IO 시스템
프로세서 – 메모리 - IO 시스템의 구성
IO장치는 굉장히 느린 장치
연결성 이슈
효율성 이슈
키보드 마우스 프린터는 느리지만
그래픽 네트워크 디스크는 빠르다
이러한 다양한 장치를 IO Subsystem에 연결해서 써줘야한다
IO performance issue
cpu와 메모리 사이 성능 측정
throughput, latency
IO도 마찬가지로
throughput – IO 하면서 데이터를 주고받을 때 단위시간당 주고받는 데이터의 양
-->높아지면 좋음
latency – 단일 오퍼레이션이 완료되는데 걸리는 시간
-->낮아지면 좋음

그림에서는 connection이 하나의 bus 형태로 되어있지만 실제로는 hierarchy 구조로 되어있는 bus임
IO의 구성
현재 선택되어있는 CPU와 메모리에 맞게 어떻게 IO구성을 할 것인가?
1. IO 시스템에서 가장 제약적인 부분을 찾는다
- processor memory
- underlying interconnection
- IO controller
- IO device
어디서 bottleneck이 오는지 확인하고 이에 맞게 조정을 해야한다
예시
CPU 입장
디스크 io 한번당 20만번 cpu 작동
cpu는 초당 3억개를 처리 가능 함
OS 레벨에서는 10만개가 필요함
즉 유저레벨에서 disk io를 하려면 운영체제 10만 + 디스크 20만 따라서 30만개
CPU는 초당 3억개를 수행함
따라서 초당 DISK IO를 만개 실행할 수 있음
메모리의 transfer rate = 1000mb / s
메모리의 bandwidth를 가지고는 총 15625개의 IO 가능
DISK IO 컨트롤러는 여러 개를 붙일 수 있음
디스크가 하나의 IO를 처리할 때 걸리는시간은
6ms + 64kb(75mb / s) = 6.9ms
하나의 디스크당 1초에 146개의 io
최대 69개를 넣을 수 있다. 10개의 SCSI 컨트롤러
IO controller 10 (SCSI Controller)
1 contorller 7 disk
IO system interconnect isssue
일반적으로 bus(shared link)를 이용함
장점
확장성이 높아진다
버스구조를 쓰면 표준화된 인터페이스를 가지고 새로운 디바이스가 시스템에 연결되거나 제거되기가 쉽다
낮은 비용 – 공유를 해서 비용이 적게 든다
단점
충돌 – 버스 bandwitdth 가 io의 최대 throughput을 제한한다. 공통된 곳에 물려잇고 공유하기 때문
버스의 최대 속도는
The length of the bus
The number of devices on the bus
가 제한하게 된다.
Bus Charteristic
control line
cpu가 master 입장에서 slave 상태의 버스를 제어함
요청 같은 signal을 주고 받음
무슨 정보가 데이터 라인에 있는지 가리킴
data line
컨트롤 라인에 의해 선택된 device에 data line으로 정보를 보냄
버스의 삽입
프로세스 메모리 버스 (고성능)
- Short and high speed 짧고 고성능
- Matched to the memory system to maximize the - memory-processor bandwidth 최대화 시킬수 있는 방향으로 설계
- Optimized for cache block transfers 캐시 블록 전송 최적하
IO버스 (장치들 사이, 케이블을 씀 )
- Usually is lengthy and slower 길고 느리다
- Needs to accommodate a wide range of I/O devices 다양한 장치를 포함할 수 있어야 한다
- Connects to the processor-memory bus or backplane bus 프로세스-메모리 혹은 백플레인과 연결
BackPlane
- PC밖으로 케이블을 뽑아서 외부에서 연결할 수 있도록 만든 것
작동방식
synchronous bus (processor-memory)
클락을 가지고 그 클락에 맞게 작동하도록 고정
클락에 맞춰서 작동하면 되기에 로직이 간단하고 매우 빠르다
다만 길이가 길어지면 clock skew(작은 단위의 클락 뒤틀림)이 발생한다 --> 동기화가 맞추기 어려워진다
asynchronous bus (i/o buses)
handshaking과 contorl line 필요
대신 느림
Handshaking Example
command line에 read request를 싣음
받았다는 신호를 ack에 실음
CPU는 ACK를 받았고 이를 없애버림
이게 없어지면 handshake를 통해 알게되는 것
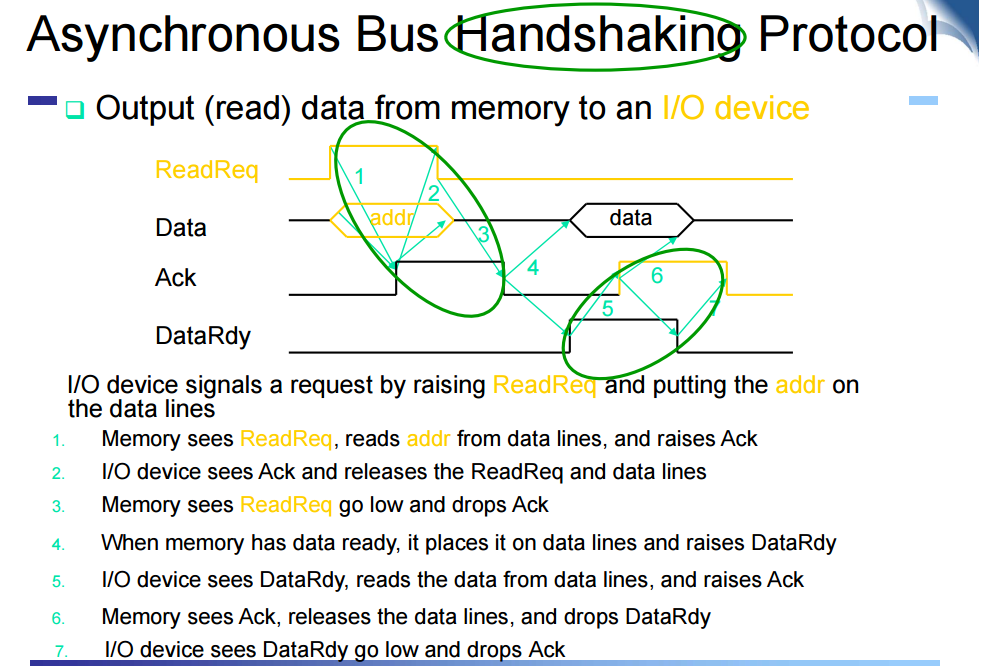
- Memory sees ReadReq, reads addr from data lines, and raises Ack
- I/O device sees Ack and releases the ReadReq and data lines
- Memory sees ReadReq go low and drops Ack
- When memory has data ready, it places it on data lines and raises DataRdy
- I/O device sees DataRdy, reads the data from data lines, and raises Ack
- Memory sees Ack, releases the data lines, and drops DataRdy
- I/O device sees DataRdy go low and drops Ack
Arbitation
버스에는 여러 개의 device가 물릴 수 있음
누가 무엇을 받을지 구분하고 인식하는 논리적인 동작이 필요함
bus에 물린 device 에 대한 동작 중계 장치 = 아비터
여러 개의 디바이스가 버스를 동시에 쓰려고 하는 경우 중재의 역할을 함
bus arbitration 방식
- 여러 디바이스가 경쟁적으로 하기 때문에
- 우선순위
- 공정성 유지
리퀘스트가 충돌이 날 수 있음 충돌이 발생 하면 버스가 바쁜지 안바쁜지 체크를 해서 쉬었다가 나중에 실음
DAISY CHAIN

디바이스들은 ACK 체인으로 묶여있다
자기 request가 아니면 체인들이 다음 device로 넘겨준다
간단하다. 하지만 공정성이 확보되지 않고 버스 스피드가 느리다
Centralized paralell arbitation
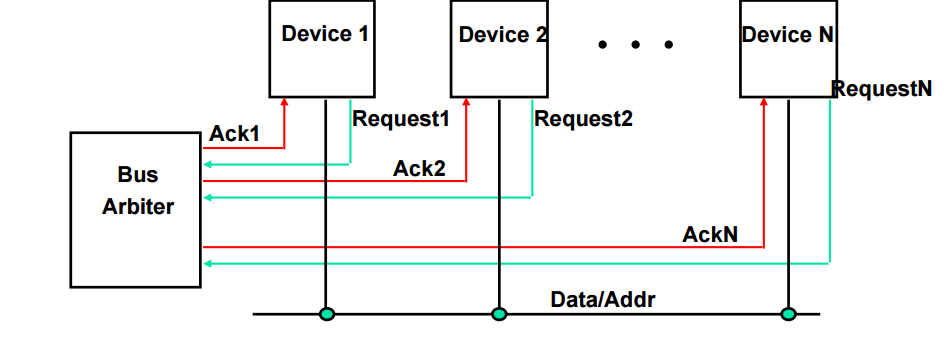
버스 아비터가 각각 개별 디바이스에 전부 다 처리한다
장점 :
유연성이나 공정성이 뛰어나다 (전부 다 하니깐)
단점 : 구조 자체가 포트가 많아지고 포트관리 컨트롤 로직이 들어가야해서 훨씬 복잡하고 어려움
bus bandwidth determinates

버스 자체도 성능 스펙이 정해져있음
스펙이 다 정해져있고 이러한 스펙에 맞도록 버스가 설계되어있다

north bus에는 고성능south 에는 저성능, 다양한 장치등이 몰려있다
Communication of I/O Devices and Processor
프로세서가 IO에 소통 방식
Special IO instruction
- 특정 디바이스에 대한 명령어가 존재 --> 프로세서가 복잡해짐
memory – mapped IO( 많이 쓴다 )
- 레지스터 영역에 대한 map이 cpu에 있고 cpu가 여기다가 read write 명령어를 통해 커뮤니캐이션 함
--> CPU입장에선 쉽게 IO 디바이스 통제 가능
IO가 프로세서에 소통 방식
polling
interrupt driven io
io는 자기작업을 하고 있다가 interrupt를 통해서 요청을 하면 device 가 processor에게 시그널을 보낸다 --> Io 장치가 있거나 말거나 신경 쓸 필요가 없지만 이 interrupt를 처리하려는 추가적인 로직이 필요함
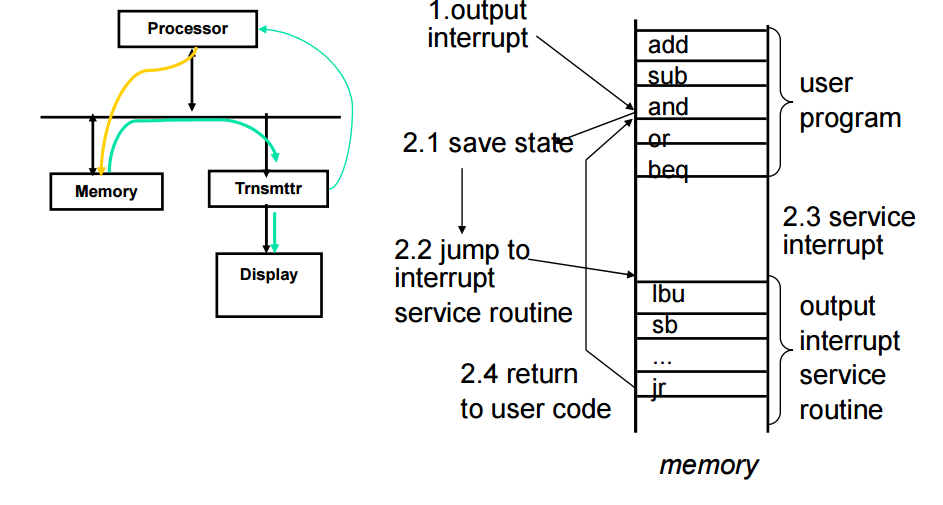
-
작업중에 키보드를 딱 치면 키보드가 interrupt를 보냄
-
작업이 멈춤
-
cpu는 1. 자기상태를 저장 2. 인터럽트를 처리하기위한 인터럽트 서비스 루틴으로 감 (별도의 코드로 작성되어있음) 3. 서비스 인터럽트 4. 유저 코드 반환
방해동작을 통해서 일반적인 IO를 처리함
비동기적인 방식임
DMA
프로레서 없이 데이터 IO 디바이스와 메모리간의 데이터 전송시 사용되는 방식
- transfer가 dma 트랜스퍼를 초기화시킨다
IO 주소, 메모리 주소 목적지, 바이트 양
2. IO DMA Controller 는 그걸 받아서 그 transfer를 발생
- interrupt를 받아서 transfer가 끝남을 알림
DMA Issue
메모리로부터 IO디바이스로 CPU 관여없이 바로 이동시키기 떄문에 CPU 외부에 있는 Cache 데이터의 경우 어떻게 되는가?
-
read의 경우 캐시의 최신데이터가 아니라 메모리 최신을 읽게 되어버림 그러면 프로세서는 캐시데이터를 없애버림
-
write의 경우 캐시가 최신데이터가 될 수 있도록 써줘야함 (wrtie through에서는 같아서 상관없지만 write back에서는 캐시데이터를 써주고 써야함)
이러한 문제를 어떻게 해결하는가
1. Read의 경우에는 전부 invalidate
2. Wrtie의 경우에는 전부 invalidate
--> 일단 캐시를 전부 invalid 처리함 (flushing)
