📌 확률적 경사 하강법
- 점진적 학습, 온라인 학습
가중치(w), 절편(b)을 유지하면서 모델 업데이트 - ML/DL 알고리즘을 훈련하는 방법 (최적화)
- Stochastic Gradient Descent (SGD)
- 샘플 하나씩 꺼내서 경사를 따라 조금씩 이동 (훈련)
-> 반복 -> 훈련 세트 모두 완료 (1 epoch) -> 반복
📍 손실 함수
- ML 알고리즘의 나쁜 정도를 측정
-> 낮아지는 쪽으로 w, b의 값을 수정 - 분류 문제의 정확도는 손실 함수로 사용할 수 없음 (미분 불가)
-> 로지스틱 손실 함수 이용
📍 로지스틱 손실 함수
- 이진 크로스 엔트로피 손실 함수
- 타깃 = 1 : -log(예측 확률)
타깃 = 0 : -log(1 - 예측 확률)
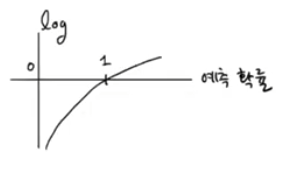 -> 미분 가능하므로 경사 하강 알고리즘 가능
-> 미분 가능하므로 경사 하강 알고리즘 가능
📍 SGDClassifier
-
확률적 경사 하강법의 분류 알고리즘
-
Data Set
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42
)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)- loss = 'log' : 로지스틱 손실 함수 지정
-> 로지스틱 회귀 모델을 훈련한다는 의미
-> SGD는 이 알고리즘을 최적화 - max_iter = 에포크 (훈련 set 사용 횟수)
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))0.773109243697479 // Train
0.775 // Test
- fit()을 다시 호출하면 기존의 w, b 초기화, 새로 학습
- partial_fit() 은 기존의 w, b를 유지하면서 훈련
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))0.8151260504201681 // Train
0.85 // Test
-> 정확도 향상, 점진적 모델 훈련
👉 but 과소적합, epoch 증가 -> 과대적합
- 규제에서 alpha 값에 따라 과대/과소적합이 변하는 것처럼
epoch 값에 따른 과대/과소적합의 적절 지점을 찾아 조기종료
📍 epoch와 과대/과소적합, 조기종료
- partial_fit()을 fit()없이 단독으로 사용할 시,
샘플(classes)의 갯수를 전달해야함
import numpy as np
sc = SGDClassifier(loss='log', random_state=42)
train_score = []
test_score = []
classes = np.unique(train_target)
for _ in range(0, 300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))import matplotlib.pyplot as plt
plt.plot(train_score)
plt.plot(test_score)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()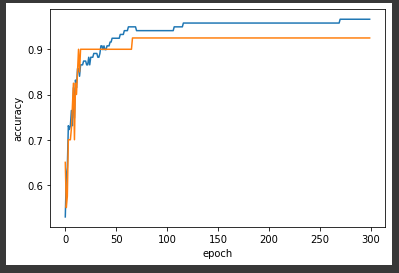
-> 훈련 set 100번 훈련 시 최적합
- tol: 반복을 멈출 조건
sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))0.957983193277311
0.925
