ML+DL
1.혼공ML+DL #3

scatter(x, y) 함수 -> 산점도k-최근접 이웃 알고리즘: 기본 5개의 주변 샘플들과 비교하여 가장 많은 클래스를 정답 클래스로 채택
2.혼공ML+DL #4

training-set / test-set 으로 슬라이싱해 사용fit 함수에는 training-set / score 함수에는 test-set슬라이싱할 때에는 sample data가 편향되지 않도록 ❗❗\-> 넘파이 사용 + 데이터 셔플 (입력과 타깃이 쌍으로)인덱스 셔
3.혼공ML+DL #5
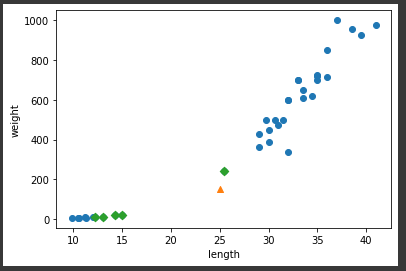
length, weight를 각각 1열로 정렬하여 length, weight 쌍으로배열을 나란히 붙여줌1x n / 0x nxm / 9x nxm 배열 생성 훈련 set, 테스트 set 나누어줌stratify 매개변수에 적절히 나누어져야하는 리스트를 입력k-최근접 이웃으
4.혼공 ML+DL #6
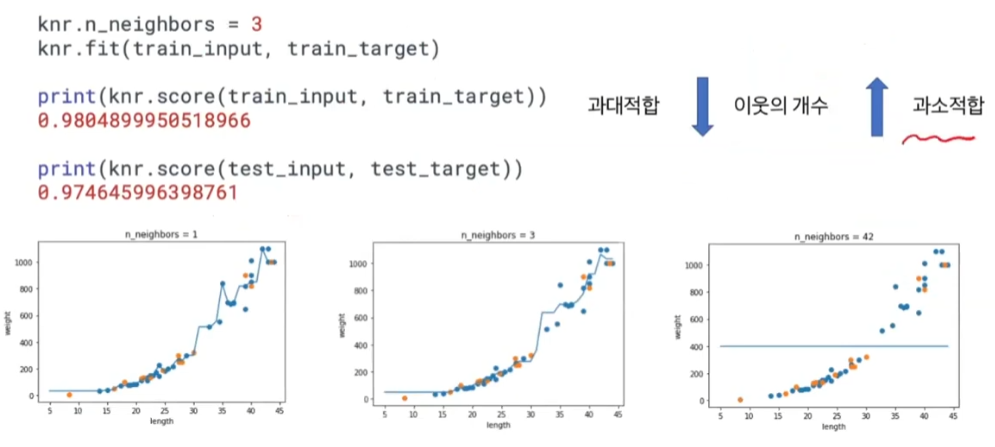
k-최근접 이웃 분류 vs k-최근접 이웃 회귀 분류는 다수결 채택, 회귀는 target 값의 평균 사이킷런 train_test_split()회귀에서는 적절히 섞는 stratify 필요 X이전과 다르게 입력, 출력 리스트가 1차원 넘파이 배열임샘플 x 특성 2차원
5.혼공 ML+DL #7
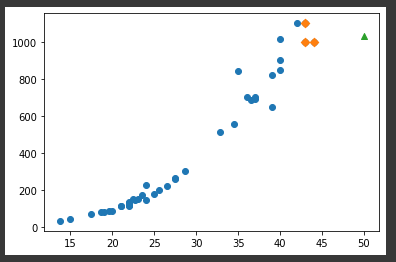
1033.33333333최근접 이웃의 데이터를 이용해 예측을 하기 때문에 훨씬 길게 입력된 길이에 비례하여 무게를 예측하지 못함👉 훈련 세트 범위 밖의 데이터에 대해 예측 불가lr = LinearRegression()lr.fit(traininput, train_tar
6.혼공 ML+DL #8
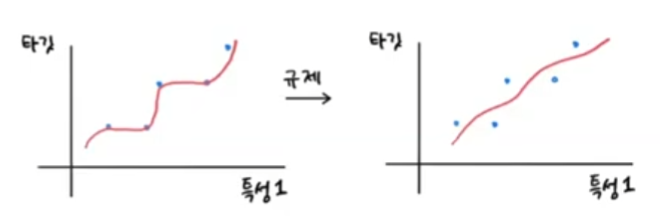
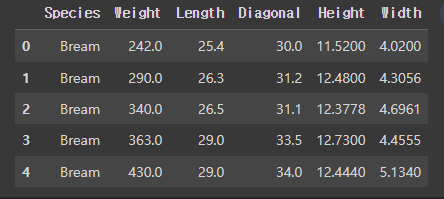
여러개의 특성을 사용 -> 길이, 높이, 무게특성 추가, 변경, 조합 = 특성 공학csv 파일 -> 판다스 데이터 프레임 -> 넘파이 배열 length, height, width\[ 8.4 2.11 1.4113.7 3.53 2. 15\. 3.82 2
7.혼공 ML+DL #9
📌 로지스틱 회귀
8.혼공 ML+DL #10
점진적 학습, 온라인 학습 가중치(w), 절편(b)을 유지하면서 모델 업데이트ML/DL 알고리즘을 훈련하는 방법 (최적화)Stochastic Gradient Descent (SGD)샘플 하나씩 꺼내서 경사를 따라 조금씩 이동 (훈련)\-> 반복 -> 훈련 세트 모두
9.혼공 ML+DL #11
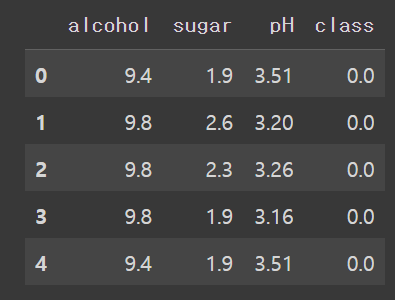
레드 와인(0) or 화이트 와인(1) 구분하기head() : 상위 5개 행 출력 info() : 행/열 크기, 컬럼명, 자료형등 정보 출력 describe() : 컬럼별 요약 통계량test_size : train - test 비율 설정(5197, 3) (1300
10.혼공 ML+DL #12
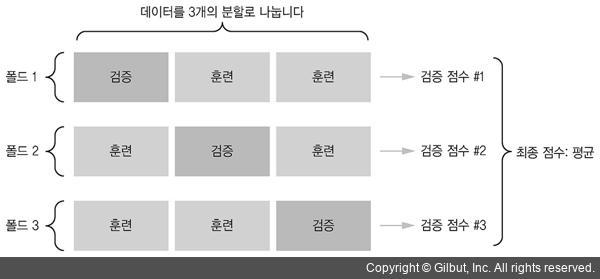
📌 검증(Validation) Set 훈련 Set 60% + 검증 Set 20% || 테스트 Set 20% 두 번 split 0.9971133028626413 0.864423076923077 📍 교차 검증 (only ML) 데이터를 n개의 폴드로 나누고 순서대로
11.혼공 ML+DL #13
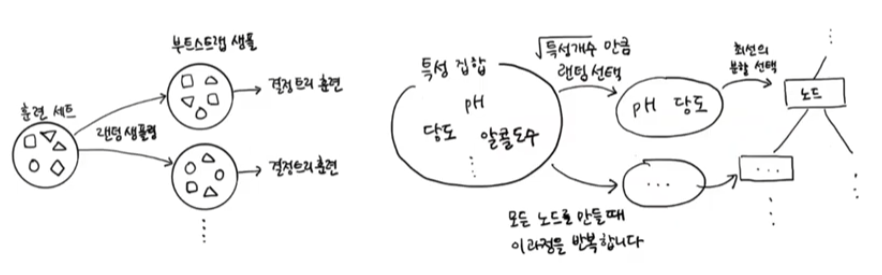
앙상블(Ensemble) : 여러 개의 모델을 사용해서 각각의 예측 결과를 만들고 그 예측 결과를 기반으로 최종 예측결과를 결정하는 방법배깅(Bagging) : 분할정복(divide and conquer and combine)과 같은 것: 전체 데이터를 여러개로 분할
12.혼공 ML+DL #14

2차원 images -> 넘파이 배열로 다운로드(300, 100, 100) // samples x 가로 x 세로한 열을 출력 (맨 위 이미지의 맨 윗부분) 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
13.혼공 ML+DL #15

클러스터(cluster) : 군집클러스터링 : 군집화. 개체 -> 군집 그룹핑k개의 중심을 무작위로 정해서 가까운 샘플들을 그룹핑\-> 그룹마다 다시 중심점을 구해서 이동, 반복\-> 한 종류만으로 이루어진 군집들이 생성3차원->2차원 배열로 변경해서 수행 n_clus
14.혼공 ML+DL #16
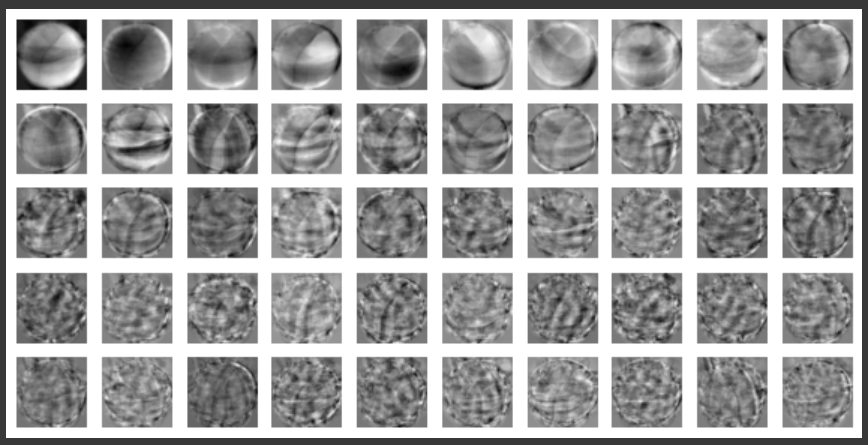
차원벡터 : 원소의 갯수 배열 : 축의 갯수 Principal Component Analysis주성분 : 데이터가 가장 많이 위치하는 방향, vector특성이 2개일때 주성분은 1개 = 차원 축소주성분의 요소 갯수는 특성의 갯수와 동일n_components : 찾을 주
15.혼공 ML+DL #17

10개 클래스28 x 28 흑백 픽셀6만개 샘플(60000, 28, 28) (60000,)(10000, 28, 28) (10000,)이미지 샘플 10개 출력해보기 9, 0, 0, 3, 0, 2, 7, 2, 5, 5스케일링 0~255 픽셀값 -> 0~1, 28 x 28
16.혼공 ML+DL #18
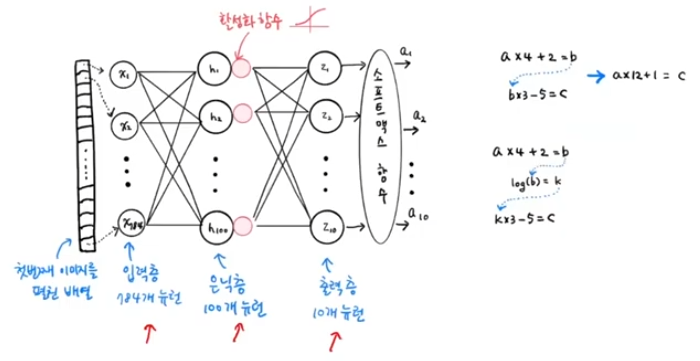
Deep Neural Network이미지, 텍스트 같이 비정형화된 데이터 -> 표현학습입력층 -> 은닉층 (여러개) -> 출력층다중분류 : softmax / 이진분류 : sigmoidrelu == max(0, z) : z<=0 이면 0, z>0 이면 z 와 동일
17.혼공 ML+DL #19
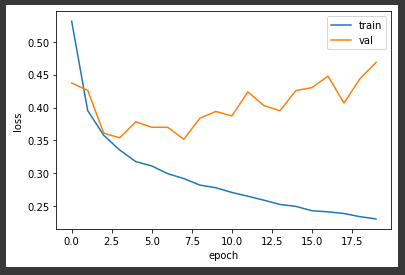
Model Setdict_keys('loss', 'accuracy', 'val_loss', 'val_accuracy')history 객체 : loss, accuracy 속성각 epoch 마다의 속성값 저장되어있음검증 손실도 확인 (val set)accuracy\-> 훈
18.혼공 ML+DL #20
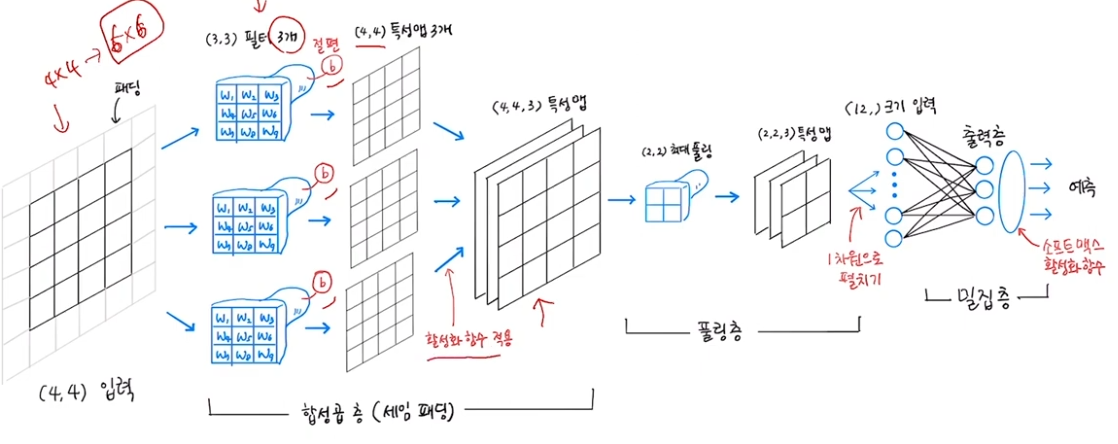
모든 특성에 대해x, 특성 3개씩에 가중치/절편 연산 (필터)\-> 가중치(=커널) 3개, 절편 1개10개 입력 -> 8개 출력2차원 합성곱 (3x3 필터)특성맵 (특징맵) : 2차원 합성곱의 출력(2x2)필터 여러개 적용 -> 특성맵 여러개패딩 : 입력을 0으로 둘러
19.혼공 ML+DL #21
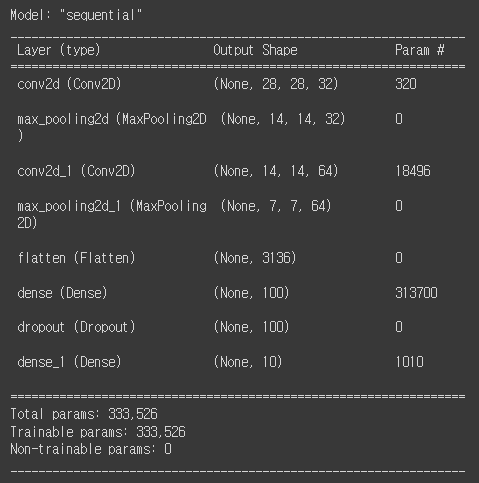
DATA SET샘플 하나에 대해 32개 필터kernel_size=3 : 3x3x1 필터 (input depth=1과 동일)padding = 'same' : 28x28x32 특성맵 (input과 동일)MaxPooling2D(2) : 14x14x32 특성맵 (높이,너비 축
20.혼공 ML+DL #22
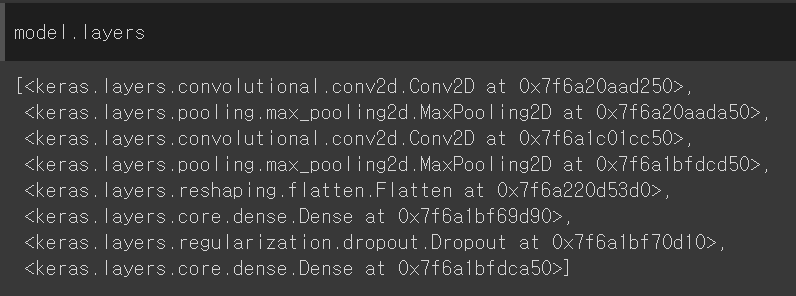
모델 layers8개의 객체를 리스트로 가짐conv 층의 가중치 크기 확인weights0 = 가중치, weights1 = 절편(3, 3, 1, 32) (32,)\-> 3x3x1 필터 32개가중치 값의 분포 (3x3x1x32 개)vmin보다 작은 값은 vmin으로, vm
21.혼공 ML+DL #23
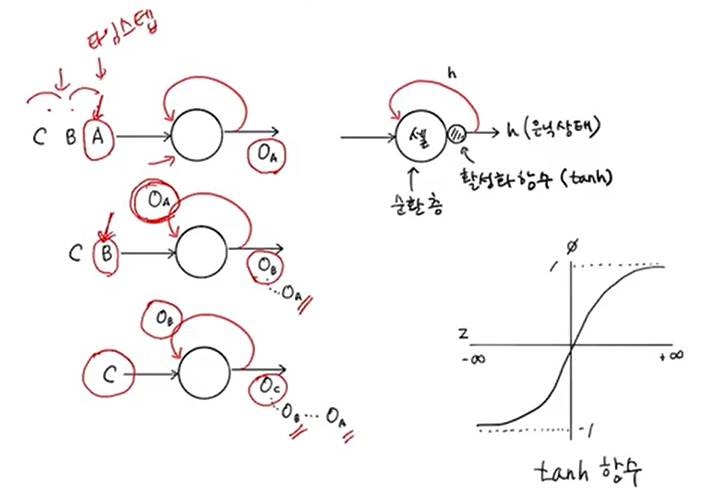
이전 샘플의 출력을 재사용하는 순환되는 고리가 있는 신경망 여러 개의 뉴런을 하나의 큰 셀(=순환층)로 표현셀의 출력값 = 은닉상태 h (특성맵과 같음)활성화 함수 tanh : -1~1 (sigmoid : 0~1 )time step 1 : 샘플A -> 뉴런 ->
22.혼공 ML+DL #24
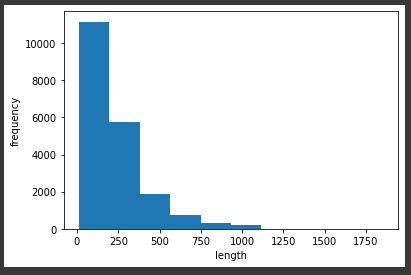
📌 IMDB 영화 리뷰 데이터 분석 감성분석 긍정/부정 text data set 각 25000개 📍 Data 불러오기 (25000,) (25000,) [1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, ... [1 0 0 1 0 0 1 0
23.혼공 ML+DL #25
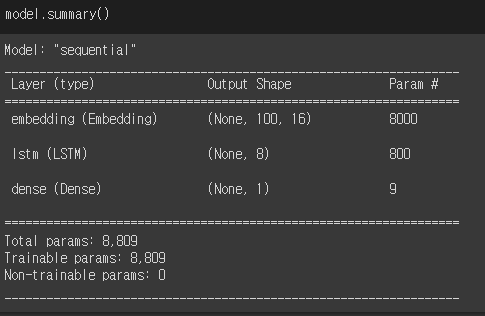
LSTM 셀은닉상태(h) x 셀(w) 4개 -> 셀(cell)상태셀 상태 에서 순환되는 상태 값 LSTM(8) : 8개 뉴런, dropout 지정LSTM Param( 16개 입력 x 8개 뉴런 완전연결\+8개 뉴런 x 8개 은닉상태\+8개 절편 ) x 4개 셀= 800