질의어 처리
SQL
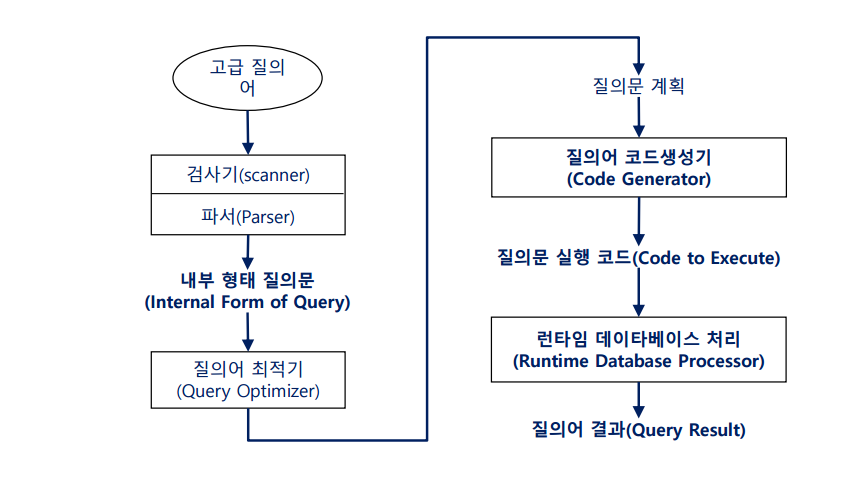
SQL은 다음과 같은 처리과정을 가진다.
검사기는 토큰을 확인하며, 파서는 문법을 검사한다.
내부 형태 질의문 -> 트리, 관계 대수로 이루어져 있다.이를 질의어 최적기가 선택을 한다. 이 질의문 최적기를 통해 질의어 코드를 생성하고 plan을 처리한다.
질의어 최적화
효율적인 실행전략의 계획
시스템 레벨 최적화는 고급질의어다. -> 자세한 실행계획이 나타나 있지 않다. 이 계획을 짜는 과정이 최적화이다.
효율적이라는 것은 빠르게 실행되는 것을 말한다. 빠르게 실행하기 위해서는 디스크I/O횟수가 가장 중요하다. (튜플 페이지 블럭)
또한, 중간결과의 크기가 작아야 한다. (결과들을 셀렉트에 입력하는데, 이 중간결과들이 너무 크면 비효율적)
질의어 최적화
- 질의문의 내부 표현
- 효율적인 내부 형태로 변환
- 후보 프로시저
- 질의문 계획의 평가 및 결정
질의문의 내부 표현
의미있는 sql 단어들을 토큰으로 만들어 낸다.
토큰의 조합이 문법에 맞는지 검사하는게 파서,
사용자가 질의문을 처리하기 적절한 어떤 내부 형태(트리)로 변환한다. 이 과정을 통해 불필요하거나 무의미한 것은 뺄 수 있다
이떄 lex(스캐너) yacc(문법)
flex, bison 프로그램 사용하여 만들어낸다. (오픈소스임)
질의문 트리 (플랜)
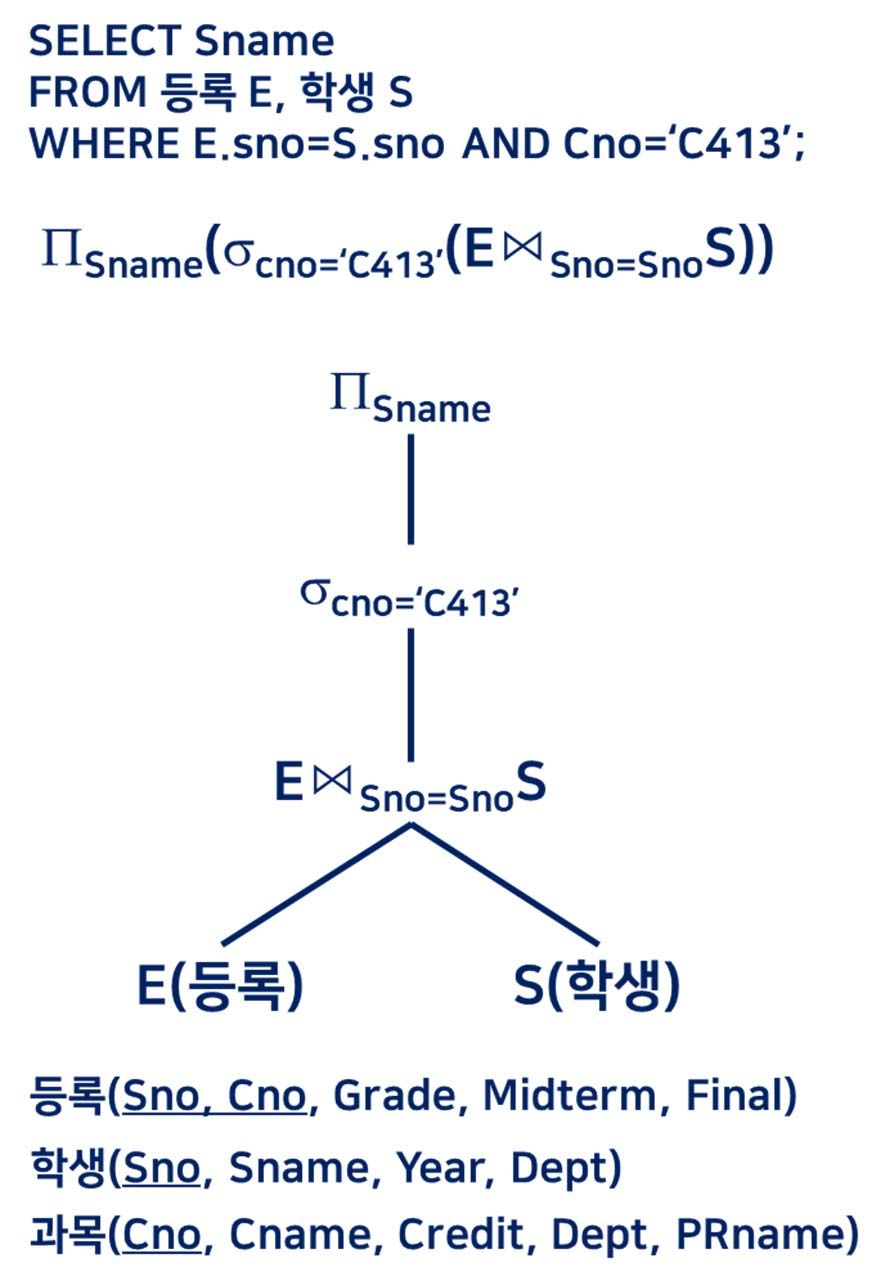
필요한 피연산자가 사용가능한 서브트리에 대해 먼저 내부노드 연산 실행, 그 결과 릴레이션을 실행된 서브트리와 대체
루트 노드 실행 : 질의문의 실행 결과
질의문은 비절차적이지만, plan은 절차적임
즉 비절차적인 것을 절차적으로 바꾸는 과정임
효율적인 내부형태로 변환
플랜이 하나 만들어지면 다른 플랜으로 바꿔서 효율성을 올려야 한다. 이 변환과정에는 rule이 있음
- 하나의 룰로 하나의 변경 --> sqlite
- 여러 룰로 여러 플랜을 두고 가장 코스트가 적은 것을 선택 --> oracle 같은 상업적 도구
질의문 트리, 질의문 실행계획, 플랜
변환규칙
질의문 내부 표현을 동등하면서도 처리에 효율적인 형태로
변환시킨다.
문법
추론
의미

예시
SELECT Sname
FROM S, E
WHERE S.Sno=E.Sno AND Cno='C413'
|S|=100
|E|=10000 (cno = 200개 10000 / 50 선택도 0.5%)
|E.CNO='C413'|=50
메인메모리는 50개의 투플을 가질 수 있다고 가정
다음과 같은 질의문이 있다고 할 때,
방법 1
① R1 ← E ⑅Sno=Sno S
No. of tuple I/O = 10000(E)+100(S)*10000+10000(R1)
② R2 ← Select CNO=‘C413’(R1)
No. of tuple I/O = 10000(R1)
③ Project Sname(R2)
⇒ No. of tuple I/O : 1,030,000
방법 2
① R1 ← Select CNO=‘C413’(E)
No. of tuple I/O = 10000(E)
② R2 ← R1 Join SNO=SNO S
No. of tuple I/O = 100(S)
③ Project Sname(R2)
⇒ No. of tuple I/O : 10,100
후보 프로시져 선정
후보에도, select에도 많은 플랜들이 있어서 엄청나게 많은 조합의 플랜이 나올 수 있다
따라서 이 플랜을 계산하는게 오히려 더 시간이 오래걸릴수도 있다.
의미있는 플랜을 만들어내서 의미없는것들을 걸러내고 더 빠르게 실행할 수 있도록 해야한다.
예시
E S 조인 후 selection 한다고 했을 때,
예 : Selection
• 후보키 비교에 기초한 프로시저
• 인덱스 필드에 기초한 프로시저
• 물리적으로 집중된 프로시저
질의문 계획의 평가 및 결정
제한된 질의문 개수를 만들어야 효율적인 플랜작성이 된다.
탐색공간을 축소해야한다. 그 후, 가장 비용이 적게드는 계획을 선택한다.
내부 형태 변환 규칙
관계대수 -> 다른 관계 대수로 변환
내부 형태 변환 규칙
1) 논리곱 and로 연결된 select 조건이면 일련의 개별적인 샐랙트 조건으로 바꿔도 된다.
2) 셀렉트 연산은 교환적이다.
- 순서를 바꿔서 진행해도 된다는 의미이다.
3) 프로젝트는 제일 마지막만 의미가 있어서 그것만 실행해도 된다.
4) 셀렉트의 조건 c가 프로젝트 애트리뷰트만 포함하고 있다면, 이들은 교환적이다.
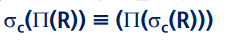
5) 셀렉트 조건이 조인이나 카티션 프로젝트에 관련된 릴레이션 하나에만 국한되면 -> 조인조건 (분배해도 된다?)
- R (A, B, C), S(D, E, F) 이면 전체 조건 c는 r의 애트리뷰트 abc로 구성되어 있어서 r을 c 하고 조인해도 된다.
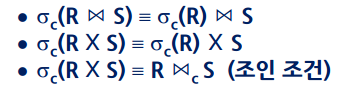
6) 셀렉트 조건 c가 c = (c1 and c2) 이고 c1은 R c2는 S의 애트리뷰트만 각각 포함한다.
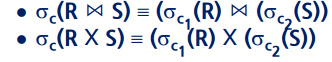
7) 카티션 프로덕트 ,합집합, 교집합, 조인은 교환적이다. (분배 가능)
8) 애트리뷰트 리스트 L이 L = (L1 L2) L1은 R에, L2는 S에 포함된다
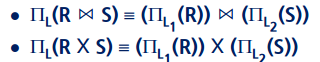
9) 집합 연산 합집합, 교집합, 차집합과 관련딘 두 조건에서는 셀렉트는 다음과 같이 변환 가능하다
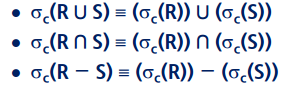
10) 합집합과 관련된 프로젝트는 다음과 같이 변환 가능하다
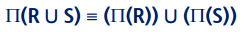
11) 합집합 교집합 카티션 조인은 연합적
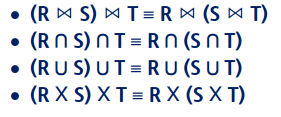
12) OR로 연결된 조건식을 AND로 연결 된 논리곱 정규형으로 변환 가능
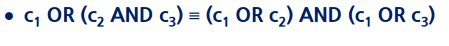
초기 트리를 최적화된 트리로의 변환 방법
-
논리곱(AND)으로 된 조건을 가진 SELECT 연산은 분해, 일련의 개별적 SELECT 연산으로 변환(R1)
-
다른 연산자를 포함하고 있는 SELECT 연산은 선택 조건의 애트리뷰트가 허용하는 범위 내에서 실렉트 연산 먼저 실행되도록 변환(R2,R4,R5,R8)
-
가장 제한적인 SELECT 연산이 가장 먼저 수행될 수 있도록 트리의 단말 노드들을 재정돈 -> 가장 적은 투플 수 또는 가장 작은 선택도
-
카티션 프로덕트 연산 다음에 바로 실렉트 연산이 나오는 것은 하나의 조인연산으로 통합(R5)
-
다른 연산을 포함하고 있는 PROJECT 연산은 가능한 한 프로젝트 애트리뷰트를 분해해서 개별적 PROJECT로 만들어 프로젝트 연산이 먼저 실행되도록 함(R4, R7)
-
OR로 연결된 조건식은 논리곱 정형식으로 변환(R11)
질의 변환 예시
조건
EMPLOYEE(Eno, Name, Bdate, Addr, Sal, Dno, Sex, Mgrno)
PROJECT(Pjno, Pname, Location, Dname)
WORKS_ON(Wno, Pno, Hours)
질의
1980년 이후에 출생하고 ‘ALPHA’ 프로젝트에
일하는 직원의 이름을 검색하라
SELECT Name
FROM EMPLOYEE, WORKS_ON, PROJECT
WHERE Pname = ‘ALPHA’
AND Pjno = Pno
AND Wno = Eno
AND Bdate > ‘1980-12-31
위의 법칙을 적용해서 생각해보면
- 셀렉트를 아래로 내릴 수 있는곳까지 내린다
- pjno만 얻어온다, (프로젝트는 최종 결과만 잇으면 된다)
- works on에서 wno pno를 가지고온다
- 3개를 조인한다
- wno를 폴젝션한다
- employee에서는 bdate만 필요하니깐 그것만 가지고 온다
- 조인 후 프로젝트
셀렉트 연산의 구현
셀렉트 연산의 구현
[S1] 선형 탐색(linear search) : 주먹구구식 방법(brute force)
[S2] 이원 탐색(binary search) : 동등 비교, 정렬된 데이터
[S3] 기본 인덱스 또는 해시 키를 통해 하나의 레코드를 탐색
[S4] 기본 인덱스를 이용해서 복수 레코드를 탐색 : >, ≥, <, ≤
[S5] 집중 인덱스(clustering)를 이용해서 복수레코드를 탐색
[S6] 보조 (B+ tree) 인덱스 이용
- 유일성 인덱스(key index field) : 단일레코드
- 비유일성 인덱스(non-key index field) : 복수레코드
조인 연산의 구현
중첩루프(Nested Loop)
- 이중 for문 구조
- 버퍼가 3자리 있으면 1번에 첫번째 루프를 올리고 나머지에 s를 하나씩 올리고 가득차면 앞에를 뺴고 뒤에를 마져 올림
- nested loop이라 부름
- 중첩 루프
BNL 기법
내부는 페이지로 되어있음
페이지로 단위로 처리하나고 했을 때
페이지가 다음과 같다.
R {1, 2, 3}
S {4, 5, 6, 7}
버퍼에 1을 올리고 1번 페이지안에 있는 모든 애트리뷰트에 대해서 s4를 전부 검사함 --> 그리고 그 다음 5에 대해서 모두 검사함 --> 이 과정을 반복해서 1-4 1-5 1-6 ... 3- 7 이런식으로 해결한다.
이러면 12번만 읽으면 된다
실제로는 이렇게 블럭당 비교를 한다
인덱스 검사(Index Lookup)
- 조인에 참여하는 애트리뷰트 A가 있음 R과 S 둘다
- 이 A에 대해 인덱스가 있음
- 인덱스가 없는 것을 외부 릴레이션에 둔다(외부는 어차피 1회씩 스캔해야함)
- 인덱스를 따라가서 읽어오고 조인 참여하는 것을 찾는다
R 릴레이션의 블럭 b1개 + 튜플 n * 데이터(h + 1) - b1 + n(h+1)
해시 검사(Hash Lookup)
- 조인에 참여하는 애트리뷰트 A가 있음
- A에 대해서 hash가 걸려있음
- 해시를 이용해서 튜플을 찾겠다는 것
- 데이터 레코드 읽는 비용 (1 + 1) * 데이터 갯수 n + 데이터갯수 n
- n + n(1 + 1)
정렬/합병(Sort/Merge)
- R, S는 정렬되어 있지 않다
- A에 대해서 R, S를 정렬한다.
- R이 외부, S가 내부
- 각 릴레이션의 첫번째 튜플을 비교함
- 같으면 결과에 넣고 inner loop를 증가
- 같지 않으면 inner loop을 벗어나니깐 k는 끊어진 위치부터 R을 증가해서 inner loop을 검사함
- 간단하게 말하면 각 테이블을 한번씩 읽는것임
- b1 + b2
- 정렬 비용 : 2(n log n)
해싱(Hashing)
- 애트리뷰트 A에서 해시 인덱스를 생성함
- 그 다음 앞의 해시 검사를 통해 해시를 검사함
위 방법의 조합
이걸 전부 다 쓰면 예전에는 비용계산시간이 너무 컷으나
요즘은 그냥 괜찮음
프로젝트 연산
프로젝트 하는 애트리뷰트가 있다
조건에 맞는 애트리뷰트를 읽으면서 T`에 해당값들을 전부 복사해서 넣음
그 다음 중복가능성을 검사함(Distinct가 있는 경우)
중복검사 및 제거는 튜플을 정렬하여 작동함
이 밖에도 합집합 교집합 차집합도 있는데 매우 간단함
비용 함수
이러한 플랜들의 비용을 계산하는 함수
비용 계산을 위해서는 통계정보가 필요함 -> DB가 가지고 있음
필요한 통계정보에는 :
-
파일의 크기
-
레코드의 수(r), 블록 수(b), 파일에 대한 블록 인수(br)
-
기본 접근 방법과 기본 접근 애트리뷰트 (정렬, 인덱스 혹은 해시 여부)
-
저장된 인덱스 애트리뷰트 값에 대해 서로 다른 상이한 값의 수(d)
-
검색 투플 수 : 키 애트리뷰트의 경우 s = 1, 키가 아닌 애트리뷰트 : s = r / d
디스크 입출력 수만을 고려, 하지만 현재는 계산하는대 들어가는 비용도 고려해야 한다.
비용
선형탐색의 경우
- 키가 아닌 애트리튜트 = 블록수 b
- 키 애트리뷰트 = b / 2 (키라면 중간에 발견되면 절반만 가고 끝내면 되기떄문)
- 이원 탐색(Binary search) : log b
- 기본 인덱스 이용 : x + 1 (인덱스의 깊이 + 데이터)
- 해싱 함수를 이용한 비용 : 1 (사실은 1 + )
의미적 질의 최적화
구문 변환 규칙과 스키마의 제약조건을 이용
예 1
SELECT Sname
FROM S
WHERE Year ≥ 5
위 질의의 무결성 제약조건 : 1 ≤ Year ≤ 4 ⇒ 결과가 공백임을 예측 가능
질의를 실행조차 할 필요가 없음
예 2
Cno(S Sno=Sno E)
① Sno는 S의 기본 인덱스
② Sno는 E의 외래키이고 널이 아님 같은 조건이 있을 때, ⇒ Project Cno(E)
E는 Null이 없기에 모든 것이 조인에 참여함
따라서 Select 하는것은 E를 셀렉트 하는것과 똑같음
즉, E에 대해 프로젝션 하는것과 동일함
