Parallel Processor
왜 병렬 프로세서를 쓰는가
클럭 사이클을 줄이면 CPU의 수행속도는 올라간다.
하지만 Moore's law에 따라 반도체의 집적도가 점점 올라가면서 양자의 영역으로 줄어들고 있고, 이에 더 이상 클락사이즈를 올릴 수 없게되었다.
따라서 성능향상을 위해서는 병렬화가 핵심적이게 되었다.
하드웨어 병렬화
- 싱글 프로세서 cpu에서 멀티 프로레서 cpu로 그리고 멀티 코어 cpu로 그리고 many core로 거듭난다.
소프트웨어 병렬화
- 프로그램을 병렬화, 소프트웨어의 병렬화
우리는 병렬 프로그램을 작성해야한다
serial sqeuential - parallel
이 두 부분을 어떻게 잘 나눌것인가?
또 paralell 부분의 job을 어떻게 잘 나눌것인가 ?
job을 나눠서 실행했으면 결과를 주고받아서 처리해야한다.
암달의 법칙
Example: 100 processors, 90× speedup?
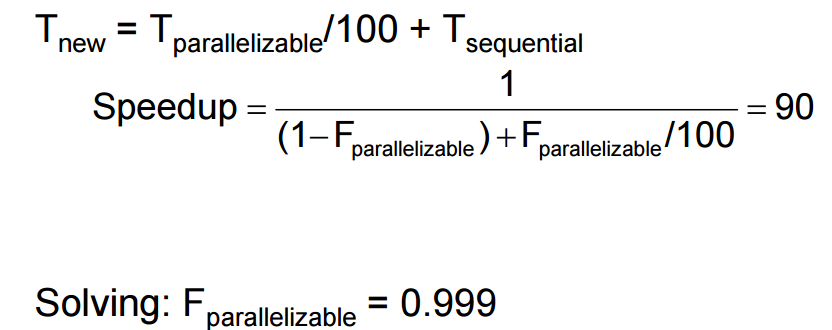
성능을 향상 시킬 수 있는 p% 부분이 S배까지 증가했다면, 새로운 시스템에서의 시간은
T new = 1 / {(1-p) + p / s}
100개의 프로세서 90배의 스피드업을 하려면 몇 개를 병렬화 해야하는가?
99.9% 가 병렬화 되어야만 90%의 속도향상이 있다
이 암달의 법칙에 따르면, 얼마나 paralell 한 부분을 잘 만드느냐에 따라 성능향상이 된다.
즉, parallel 파트에서 Job을 얼마나 잘 분할하는가
프로세서는 늘어도 사실 크게 성능향상이 안된다.
매트릭스 사이즈가 늘어야한다는것을 알 수 있다.
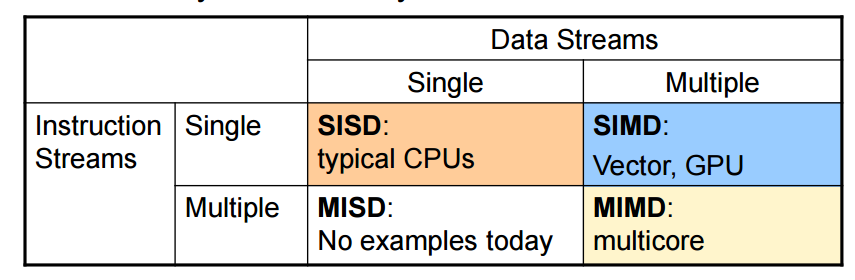
Concurrency Parallelism
동시성과 병렬성을 가진다
여러개의 프로세서(코어)를 올린다던가
하나의 코어에서도 병렬성을 가져야한다
공유데이터들에 대한 데이터 주고받기는 어떻게 할 것인가?
Instruction level parallesim
- SuperSclar
- 병렬성을 높이기 위해서는 명령어 수행 단계에서 여러개를 수행할 수 있도록 연산을 동시수행할 수 있는 function 유닛을 여러 개 만들어준다
다른걸 연산하는 시간동안 또 다른것도 연산 가능하게 만들어버림
- 병렬성을 높이기 위해서는 명령어 수행 단계에서 여러개를 수행할 수 있도록 연산을 동시수행할 수 있는 function 유닛을 여러 개 만들어준다
- Very Large Instruction Word
- 명렁어 자체가 한번에 동시에 4~8개 이런식으로 가져와서 실행시킬 수 있는 아키텍쳐
디펜던시나 스톨이 있으면 같이 실행 못함
이런 경우 paralell 이 아니라 sequential 파트임
- 명렁어 자체가 한번에 동시에 4~8개 이런식으로 가져와서 실행시킬 수 있는 아키텍쳐
Thread level parallelism
single processor에서 혹은 Multi processor에서도 사용 (쓰레드를 독립적으로 돌림)
CPU를 여러 개 두고 쓰레드를 병렬화 할 수도 있고
혹은
processor안에서 쓰레드를 정렬하거나 하는 방식을 추가해서 쓰레드 병렬화 시도
레지스터를 여러개 가짐
멀티 스레딩
register와 memory가 작업을 수행하고 그것을 병합하는 과정
현재 쓰레드의 상태를 저장하고 백업하고, 다른 쓰레드에 대해서 restore 하고 다시 쓰고를 반복한다.
이 과정이 엄청 오래걸려서, 빠르게 switching 해주기위해
pc, register같은걸 여러 개 만들고 동시에 수행함
Fine-grain multithreading
- Switch threads after each cycle
- 사이클마다 스위칭
Coarse-grain multithreading
- Only switch on long stall (e.g., L2-cache miss)
- 장기 스톨(메모리 미스)같은것에서만 스위칭
SuperScalar Simultaneous MultiThreading
수퍼스칼라는 하나의 Instruction으로 동시에 실행 가능함
동시에 멀티쓰레드가 돌아가게 할 수 도 있다.
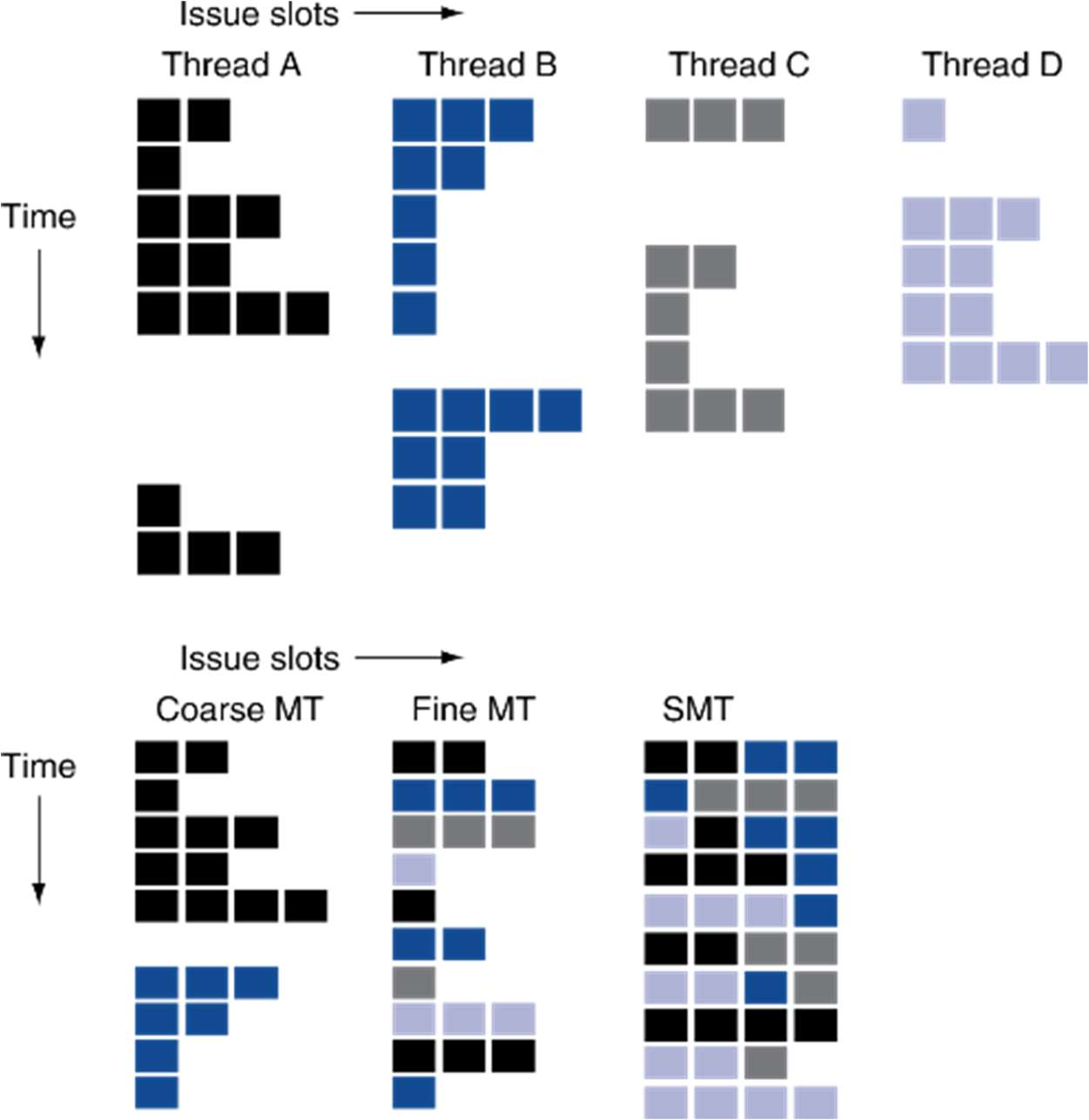
ILP
멀티플 이슈가 가능한 아키텍쳐
최대 4개가 가능하도록 하는 아키텍쳐
쓰레드 내부에도 여러 개가 돌아가도록 되어있음
SMT가 이를 이용함
Shared Memory
SMP : Shared Memory Multiprocessor
Symmetric multi processor
프로세서가 여러 개 있을떄, 이들이 하나의 Physical address를 사용한다
이때, 어떤 이슈들이 있을까?
1. 가까운 메모리가 있을 수 있고 먼 메모리가 있을 수 있다.
2. Access time 이 동일할수도 있고 각 메모리 위치마다 달라질수도 있다
UMA – Unifrom memory Access – 시간이 동일해서 상관 없음
NUMA – Non uniform memory Access – 각각 시간이 달라져서 조절이 필요하다
병렬 프로그램에서는 파티션을 나누고 coordiantion, communication이 중요하다
클러스터, 혹은 commnication web같은 경우도 병렬 프로세서라고 할 수 있다
Shared Memory에 대해서
분리해주면 independency가 생김
만약 여러 개의 프로세스가 하나의 메모리를 쓰면 동기화가 필요함
동기화 문제
count ++ , count -- 문제
S0: producer execute register1 = count {register1 = 5}
S1: producer execute register1 = register1 + 1 {register1 = 6}
S2: consumer execute register2 = count {register2 = 5}
S3: consumer execute register2 = register2 - 1 {register2 = 4}
S4: producer execute count = register1 {count = 6 }
S5: consumer execute count = register2 {count = 4}
업데이트 전에 다른 쓰레드에서 가져가서 레지스터 값을 바꿔버리면 문제가 생긴다
따라서 원자성을 보장시켜주는 프로세서 아키텍쳐가 필요하다.
동기화를 풀기 위해서는 atomic한 read/write 메모리 오퍼레이션 필요하다
메모리 주소를 lock 시킨다
다른 명령어가 가져가서 링크를 부수거나 하지 못함
cache coherence
write back 성능이 더 좋긴하다
하지만 동기화 문제가 생긴다.
wtire through, write back 둘다 동기화 문제가 생긴다.
migration = 업데이트 하는 순간 바로 다른 프로세서에도 넘긴다
writeback의 경우 업데이트 되는 순간 캐시에 그 값을 알려주고 캐시가 최산상의 값을 알도록 한다.
programming model : Message Passing
동일한 Address가 아니라
서로 떨어진 다른 어드레스를 보는 interconnection architecture가 있을 수 있다.
IPC, PIPE. File, Socket
느슨하게
이제는 loosely 하게 묶인 것들을 보겠다
웹서버
클러스터 시스템을 만들고 dispatcher라고 하는 서버를 두고 client connection이 들어오면 job을 distribute 한다.
각각의 클라이언트의 connection이 독립적인 일이 된다.
서비스 플랫폼에 분리시켜서 일을 처리한다
문제점:
- 메모리 이슈라거나 dependent 이슈가 발생한다.
- 프로그램 자체를 어덯게 administration 할거냐
- low interconnect bandwidth
이러한 성능적,관리적 이슈 발생 가능
Grid computing
Grid Computing
- 연결된 모든 컴퓨터에 job을 할당시킴
- SETI@home
programming model : SIMD
data에 대해서 multiple 데이터를 가지고 작동함
graphic, Media
픽셀단위로 연산하는 경우가 많아서
데이터를 픽셀단위로 두고 반복적으로 가져오게 된다
따라서 한번에 데이터를 4~8개 들고와서 같이 계산해주는게 효율적이다
예를들어 32비트를 4번 한다고 할 때, 32비트를 4번 연속적으로 하는것보다 128비트를 한번에 하는것이 좋다.
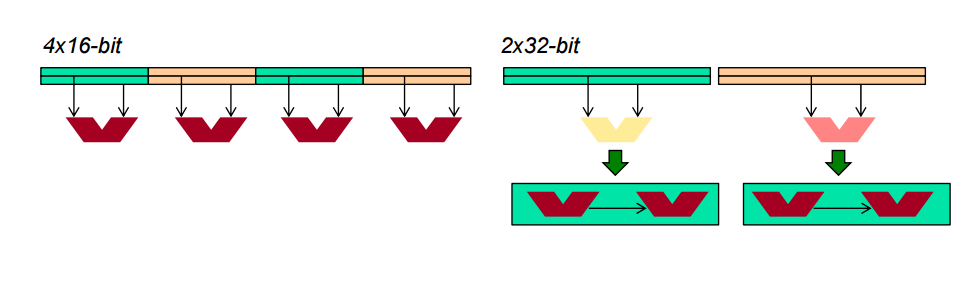
SIMD --> MIMD(multiple thread, multiple data)
GPU
– 현 병렬처리 아키텍쳐중에 가장 진화된 형태
Early Video cards
- frame buffer (디스플레이할 데이터를 담고있는 버퍼)
GPU architecture
Highly data paralell
연산을 어떻게 할지, 연산결과를 어떻게 메모리에 받아서 이동시킬 것인지
OpenGL, CUDA 같은 언어들이있음
CUDA Thread Block
이미지를 잘라서 반복적으로 한다
Vector Processor
백터 프로세서
백터 = array
레지스터에 array 형식으로 동일하게 명령을 하나로 병렬적으로 처리할 수 있는 단위
이런 백터 기반을 연산 할 수 있는 것이 백터 프로세서
mips를 백터로 확장한 버전을 보면
interconnection network에는 다양한 형태가 있다
각 프로세스나 클러스터를 어떻게 연결시켜 줄 것이냐
정리
아주 구체적인 레벨의 설계나 구현은 아니지만
지금까지의 프로세서 아키텍처들을 기반으로 어떻게 병렬화시켜서 app이나 프로그램을 빠르게 수행할 수 있게 만드는지, 어떻게 진화해왔고, 다양한 관점에서 이러한 이슈들을 다루고있다.
