JPA
1.JPA가 무엇인가

과거 백엔드 개발에서 DB에 데이터를 저장하려면, 순수 JDBC 기술만을 이용해서 수행해야했다. 예전에 작성한 JDBC 기반 DB 프로그램인데, 대충봐도 엄청 복잡하다는걸 알 수 있다 .그 후, MyBatis같은 JDBCTemplate이 나오면서 많이 간단해지긴했지만,
2.JPA로 예제 만들기
인프런 스프링 강의를 듣고 JPA를 무작정 따라해보고, 그 다음 JPA의 기본개념을 익혀보려고 한다.JDBC 나 Template는 대충 아는 수준인데 JPA는 진짜로 조금밖에 해본적이 없어서, 이번기회에 체험을 해보고 방학기간동안 있을 UMC Team Project에서
3.엔티티 설계 주의점
Setter가 모두 열려있으면, 변경 포인트가 너무 많아서 유지보수가 어렵다. 연관관계를 로딩할 때, 연결된 모든 연관데이터를 전부 다 불러오는 기능이다. 따라서 어떤 SQL이 실행될지 추적하기 어렵다따라서 모든 연관관계는 지연로딩( LAZY )으로 설정해야 한다.연관
4.변경 감지와 병합
위의 코드에서 Book은 itemService.saveItem 하기 전까지는 JPA에서 관리하지 않는다. 내가 만들고 내가 쓰고있을 뿐이지 아무리 코드를 추가해도 db에 올라갈 일이 없다. 이러한 엔티티들을 준영속 엔티티라 부른다. 이를 관리하는 방법은 크게 두가지가
5.영속성 관리
영속성 컨텍스트는 JPA 이해에 있어서 가장 중요한 용어이다. 엔티티를 영구 저장하는 환경이라는뜻으로, EntityManager.persist(entity)로 표현할 수 있다. 영속성 컨텍스트는 논리적 개념이다. EM을 생성하면 눈에 보이지 않는 PersistenceC
6.엔티티 매핑
이는 JPA가 인식하기 위한 어노테이션이다. DDL을 어플리캐이션 실행 시점에 자동 생성한다. 데이터베이스 방언을 활용해서 데이터배이스에 적절한 DDL을 작성해준다. 하지만 이렇게 생성된 DDL은 운영단계에서는 사용하지 않고, 조금 개선해서 사용하는편이다. 운영장비에
7.연관관계 매핑
방향(Direction): 단방향, 양방향다중성(Multiplicity): 다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(N:M) 이해연관관계의 주인(Owner): 객체 양방향 연관관계는 관리 주인이 필요지향 설계의 목표는 자율적인 객체들의 협력공동체를
8.다양한 연관관계 매핑
연관관계 매핑 시, 고려할 상황 다중성 단방향, 양방향 연관관계의 주인 다대일 @ManyToOne 다대일은 이전글에서 만들었던 Member, Team 구조가 ManyToOne 구조이다. Member쪽이 주인이 된다. Team도 만약 거꾸로 Member로 가보고싶다면
9.상속관계 매핑
상속 관계 관계형 DB에서는 상속관계가 없다. 슈퍼타입, 서브타입 관계라는 모델링 기법이 객체상속과 유사한 기능을 한다. 조인 전략 Item 테이블을 만들고, 각 상품들을 Item 테이블에 매핑하는 전략이다. 이렇게 상속하고 Entity로 만들면 상속을 반영할 수
10.프록시와 연관관계 관리
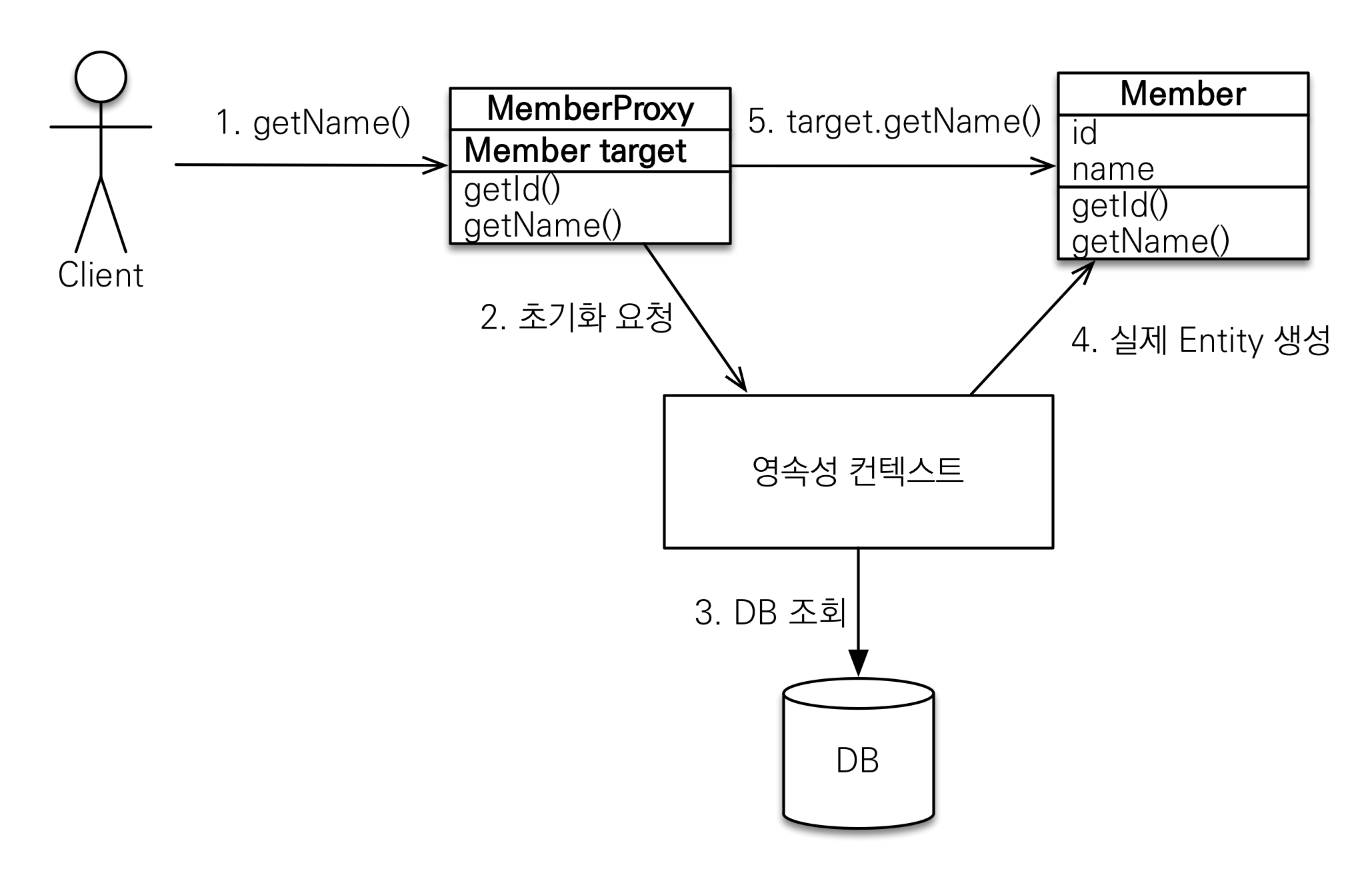
다대일관계에 있는 Member, Team 테이블이 있을때, Member를 조회할 때, 이를 꼭 같이 출력해야 하는걸까?em.find() : 데이터베이스를 통해 진짜 entity를 조회한다em.getReference() : 데이터베이스 조회를 미루는 프록시 엔티티 조회
11.값 타입
@Entity로 정의하는 객체데이터가 변해도 식별자로 지속해서 추적 int, integer, String처럼 단순히 값으로 쓰는 자바기존타입식별자가 없어서 추적 불가능생명주기를 엔티티에 의존한다. 엔티티 삭제하면 필드가 같이 사라지는 원리이다. 기본 타입은 절대로 공유
12.JPQL
지금까지 사용하던 EntityManager는 물론, 직접 쿼리를 작성해서 보낼 수 있는 방법도 있다. JPQLJPQ CriteriaQueryDSLNative SQLJDBC API 사용JPA는 엔티티 객체 중심 개발이다. 따라서 검색 쿼리를 보내는게 조금 곤란한다.검색을
13.지연로딩 성능 최적화

Order 조회 지금까지 만들던 서비스에서 조회용 API를 만들어보자. JPA를 통해서 만든 프로젝트에서 다음과 같은 query로 전체 order를 조회하면 다음과 같은 결과가 나온다.
14.컬렉션 조회 최적화 1

지난번에는 Lazy 조회 최적화를 했는데 이번에는 Collection 조회 최적화를 해보도록 하겠다.좋은 방법이 아니니깐 넘기도록 하겠다.OrderItems는 Lazy로 세팅된 별도의 엔티티이다. 따라서 stream 과정 없이 호출하게 되면 이렇게 오더 엔티티가 비어있
15.@Transactional
Transcaction 트랜잭션은 DB쪽에서 사용되는 용어로, 영어 단어 그 자체는 거래 라는 의미를 가지고 있다. DB에서의 트랙잭션은 하나의 DB 작업이 수행되고, 그 값이 저장되기까지의 과정을 말한다. 참고자료 이러한 개념의 도입으로 모든 작업이 성공적으로
16.컬렉션 조회 최적화

위와 같은 DTO를 JPA에서 직접 조회해보도록 하겠다. Order안에 있는 OrderItems 역시 Entity이기 때문에, orderItems를 담을 DTO를 하나 더 만들어야한다. 그 전에, 이 둘의 관계를 살펴보면 Order와 orderItems는 1:N 관계라
17.OSIV
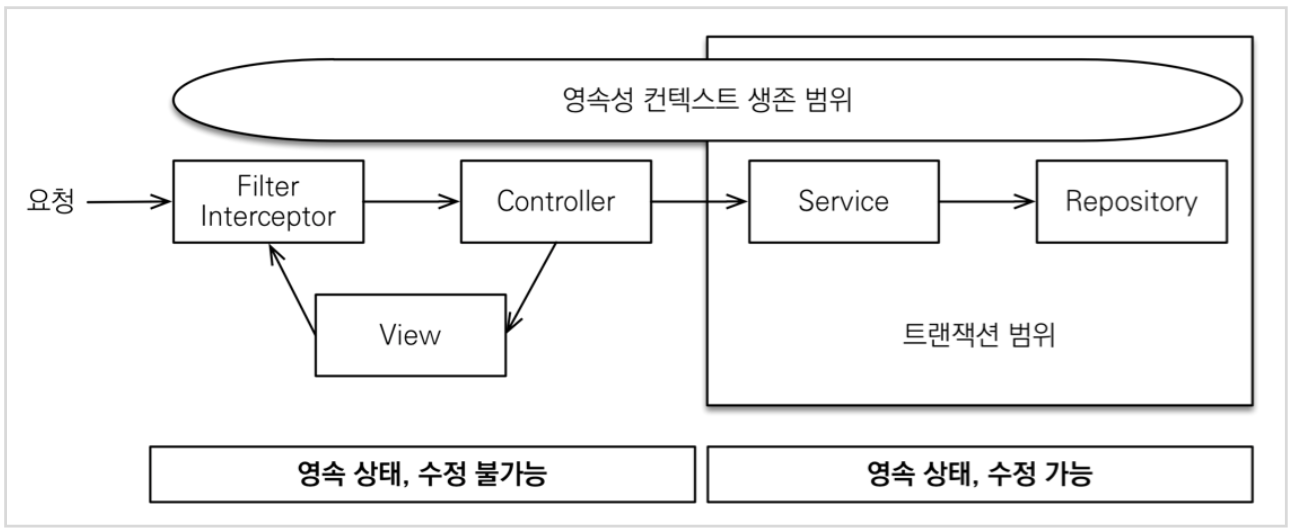
혹은 JPA에서는 Open EntityManager In View라고 하지만 관례상 OSIV라고 한다.OSIV 전략은 트랙잭션 시작처럼 DB 첫 커넥션 시점부터 API 응답종료까지 영속성 컨텍스트와 DB 커넥션을 유지한다. 즉, Transaction이 시작하고 나면 D
18.순수 JPA와 JPARepository
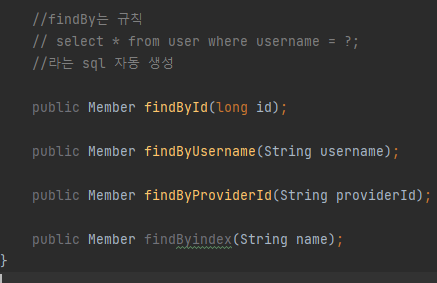
이건 내가 현재 프로젝트 진행중인 코드의 일부분이다.Entity Manager를 통해서 직접 쿼리문을 작성하고, 이를 기반으로 쿼리를 날리는것을 볼 수 있다. 이러한 방식을 순수 JPA라고 한다. 지금까지 해오던 방식이라서 크게 어려운것은 없을거라 생각된다. 이는 Jp
19.사용자 정의 Repository / 확장기능
스프링 데이터 JPA는 인터페이스만 정의하고, 구현체는 스프링이 자동생성한다. 하지만 이를 안쓰고 스프링 데이터 JPA가 제공하는 인터페이스를 직접 구현하면 구현해야 하는 기능이 너무 많다. 이를 해결해 주는것이 사용자 정의 인터페이스이다. 우선 인터페이스를 하나 만든
20.스프링 JPA 구현체 분석

이런 이름을 가진 클래스가 미리 구현되어있는 상태로 JPARepoistory에 들어가있다. 조회나 이런 기능들은 우리가 jpa에서 하는걸 그냥 미리 만들어 둔 것이다. 기본적으로 클래스 전체에는 ReadOnly Transactional로 되어있다. 다만 변경, 저장 같
21.JPA의 나머지 기능
사실 잘 안쓰는 그런 기술들이다. 복잡도 대비 실무효용성은 별로 없는편이다.Specification은 JPA Criteria를 이용하는데 Criteria는 실무에서 사용하기 너무 불편하고 어려운 기술이다.실무에서는 대부분 QueryDSL을 쓴다. 멤버 엔티티 자체를 검
22.QueryDSL 기초 문법
fetchOne을 통해서 결과를 가지고 오는 부분말고는 큰 차이가 없다.fetchResults의 경우 취소선이 생기는것으로 볼때 더이상 권장되지 않는듯하다.orderBy를 통해 조건에 맞는 정렬을 한다. JPQL과 똑같이 offset, limit를 걸어서 찾아온다.전체
23.QueryDSL 중급 문법

가장 간단한 형태의 결과반환은 튜플형을 사용하면 된다.String, int 형을 담은 두 형태가 알아서 들어가게 된다.이런 형태의 DTO를 반환하려고 한다.순수 JPQL에서는 new 를 활용해서 이를 반환한다. 하지만 이 방식은 패키지명을 하나씩 다 넣어야해서 그렇게
24.순수 JPA와 Querydsl
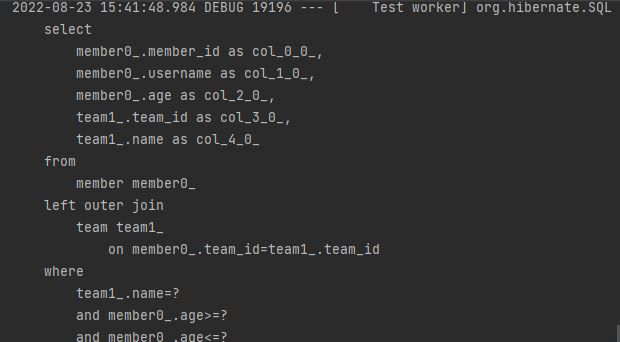
순수 JPA로 repository를 작성하면 다음과 같다.여기서 findByUsername, findAll 같은 경우는 querydsl로 작성할 수 있는 부분이다.다만, queryFactory의 경우 미리 bean 등록을 해야지 다음의 오류가 발생하지 않는다.기존의 동
25.스프링 데이터 JPA와 Querydsl
인터페이스에 직접 queryDsl을 다 적어줄수는 없다. 따라서 customRepository를 만들고, 이를 JpaRepository에 상속을 해주면 된다.혹은, 쿼리조회용 리포지토리를 아예 하나 따로 분리해서 서비스 리포지토리와 쿼리 리포지토리를 구분해서 관리하는것
26.스프링 데이터JPA 제공 기능
하지만 이 기능들은 조금 부족해서 잘 안쓰인다 공식 문서(https://docs.spring.io/spring-data/jpa/docs/2.2.3.RELEASE/reference/html/조인이 안된다. (묵시적 조인은 가능하지만 left join이 불가능하
27.Sequence 생성 전략

PK를 자동생성해줄때 자주 사용하는 어노테이션이다. 이렇게 하이버네이트 시퀀스를 이용해서 값을 자동생성해주는데, 이때 pk값은 전체 테이블이 공유하게 된다.즉, 하나의 숫자가 중구난방으로 나오게 되는것이다.이를 해결하기 위한 전략을 정리하도록 하겠다.전략은 크게 4개가