프로세서
Combinational Logic
논리게이트 소자 (and or xor not)을 통해 계산을 수행하는 회로를 작성한다.
구성요소
- adder
- PC를 +4 하여 다음 PC로 이동시키는 역할
- ALU
- Arithmetic Logic Unit
- Control
- 어떤 명령을 수행하고 어떤 ALU가 들어와야 하는지 결정
- Register
- D Flipflop과 유사함(1비트의 정보를 보관할 수 있는 회로) 하지만 레지스터는 N비트의 IO가 가능함
- Memory
- 저장공간 (CPU가 직접 연산에 사용하지는 않고 이동목적)이고 Memory Address를 통해 접급할 수 있음. Write(data in) 과 Read(Data out) 기능이 있음
- MUX
- mulitplexor : 여러개의 인풋 중 어떤 하나를 선택하는 논리회로
A, B 인풋이 들어오면 S(Select)비트를 통해 어던 것을 통과시킬 지 결정함
- mulitplexor : 여러개의 인풋 중 어떤 하나를 선택하는 논리회로
Register file
값이 시간에 따라서 나누어서 들어온다. 레지스터에 따라서 어떤 레지스터에 넣어 줄 것인지 선택함
디코더를 통해서 들어온느 입력값에 따라서 어떤것을 선택할 지 고르고 값을 넣어줌
Instruction Execution
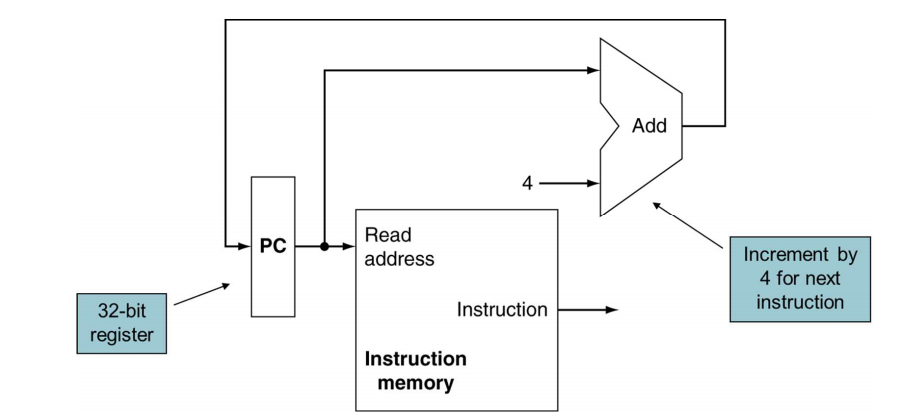
step 1. Instruction Fetch
Pc가 가르키는 주소로부터 명령어를 가지고 옴
그때, Pc 라고 하는 주소를 저장하는 공간이 필요함 따라서 IR, Instruction Register – 지금 수행해야하는 명령어, 지금 fetch해야하는 명령어를 담고있는 공간이 필요함.
PC 와 IR 이라고 하는 것은 register file 과 별도로 특별한 레지스터로 존재하고 있음
Pc가 가르키는 메모리로부터 inst를 가지고 옴
PC를 4 증가시킴(다음 명령어 지칭)
step 2. Decode (Decoding for execution)
OP를 받아 해석해서 ALI LW SW B 같은 명령어들 해석해서
필요한 연산을 불러올 준비를 함.
Ex) Add
특정 레지스터로부터 연산을 하기 위해서 준비를 시켜야 함
Alui에 레지스터값을 가져오는 준비단계 (fetch)
명령어를 해석해서 실행전까지 가는게 두번째 단계
step 3. Execution
ALU 를 통해서 연산을 함
결과를 만들어 내고, 그 결과를 미리 만들어진 프로세서에 따라서 저장, 로드, 혹은 브랜치 함.
Arithmetic 만 하는게 아님 lw sw b 다 연산한다.
각각의 명령어에 따른 정의된 대로의 연산을 수행한다.
step 4. Final Step
-
Memory reference
Lw – 어드레스에 메모리를 씀
Sw – 어드레스로가서 메모리를 가지고 옴 -
Arithmetic logic – 연산의 결과를 레지스터에 지칭된 공간에 써줌
-
Branch – PC값을 조건에 맞게 바꿔줌 (타겟주소값을 PC로 업데이트)
Abstract Picture of MIPS
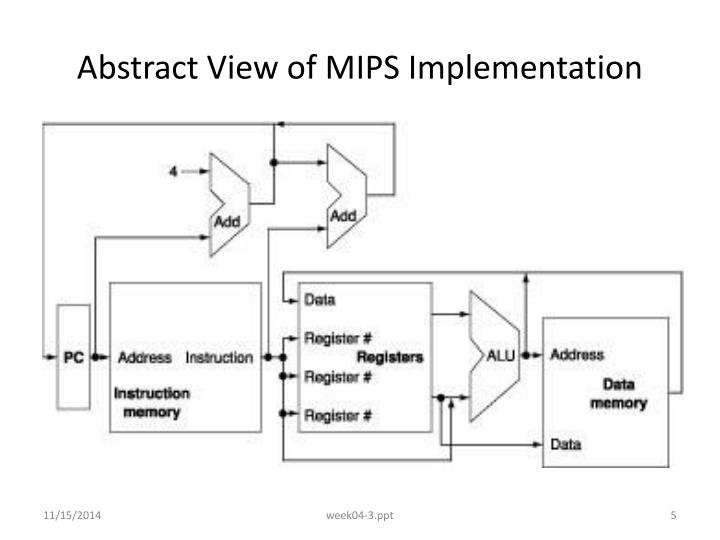
- PC
- 수행 할 명령을 저장해두는 공간이다. 특이한점은 계산에 들어가기전에 이미 Adder를 통해 PC+4를 완성해서 가지고있다는 점이다.
- Instruction
- 주소, instruction 이 저장되어 있고 이에 맞게 register에 들어가서 명령을 수행하게 된다.
- Register
- 값을 입력받아 맞는 위치에 저장하고 신호에 따라 ALU에 넣어 계산을 수행하게 한다.
- ALU
- 입력받은 값으로 계산을 하고 그 결과를 신호에 따라 memory에 쓰거나 다시 돌려보내거나 branch하거나 한다.
- Memory
- 값을 저장하는 공간이다. 혹은 값을 불러올 수 있다.
- Control
- 어떤 시그널을보내서 어떤 명령어를 만들고 어떤 동작을 할지 결정하는 역할을 한다.
몇몇 경우에 path는 공유하는데 둘중 하나를 선택해서 사용하는 경우가 있다. 이런 경우 Mux로 판단한다.
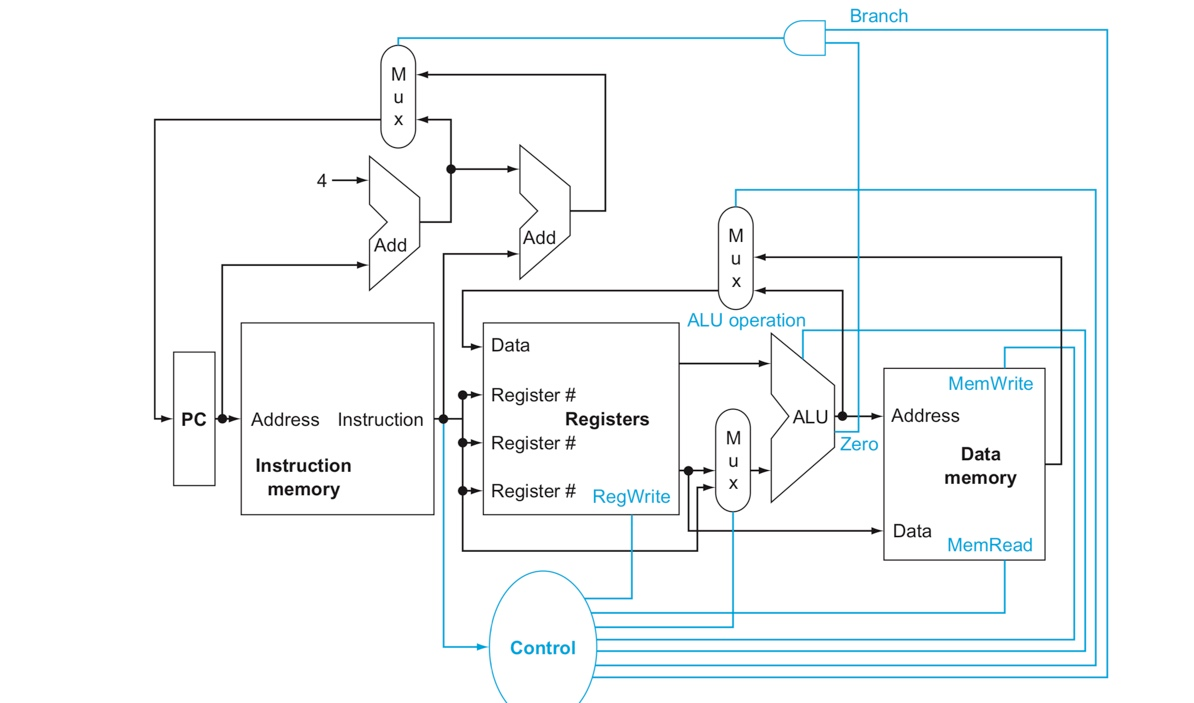
<밉스의 기본 구현도>
설계와 구현
-
RTL, 상위 레벨, logic level
- 논리게이트를 가지고 명령 수행을 위한 프로세서 설계를 어떻게 할 것인가?
-
반도체 실리콘 레벨
- VLSI 반도체 같은 전자공학쪽
ADD의 경우
Mips 의 add 연산은 다음과 같은 구조를 가지고 있다.
단계별로 나눠보면 다음과 같다

-
instruction을 memory에서 fetch 한다.
-
Add instruction을 수행한다,
-
PC 값을 변경한다.
sub의 경우 ADD와 거의 동일하다.
LW의 경우
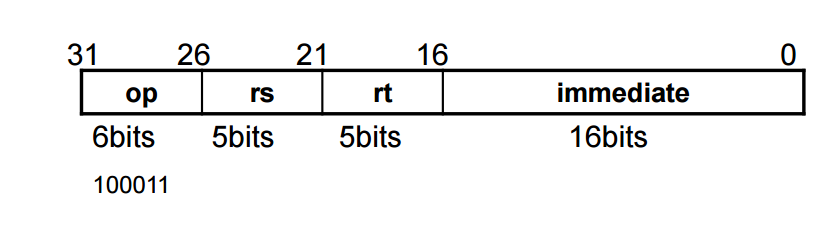
Mips 의 load word 연산은 다음과 같은 구조를 가지고 있다.
-
Inst 에 직접 기제되어있는 immdeisat 16이 Alu에 연산되어 데이터 메모리 접근이 이루어진다
단계별로 나눠보면 다음과 같다

-
instruction을 memory에서 fetch 한다.
-
메모리 주소를 계산한다.
-
register에 데이터를 로드한다.
-
다음 PC를 계산한다.
SW의 경우 3번과정이 세이브로 바뀌고 다 똑같다.
Branch의 경우
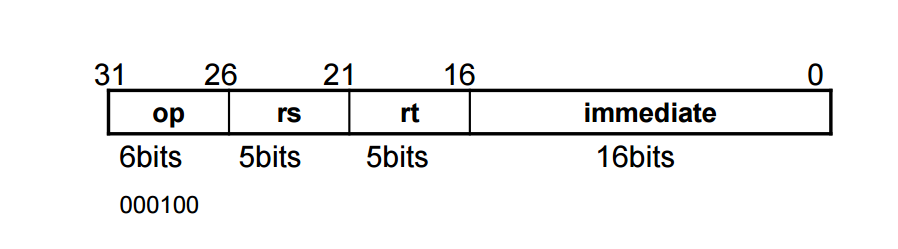
Branch의 beq의 경우 다음과 같은 구조를 갖고 있다.
단계별로 나눠보면 다음과 같다.

-
메모리에셔 명령 fetch
-
conditonal cond를 계산한다.
-
cond 값에 맞춰서 PC값을 정해준다 .
총정리
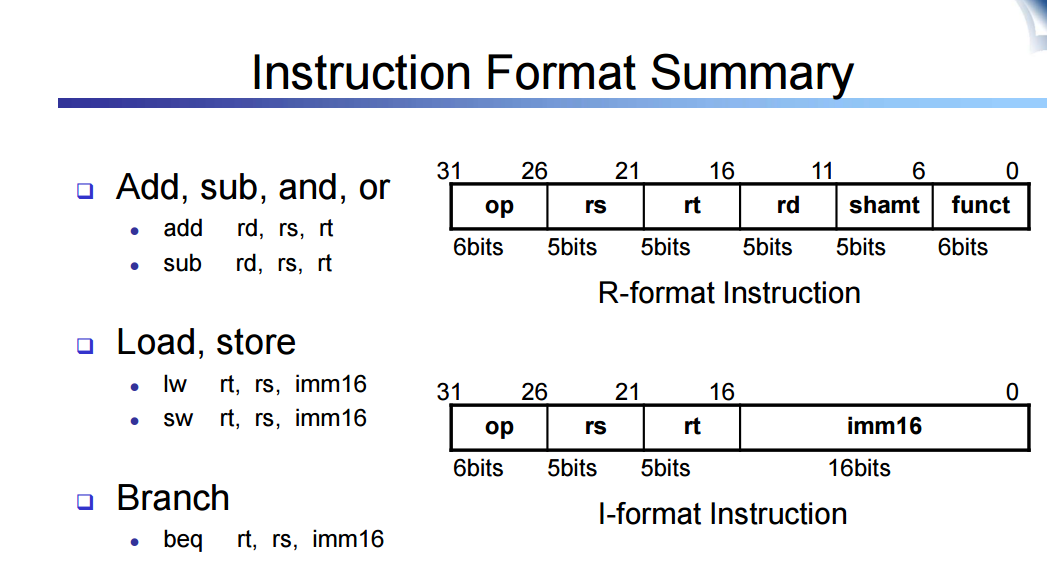
PC Data Path
Instruction memory : Store the instructions of a program
Program Counter (PC) : Store the address of the instruction
Adder : Increment the PC to the address of the next instruction PC + 4 수행함
R format datapath
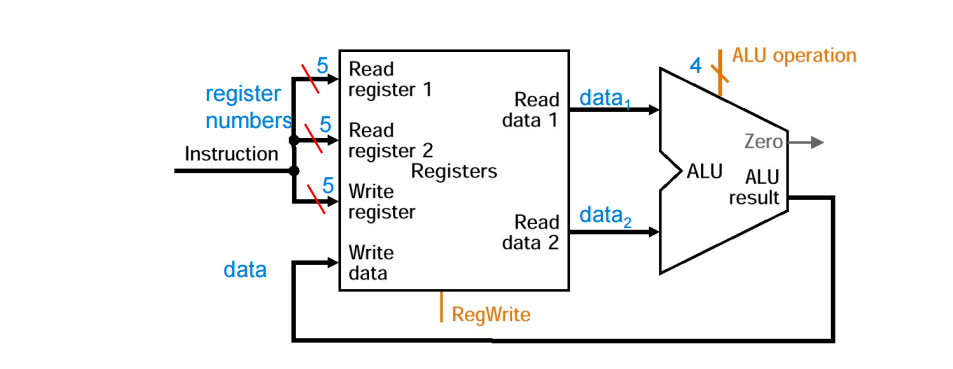
-
ALU를 이용해서 OP코드를 실행함
-
ALU에서 나온 Data를 레지스터에 다시 넣는다.
- 2개의 path와 1개의 destination이 있음
- ALU에서 나온 결과가 Write data로 들어가 특정 register에 값을 써주도록 되어있음
- OP코드를 보고 어떤 alu인지 보고 만들어두는 시그널이 path에 있음
Datapath for Load/Store
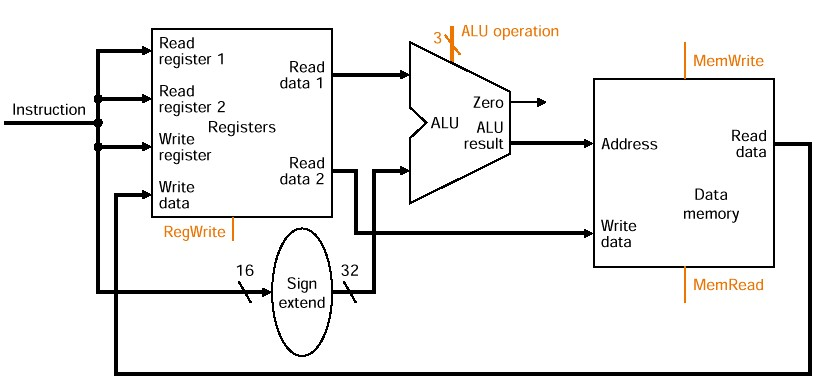
Load store 의 경우, 데이터패스가 약간 다르다
-
ALU는 항상 add 연산이 되도록 control signal이 조정한다.
-
RS는 write register로 들어가고, immediate값이 바로 ALU로 넘어가는 DATAPATH가 있음. (Sign Extend)를 통해 값을 변환
-
데이터를 메모리에 넣고, Control Signal에 맞춰서 lw = memory read, sw = read register로 실행한다.
DataPath for Branch
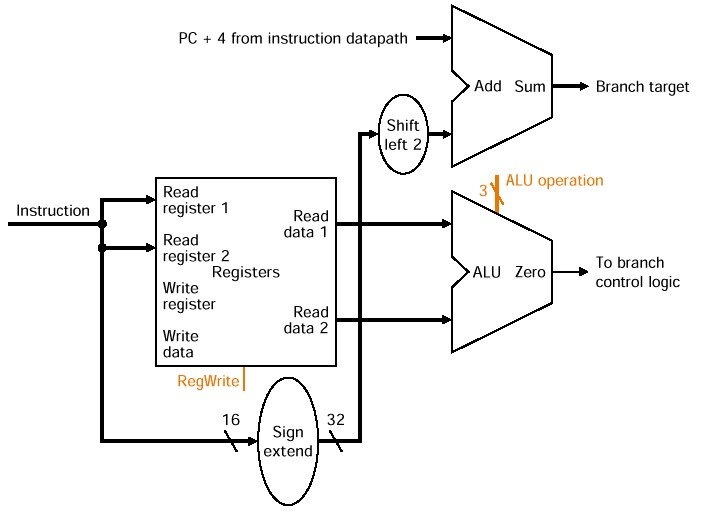
-
ALU가 항상 SUB가 될 수 있도록 조정한다.
-
Imm16이 항상 add sum으로 들어가서 주소 얻을 수 있도록 하는 datapath 존재한다. (Shift left 2 unit)
Integrated one
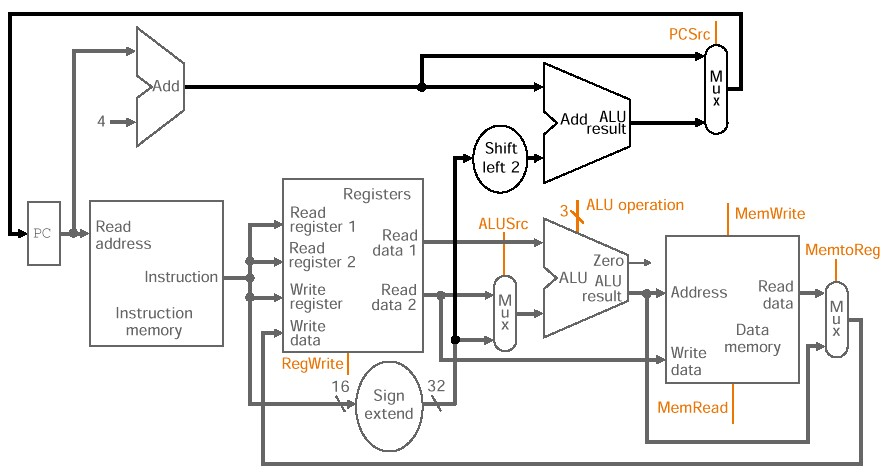
-
Mux를 2개 추가해서 종합적인 설계를 할 수 있다
- ALU 소스를 register로 받을건지, imm으로 받을 건지 결정하는 mux
- 레지스터에 write하는 data를 ALU에서 받는지, 혹은 직접 받는지에 대한 mux
-
이를 수행하기 위해서는 총 6개의 시그널이 필요하다.
-
Branch 에서는 분기명령어 처리를 위한 또 하나의 mux가 필요하다
Single Cycle Datapath
The simplest datapath
Execute all instructions in one clock cycle
− No datapath resource can be used more than once per instruction.
− Any element needed more than once must be duplicated.
− Separate instruction and data memories
Sharing a datapath between two different instruction types
− Use multiplexor
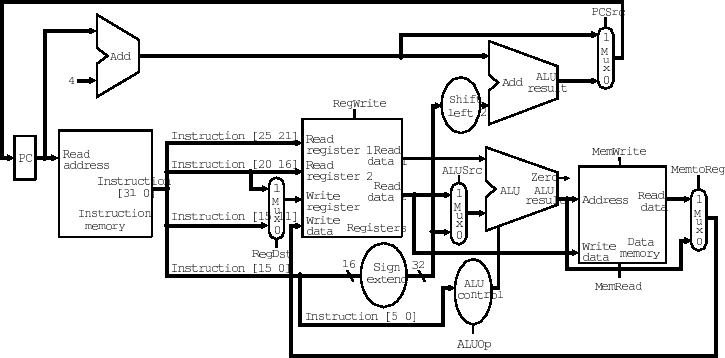
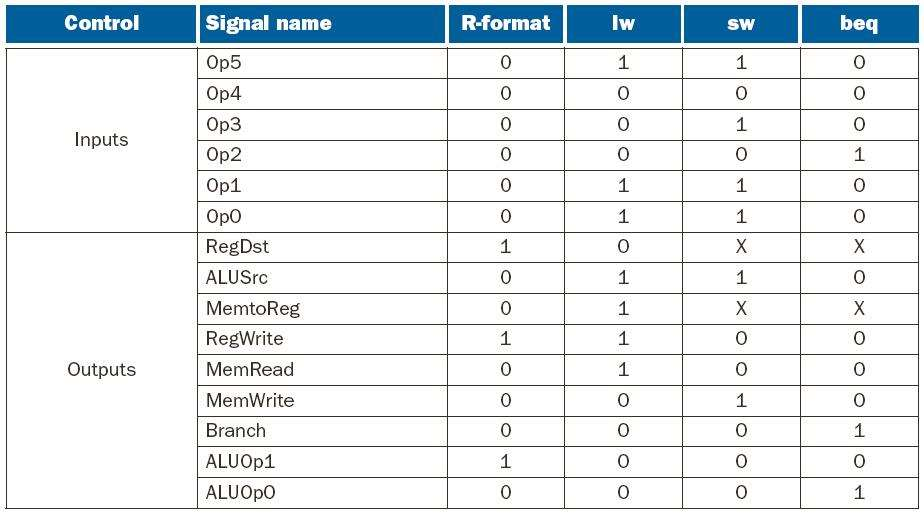
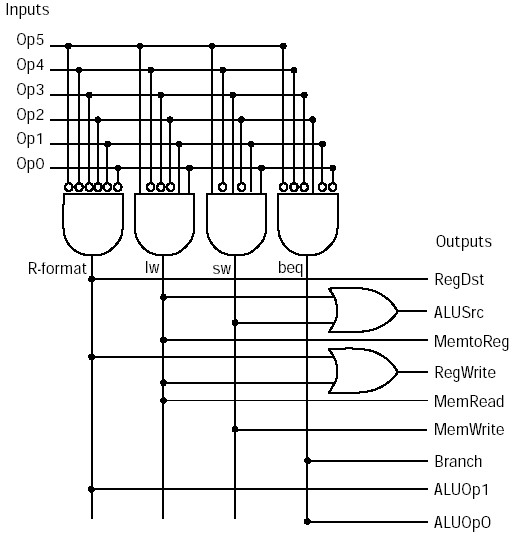
Single Cycle Control
RegDst Select destination register
RegWrite Specify if the destination register is written
ALUSrc Select whether source is register or immediate
ALUOp Specify operation for ALU
MemWrite Specify whether memory is to be written
MemRead Specify whether memory is to be read
MemtoReg Select whether memory or ALU output is used
PCSrc Select whether next PC or computed address is used
Execution of an R-format Instruction
add $t1m $t2m $t3
-
Fetch instruction and increment PC.
-
Read two registers ($t2 and $t3) and generate control
signals in the main control unit. -
ALU operates on the data, using the function code.
-
ALU result is written into $t1.
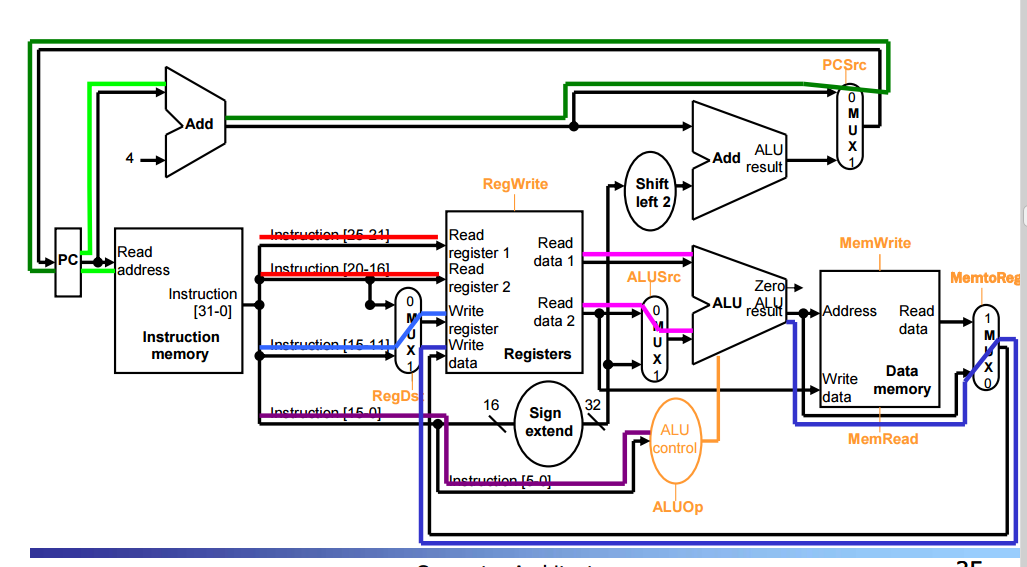
시그널은 다음과 같다
RegDst 1 to select Rd (Rd를 고르기 위해 1)
RegWrite 1 to enable writing Rd (Rd를 쓰기위해 1)
ALUSrc 0 to select Rt value from register file (Rt를 레지스터 파일에서 선택하기 위해 0)
ALUOp OP (Op에 따라 다른 시그널)
MemWrite 0 to disable writing memory (메모리에 쓰지 않기 위해 0)
MemRead 0 to disable reading memory (메모리 리드를 하지 못하게 하기 위해 0)
MemtoReg 0 to select ALU output to register (ALU 결과를 레지스터에 넣기 위해 0)
PCSrc 0 to select next PC (다음 PC선택을 위해 0)
lw t2)
-
Fetch instruction and increment PC.
-
Read a register ($t2) and generate control signals in the main control unit.
-
ALU computes the effective address by adding $t2 and sign-extended offset.
-
Use the ALU output as the address for the data memory.
-
Write the data from the memory into $t1.
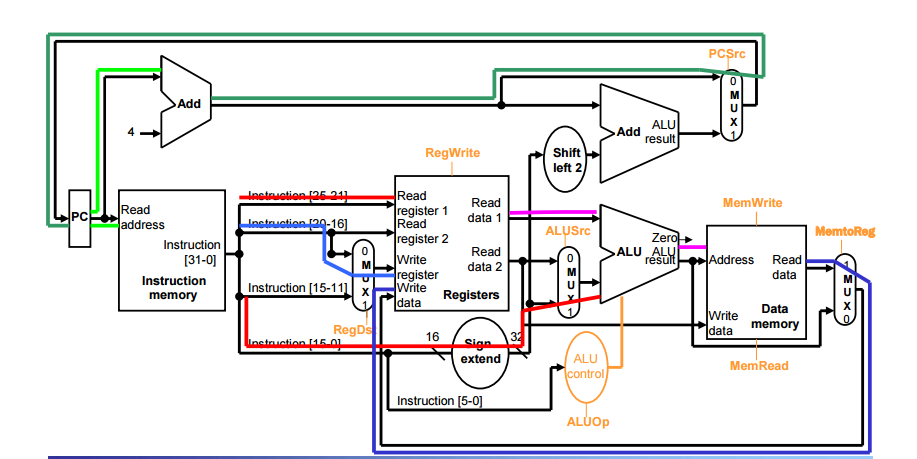
시그널은 다음과 같다
RegDst 0 to select Rt (Rt 선택을 위한 0)
RegWrite 1 to enable writing Rt (Rt를 쓸 수 있게 만들기 위해 1)
ALUSrc 1 to select immediate field value from instruction (immediate 필드에서 값을 가져오기 위해서 1)
ALUOp add (무조건 ALU는 add)
MemWrite 0 to disable writing memory (메모리에 쓰는 걸 막기 위해서 0)
MemRead 1 to enable reading memory ( 메모리 리드를 가능하게 만들기 위해 1)
MemtoReg 1 to select memory output to register (메모리 출력을 레지스터에 넣기 위해 1)
PCSrc 0 to select next PC (다음 PC 선택)
sw의 경우 다음과 같다
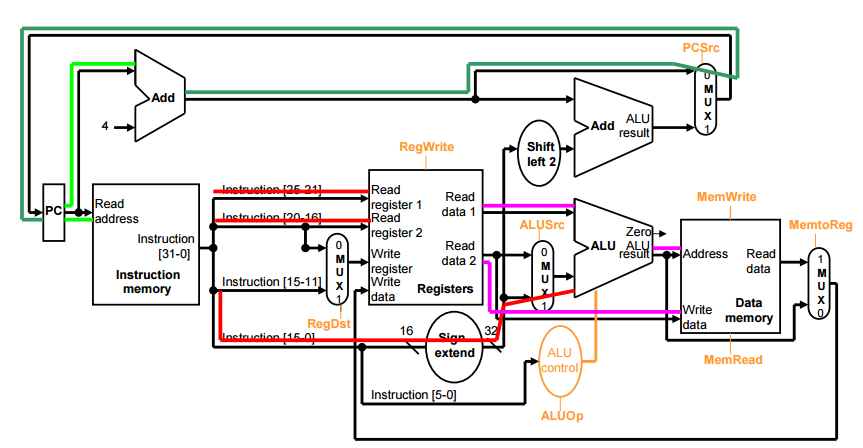
시그널은 다음과 같다
RegDst x (don’t care)
RegWrite 0 to disable writing a register
ALUSrc 1 to select Rt value from register file
ALUOp add
MemWrite 1 to enable writing memory
MemRead 0 to disable reading memory
MemtoReg x (don’t care)
PCSrc 0 to select next PC
beq t2,offset
-
Fetch instruction and increment PC.
-
Read two registers ($t2 and $t3) and generate control signals in the main control unit.
-
Subtract the two data from registers. And compute branch target address by adding (PC+4) and signextended and shifted-left offset.
-
Decide which adder result to store into the PC using the Zero result from ALU
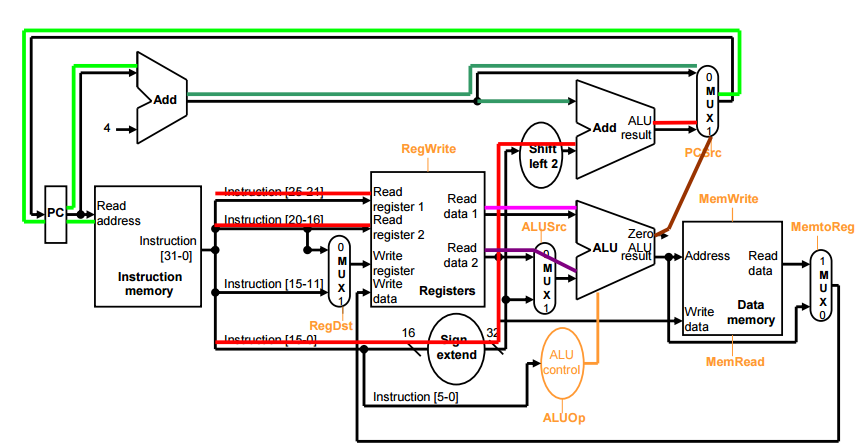
시그널은 다음과 같다
RegDst x (don’t care)
RegWrite 0 to disable writing a register (레지스터에 쓰기를 막기 위한 0)
ALUSrc 0 to select Rt value from register file ( rt값을 레지스터 파일에서 선택하기위해 0)
ALUOp sub (무조건 Sub)
MemWrite 0 to disable writing memory(메모리에 쓰는것을 막기위해 0)
MemRead 0 to disable reading memory (메모리를 읽는것을 막기위해 0)
MemtoReg x (don’t care)
PCSrc zero to select next PC
Signal summary

ALU Control
MIPS의 경우, 크게
- R_Format
- lw sw
- branch
3 가지로 나뉜다.
이들은 OP코드로 구분 할 수 있는데
- ALU연산의 OP코드는 000000으로 고정되어 있다.
- lw, sw 의 경우 op코드만 봐도 lw 인지, sw인지 구분이 가능하다. 따라서 ALU 명령어에 따라서 lw, sw 는 add, branch는 sub로 ALU를 고정한다.
나머지 R 포맷은 각각 맞는 ALU를 사용한다 .
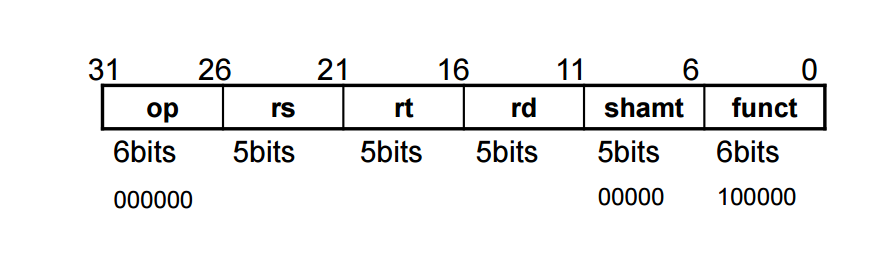
명령어에 따른 ALUOP정의
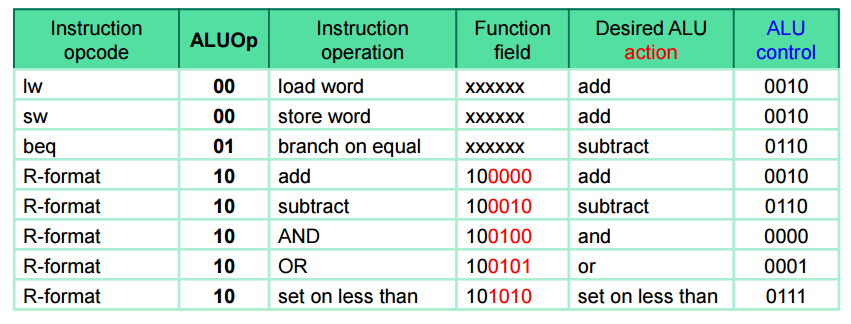
00 – 0010 (ADD)
01 – 0110 (SUB)
R FORMAT – 10을 주고 5개 연산(add, sub, and, or ,slt)중에 뭔지 모름 -> 이떄 FUNCT 비트를 넣어서 5개 중 하나를 만들어냄
명령은 다음과 같다
0000 - AND
0001 - OR
0010 - ADD
0110 - SUBTRACT
0111 -SLT
1100 - NOR
1x 0010 add
1x 0110 sub
1x 0000 and
1x 0001 or
1x 0111 slt
Implementation of ALU Control
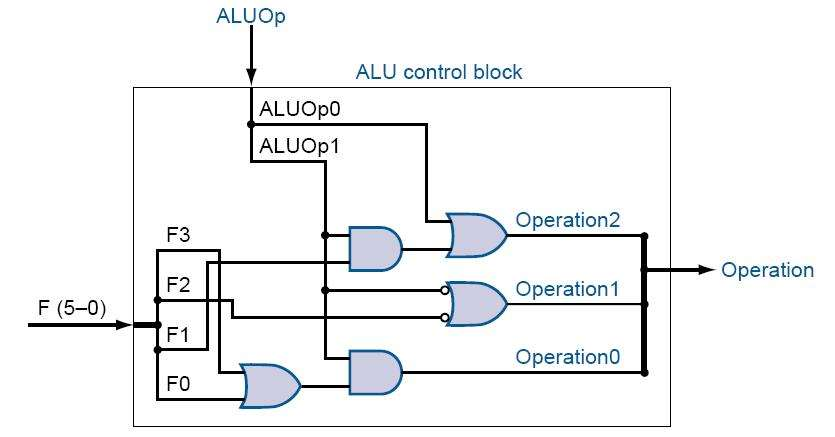
00 | 0000 에서 맨 오른쪽부터 operation 0 1 2 3 (3 2 1 0) 임
Operation3 = 0
Operation2 = ALUOp0 + ALUOp1 · F1
Operation1 = ALUOp1' + F2'
Operation0 = ALUOp1 · (F0 + F3)
r포맷의 경우 000000으로 게이트를 나오면 1이 나옴
unconditional branch jump는 다른 것 볼 것 없이 op코드만 보고 판단 후 무조건 target address 로 jump하기 떄문 (shift left 2 하고 무조건 jump address 로 가서 다시 pc로 들어가는 과정)
Final
Detail
Jump Operations
점프의 경우 32개의 비트중에서 앞부분 op를 제외하면 jump target address로 바로 jump하는 구조를 가지고 있다.
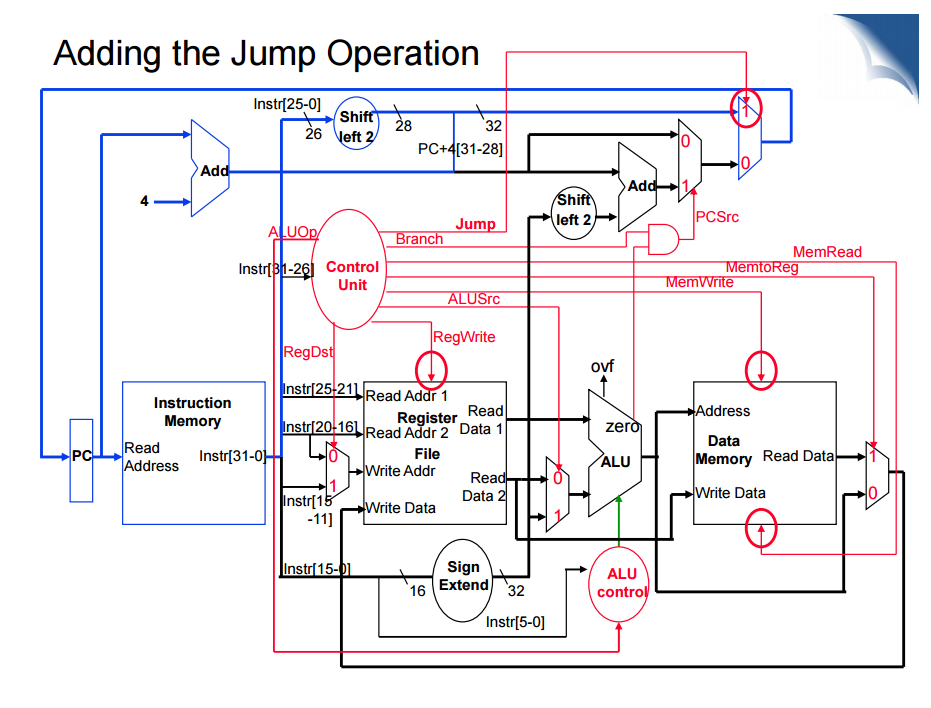
위 그림에서 파란선으로 구성된 부분이 jump 부분이다.
기존의 pc데이터패스에 mux를 추가해서 jump signal이 있다면 jump명령을 실행해서 mux를 작동시키도록 함
점프명령어의 하위 26비트를 전부 왼쪽으로 2비트씩 자리이동 한 후, PC+4의 사우이 4비트를 왼쪽에 덧붙여서 32비트의 점프주소를 만든다.
나머지는 없어도 되는 유닛들이라 전부 don’t care 들어감
왜 단일 사이클은 사용되지 않는가?
각각의 명령은 다음과 같은 시간이 걸린다.
Instruction and data memory (4ns)
ALU and adder (2ns)
Register file access(1ns)
r타입 같은 경우 4 1 2 0 1 8ns 정도 소요
load 4 1 2 4 1 12 ns
store 4 1 2 4 0 11 ns (load 와 다르게 데이터를 쓸 시간이 들지 않고 read 에서 주소까지 같이 읽어와서 시간이 적게 들어감)
beq 4 1 2 7 ns 메모리에 쓸 시간이 필요가 없음
jump 4 4ns 읽고 바로 pc 업데이트
데이터를 메모리로부터 레지스터로 읽어들이는 lw명령어라고 할 수있다 .
Why single cycle impementaion is not used ?
대부분 이렇게 쓰지 않고 멀티사이클로 실행함
Cpi = 1 but 성능을 올리려면 clock cycle을 줄여야함, 하지만 Clock cycle은 가장 긴 데이터페스가 실행가능하도록 구현되어야함 (lw)
장점 : 간단하고 이해하기 쉽다
단점 : 느리다 (lw에 맞춰져있어서 시간이 낭비되고 있다)
현재 우리가 수행하는 명령은 Instructuion 은 25% lw/ 10% sw/ 45% r format/ 15% beq/ 5% j 로 구성되어있다.
합해서 계산해보면, 40%는 처리, 30%는 lw sw, 30% branch 이런식으로 사용되고 있다.
lw sw branch 의 60% 는 cpu의 연산과 관련없는 이동과 flow로 이루워졋음
variable execution time(가변 클락 사이클)을 사용하면 사용 비율에 맞춰서 클락사이클을 줄 수 있지만, 실제로는 이건 굉장히 어려워서 무조건 fixed로 하게 만들어두었다.
Cpu execution time
각각 실행시간이 다르지만 fixed length 떄문에 가장 긴 걸 선택해야한다. 즉, 가장 긴 lw에 맞춰놓아서 다른 명령들은 이를 수행하면서 시간을 손해보게 된다.
따라서 멀티 태스킹을 하는 멀티 사이클을 이용해서 시간낭비를 줄이고 작업의 효율화를 노린다.
