회복
장애와 회복
- 시스템이 정해진 명세대로 작동하지 않는 상태
- 원인 : 하드웨어 결함, 소프트웨어 논리오류, 사람 실수
장애의 유형
트랜잭션 장애
논리적 오류 입력 데이터의 불량
시스템 장애
하드웨어의 오동작
미디어 장애
디스크 헤드 붕괴 또는 고장
회복
데이터베이스 장애 이전의 일관된 상태로 되돌아 가는 것 (트랙잭션의 사이)
회복관리자 : DBMS의 서브시스템
DBMS 코드의 10%이상 차지
신뢰성 있는 회복을 책임짐
회복의 원리와 조치
회복의 기본 원리
중복
덤프 – 다른 저장장치로 복제
로그 – 데이터 아이템의 옛 값과 새 값을 별도의 파일에 기록
회복을 위한 조치
REDO : 가장 최근 복제본(미디어가 망가졌다면 log가 없고 복제본이 있기 떄문) + 로그 --> 데이타베이스 복원
UNDO : 로그 + 모든 변경들을 취소 --> 원래의 데이타베이스 상태로 복원
이중 데이터베이스 시스템 -->
두 시스템을 분리해서 보관하게 되어있음
회복관리자
- 장애탐지
- DB 복원
회복 작업
- 손상된 부분만을 포함하는 최소의 범위
- 최단시간
- 트랜잭션 기반
- 회복자료 보장
- 시스템레벨 자동조치
저장장치의 타입: 속도, 용량, 장애시의 탄력성
1) 소멸 저장장치(volatile storage)
예시) 메인 메모리, DRAM
시스템의 붕괴와 함께 저장된 데이터 상실
2) 비소멸성 저장장치(nonvolatile storage)
디스크나 테이프
시스템 붕괴 시에도 보통 저장된 데이터 손실되지 않음
저장장치 자체의 고장으로 손실 가능
3) 안정 저장장치(stable storage)
데이터의 손실이 발생하지 않게 여러 개의 비소멸 저장장치로 구성된 저장장치
프로그램과 데이터베이스 사이의 이동
응용프로그램이 변수 X를 사용하기 위해선 Read Write 연산을 함
Read
버퍼에 데이터아이템 x가 있다면 읽어오지만 없다면 x가 포함된 디스크 블록에서 input 을 해야함 (시간 많이 걸림)
Write
버퍼가 있다면 Write하고 디스크에 씌워주지만 만약 없다면, 버퍼 관리자가 비울 버퍼를 하나 선정함. 해당 버퍼는 클린 혹은 더티함.
클린 – 메모리와 디스크의 이미지가 같다
더티 – 디스크 이미지와 버퍼 이미지가 서로 다르다
버퍼에 있는 것이 더 최신이라 기존 패이지를 없애기 전에 디스크에 기록 후 없앤다 (LRU)
버퍼에서 없는 경우 --> 미스가 났다 --> LRU로 가장 오래된 페이지를 선택하고 클린/더티 상태 확인해서 디스크 블록에 새로 써준다 의 과정을 거친다
트랜잭션
T : Si → Sj, Si, Sj ∈ S
S : 데이터베이스의 일관된 상태의 집합
일관된 상태에서 다른 일관된 상태로의 변환
트랜잭션의 특성(ACID)
원자성(atomicity)
- 전부 또는 전무다. 전부 실행되거나 전부 안되어야함
일관성(consistency)
- 트랜잭션 실행 후에도 일관성 유지 – 실행전에도 실행후에도 일관성이 유지되어야 함
격리성(isolation)
- 트랜잭션 실행 중 연산의 중간 결과에 다른 트랜잭션이 접근할 수 없음 – 중간결과를 읽으면 안되고 끼어들어서도 안된다
영속성(durability)
- 트랜잭션이 일단 성공적으로 실행되면 그 결과는 영속적으로 유지된다
예시
트랜잭션 T0
계좌 A에서 100원을 계좌 B에 이체 (A=1000, B=2000)
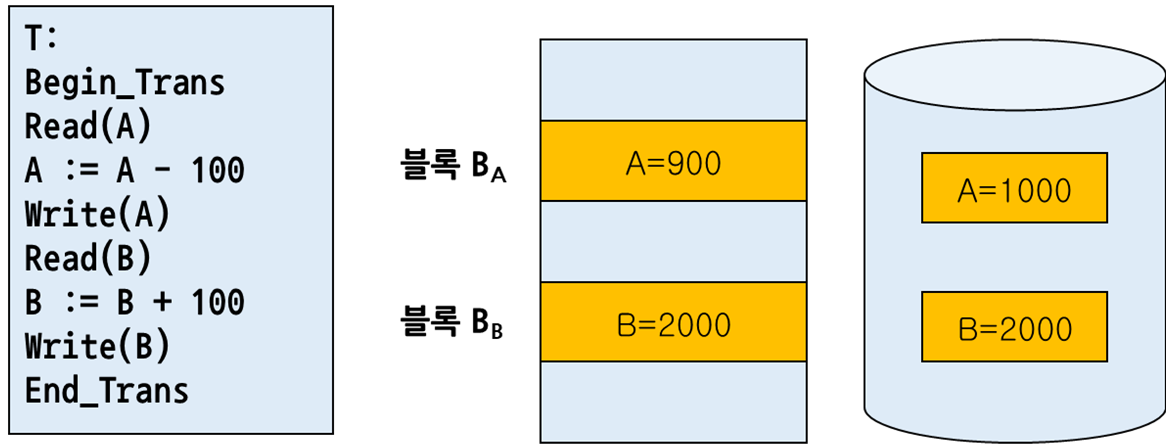
Output 연산들을 실행하는 도중 장애 발생 --> Output(BA)를 수행하고 Output(BB)를
실행하려는 순간장애
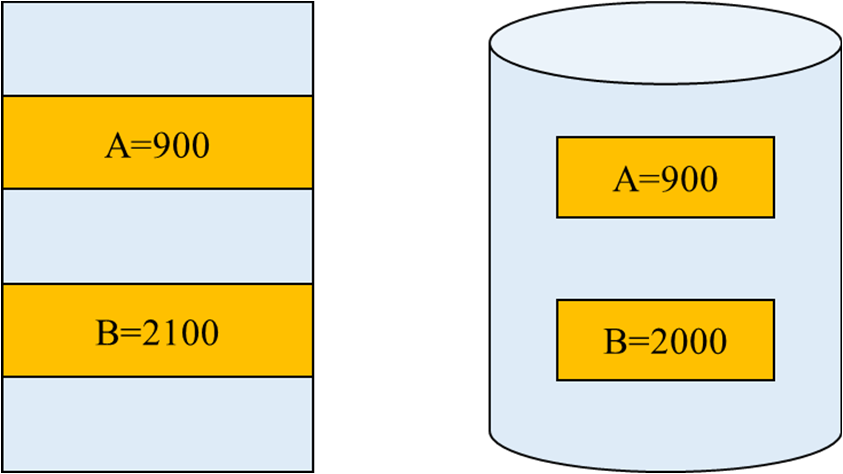
트랜잭션 원자성을 위한 연산
트랜잭션은 회복의 논리적 단위
commit
트랜잭션의 성공적 실행 후 일관서 있는 DB상태
영구적인 갱신 --> 디스크에 반영
갱신된 데이터의 영속성을 보장함
Rollback
트랜잭션 실행의 실패 --> 모순된 DB 상태
수행된 모든 연산 결과의 UNDO (1번은 원자성 유지를 위해 성공했어도 싹다 취소해야한다)
디스크 블록 갱신 방법
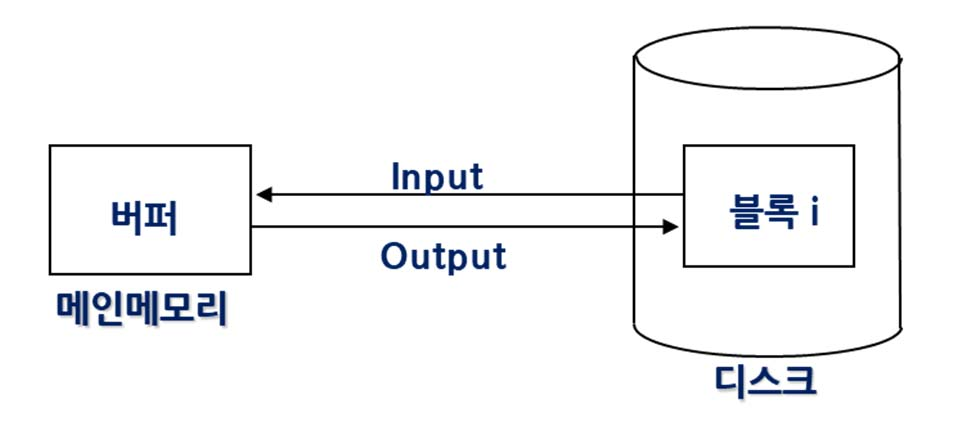
원위치 갱신
DB 블록번호와 실제 디스크 블록번호가 같음 --> 대부분 이런 방식
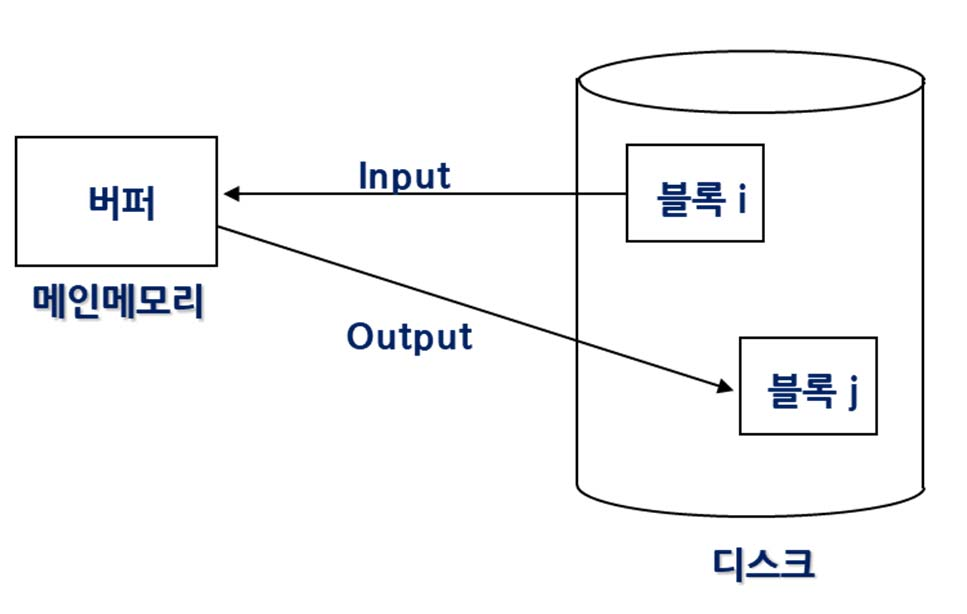
간접 갱신
DB 블록번호와 실제 디스크 블록번호가 다름
예시) - 3번페이지를 요청하면 물리적으로 다른 위치에 있을 수 있음. 따라서 Mapping 테이블을 이용해서 블록의 위치를 찾아야함 거의 안씀
트랜잭션 상태
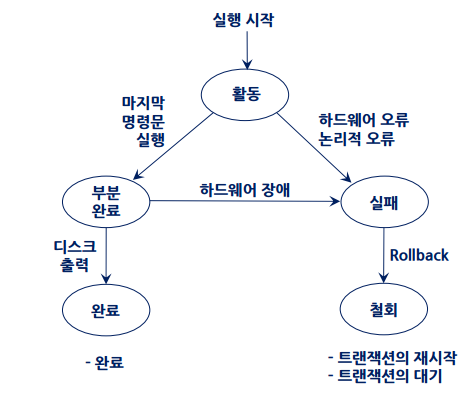
프로그램 : 하나 이상의 트랜잭션을 포함
프로그램의 성공적인 수행
모든 트랜잭션의 성공적인 완료
트랜잭션의 예
계좌 A에서 계좌 B로 100원을 이체
BEGIN_TRANS;
UPDATE ACCOUNT
SET Balance = Balance - 100
WHERE Accnt = 'A';
IF ERROR GO TO UNDO;
UPDATE ACCOUNT
SET Balance = Balance + 100
WHERE Accnt = 'B';
IF ERROR GO TO UNDO;
COMMIT TRANS;
GO TO FINISH;
UNDO:
ROLLBACK TRANS;
FINISH:
RETURN;
END_TRANS실패상태의 트랜잭션
직전 상태로 ROllBACK 연산 실행
그 뒤에서 철회 상태의 트랙잭션으로 되어 종료 --> 이때, 트랜잭션의 재시작 --> 철회된 트랜잭션을 다시 재시작함
폐기
- 트랜잭션의 내부적 오류로 재작성이든 뭐든 필요하면 트랜잭션을 아예 날려버림
데이터베이스 로그
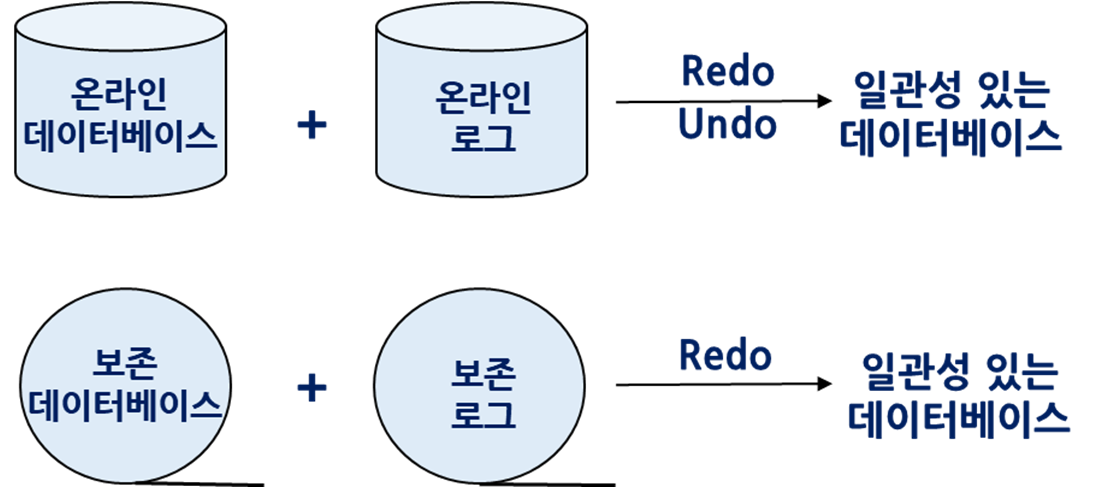
온라인 로그 : 디스크
archival log : 테이프
로그레코드
<Ti, Start>
트랜잭션 Ti가 실행 시작
<Ti, Xj, V1, V2>
트랜잭션 Ti가 데이터 아이템 Xj의 값을 V1에서 V2 로 변경
<Ti, commit>
트랜잭션 Ti 가 실행 완료 --> 영속성을 제공하야함 (커밋되었기 떄문)
로그가 사이즈가 엄청 크기에 원래는 온라인 DB와 온라인 LOG로 기록한다 이게 너무 커지니깐 주기적으로 보관 LOG (테이프, HDD)에 기록해야한다.
로그 압축
효율성과 신속한 회복을 위해
-
실패한 트랜잭션을 로그가 필요 없다 (이미 rollback 했음)
-
성공한 트랜잭션의 갱신 전 데이터는 불필요함 (REDO를 위해 새로운 값만 필요함)
-
하나의 데이터 아이템이 여러 트랜잭션에 의해 어러번 갱신되었다면, 마지막 데이터 값만 필요 (REDO 중간 과정의 데이터값 불필요함)
지연갱신
부분 완료될 때까지 모든 Output 연산을 지연
- 모든 데이터베이스의 변경을 로그에 기록
비커밋 데이터는 DB에 반영되어서는 절대 안된다!
안전한 저장소에 T commit을 포함하는 레코드를 기록하고, DB 갱신 후, 완료 상태 (UNDO 불필요)
예시
트랜잭션 T1: 계좌 A에서 100을 계좌 B로 이체
트랜잭션 T2: 계좌 C로부터 200을 인출
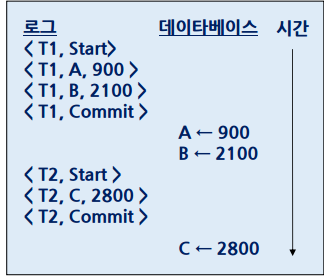
commit후 데이터베이스를 변경하는것을 알 수 있다.
지연갱신에서 REDO 연산
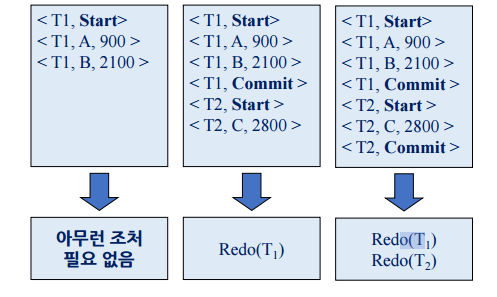
REDO는 idmpotent 성질을 가지고 있어야함 --> REDO는 여러 번 실행하나, 한번 실행하나 결과가 똑같다.
Redo(Redo(Redo…(x))) = Redo(x)
예) C를 2800으로 바꾸려다 오류가 나면 또 그걸 계속 반복해도 된다.
어떤 트랜잭션이 REDO 되어야 하는가?
로그에 <Ti, Start> 레코드와 <Ti, Commit> 레코드가 모두 있는 트랜잭션 Ti에 대해서만 재실행을 한다.
로그에 Commit 레코드가 있는 트랜잭션에 대해서 Redo 다시 실행
즉시 갱신
지연갱신을 하다보면 버퍼가 학생으로 가득차게 된다
-> 다른 트랜잭션도 병렬적으로 이루어지는데 가득차버리면 쓸수가 없고, 버퍼보다 테이블이 더 크면 갱신이 안된다

커밋되지 않은 트랜잭션도 쓸 수 있다는 뜻이지만 --> 어느것이 된건지 안된건지 알 수가 없다
따라서 REDO가 아니라 옛날 데이터로 되돌리는 UNDO를 해야한다
Procedure Undo(Ti)
트랜잭션 Ti가 변경한 모든 데이타 아이템 값들을 로그에
기록된 역순으로 로그에 있는 변경 저 값으로 환원
Undo 연산도 idempotent 성질 가지고 있어야 함
--> 로그 레코드 안정 저장소에 기록 후 Output(Bx)
즉시 갱신에서의 회복 연산
장애가 일어나면 회복 관리자는 로그를 검사
1. 만일 로그에 <Ti, Start > 레코드만 있고 <Ti, Commit> 레코드가 없으면 Undo(Ti)를 수행
- 만일 로그에 <Ti, Start > 레코드와 <Ti, Commit> 레코드가 모두 다 있으면 Redo(Ti)를 수행
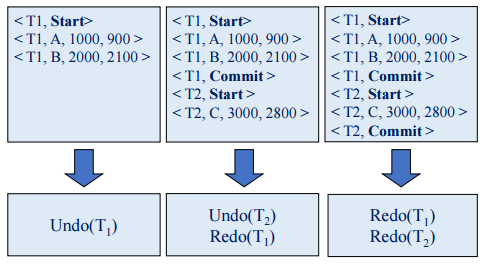
검사 시점 회복
장애가 발생한 시점에서 로그를 전체 undo 하고 다시 redo를 해야함 --> 너무 크다
체크포인트를 만들어서 그 영역들까지만 redo undo를 한다.
체크포인트 설정 방법
- 메인메모리에 있는 로그 레코드를 안정저장소로 출력(로그를 무조건적 기록함)
- 페이지중 더티페이지를 디스크에 기록
- 현재 실행중인 모든 트랜잭션을 기록
- 체크포인트 했다고 기록함
시행 예시
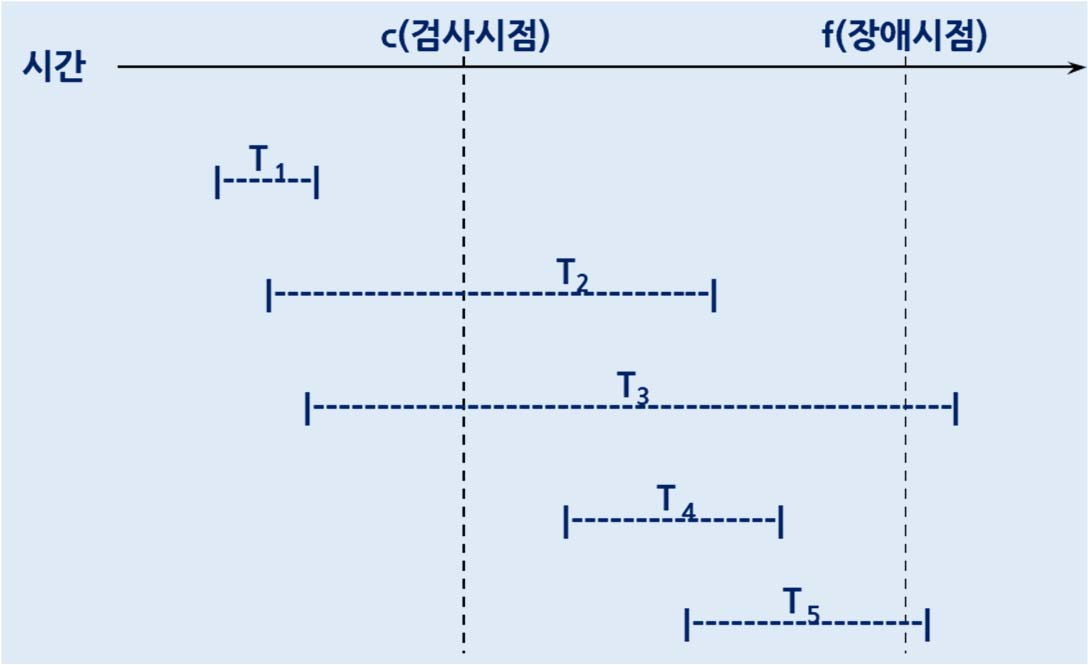
트랜잭션 유형
◦ T2, T4 : REDO
◦ T3, T5 : UNDO
◦ T1 : 회복작업과 무관
일단 체크포인트 이후에 수행되어가는 것들은 전부 undo list에 전부 넣음. 그 후, 확인하다가 가다가 commit을 만나면 REDO에 집어넣음
섀도우 페이징
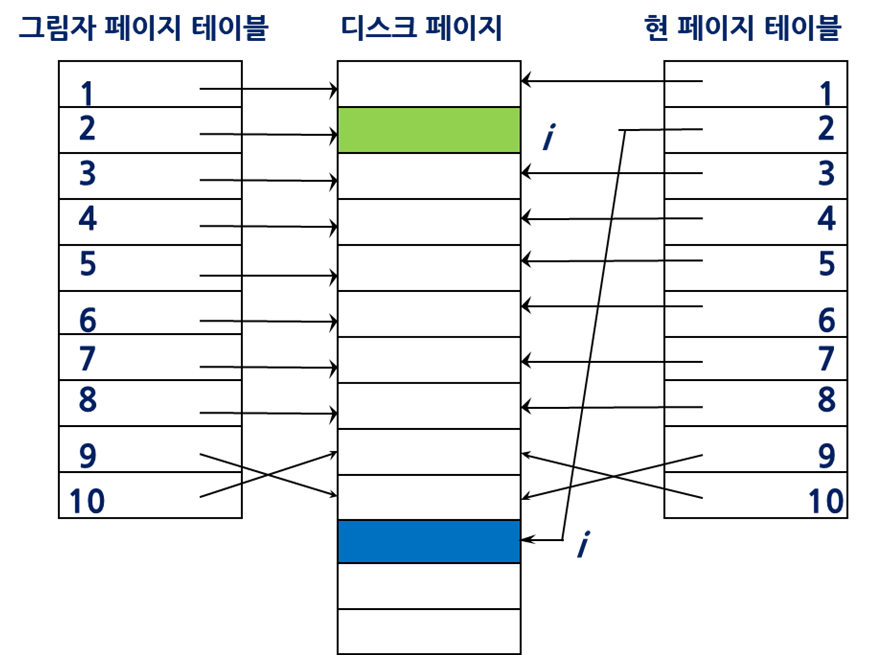
간단한 DB에서 사용함 (PC용)
두개의 페이지 테이블 유지
- 그림자 페이지 테이블
- 현 페이지 테이블
작동원리
2번 페이지에 대해서 업데이트가 일어나면 새로운 페이지를 할당받고, 그 페이지를 업데이트함. 버퍼에 2번을 올리고 버퍼가 새로운 페이지에 업데이트된 내용을 씀.
커밋이 일어나면 현재 페이지 테이블을 복사를 해서 그림자 테이블에 넣어준다. 그 후, 현재 페이지 테이블을 가르키는 변수를 그림자 페이지를 가르키도록 바꾼다.
그러면 두 테이블이 서로 뒤바뀌게 되고 현 테이블은 최산상태의 정보를, 그림자 테이블은 과거의 정보를 지니게 된다.
원래 페이지는 값 변경 없이 유지되고 있음. 따라서 오류 발생 시 직전 커밋이 유지하던 페이지 테이블이라는걸 알 수있다. (그림자 테이블)
이때 철회가 된다면 페이지테이블을 가르키는 변수가 다시 섀도우를 가르키게 한다면 된다
트랜잭션이 변경한 버퍼의 페이지를 디스크에 출력 (더티 페이지 writing)
현 페이지 테이블을 디스크에 출력
현 페이지 테이블을 가르키는 변수를 디스크에 출력
3 단계 직전에 시스템 장애 발생
현 페이지 테이블을 폐기
3 단계 끝난 직후 장애
특징
트랜잭션의 실행 결과에는 아무런 영향 주지 않음
Redo 연산 필요 없음
그림자 페이징 기법의 장점
로그 레코드를 출력하는 오버헤드 없음 → 디스크 접근 횟수 줄일 수 있음
Undo 연산이 아주 간단하고 Redo 연산이 필요 없음 → 장애로부터의 회복 작업 신속
결점(Drawbacks)
- 커밋 오버헤드 (더티 페이지 전부 기록 시간 과다)
- 데이터가 단편임 (클러스터링이 불가능함)
- 쓰레기 수집 (페이지를 바꾸면 이전 페이지는 가비지가 되고 이를 수집해줘야함)
- 병행 트랜잭션 지원이 곤란함
미디어 회복
디스크 붕괴 : 비소멸성 저장 장치의 내용이 손상
이를 보호하기 위해
주기적인 덤프를 수행함
단계별 작업
테이블을 보관함
메인 메모리에 있는 모든 로그 레코드를 안정 저장소에 출력
변경된 버퍼 블록들을 모두 디스크에 출력
데이터베이스의 내용을 안정 저장장치에 복사
로그 레코드 dump를 안정 저장소에 출력시켜 덤프를 표시
로그 우선 기록 규약 Write Ahead Log Protocol
로그가 없으면 복구가 안되어서 항상 안정적인 매체에 저장을 해야함 --> 하지만 매번 이러면 시간이 너무 오래 걸림
로그도 버퍼링을 한다.
메인메모리에 로그가 있고 디스크에 없을떄 장애가 생기면 로그를 전부 잃게된다. 그러면 commit 레코드들을 전부 날리고 회복이 불가능해지고 commmit의 속성들이 깨지게된다. 따라서 Write Ahead Log protocol 이라는 기법을 씀
커밋이라는건 커밋 레코드가 디스크에 저장됨을 보장한다
Commit을 이 레코드가 log에 기록되는데, 이때 반드시 디스크에도 들어아갸한다. --> 즉, 디스크에도 저장됨을 보장해야한다 이렇게 강제로 기록하는 것을 flush라고 함
커밋을 포함하는 로그버퍼를 기록할 떄는 그보다 이전의 로그버퍼도 다 기록한다. 데이터 블록은 즉시갱신이라 언제든 저장될 수 있는데, 그 데이터 블록관련 로그들은 전부 디스크에 기록한다. 그렇지 않으면 old 데이터가 유실 될 수 있다.
테이터베이스 버퍼 관리 방안
방안 1
메인 메모리 일부를 운영체제가 아니라 DBMS가 직접 관리하는 버퍼로 예약
데이터베이스 블록 이동을 DBMS가 관리
모든걸 DB가 다 할 수 있고, 알고리즘이 간단해진다.
단점
하지만 컴퓨터를 DB머신으로만 사용하는게 아니라서 운영체제가 사용하는 메모리 양이 줄어서 메인메모리 크기가 제한된다
메인메모리 낭비가 일어난다. 예약된 부분을 비DB응용 프로그램은 사용 할 수 없다.
방안 2
DBMS는 운영체제의 Virtual address space 안에 데이터베이스 버퍼 구현
운영체제를 관장하는 OS 캐시. 그리고 DB안에 buffer를 둔다.
Read를 실행하면 버퍼를 통해 OS 캐시를 통해 디스크를 읽어서 OS 메인메모리에 가져다 두는 기법.
두번의 출력이 일어나는 단점이 있으나, 다른 응용 프로그램이 메모리를 더 잘 쓸 수 있다.
다중 DB 트랜잭션의 회복
글로벌 트랜잭션을 회복하기 위해서 전역 회복 관리자(조정자)를 두고 관리한다.
2-레벨 회복 기법(2PL; 2-Phase Locking Protocol)
단계 1
- 조정자는 각 참여자에게 ‘prepare for commit’ 메시지를 전송
- 각 참여자는 모든 레코드를 강제 출력시키고 ‘OK’를 조정자에게 전송 그렇게 할 수 없는 경우는 ‘NOT OK’를 전송
단계 2
- 만일 조정자가 모든 참여자로부터 ‘OK’메시지를 받았다면 자신의 로그에 ‘commit’을 기록하고 ‘commit’ 메시지를 모든 참여자에게 전송하고, 각 참여자는 로그에 ‘commit’을 기록
- 그 이외의 경우(시간경과도 포함) 조정자는 자신의 로그에 rollback’을 기록하고 각 참여자에게 ‘rollback’메시지를 전송하고, 각 참여자는 ‘rollback’연산을 수행
