TL; DR
- Input features
- BERT에서 사용된 MLM 전략과 XLNet 에서 사용된 PLM 전략을 결합한 학습 방법을 제시
1. Introduction 요약
저자들은 BERT에서 사용된 MLM(Masked Lanugage Modeling) 전략과 XLNet 에서 사용된 PLM(Permuted Language Modeling) 전략을 결합한 학습 방법을 제시하며, 두 전략의 장점을 모두 취할 수 있다고 말합니다.
- MLM : 특정 단어를 맞추도록 학습시키는 방법 (BERT)
- PLM : 특정 단어의 순서를 맞추도록 학습시키는 방법 (XLNet)
MLM 학습 방식의 장점은 masked된 token에 대해 bidirectinal context를 이용하여 효율적으로 학습할 수 있다는 것입니다. 그러나 단점은 맞추어야 할 token들의 의존 관계를 무시한다는 것입니다. 즉, 순서를 신경쓰지 않고 loss를 계산합니다.
PLM 학습 방식은 특정 위치 이전 token만들 보고 이후 token 들을 맞추도록 학습하여 MLM 방식의 의존관계를 가져가며 학습시킬 수 있는 장점이 있습니다. 그러나 이 방식의 자체적 단점으로는 전체 문장의 순서는 학습 시킬 수 없다는 것입니다. 즉, 특정 시점 이전의 단어들만을 가지고 미래의 단어를 예측하여 loss를 계산합니다.
이 두 방식을 unified한 관점에서 새로운 학습방식을 개발하였고 이 architecture를 MPNet으로 명명하였습니다.
<그림1: MLM 학습 방식>
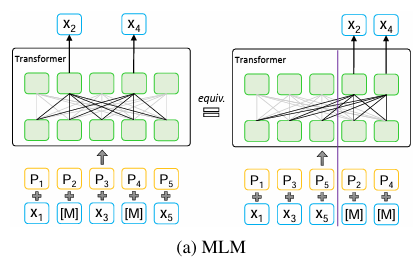
MLM 학습 방식을 position에 따라 나타내면 위와 같습니다. 왼쪽의 masked된 token들을 맨 오른쪽으로 보내면, 오른쪽 그림과 같이 학습된다고 볼 수 있습니다.
MLM의 단점으로 Output Dependency라는 특징을 언급하였습니다. MLM 학습 방식은 masked된 단어들을 독립적으로 예측하고 이에 대한 loss를 합산합니다. 이는 문장 context 정보를 loss에 포함시키지 못하고 있음을 의미합니다.
직관적으로 생각해볼 때도 앞에 어떤 단어가 나오는지에 따라 뒤의 단어가 달라질 수 있습니다. 그러나 MLM에 이러한 상황은 고려하지 않습니다.
<그림2: PLM 학습 방식>
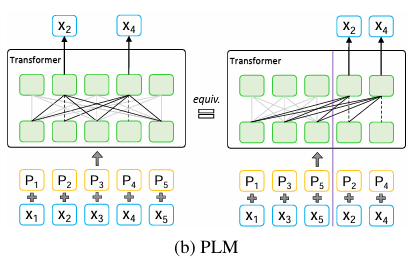
PLM 학습 방식을 position에 따라 나타내면 위와 같습니다. 랜덤으로 shuffle된 문장 순서에서 특정 position 이후의 token은 target이 됩니다. MLM과는 다르게 자신의 position 이전의 단어의 정보만을 이용하여 학습됩니다.
Input consistency는 같은 의미를 가진 다양한 문장 variation에 대해 일관된 결과를 가져다주는 것을 의미합니다.
PLM의 단점으로 Input Consistency라는 것을 언급하였습니다. 실제 test 환경에서 보게 될 문장들은 full sentence 정보를 이용할 수 있는데, PLM 방식은 full sentence 정보를 이용하여 학습시키지 못하여 이에 대한 정보를 활용해 추론할 수 없습니다. MLM 방식은 부분적으로 나마 이러한 sentence 정보를 이용할 수 있습니다.
Architecture 요약
<그림3: MPNet Architecture>
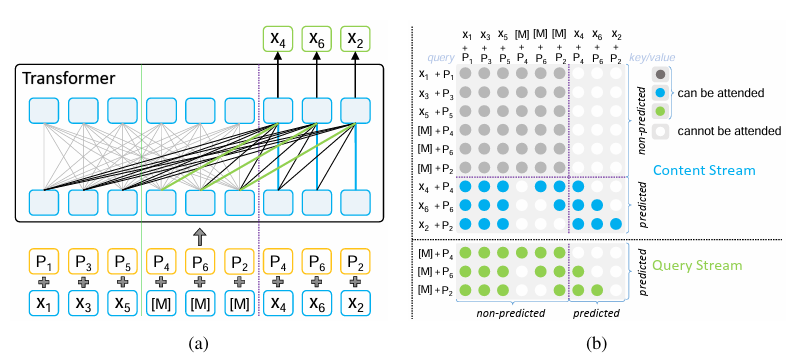
input sequence x1, x2, x3, x4, x5, x6 (n=6)로 가정하면 아래와 같이 token과 position이 구성됩니다.
- (x1, x3, x5, [M4], [M6], [M2], x4, x6, x2), (pos1, pos3, pos5, pos4, pos6, pos2, pos4, pos6, pos2)
특정 포지션 (C=3) 이후 token은 predicted-token으로 간주되며 같은 길이의 masked token이 중간에 삽입 됩니다.
학습 pair 예시는 아래와 같습니다.
-
target : [x4, pos4]
feature : [(x1, pos1), (x3, pos3), (x5, pos5), (M6, pos6), (M2, pos2)]
-
target : [x6, pos6]
feature : [(x1, pos1), (x3, pos3), (x5, pos5), (x4, pos4), (M2, pos2)]
-
target : [x2, pos2]
feature : [(x1, pos1), (x3, pos3), (x5, pos5), (x4, pos4), (x6, pos6)]
→ 전체 context를 이용해서 맞추지만 자신 token 이전 token들에 대해서는 position 정보만 제공되고 token 정보는 masked되어 제공되지 않습니다.
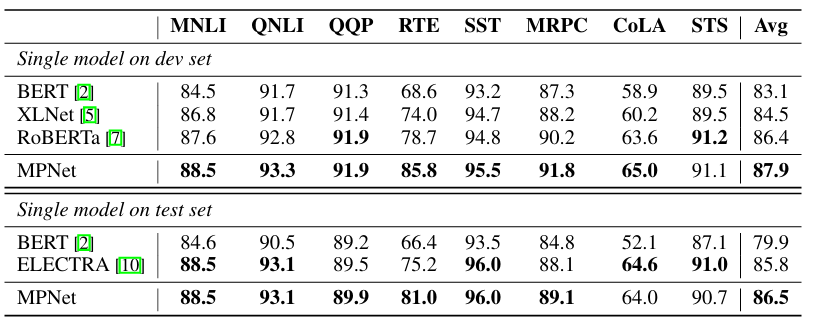
해당 architecutre를 통해 다양한 task에서 널리 사용되는 RoBERTa, XLNet 대비 더 높은 성능을 보여주었다고 합니다.
