논문리뷰
1.[논문리뷰] Deep Neural Networks for YouTube Recommendations
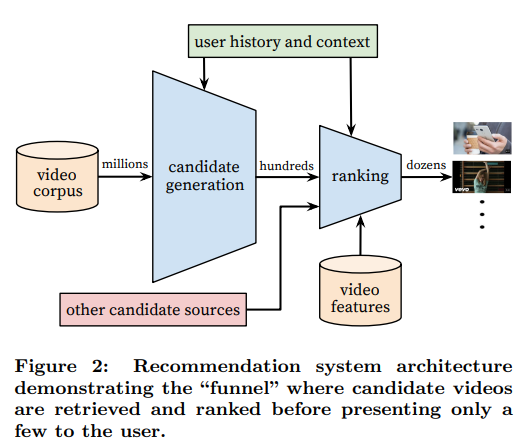
Deep Neural Networks for YouTube Recommendations
2.[논문리뷰] Attention Is All You Need (Transformer)
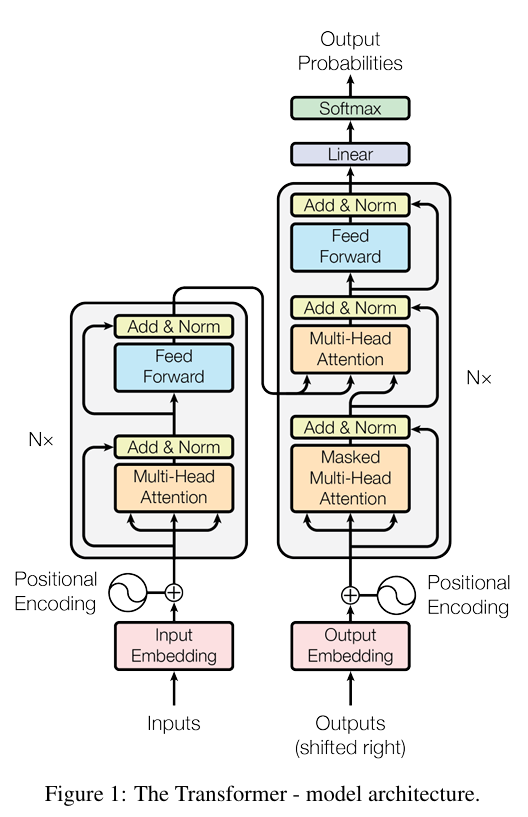
Model featuresEmbedding Vector에 대한 행렬곱 연산을 적용해 토큰 간 interaction 정보를 학습 (Attention)Deocding block 학습 시 특정 토큰 이전의 토큰에 대해서는 masking 처리(0으로 대체)저자들은 시퀀스 기반
3.[논문리뷰] Improving Language Understanding by Generative Pre-Training (GPT-1)
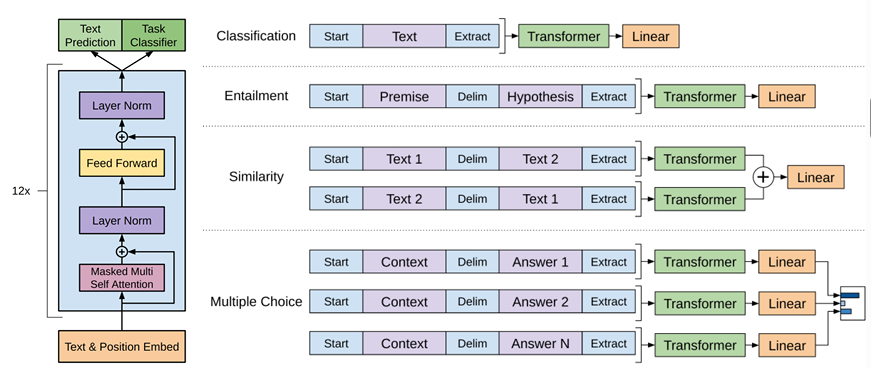
Model features준지도학습과 지도학습을 동시에 수행 (Next Token Prediction + Task Classification)Masked Self-Attention을 통해 NSP시 예측할 토큰 이전의 토큰의 정보만 사용하도록 함Next Token Pre
4.[논문리뷰] Pre-training of Deep Bidirectional Transformers for Language Understanding (BERT)
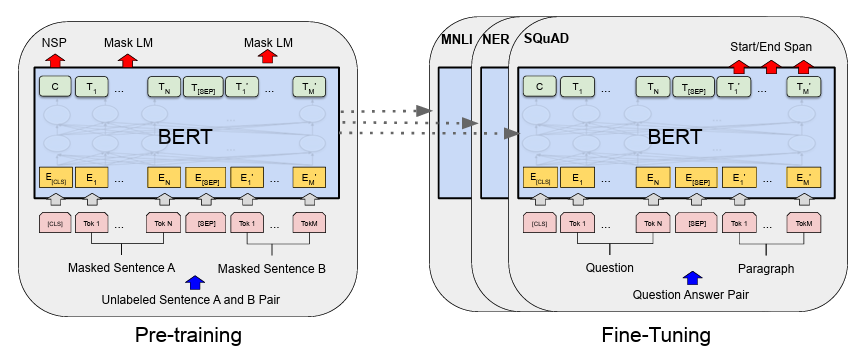
Model features양 방향의 모든 단어 정보를 활용하여 NSP task를 수행하도록 설계Pre-training 후 Fine-Tuning을 하는 방식을 통해 높은 성능을 보이도록 설계BERT는 Pre-Training & Fine-Tuning 단계를 나누어 학습함으
5.[논문리뷰] Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers (MiniLM)
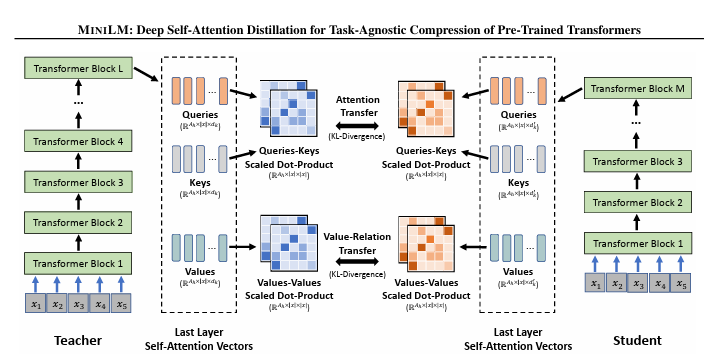
<모델 아키텍처 요약>마지막 Transformer block의 attention 정보만 사용하여 distilationSelf-attention between Query & Key, Self-attention betwwen Values 이라는 추가적인 self-at
6.[논문리뷰] Masked and Permuted Pre-training for Language Understanding (MPNet)

TL; DR Input features BERT에서 사용된 MLM 전략과 XLNet 에서 사용된 PLM 전략을 결합한 학습 방법을 제시 1. Introduction 요약 저자들은 BERT에서 사용된 MLM(Masked Lanugage Modeling) 전략