다.
DTO 조회
@Query("select m.username from Member m")
List<String> findUsernameList();이렇게 단순하게 쓰면, 이름만 담은 리스트를 조회할 수 있다. 그렇다면 DTO는 어떤식으로 조회해야할까?
@Query("select new study.datajpa.entity.dto.MemberDto(m.id, m.username, t.name) " +
"from Member m join m.team t")
List<MemberDto> findMemberDto();이것도 기존의 dto 조회랑 똑같이 하면 된다.
파라미터 바인딩
이름 기반
@Query("select m from Member m where m.username = :name")
Member findMembers(@Param("name") String username);기존에 하던 param 바인딩과 동일하다.
위치 기반
위치가 바뀌면 모든게 틀어지니깐 쓰지말자.
반환타입
스프링 JPA는 괭장히 많은 반환타입을 지원한다.
List<Member> findByUsername(String name); //컬렉션
Member findByUsername(String name); //단건
Optional<Member> findByUsername(String name); //단건 Optional이렇게 다양한 타입을 지원한다.
페이징과 순수 정렬
순수 JPA에서
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m where m.age = :age order by m.username desc")
.setParameter("age", age)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
public long totalCount(int age) {
return em.createQuery("select count(m) from Member m where m.age = :age",
Long.class)
.setParameter("age", age)
.getSingleResult();
}페이징에서 offset은 시작점, limit는 페이지의 끝이 된다.
또한 페이징은 정렬 후에 기록을 가지고 오기 때문에 뒤에 desc 정렬을 추가하였다.
카운트 메서드는 단순하게 숫자를 새는 기능이라 따로 정렬은 할 필요가 없다.
스프링 JPA에서
페이징과 정렬 파라미터
org.springframework.data.domain.Sort : 정렬 기능
org.springframework.data.domain.Pageable : 페이징 기능 (내부에 Sort 포함)
특별한 반환 타입
org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능(내부적으로 limit + 1조회)
List (자바 컬렉션): 추가 count 쿼리 없이 결과만 반환Page<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용
Slice<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용안함
List<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용안함
List<Member> findByUsername(String name, Sort sort);다음과 같은 샘플들이 존재한다.
Pageable은 인터페이스이다. 따라서 실제로 사용할때는 구현객체인 PageRequest를 사용한다.
PageRequest 생성자의 첫번째 파라미터에는 현재페이지, 두번째 파라미터에는 조회데이터수를 입력한다.
이렇게 조회되고 완성된 페이지를
List<Member> content = page.getContent(); //조회된 데이터다음과 같이 받아서 사용할 수 있다.
경고
지금은 엔티티를 바로 반환하고있다. 이는 엄격히 금지되어있는 사항중 하나이다. 따라서 받아온 member를 MemberDto로 변환해야 한다.
이는 page.map을 통해 구현할 수 있다.
Page<Member> page = memberRepository.findByAge(10, pageRequest);
Page<MemberDto> dtoPage = page.map(m -> new MemberDto());이렇게 페이지를 유지하면서 DTO로 반환해서 Enttiy 직접노출도 막으면서 페이징도 할 수 있게 된다.
벌크성 수정 쿼리
특정 데이터를 한번에 바꾸는 쿼리문이다.
순수 jpa
public int bulkAgePlus(int age) {
return em.createQuery("update Member m set m.age = m.age +1 where m.age >= :age")
.setParameter("age", age)
.executeUpdate();
}특정 파라미터를 기준으로 그 이상은 전부 1씩 더하는 jpa 쿼리문이다.
스프링 JPA
@Modifying
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);Modifying 어노테이션을 붙여야 select 쿼리가 아닌 변경문 쿼리로 정상작동한다.
벌크연산은 영속성 컨텍스트를 고려하지 않고 바로 DB에 쿼리를 날린다. 따라서 영속성 컨텍스트는 이를 인지하지 못한다.
따라서 벌크연산 후에는 영속성 컨텍스트를 em.flush를 통해서 전부 밀어버려야 한다.
@EntityGraph
연관된 엔티티들을 SQL 한번에 조회하는 방법이다.
기존의 방식대로 조회를 하면 1:N연관관계를 전부 불러오려고 하면, Lazy로딩의 특성상 proxy를 먼저 불러오고 나중에 proxy를 조회할 때 조회를 한번 더 하기위해서 쿼리를 또 날리게 되고 이때 N+1문제가 발생하게 된다.
순수 JPA
순수 JPA에서는 보통 fetch 조인으로 처리하는 방법이 일반적이다. 이와 관련해서는 최적화에서 다룬적이 있다.
스프링 JPA
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();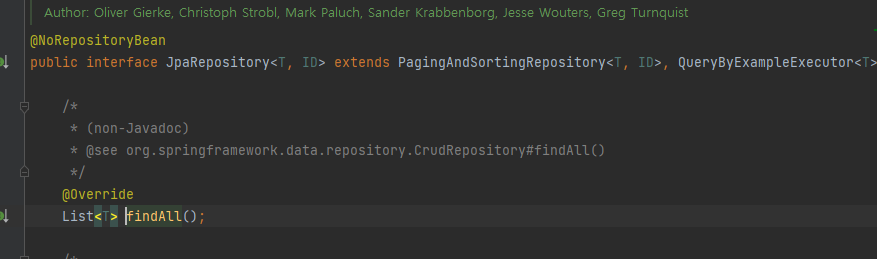
JPA인터페이스 안에 있는 Findall을 이용하고 위에 어노테이션을 달아서 해결할 수 있다.
근데 사실 이것도 fetch join을 이용한 방법이다.
//공통 메서드 오버라이드
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
//JPQL + 엔티티 그래프
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
//메서드 이름으로 쿼리에서 특히 편리하다.
@EntityGraph(attributePaths = {"team"})
List<Member> findByUsername(String username)다른 예시들이다.
하지만 복잡한 쿼리문은 직접 fetch join으로 작성해서 보내는게 좋다.
Hint
JPA 쿼리 힌트는 SQL 힌트가 아니라 JPA 구현체에게 제공하는 힌트이다.
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);이런식으로 읽기전용 메서드를 만들 수 있다. 이렇게 세팅하면 내부에서 최적화를 통해 스냅샷을 만들지 않고 변경없이 바로 돌려버린다.
Lock
@Lock(LockModeType.PESSIMISTIC_WRITE)
List<Member> findByUsername(String name);