MySQL 명령어
기존에 올렸던 MySQL 포스팅이 존재하지만 새롭게 알게된 것들을 정리하고자 한다.
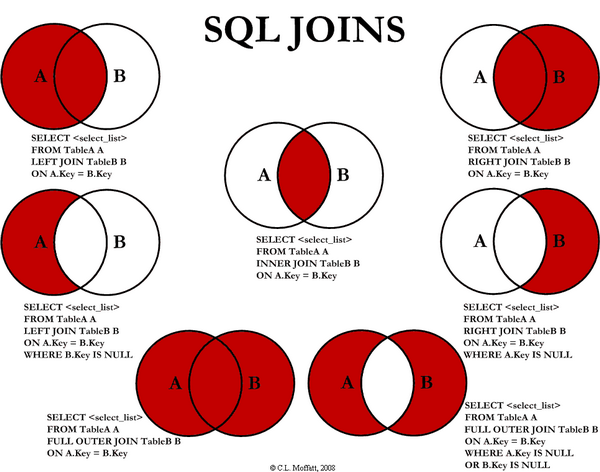
JOIN
Join은 관계형 데이터베이스의 핵심으로 여러번 봐도 과하지 않다고 판단.
WHERE
OR, AND
조건을 여러 개를 걸 수 있다.
LIKE
검색 기능을 구현할 때 주로 사용할 것으로 예상되는 명령어이다. 예를 들어
SELECT * FROM orders WHERE order_number LIKE '%2020%'위의 명령어는 orders 테이블의 모든 컬럼을 참조해오는데 이때 조건은 order_number 필드 값 중 2020이 포함된 row를 참조해오게 된다. 즉 필드 값에 대한 검색 기능으로 구현 가능하다.
ORDER BY
데이터를 정렬할 때 사용하는 것으로 ASC는 오름차순, DESC는 내림차순이다. 입력하지 않는다면 오름차순으로 정렬된다.
LIMIT
참조해오는 row의 수를 특정할 수 있다.
인자를 하나만 전달할 경우 가져올 개수에 해당하고 두 개를 전달할 경우 시작점과 개수가 된다.
SELECT * FROM orders LIMIT 10;
SELECT * FROM orders LIMIT 10,10;첫 번째 명령은 10개를 참조해오는 것이고 두 번째 명령은 11번 레코드부터 10개를 참조해오는 것이다. 참고로 id값과는 다르게 0번부터 시작한다. list slicing 개념과 유사하다고 이해하면 편할 것이다.
쿼리문 작성하면서 느낀 점
또한 쿼리문을 직접 작성하면서 느끼는 것은 생각보다 조합에 자유로운 편이며 그렇기 때문에 쿼리문을 작성할 때 주의깊게 해야할 것으로 판단된다. 자유도가 높은 만큼 잘못된 방식으로 쿼리를 짜게 되면 데이터를 참조해오는 과정에 있어서 비효율적인 작업이 진행될 여지가 있기 때문이다.
ORM을 사용하는 것에 있어서도 Django의 경우 prefetch_related나 select_related를 사용하였을 때 자동으로 생성해주는 쿼리문이 최적의 효율을 가져온다고 말할 수 없다. 때문에 성능을 높히기 위해서 직접 쿼리문을 작성하는 경우도 존재한다는 전의 가르침이 이해가 되었다.
DB Hit를 최소화하고 테이블을 참조하는 횟수를 최소화하여 즉 데이터를 최적의 방법으로 가져오기 위한 노력을 해야할 것으로 생각된다. 해당 포스팅은 새로운 것을 알게되면 이 곳에 추가할 예정이다.
