Full Stack ML Engineer
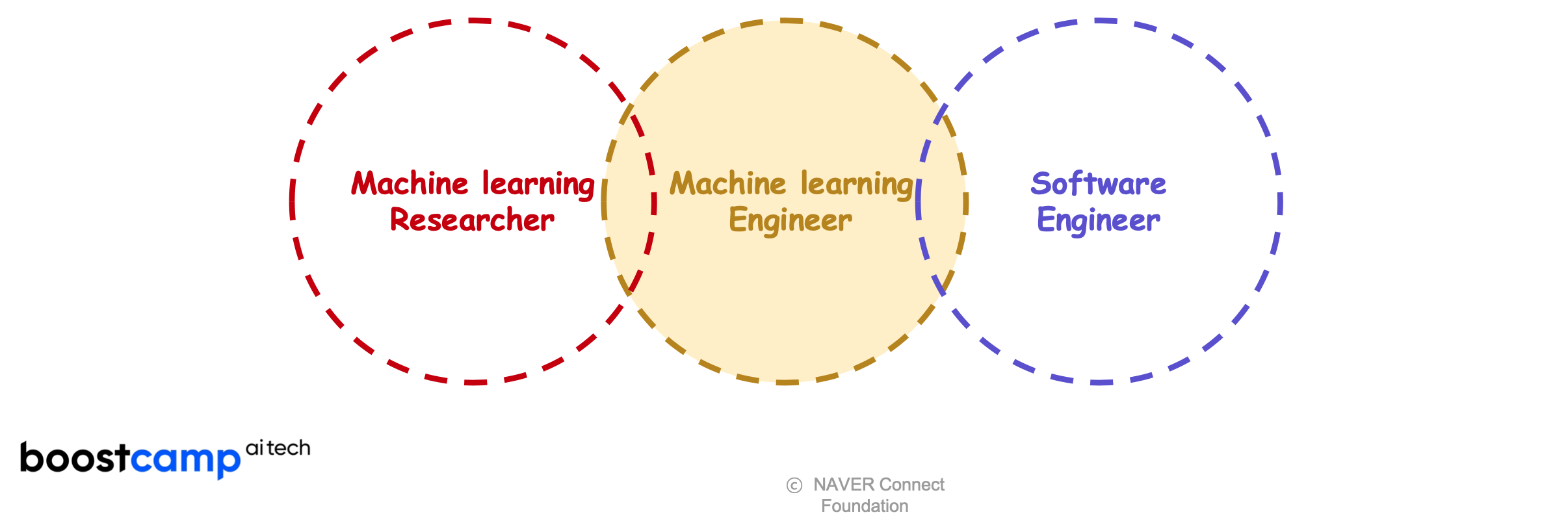
Full Stack ML Engineer?
-
DL research를 이해하고 + ML product로 만들 수 있는 engineer
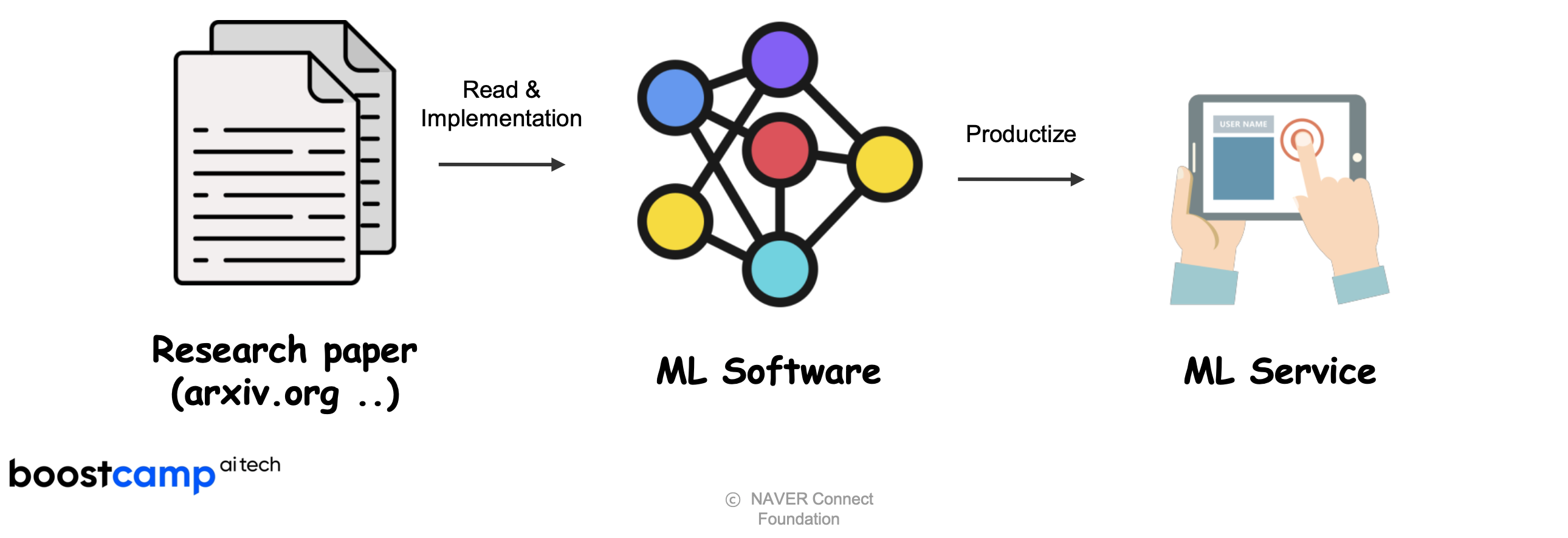
-
Full stack ML service (back-end level)
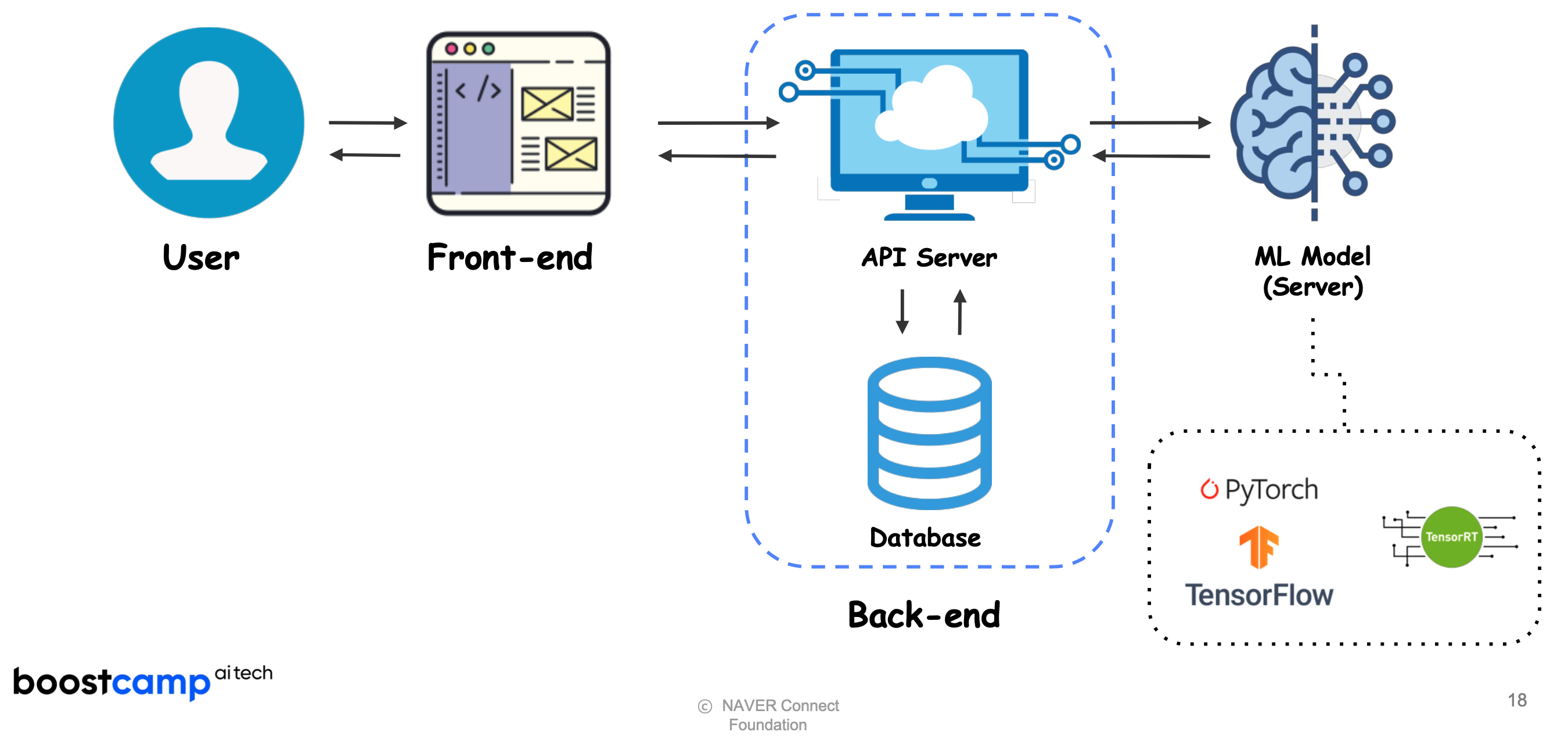
-
Full stack ML Edge device service (front-end level)
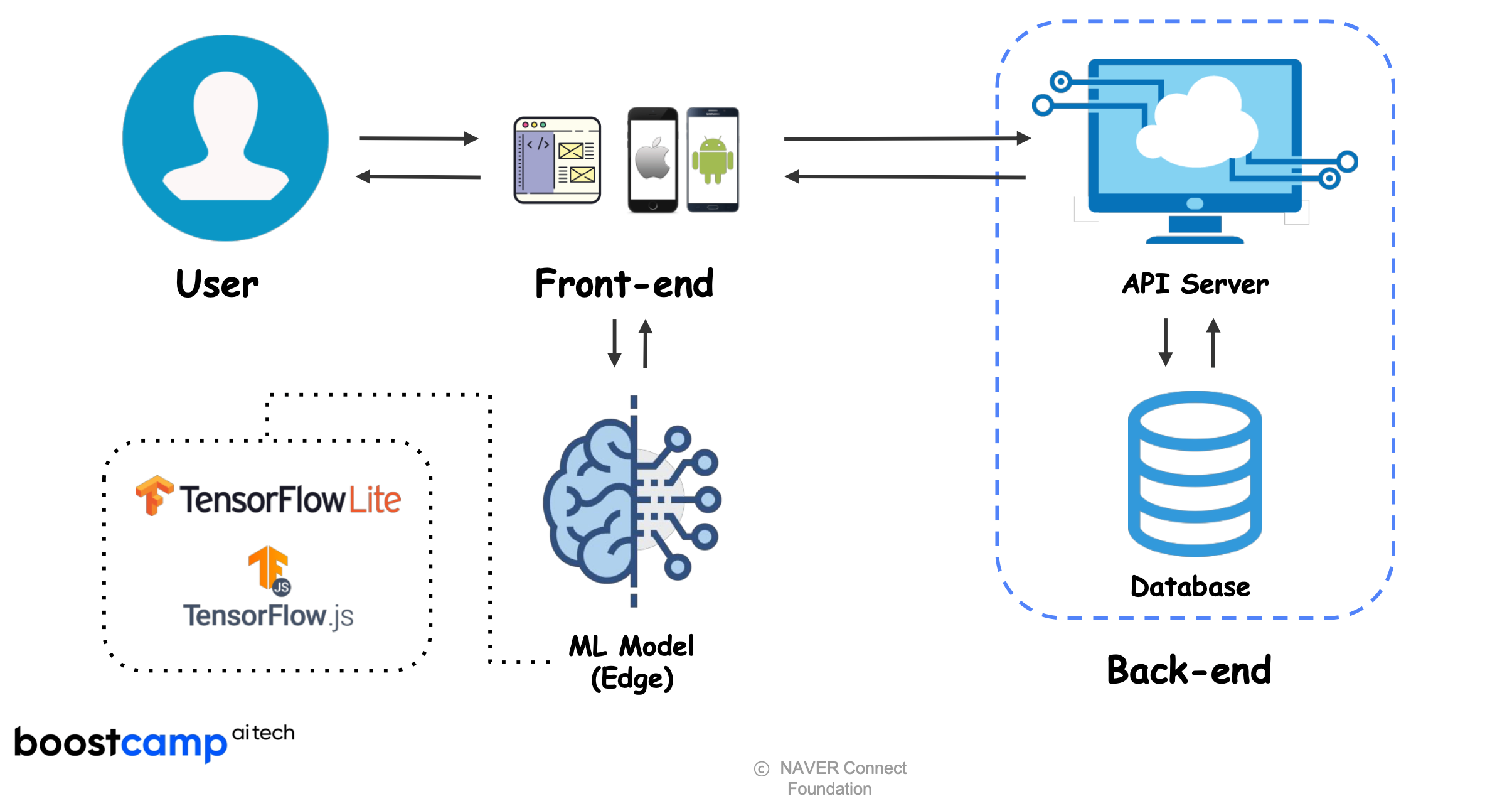
-
Data collection with web service tool (ML training pipeline)
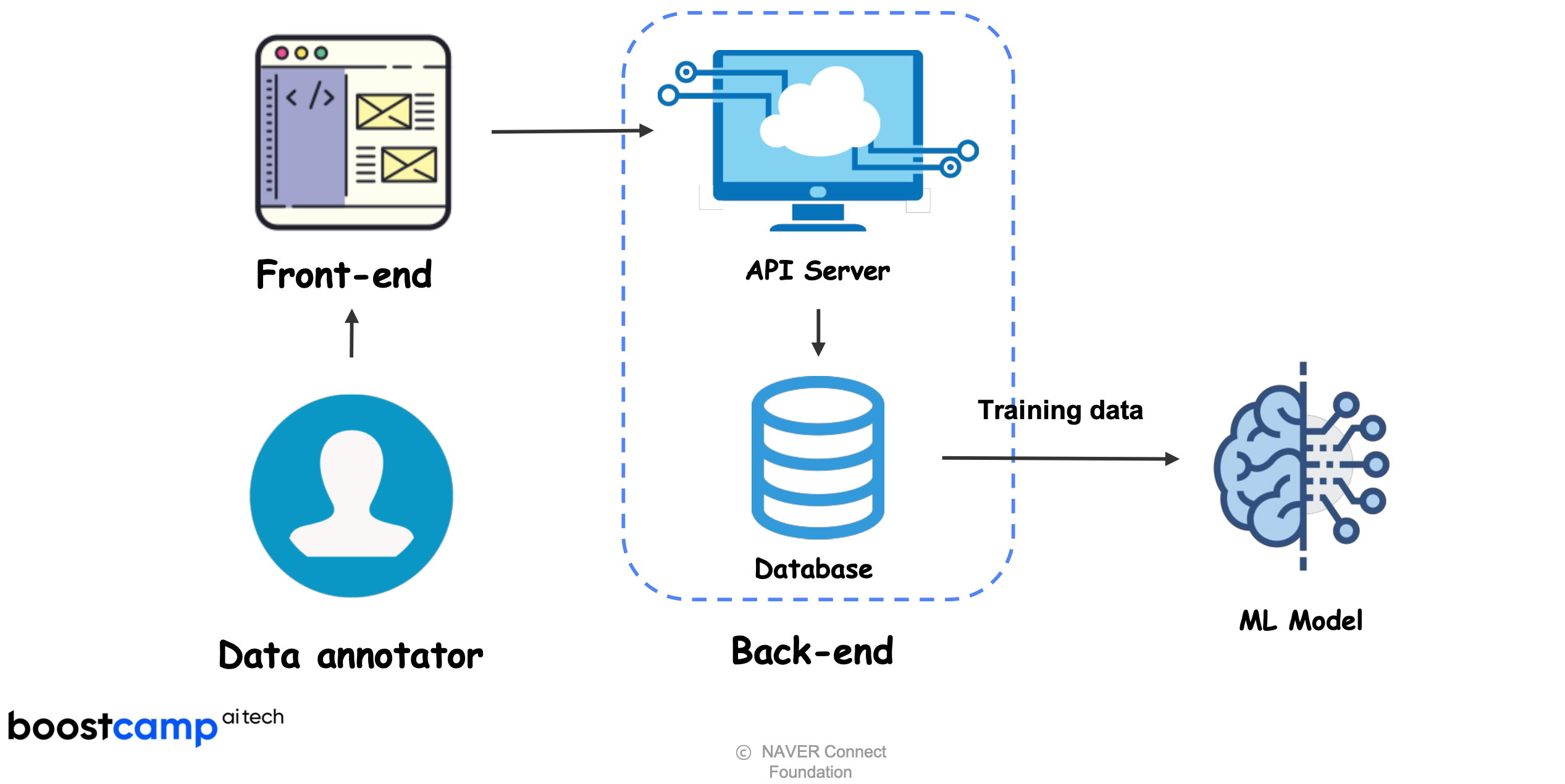
ML Product
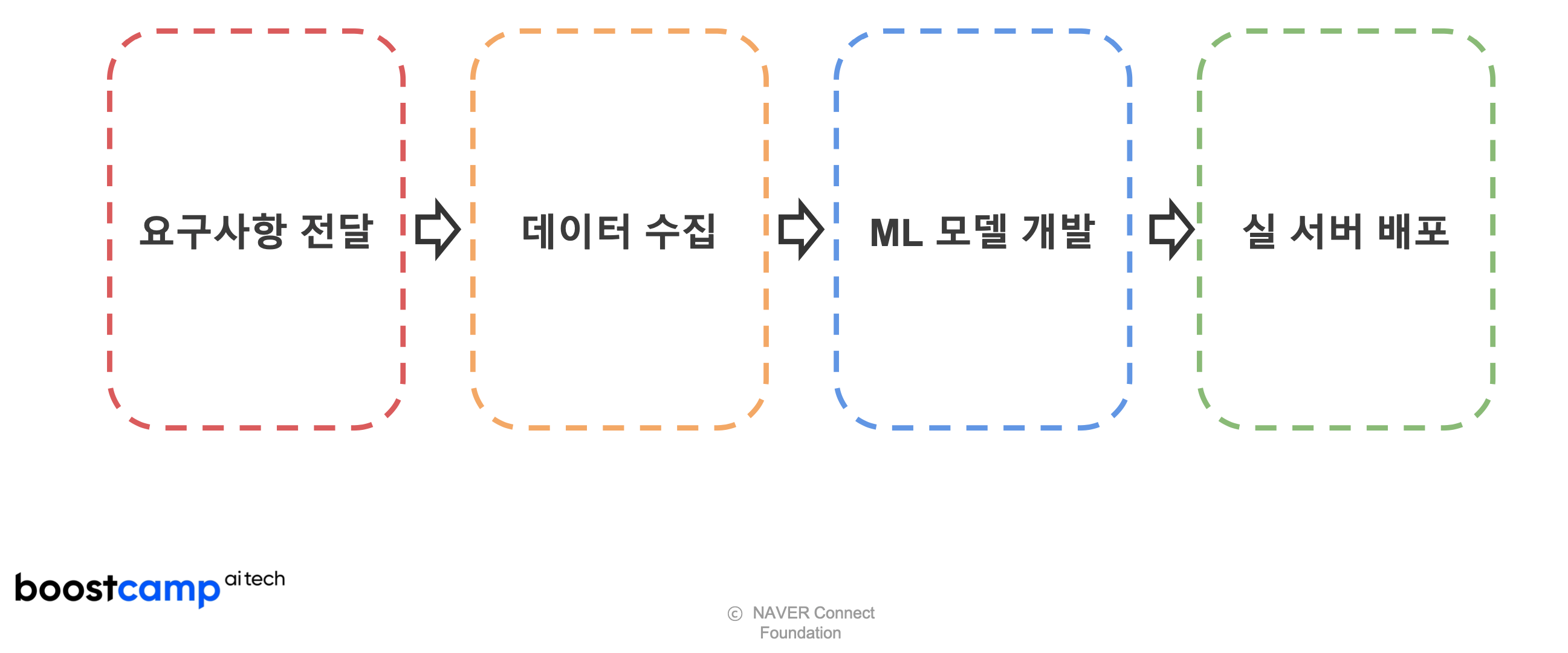
요구사항 전달: 고객 요구사항 수집 단계
- 고객사 미팅(B2B) or 서비스 기획(B2C)
- 제품에 대한 요구사항 전달
- 추상적 단계- 요구사항 + 제약사항 정리
- 기능 상세 요구 사항, 제약 사항, 일정 정리- ML Problem으로 회귀(중요)
- 요구사항은 실생활의 문제
- ML이 풀 수 있는 형태의 문제로 회귀하는 작업
데이터 수집: 훈련/평가 data 취득 단계; 사실상 pipeline에서 가장 오랜 시간과 인력 투자
- Raw data 수집
- 요구사항에 맞는 data 수집
- bias 없도록 분포 주의, 저작권 주의- Annotation tool 기획 및 개발
- data labeling tool
- model input/output 고려
- 작업속도/정확도 극대화- Annotation guide 작성 및 운용
- 이럴 땐 어떻게 annotation 하나요? 에 대한 대답이 되는 문서
- 간단명료한 guide를 작성하도록 노력
ML model 개발: ML model 개발 단계
- 기존 연구 Research 및 내재화
- 풀고자 하는 문제와 비슷한 형태가 있는지, 어느 정도 수준으로 되고 있는지 논문을 찾아보고 이해하는 단계
- 적절한 연구를 재현하여 내재화, baseline model 확보- 실 데이터 적용 실험 + 평가 및 피드백
- baseline model의 benchmark와 수집된 데이터 적용된 model 간의 간극을 평가 및 모델 수정을 통해 줄이는 과정- 모델 차원 경량화 작업
- 모델 단계의 경량화
- Distillation
- Network surgery : network를 잘라내서 얇게 만드는 작업 (Network pruning)
실 서버 배포: Service server 적용 단계
- Engineering 경량화 작업
- TensoRT 등의 inference framework 적용
- Qunatization- Research code 수정 작업
- Research code 정리
- Deploy code와 interface 맞추는 작업- Model version 관리 및 deploy wkehdghk
- Model version 관리 system
- Model deploy 주기 결정 & update 자동화 작업
피어세션 정리
- ground rules 수립
- 논문 리뷰, 알고리즘 공부 등 계획
- KLUE 대회 준비
학습 회고
- 번 아웃 조심!
