📕(강의) Beyond ML/DL pipeline
Ensemble
- 여러 실험을 하면 여러가지 모델로 여러 결과가 나옴
- 싱글 모델보다 더 나은 성능을 위해 서로 다른 여러 학습 모델을 사용하는 기법
- 현업에서 많이 쓰이지는 않음 → 성능 < 효율 & 최적화인 경우가 많다.
Variance & Bias
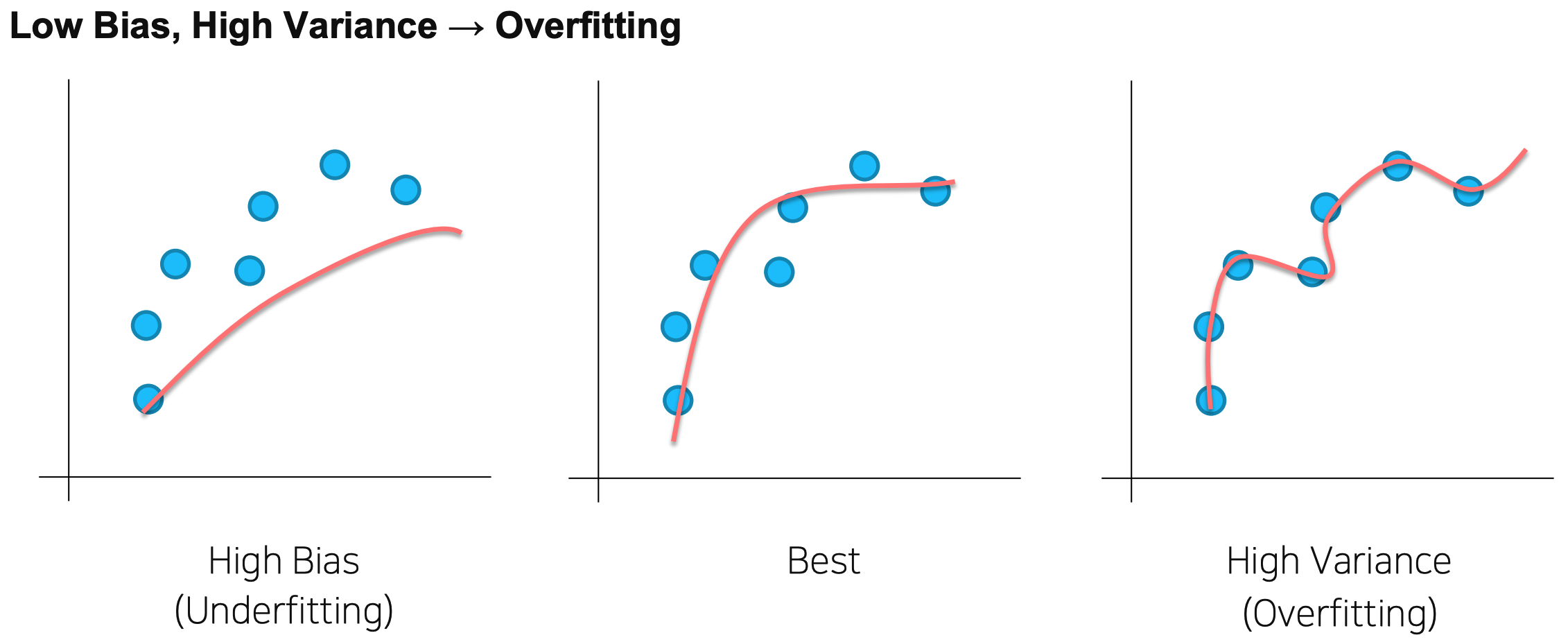
- High Bias : boosting 기법 사용 → 병렬적인 학습이 아닌 계속 좀 더 나은 방향으로 fitting 되는 ensemble 기법 e.g. gradient boosting, xgboost, lgbm ...
- High Variance : bagging 기법 사용 → data sample을 나누어 각각 학습, 취합 후 평균 (일반화 효과) e.g. random forest
Model Averaging (Voting)
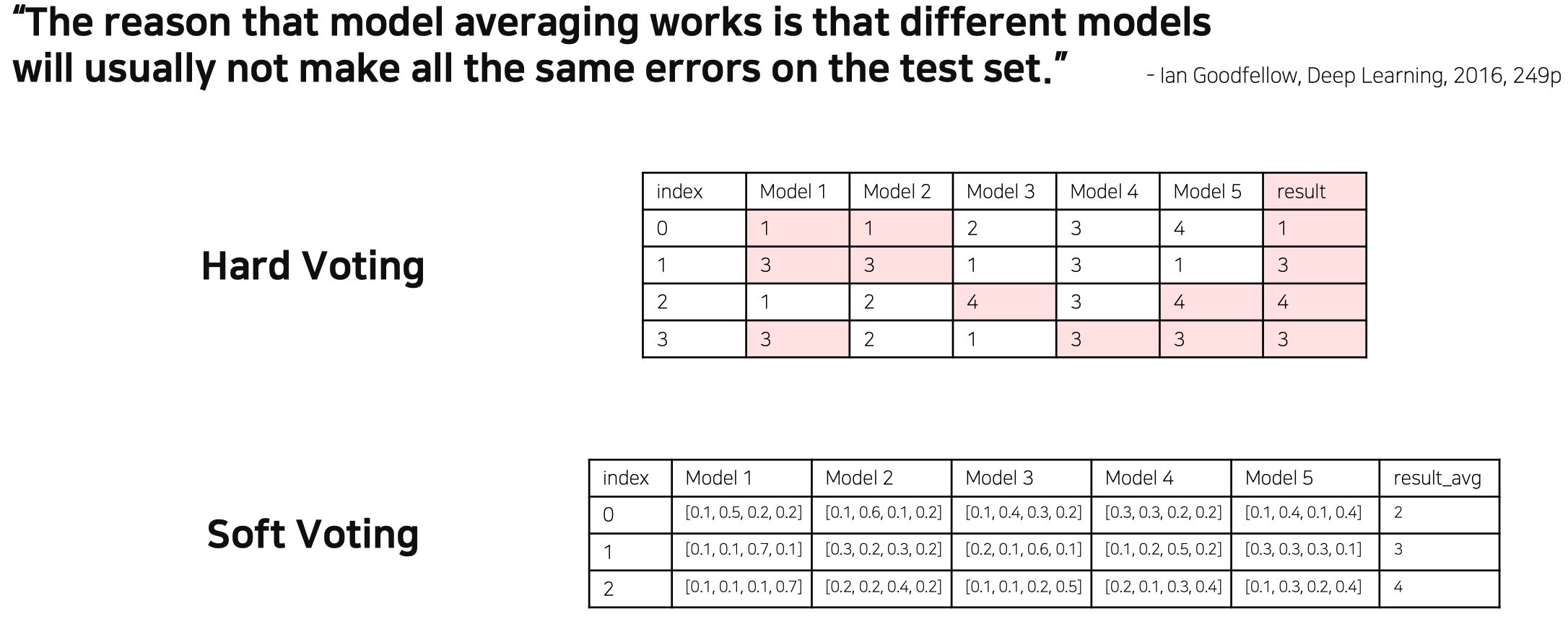
- 각각의 모델마다 특성(경향성)이 다르기 때문에, 모두 ensemble하면 더 좋은 성능을 기대할 수 있다.
Hard Voting : 높은 빈도의 class만 고려
Soft Voting : 모든 class 확률 고려 - 보편적으로 soft voting을 많이 사용
Cross Validation
- 훈련 셋과 검증 셋을 나누면서 그만큼 학습데이터 수가 줄어듬
- 훈련 셋과 검증 셋을 분리는 하되, 검증 셋을 학습에 활용
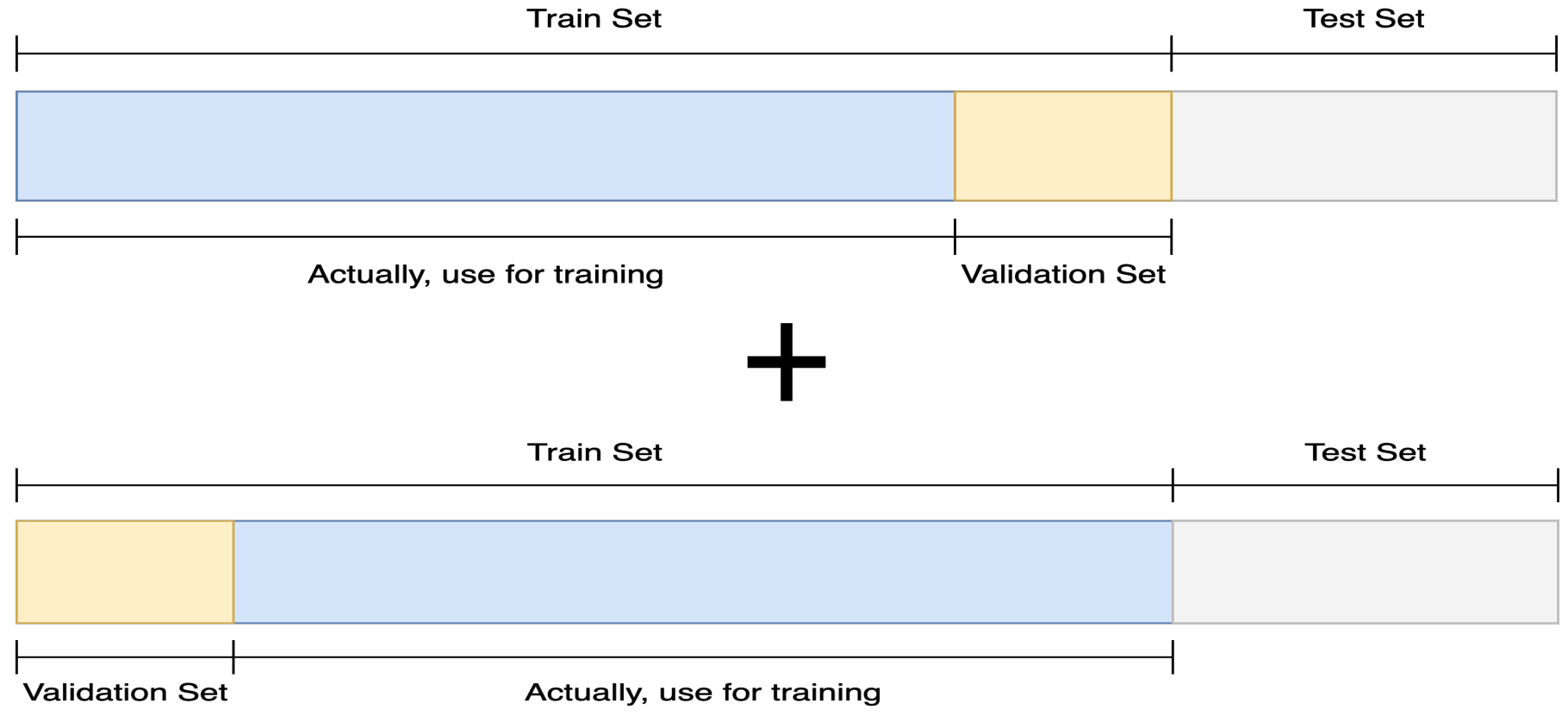
- CV score : 일반적인 모델 성능 평가 지표
Stratified K-Fold Cross Validation
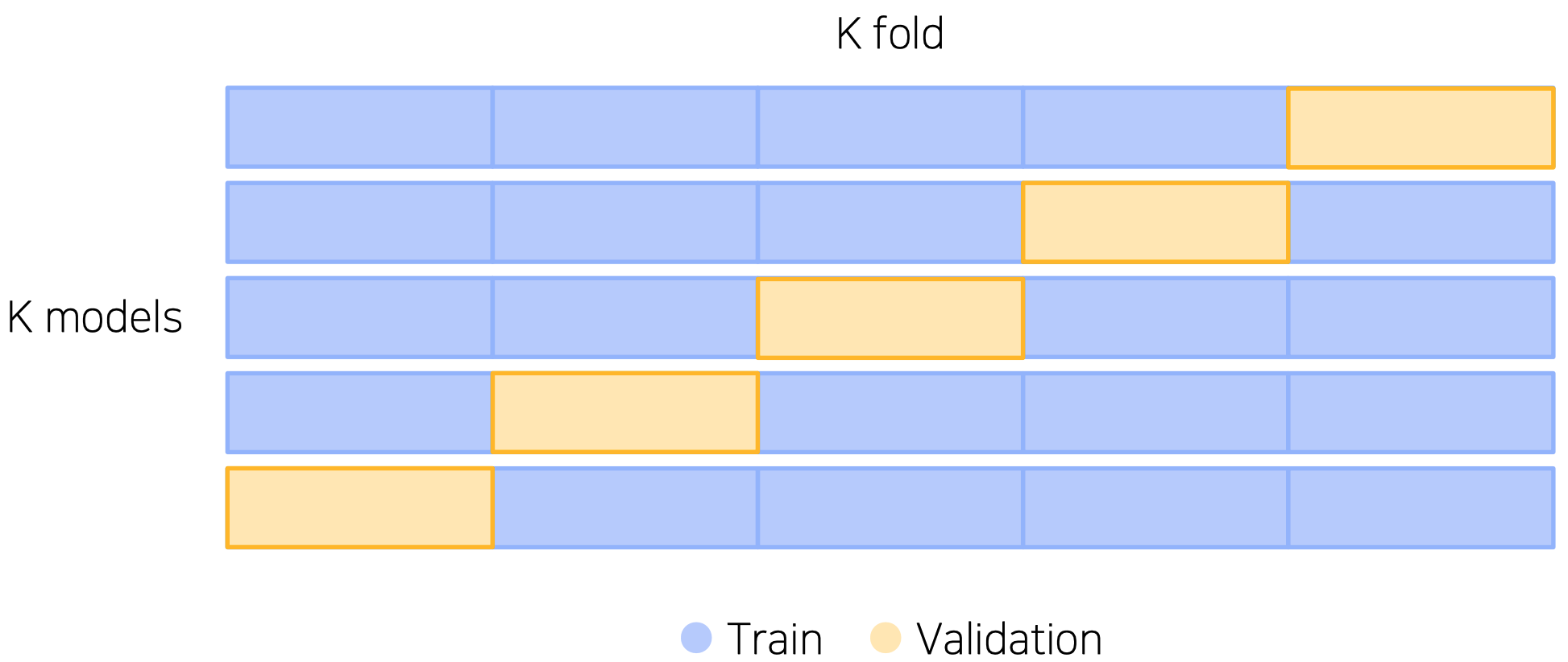
- split 시 class distribution balance까지 고려
- K는 일반적으로 5로 시작 → 너무 크면 모델 수 증가, computational cost가 커질 수 있음
TTA (Test Time Augmentation)
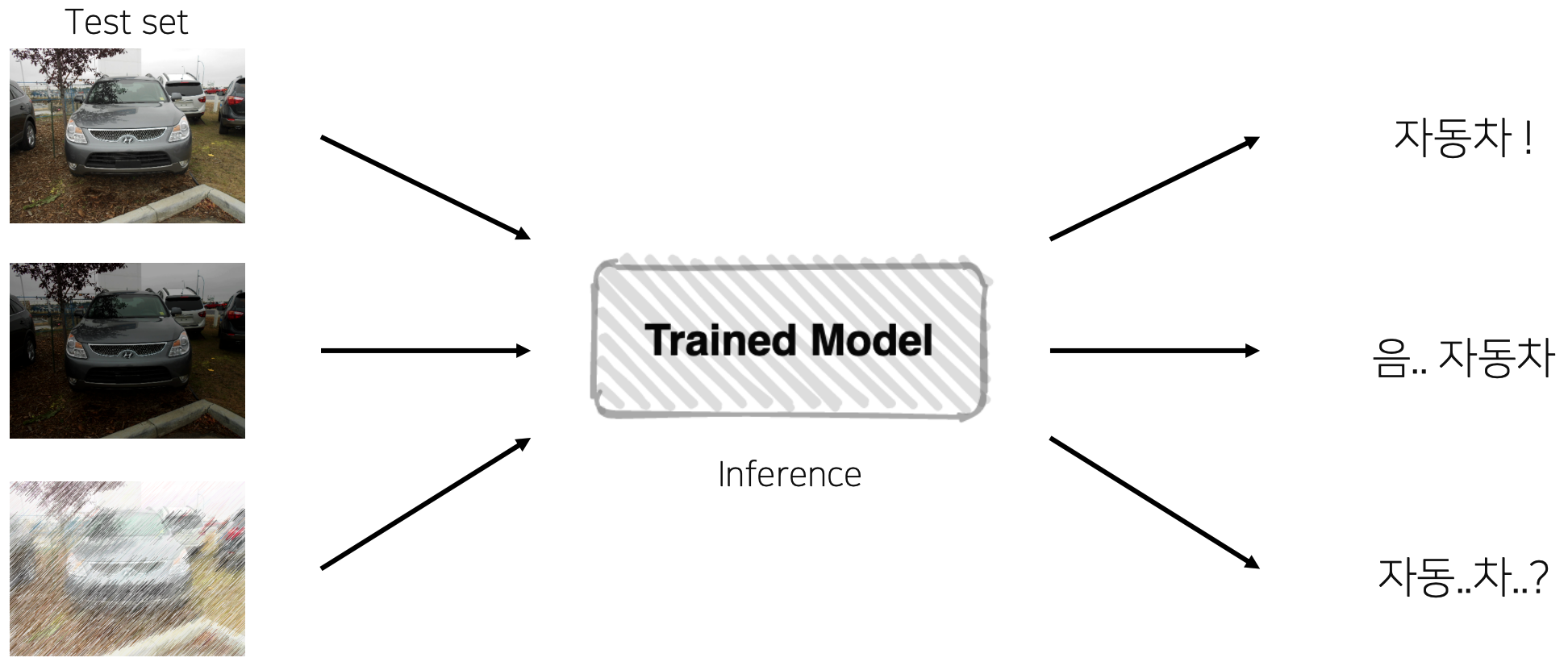
- training 단계에서도 다양성 및 일반화를 위해 augmentation을 활용했었다. 그럼 test 단계에서도 noise 섞인 data를 모델에 넣었을 때 같은 성능을 보장할까? → robust 당위성 체크
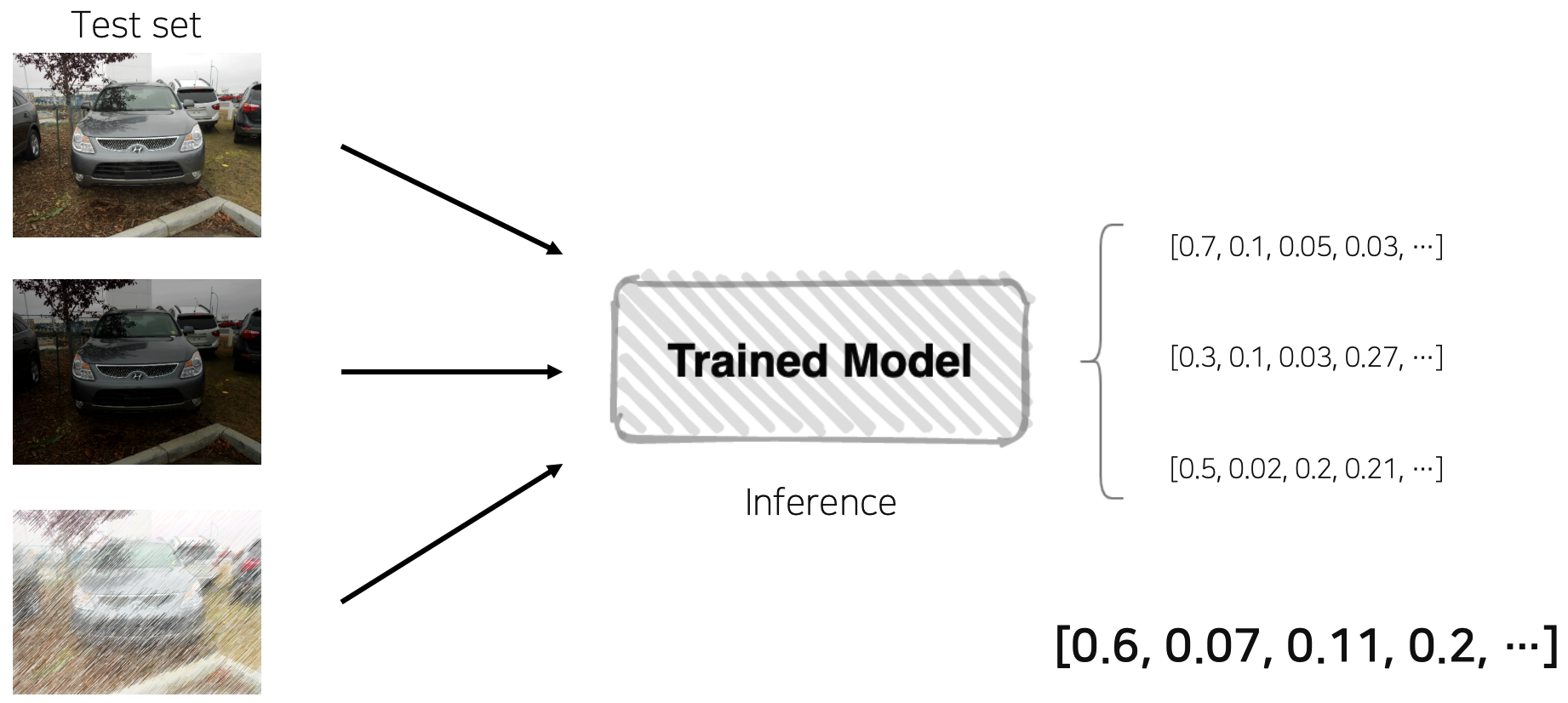
- test image를 augmentation 후 model inference 수행, 출력된 결과들을 ensemble하면 일반화된 test output이라고 판단 가능
성능과 효율의 trade-off
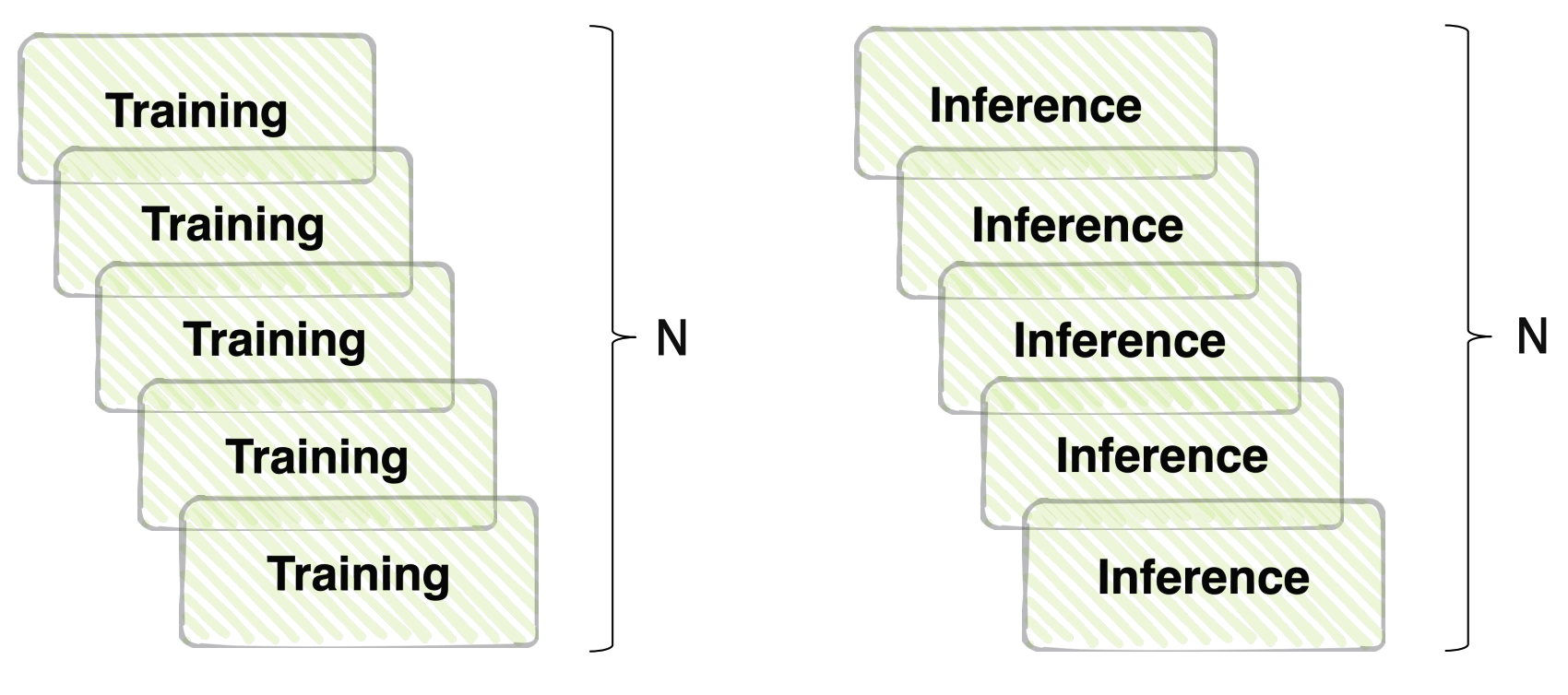
- ensemble 효과는 확실히 있지만 그 만큼 training, inference 시간이 배로 소모
Hyperparameter Optimization
- 많이 하지 않는다; 투자 시간 대비 효율이 낮기 때문
Hyperparameter?
- system의 mechanism에 영향을 주는 주요한 parameter
- batch size, optimizer paramters, regularization, dropout, k-fold, hidden layer size, leraning rate, loss parameters, etc.
- 변경할 때 마다 학습 재진행 → 시간과 장비가 충분하다면... 해보겠지만... 일반적으로는 충족 못하는 환경
- grid search, random search 등의 방법론들이 존재
Optuna

- hyperparameter optimization tool
