Memory Hierarchy
도입
컴퓨터의 기본 구조는 메모리에서 코드를 가지고오고 LW, SW연산을 통해 메모리의 데이터를 저장하거나 읽어오는것이다. 주소에 대한 읽기 쓰기가 실행된다.
하나의 프로그램이 모든 논리주소체계를 가지고 있지 않다. 각자 자신만의 Virtual Address를 가지고 프로그램을 실행하는데, CPU입장에선 자신만의 주소로 접근이 가능해보이지만, 실제로 시스템에서는 Physical Address를 사용한다.
즉 이런 메모리를 사용하는 시스템 입장에서는 메모리를 효율적으로 사용해야한다.
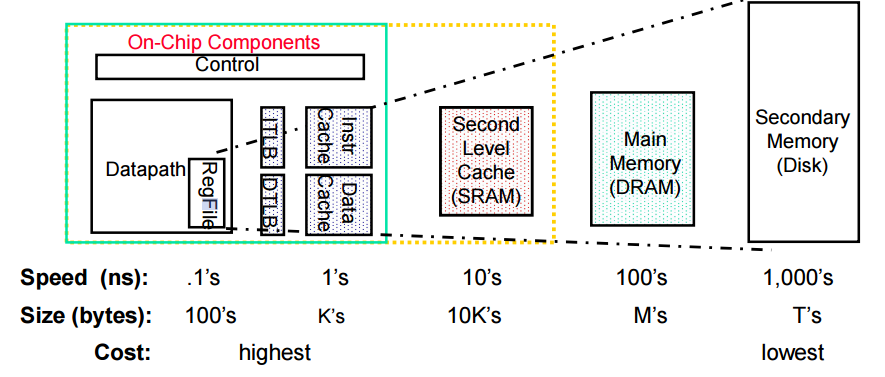
프로세서 입장에서는 ALU연산대상은 레지스터이고, 레지스터도 하나의 저장소 top hierarchy이다.
CPU입장에서 메모리도 매우 느린 저장장치이고 그 위에 있는 storage는 cpu가 직접 접근하지 않는다.
따라서 이러한 접근속도를 해결하기 위해 cache를 둔다.
상위레벨의 소자가 빠르게 접근할 수 있도록 하위레벨 데이터의 일부를 미리 가져다두는 것을 캐시라고 부른다.
Random Access Memory RAM
바이트단위로 랜덤접근을 한다.
Dynamic RAM
메인메모리 (용량 훨씬 높음) 느림
Static RAM
캐시메모리 (용량은 낮으나 속도 빠르고 비쌈)
성능 비교
Dram/Sram = 4 to 8
cost cycle time: sram drma ratio t8 to 16
스토리지 영역에서는 nand flash memory같은 비휘발성 메모리가 활성화되어 있다.
성능 평가 요소
latency : 한 워드에 접근하는 시간
접근시간 레이턴시 : 한 워드를 읽거를 쓰거나 쓸 때, 한 리퀘스트의 시간
사이클 타임 : 한 리퀘스트가 끝나고 다음 리퀘스트 시작하기까지의 시간 두 리퀘스트 사이의 시간
bandwidth 광대역 : 단일시간당 얼마나 많은 데이터를 공급하느냐
SRAM
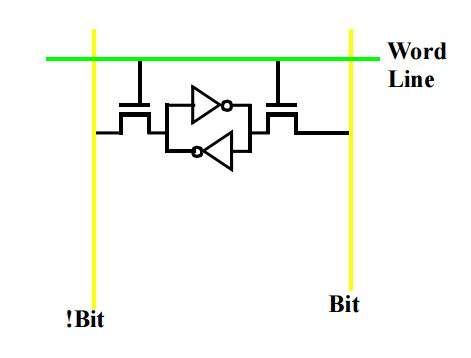
작동 원리
Cell 1 bit를 저장하는 구조.
1 또는 0을 저장한다.
저장을 하고 나면 유지가 된다.
2개의 트렌지스터로 만든다
WordLine에 전압을 넣고, 트랜지스터가 켜지면 bit의 전압레벨을 읽고 !bit는 그 반대값이 된다. 따라서 이를 읽으면 한 셀에 얼마인지 읽을 수 있다.
저장의 경우 WordLine에 전압을 넣고 bit에 ground나 vcc를 넣어준다.
Classic SRAM Organization
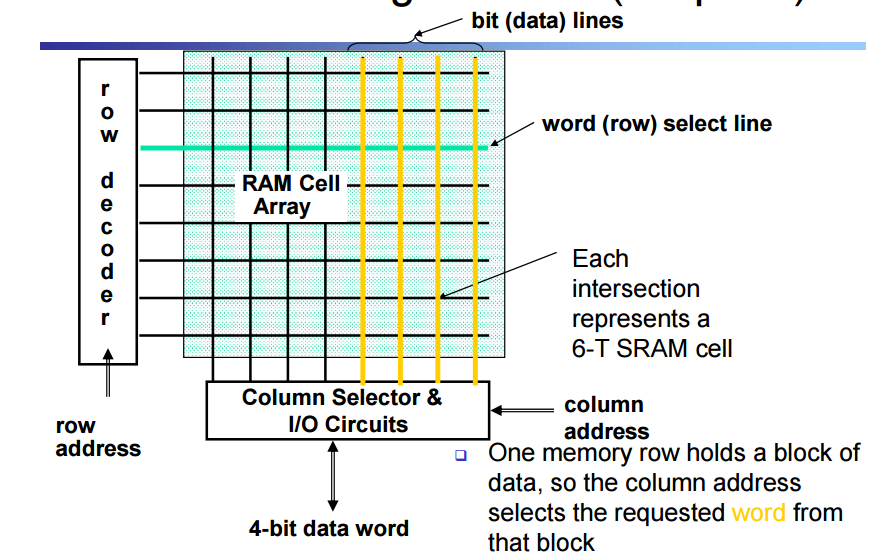
인터섹션을 6개의 tsram으로 구성한 셀이다
워드라인을 4줄 넣으면 4비트 데이터를 읽을 수 있다.
행 8개의 비트가 블락이라는 개념으로 묶임
DRAM
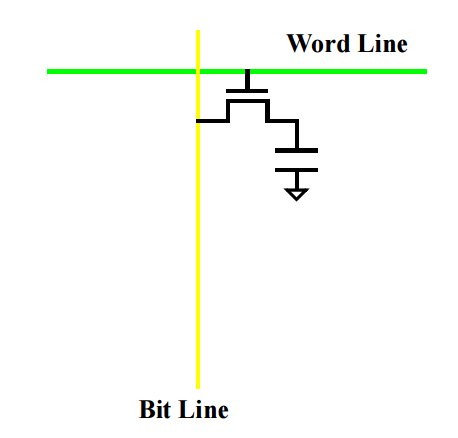
DRAM은 하나의 비트 셀 크기가 SRAM보다 작다
작동원리
1개의 트렌지스터와 capacitor를 결합하여 만들어난다.
capacitor에 전압을 충전하고 사용한다. WordLine에 전압을 걸고 capacitor에 얼마나 충전되었는지 확인하여 1인지 혹은 0인지 판독한다.
Classic DRAM Origanization
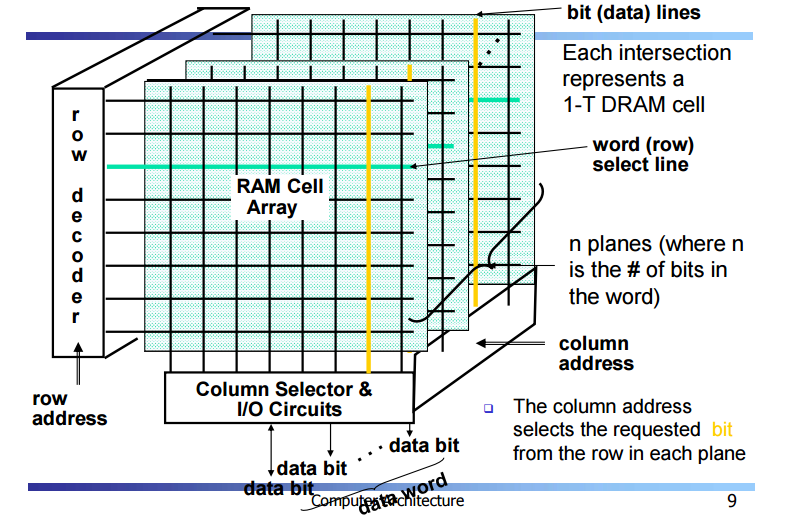
n개의 플랜을 중첩시켜서 6면체 구조로 입체화해서 사용한다
column에 address 가 들어간다 따라서 입체적 column이 block이 된다
snychronous rams
디렘의 주소를 간단하게 주고 burst하고 읽을수 있게 해주는 방식. 일반적으로 읽을때 한 워드씩 읽는 것이 아니라 한번에 많은 데이터를 두고 읽을 가능성이 높다. 따라서 한번에 많은 데이터를 가져갈 수 있도록 만드는 것임.
Page Mode DRAM Operation
구조는 Classic DRAM과 똑같음.
기존에는 한번 읽을 때 row col address를 주면 해당하는 비트를 한번에 읽었음.
해당 방식에선 한번 읽을떄 burst하게 읽게 하기 위해서 만약 4개를 읽겠다하면 row 는 그대로 두고 col address를 4개를 준다. 이러면 4개의 col address bit를 가져갈 수 있음
Synchronous DRAM Operation
row col의 값만을 바로 옆에 붙은 4개를 가져간다. 필요한만큼 자동적으로 증가시키면서 가져간다.
DDR SDRAMs (Double Data Rate SDRAMs)
sdram의 읽기속도를 2배시켰다.
원래 데이터를 읽을 때 클락 사이클과 동기화해서 1클락에서 1데이터를 가져가도록 되어있다. 하지만 ddr에서는 하나의 클락에서 한 클락을 나눠서 0 1 에서 두번가져간다.
하지만 이 과정에서 노이즈가 발생하고 이 노이즈를 줄여주는것이 기술의 핵심이다.
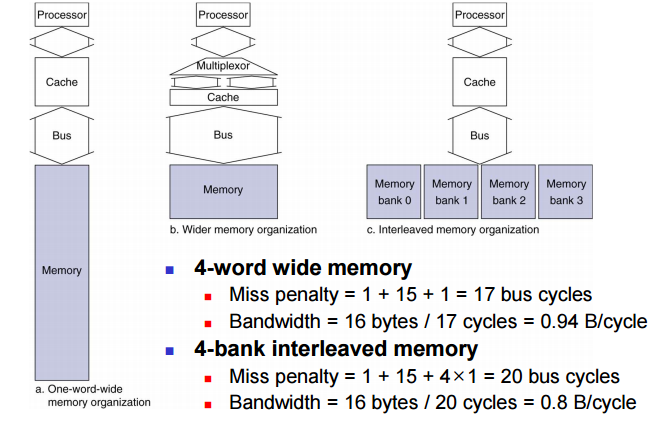
Memory Bandwidth
메모리에 접근하는것은
캐시 하나 존재 > 메모리가 버스로 연결 > 메모리 구조이다.
이때, bandwidth를 늘리면 한번에 이동가능한 메모리양이 늘어난다. bus를 늘리기 위해서는 구조비용이 많이 들게 된다. 따라서 비용없이 늘리기 위해서는 bank라고 하는 개념이 도입된다.
Cache
캐시에 올리기
큰 용량의 데이터들이 메모리에 가득차있다면 어떤것들을 캐시에 올릴것인기?
개념 이해
모든 데이터는 스토리지에 들어있음
프로그램 수행시 필요한 부분만 메모리에 올리게 된다
Principle of Locality
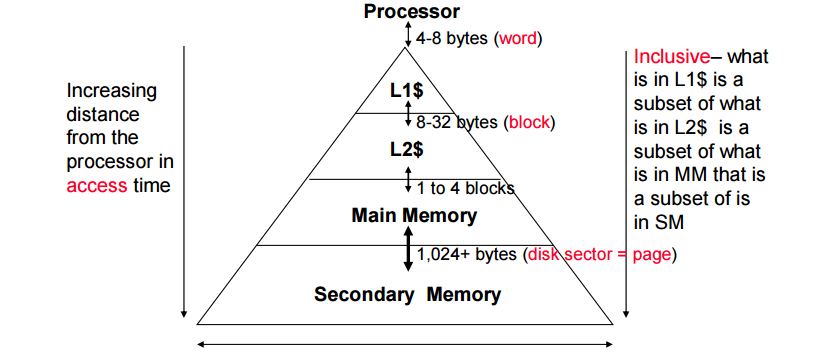
지역성이라는 특징을 이용해서 지역의 상위 저장공간에 저장한다. 즉, 프로그램이 실행될 떄 어드레스 영역의 극히 작은 영역에만 접근해서 실행한다.
temoral locality – locality in time 시간적 지역성
조만간 반복될 가능성이 높은 작동. 루프, 인덱스 같은 것들은 일반적으로 이런 특징을 가진다.
spatial locality – locality in space 공간적 지역성
어드레스 하나에 접근했으면 근접한 부분의 데이터주소에 접근할 가능성이 높다. 연속 명령어, 배열 데이터등이 이러하다.
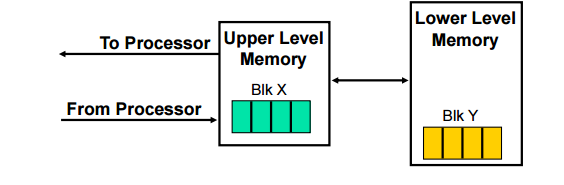
temporal
- 최근에 접근한 데이터들을 유지시켜라
- memory hiearachy 상위권에
spatial
- 현재 읽을 블락과 연속적인 영역의 워드들을 상위권에 유지해라
Terminology
많약 상위레벨에 데이터가 있다면 가지고오면 되지만, 없다면 lower까지 가서 가지고 와야 한다. 이에 성능차이가 많이 나게 된다.
Hit
데이터가 상위레벨에 있는 비율 = hit rate
hit가 되었을 때 데이터에 접근하는 시간을 hit time이라 함
1 – hit rate = missrate
miss panelty
미스가 났을 때 다시 lower 까지 접근해서 상위레벨로 가져오거나 혹은 공간이 없으면 upper를 replace 하는 시간
hit time <<< miss penalty
따라서 미스가 한번 발생하면 cpu입장에서는 maxim한 손해이다.
Memory Management
registers <=> memory
- by compiler (programmer?)
cache <=> main memory
- by the cache controller hardware
main memory <=> disks
- by the operating system (virtual memory)
- virtual to physical address mapping assisted by the hardware (TLB)
- by the programmer (files)
The Cache
캐시에 메모리의 일부분(정확히는 주소)을 캐싱해야한다.
q1. 이 캐시에는 어떤 데이터가 들어가느냐 (메모리는 데이터를 옮길 때 어떤 메모리 주소가 생산되는지를 관리하는가)
q2. 어떤 주소의 데이터가 있을떄 어떻게 캐시에서 찾을거냐
Cache Controller
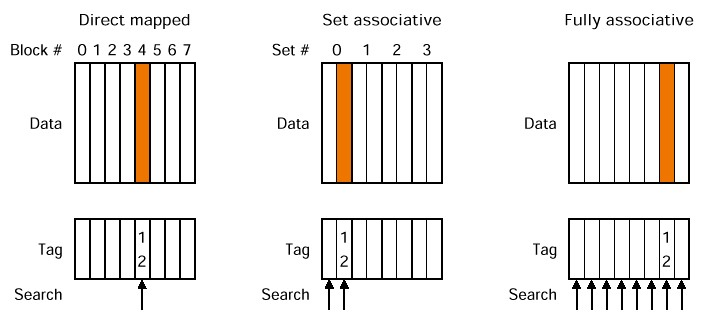
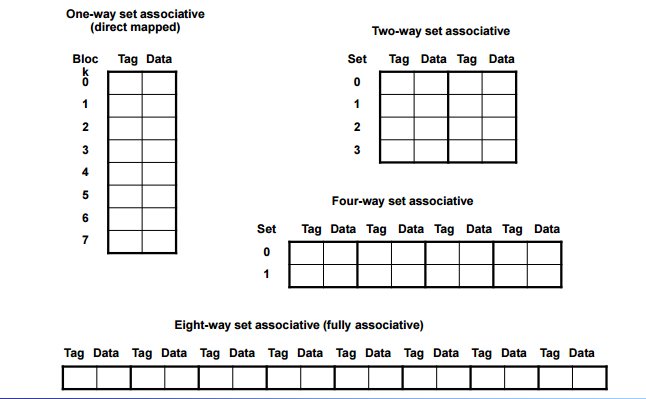
m way set associative map
fully associative map
direct mapped
직접 주소 지정 방식.
전체 메모리를 4개씩 자른다. 0 1 2 3
그리고 동시에 캐시도 0 1 2 3 으로 나누고 각자 번호가 맞는 곳에만 올라갈 수 있도록 설정한다.
캐시에 올라갈 수 있는 블락의 개수 % 현재 메모리 주소 올라가는 자리가 된다.
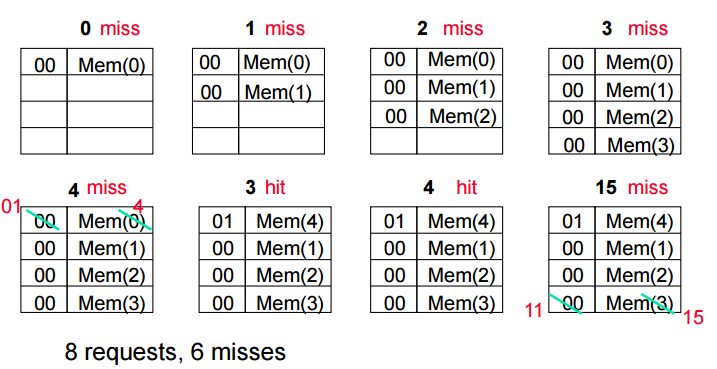
주소를 나눈 몫이 캐시에서 값의 동일여부를 판단하는 판별자가 되고 나머지가 저장위치가 된다.
handling Cache Hits
read hit
cpu가 메모리 데이터를 읽는 것 따라서 그냥 캐시에서 읽으면 되고 캐시의 데이터 변화는 없음
write hit
캐시에 써야하는데 캐시가 보는 주소는 임시주소 직접적으로 메모리에 써야함
cpu는 캐시에만 메모리름 씀 -> 캐시데이터와 메모리 데이터가 달라짐
-
write through
hit 발생 순간 동기화를 해서 일관성을 유지함
일관성을 유지하면 성능적인 문제가 생김 -
write back
데이터가 변경된것을 알 수 있는 Dirty Bit가 필요하다.
일관성 유지 안하고 캐시에서 메모리가 사라질 때 메모리와 동기화시킨다
극단적인 경우
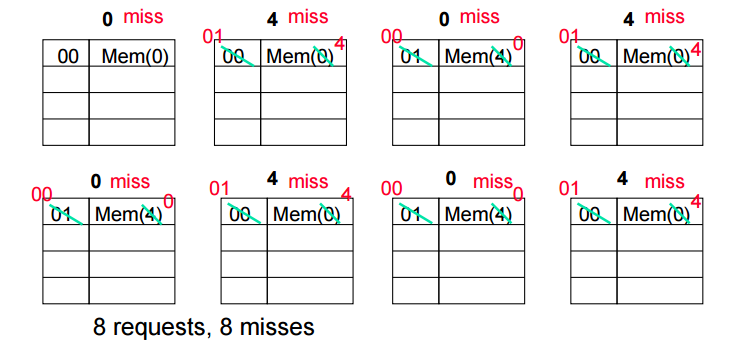
Ping-Pong
Cache Miss
compulosry
- First access to a block, “cold” fact of life, not a whole lot you can do about it
- If you are going to run “millions” of instruction, compulsory misses are insignificant
conflict
- 복수의 메모리가 같은 공간에 메핑
- 캐시 사이즈 늘리기
- associativity 늘리기
3x) 예시처럼 극단적인 핑퐁 가능성
Capacity
- Cache cannot contain all blocks accessed by the program
- increase cache size
Handling Cache Miss
read miss
현 프로세스에 스톨을 넣음(데이터가 없어서 진행 불가능).
메모리의 데이터를 캐시로 올리고, 캐시의 데이터를 다시 프로세서로 옮기고, 실행을 이어나간다.
write miss
캐시에 데이터가 없으면 당연히 데이터를 올려야한다
스톨로 명령어를 멈추고 메모리의 데이터를 캐시로 올려서 업데이트 시킨다. 하지만 굳이 이렇게 할 필요가 없다.
write는 cpu입장에선 cpu가 쓰는게 아니라 그냥 업데이트 하는 것이기때문.
따라서 write – back 의 경우 일반적으로
-
Write Allocate - 무조건 캐시의 빈 공간에 데이터를 쓸 수 있으면 쓴다 다른 데이터가 있는 경우 쫓아내고 쓴다. (동기화 발생시 wb정책 따름) 캐시에 allocation해서 write한다
-
No-Write Allocate - 캐시 writing을 스킵한다. 이럴떄는 writebuffer라는 별도의 공간이 또 있다. 여기 버퍼에 있는것들은 언젠간 메모리에 쓰여진다.
Taking Advantage of Spatial
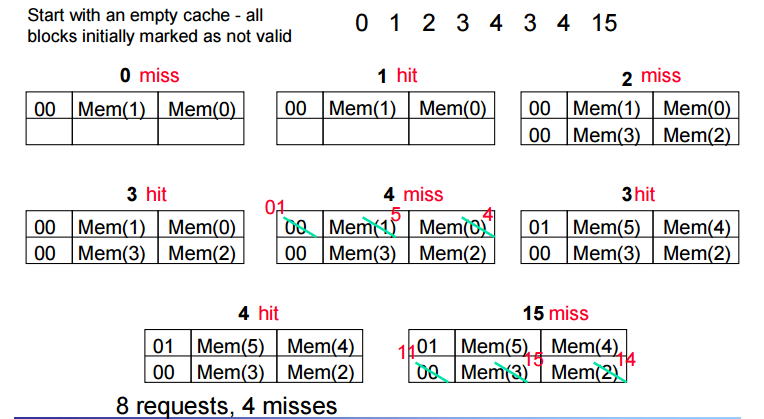
spatial 에서는 인근주소가 access 될 가능성이 높기에 주소 / 2 해서 인덱스를 구하고 인접한 것을 한번에 올린다.
이를고려한 miltiword block direct mapped cache
4개의 워드블록이 올라감
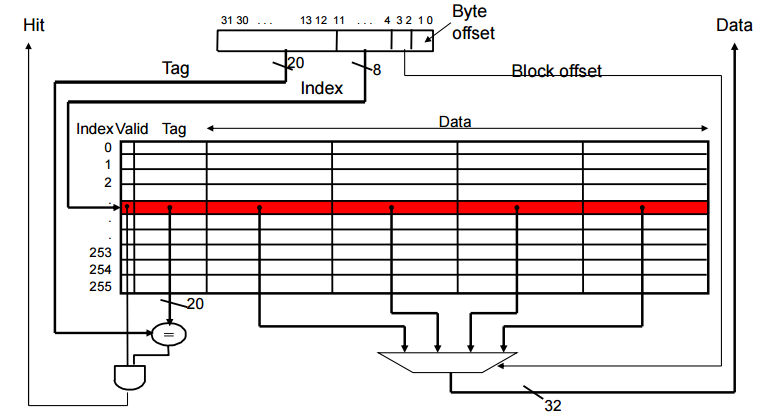
Miss Rate vs Block Size vs Cache Size
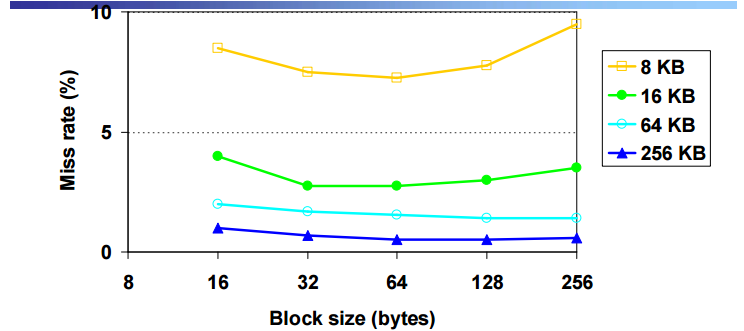
x 축의 block size 8 ~ 256
y 축의 miss rate miss rate 는 떨어짐
블락사이즈가 어느정도 증가할 때까지는 miss rate가 줄어들지만 block이 너무 커지면 miss가 늘어남 (capacity)때문
Block Size TradeOff
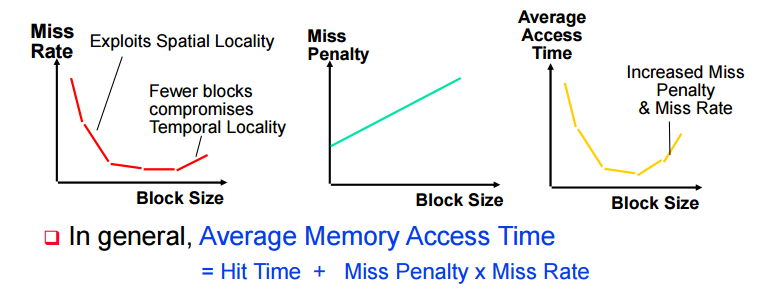
block을 키울수록 일정부분까진 spatial 이점이 있지만, 너무 커지면 replacement횟수가 너무 많아짐
블락사이즈가 커질수록 miss penalty가 점점 커짐
평균 access time은 miss rate가 줄어들떄 까지 시간이 줄긴 하지만 penalty가 늘어나서 어느 수준 이상에서는 급격하게 time 이 증가함
avg memory access time
= hit time + miss penalty * miss rate
MultiWordBlock Consideration
read miss
블락에서 일부분만 오류가 발생한 경우 > 전체를 반환함 그래야 데이터가 올라간다
따라서 bs가 커질수록 penalty가 점점 커진다
write misses
~~미스페널티를 줄지 그냥 캐시에 쓸지를 선택할 수 없음
블록의 한 워드에서 오류가 발생했을 때 그냥 써버리면 garbled block에 영향을 미침(나머지 블락) 따라서 그냥 write 해버릴수는 없다. 따라서 이 블락을 cache 라인에 할당하고 여기에 데이터를 다시 써줘야한다. ~~
write allocate 불가능. 하지만 그냥 쓰면 인접 블락들에 영향을 미치고 이걸 할 수는 없다. 따라서 캐시에 할당하고 다시 써주는 것이 국룰임
Cache miss rate 줄이기
- 좀더 유연한 블락 배치 채용
- Direct mapped 방식을 쓰지 않는다
- DM의 경우 해당 캐시블락의 본인데이터가 아닌경우 무조건 내보내고 접근 메모리 데이터를 올리거나 하기 떄문에 replacement가 유연하지 못함
- 하나의 메모리 블락은 하나의 캐시블락에만 들어가도록 설계되어서 극단적인 에러에 대응하기 어렵다
- fullay associative
– 어떤 메모리 블락이라도 어떤 캐시 블락이든 올라갈 수 있게 만든다 - N-way set associative
- n개만큼 set하고 나머지는 자유롭게 사용함
- 여러 레벨의 캐시를 쓴다
- L1 L2 L3 이런식으로 여러 레벨을 만들어서 L1에서 미스가 나도 L2(용량이 조금 더 큼)에서 찾아본다. 이 방식이 Memory까지 직접 가서 찾는것보다 훨씬 빠르다.
Improving Cache Perfomence
-
Hit Time을 줄여야함 (캐시 접속 시간을 줄임)
- 서치 오버헤드를 줄여야하고 이를 줄이려면 캐시 사이즈를 작게 만들어야함
- 다이렉트 맵 캐시를 쓰면 hit time이 가장 줄어든다 (해당 블락만 조사하면 끝나기때문)
- Wtire할때는 Allocation을 하지 않고 바로 buffer에 쓰거나 한다
-
Reduce miss rate
- 큰 캐시
- associative cache
- 16~64 까지의 큰 블록
- Victim Cache (최근에 버려진 블락을 들고있는 작은 버퍼)
-
Reduce miss penalty
- 작은 블락
- Write buffer
- 다중 레벨 캐시 사용
set associatvie cache (보완)
N-way의 경우 하나의 세트가 n개의 캐시로 되어있다.
하나의 메모리 블락이 set로 지정되고 set에 올라가있는지 찾는건 그 set의 개수만큼만 찾으면 된다 따라서 n번 서치한다.
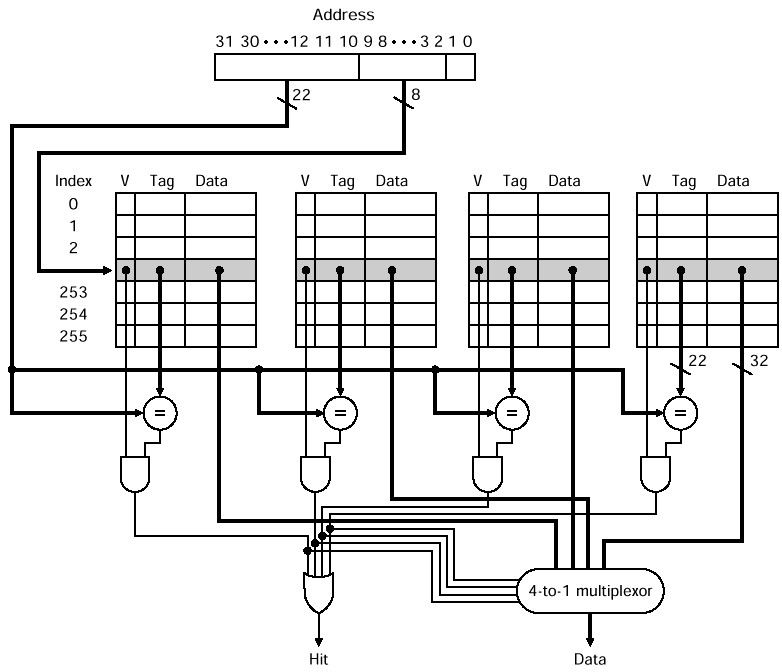
256 set 4 block 1024 block
세트의 00번째 자리는 어디에도 올라갈 수 있고 tag를 통해 비교해서 valid하면 caching되어있는것을 알 수 있음
캐시 블락 교체 정책
-
direct map 의 경우 교체정책이 없다
-
N - Way
Leat Recently Used (LRU)
가장 오랫동안 사용되지 않은 블락을 교체해준다
(temporal locality)에 기안함
Missrate vs Set Associative
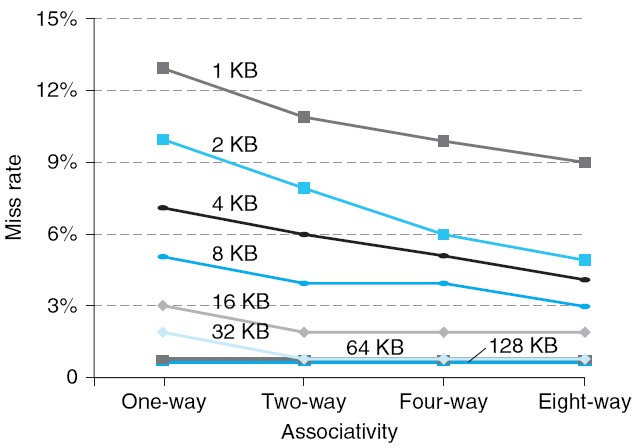
캐시 사이즈가 커질수록, missrate는 떨어진다. 만약, 동일한 캐시 블락 사이즈일 경우 associative 를 높힐수록 missrate가 떨어진다. 대신 Hit time은 늘어난다.
하지만 missrate가 overhead가 더 크기 때문에 hit time을 줄이는것보다는 missrate를 줄이는 것이 더 효율적이다.
Memory Reference Seq
캐시구조 : 2way associative 이고 1세트가 2블락, 8바이트 (2word). 4kb 캐시크기한 블락이 2word라서 블락주소를 블락사이즈로 나눈 몫이 세트.
0 4 8188 0 16384 0 을 방문한다 했을 때,
0 4 는 워드는 다르지만, 2 word 이기 때문에 하나의 블락에 올라간다.
512block * 8byte = 4kb 캐시크기
만약, Direct mapped의 경우 5miss, 1 hit이다.
256개의 세트가 있다. 따라서 총 세트 개수로 주소를 나눈다.
주소를 워드(블락사이즈)로 나누고 % 구해야한다.
1) 0 / 8 % 256 = 0
0번째 세트에 올린다
두 칸이 비어있어서 2개를 올린다 (0, 4) miss
2) 4 / 8 % 256 = 0
세트는 0번째,
태그는 4 / 256 = 0
태그도 동일함 hit
3) 8188 / 8 % 256 = 255
255번째 세트임
tag 값은 (8188 / 8) = 1023 / 256 = 3 miss
4) 0번째 접근해서 hit (아까 올라온 데이터)
5) 16384 / 8 % 256 = 0
0번째 세트에 넣어야하고 주소값을 구하면
이 주소값은 기존의 블락에 값들의 태그와 비교하여 다르면 miss. (2번째가 비어있어서 2번째에 추가함)
6) 0번째 접근해서 hit (아까 올라온 데이터)
3히트 3미스
Improving Cache performance
hit time + (missrate * miss penalty)
셋중 하나를 줄여주는게 낫다.
방법은 각각 위에서 설명함.
Cache Coherence Problem
L1과 L2캐시는 각 코어마다 있다.
L1과 L2는 보통 Instruction Decode 로 나눠져있다.
L3는 통합적으로 이용되는 공유영역이다.
이때 cache coherence problem 발생한다.
Write invalidate
CPU A가 X를 읽고, B가 X를 읽음
A가 1을 X에 쓰면 data 를 invalidate 시켜버림 (둘이 읽은 값이 다름)
이러면 B가 다시 읽을때는 invalidate라서 다시 읽어와야한다. 이때 다시 읽기전에 쓰여진 A 데이터를 가져온다.
Snoopy Protocols
Write Invalidate Protocol:
공유된 데이터에 대해서 업데이트가 발생하면 모든 나머지 캐시의 데이터를 invalid 시키는 signal을 보낸다.
Write Broadcast Protocol:
캐시에 데이터를 쓰면 공유된 데이터에 대해서 다른 CPU에게 Broadcast해서 업데이트 시켜준다. BUS를 통해서 데이터를 전달함.
Write Serialization:
버스가 시리얼라이즈 되도록 만든다.
