Collection 조회 최적화
지난번에는 Lazy 조회 최적화를 했는데 이번에는 Collection 조회 최적화를 해보도록 하겠다.
Entity를 직접 노출
@GetMapping("/api/v1/orders")
public List<Order> ordersV1() {
List<Order> all = orderRepository.findAll();
for (Order order : all) {
order.getMember().getName(); //Lazy 강제 초기화
order.getDelivery().getAddress(); //Lazy 강제 초기환
List<OrderItem> orderItems = order.getOrderItems();
orderItems.stream().forEach(o -> o.getItem().getName()); //Lazy 강제 초기화
}
return all;
}좋은 방법이 아니니깐 넘기도록 하겠다.
Dto로 반환
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> all = orderRepository.findAllByString(new OrderSearch());
List<OrderDto> collect = all.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
@Data
static class OrderDto {
private long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItem> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
address = order.getDelivery().getAddress();
orderStatus = order.getStatus();
order.getOrderItems().stream().forEach((o -> o.getItem().getName()));
orderItems = order.getOrderItems();
}
}OrderItems는 Lazy로 세팅된 별도의 엔티티이다. 따라서 stream 과정 없이 호출하게 되면

이렇게 오더 엔티티가 비어있는상태로 나오게 된다.
따라서 Stream을 돌리면서 lazy 초기화를 해야한다.
다만 이렇게 하는 방식은 결국 Dto안에 Entity를 넣어서 보여주는 형태라서 Entity를 절대 노출하지 않는다는 원칙에 어긋난다. Entity에 대한 의존을 완전히 끊어내는것이 우리가 노리는것이다.
따라서 OrderItems를 받는 DTO가 따로 필요하다.
OrderItemDto 만들기
@Data
static class OrderDto {
private long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
address = order.getDelivery().getAddress();
orderStatus = order.getStatus();
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
@Getter
static class OrderItemDto {
private String itemName;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}생성자를 통해 orderItem에서 필요한 정보만 꺼내와서 새로운 Dto를 만들고, 이를 반환해주면 된다.
하지만, 이전글에서 알아봤던것처럼 이러한 방식은 자원낭비가 심각하다

fetch
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.getResultList();
}이렇게 fetch join query로 만들어야한다.
하지만 이런식으로 조인을 하면, DB입장에서는 일대다관계인 둘을 조인해서 출력을 해야하고 Many 쪽에 맞춰서 더 많은 갯수인 OrderItems갯수만큼 나오게 된다. 따라서
실제 오더는 2개지만 4개가 나오게 되는것이다.
이를 방지하기 위해서 distinct를 써야한다. distinct는 중복데이터 출력을 방지하는 기능이다.
하지만 db에서의 distinct는 완전히 똑같은 결과값만 처리해준다. 따라서 조금이라도 다르면 중복제거가 되지 않는다.
하지만 jpa의 중복제거는 order의 id가 같은면 전부 제거해주는 강력한 distinct 기능을 가지고 있다.
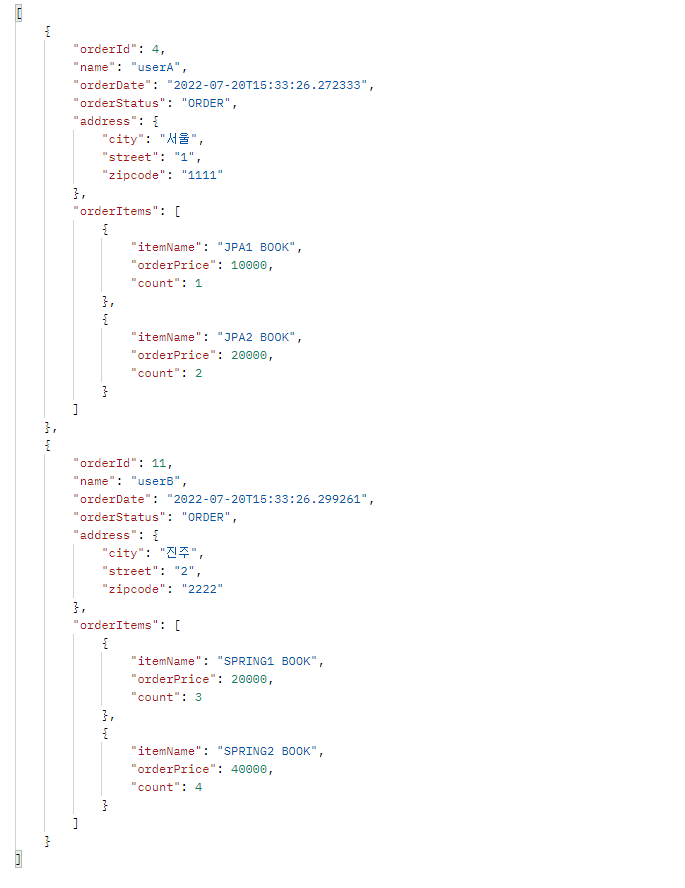
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithItem();
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}
치명적인 단점
하지만 JPA distinct는 페이징 기능을 사용하지 못한다는 치명적인 단점이 존재한다.
하이버네이트는 데이터를 전부 어플리케이션에 퍼올리고, 그 다음 메모리에서 페이징처리를 시도한다. 이는 데이터가 많아지면 치명적인 오류를 발생한다.
이는 일대다 조인을 하는순간 Order의 기준이 다 틀어지면서 패이징이 불가능해지기 떄문이다.
또한 컬랙션 페치 조인은 하나만 사용한다. 컬렉션 둘 이상에 패치조인을 사용하면 OneToManyToMany같은 이상한 관계가 형성되고 이는 부정확한 조회를 유발한다.
fetch join의 페이징
이전에 정리한것처럼 join에서 다를 기준으로 조인이 발생해서 데이터가 예측 불가능해지고 이를 페이징하는게 불가능해진다.
하이버네이트는 경고로그와 함께 모든 db를 읽어들여서 페이징을 시도하고 이는 장애로 이어질 수 있다.
해결책
- ToOne 관계를 전부 fetch join한다.
- 컬렉션은 지연로딩 조회한다.
- 최적화를 위해 hibernate.default_batch_fetch_size , @BatchSize 를 적용한다.
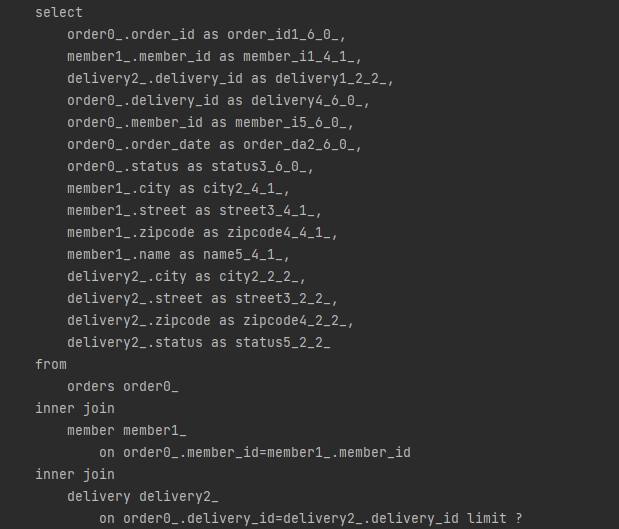
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
} @GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList()); return result;
}
결과는 정상적으로 출력된다. 또한 ToOne 관계로 조인을 해놨기때문에, 페이징역시 문제없이 작동한다.
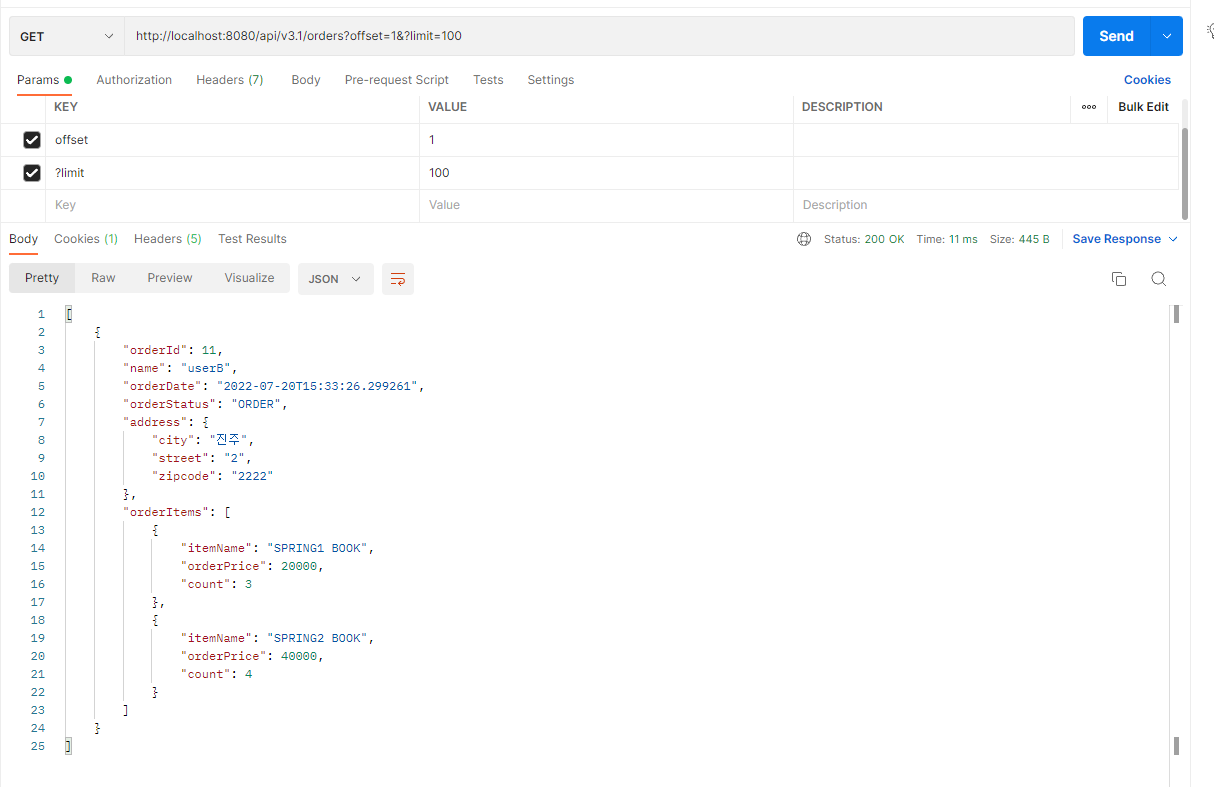

Offset값과 Limit를 param으로 넘겨도 잘 작동하는것을 확인할 수 있다.
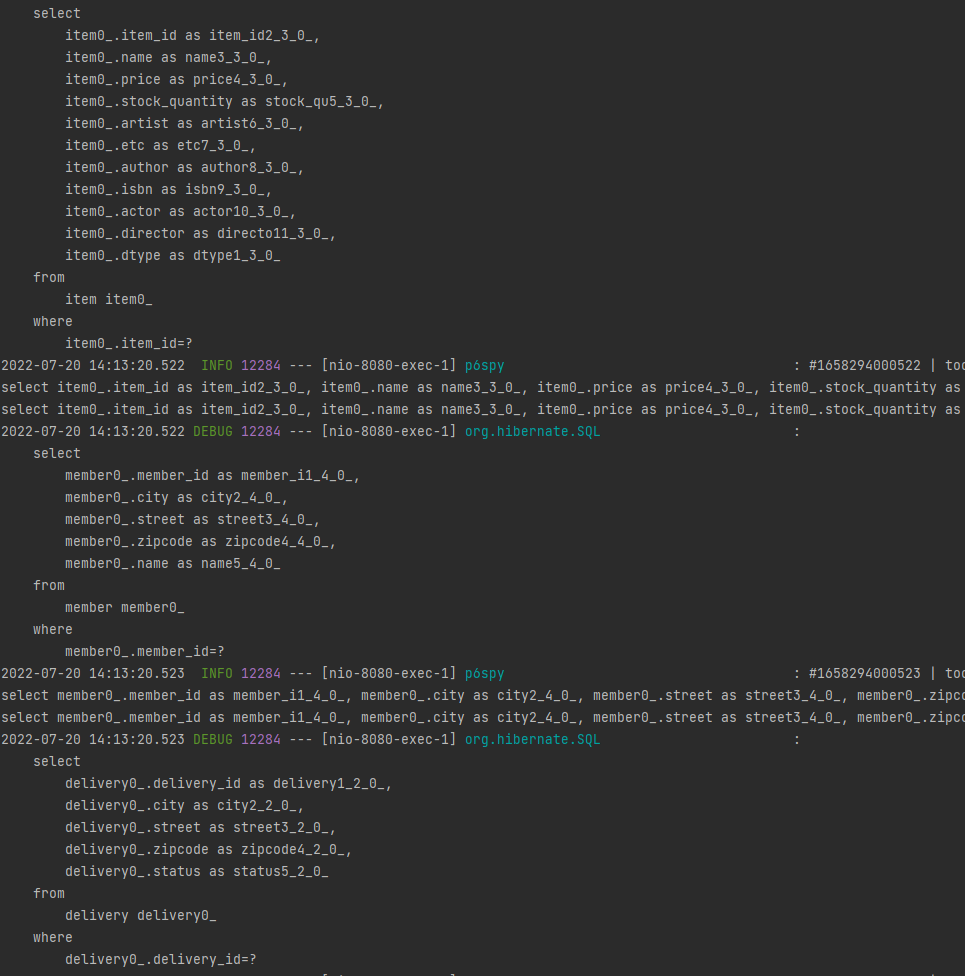
쿼리문 보기
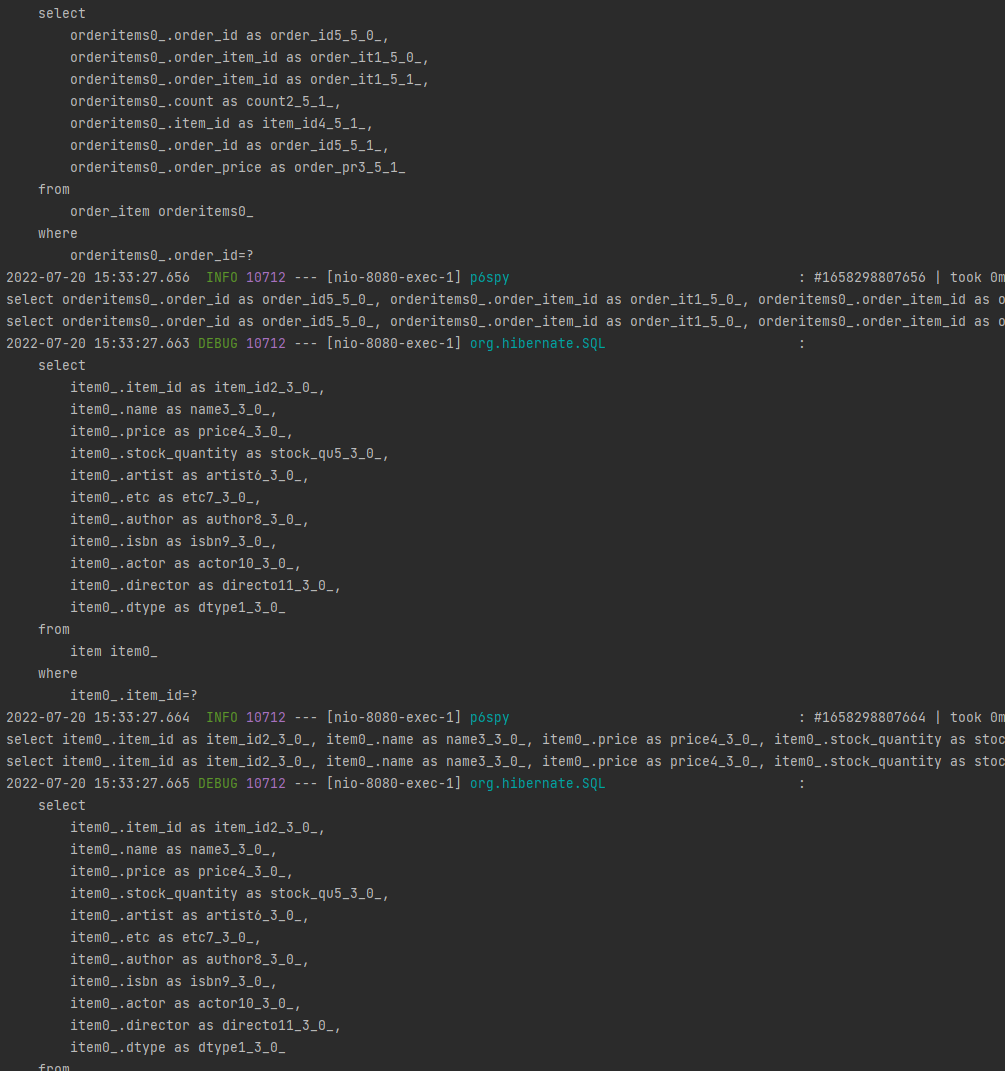
일단 order를 조회한다.
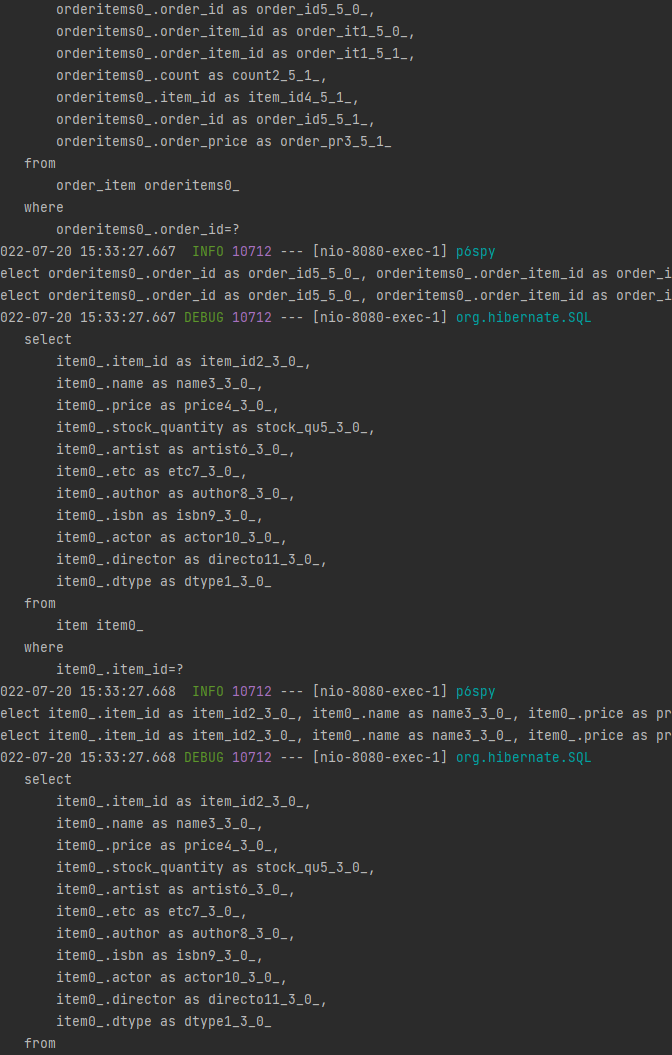
그리고 오더아이템을 조회하고 그 안에 아이템들을 또 조회하는 쿼리가 2회 나간다
그리고 이제 또 다른 오더 아이템을 조회하고 아이템을 한번씩 더 조회한다.
즉, N+1 문제가 발생하는 쿼리문이 나온다.
하이버네이트 최적화
default_batch_fetch_size: 1000
yml에 다음과 같은 내용을 추가하면 lazy 로딩시 1000개를 한번에 가지고 와서 처리하게 된다.
이러면 아까 발생한 n+1 문제가 1+1로 최적화된다.
하지만 이 최적화는 적당한 사이즈를 골라야지 너무 큰 숫자를 고르면 어플리케이션에 부담이 될 수 있다.
Collections에서 사실상 유일한 페이징 방법이다.
