
잘못된 점이 있다면 알려주세요.😁
이 글은SQL레벨업이라는 책을 읽고 정리한 글입니다.
쿼리는 질의라는 뜻으로 보통 SQL문의 SELECT에 해당한다. 크게는 SQL 전체를 의미하기도 한다. 이러한 SELECT문을 보다 빠르고 효율적으로 실행되도록 하기 위한 것을 쿼리 최적화 작업이라 생각하면 될 것이다. 요즘은 프레임워크에서 제공되는 여러 ORM이 존재하지만 ORM은 완벽하지 않다는 평가를 받는다. 또한 ORM이 문법만 익힌다면 굉장히 편리한 것은 사실이지만 공부하는 입장에서 DB에서 어떻게 동작하는지 파악하는 것은 쉬운 일이 아니다.
거기에 더불어 직접 쿼리를 작성하고 실행하여도 각각의 DBMS 쿼리 평가 엔진에 따라 실행되는 모습은 상이할 수 있다. 즉 쿼리 최적화를 이루기 위해서는 DB에서 해당 쿼리가 어떻게 실행되는지 파악하는 것이 일순위이다. 그것을 알기 위해 DBMS 아키텍처 중 쿼리 평가 엔진에 대해 공부할 필요가 있다.
쿼리 최적화가 필요한 이유
그런데 우리가 이렇게까지 쿼리 최적화를 해야하는 이유는 뭘까? 쿼리 최적화를 하는 이유는 데이터를 빠르게 가져오기 위함이다. 데이터를 빠르게 가져와야하는 이유는 무엇일까?
어떤 서비스의 한 페이지를 한 명의 사용자가 보기를 원한다. 이 때 페이지에는 여러 데이터가 담겨 있을 것이고 해당 데이터를 DB에서 빠르게 가져와야만 사용자에게 빠른 서비스를 제공할 수 있다. 하지만 데이터를 가져오는 속도가 느리다면 한 명의 사용자에게 제공되는 서비스의 속도 또한 느려질 것이다. 그러나 이러한 서비스를 한 명의 사용자가 아닌 많은 사람이 이용한다면 문제는 더욱 커지게 된다. 데이터를 가져오기 위해 쿼리를 날리는 행위는 DB 커넥션을 맺은 상태에서 이루어진다. 그러나 DB의 커넥션은 제한되어 있다. 즉 한 번 데이터를 가져올 때 빠르게 가져오고 사용중이던 커넥션을 다른 쪽에서 사용할 수 있도록 빠르게 반환 해야 한다.
결국 비용 감소와 서비스의 질을 높히기 위해서 쿼리 최적화는 필수적인 것이다.
쿼리 평가 엔진
쿼리 평가 엔진은 SQL 구문을 분석하고 어떤 순서로 데이터에 접근할지를 결정한다. 즉 우리가 DB에 쿼리를 전달하게 되면 먼저 쿼리 평가 엔진의 파서를 통하게 된다.
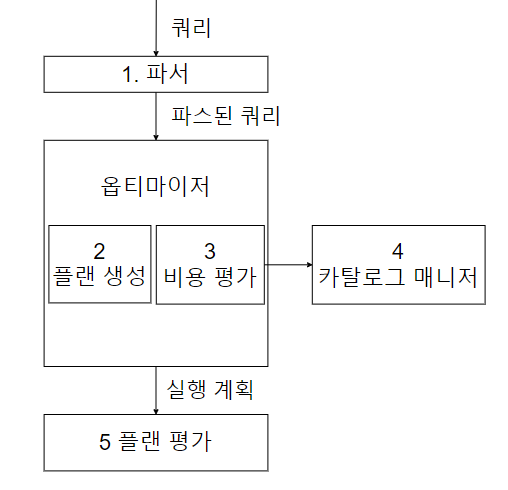
파서
파서의 역할은 구문 분석이다. 즉 우리가 전달한 쿼리는 작성한 사람에 따라 각기 다른 방식으로 작성되어 있고 그것을 파서를 통해 정형적인 형식으로 변환한다. 이 단계에서 쿼리의 문법이나 없는 테이블, 컬럼 등이 작성되어 있으면 실행을 중단 시킨다. 이는 프로그래밍 언어의 컴파일 시점에서 실행되는 것과 동일하다.
옵티마이저
먼저 설명한 파서를 통해 파싱된 쿼리는 옵티마이저로 전송된다. 개발자가 쿼리를 작성하면서 가장 많이 들여다보게 될 것이 이 옵티마이저이다. 옵티마이저는 한국어로 최적화이다. 옵티마이저는 파싱된 쿼리를 어떻게 실행하는 것이 가장 효율적일지 판단한다. 즉 실행계획을 수립한다.
실행 계획을 수립할 때 옵티마이저는 인덱스 유무, 데이터 분산, 편향 정도, 매개변수 등의 조건을 고려해서 실행 가능한 계획을 수립하고 그 중 가장 낮은 비용의 실행 계획을 선택한다.
카탈로그 매니저
이 때 인덱스 유무, 데이터 분산, 편향 정도, 매개변수 등의 중요한 정보를 제공하는 것이 카탈로그 매니저이다. 카탈로그란 DBMS의 내부 정보를 모아놓은 테이블들로, 테이블 또한 인덱스의 통계 정보가 저장되어 있다.
그러나 옵티마이저는 완벽하지 않다.
옵티마이저는 우리가 쿼리 최적화를 시킴에 있어서 많은 도움을 주지만 완벽하지는 않다. 그렇기 때문에 쿼리를 작성하고 옵티마이저의 실행 계획을 보면서 쿼리를 수정하는 것이다. 이러한 이유 중 가장 큰 이유는 카탈로그 매니저가 제공해주는 정보에 있다. 카탈로그 정보는 갱신이 필요하다. 즉 테이블의 정보가 시간이 지나면서 많은 데이터의 변경이 이루어졌음에도 카탈로그 정보가 업데이트 되지 않았다면 카탈로그 정보는 과거의 것으로 현재 쿼리의 실행 계획을 수립함에 있어 잘못된 계획을 수립하도록 할 수 있다는 것이다. 즉 데이터가 많이 바뀌면 카탈로그 정보도 함께 갱신되어야 한다.
그러나 카탈로그 정보가 최신의 정보임에도 SQL 구문이 너무 복잡하게 작성되어 있다면 최적의 계획을 선택하지 못 할 수도 있다.
실행 계획 보는 법(간단하게)
먼저 명령어는 EXPLAIN 실행할 쿼리 이다. 실행시키고 싶은 쿼리 앞에 EXPLAN 명령어를 작성하고 실행시키면 옵티마이저가 선택한 최적의 실행 계획을 보여준다. 해당 명령어가 아니더라도 사용하는 DB 툴에 따라 버튼을 누르면 실행 계획을 볼 수 있다. 예시로 드는 이미지는 DataGrip을 사용한 것이다.
해당 서적의 예제 코드 중 가장 복잡해 보이는 쿼리를 가지고 왔다. (해당 쿼리가 좋아서 가져온 것이 아닌 실행 계획 보는 법을 위해 가져온 것 뿐이다.)
EXPLAIN
SELECT
TMP_MIN.cust_id,
TMP_MIN.price - TMP_MAX.price AS diff
FROM
(
SELECT
R1.cust_id,
R1.seq,
R1.price
FROM
Receipts R1
INNER JOIN
(
SELECT
cust_id,
MIN(seq) AS min_seq
FROM
Receipts
GROUP BY cust_id
) R2
ON R1.cust_id = R2.cust_id
AND R1.seq = R2.min_seq
) TMP_MIN
INNER JOIN
(
SELECT
R3.cust_id,
R3.seq,
R3.price
FROM
Receipts R3
INNER JOIN
(
SELECT
cust_id,
MAX(seq) AS min_seq
FROM
Receipts
GROUP BY cust_id
) R4
ON R3.cust_id = R4.cust_id
AND R3.seq = R4.min_seq
) TMP_MAX
ON TMP_MIN.cust_id = TMP_MAX.cust_id;
실행 계획 보는 법 중 내가 주로 보는 두 가지만 살펴보려 한다. 자세한 내용은 다른 블로그의 글에도 많기 때문에..ㅎㅎ
내가 주로 보는 영역은 주로 rows와 Extra 부분이다.
rows에 해당하는 수는 작을 수록 좋다. rows는 테이블에서 들여다보는 row의 갯수를 의미한다. 즉 그 수가 크면 클 수록 해당 테이블에서 많은 수의 row를 거친다는 뜻으로 실행 시간은 늘어난다. 이상적인 rows의 값은 원하는 결과 값의 수와 가까운 것이다. 물론 언제나 그렇듯 쉬운 일은 아니다.
Extra 부분은 예시 이미지에서 보이듯 Using where, Using index 등등의 값이 있다. 이 외에도 여러 많은 값이 존재한다. 예시에 나온 where 같은 경우는 쿼리문 조건에 의한 필터가 이루어진 경우 index 같은 경우는 테이블의 설정된 인덱스를 타는 경우를 뜻한다. 인덱스를 타는 경우는 언제나 늘 좋다고 할 수는 없다. 하지만 대부분의 경우 인덱스를 타는 경우 비용적으로 유리한데 이는 모집합의 데이터가 많을 수록 인덱스 스캔이 유리하기 때문이다. 즉 데이터 수가 많지 않을 때는 full scan이 유리하고 많을 때는 index scan이 유리하다는 것이다. 이처럼 Extra에 어떤 값이 있는지 확인하고 index를 타지 않는 항목이 있다면 인덱스를 타도록 하여 쿼리를 수정해서 쿼리 최적화를 시킬 수 있다.
아래 이미지는 DataGrip에서 제공하는 것으로 실행 계획을 다이어그램으로 보여주는 것이다.
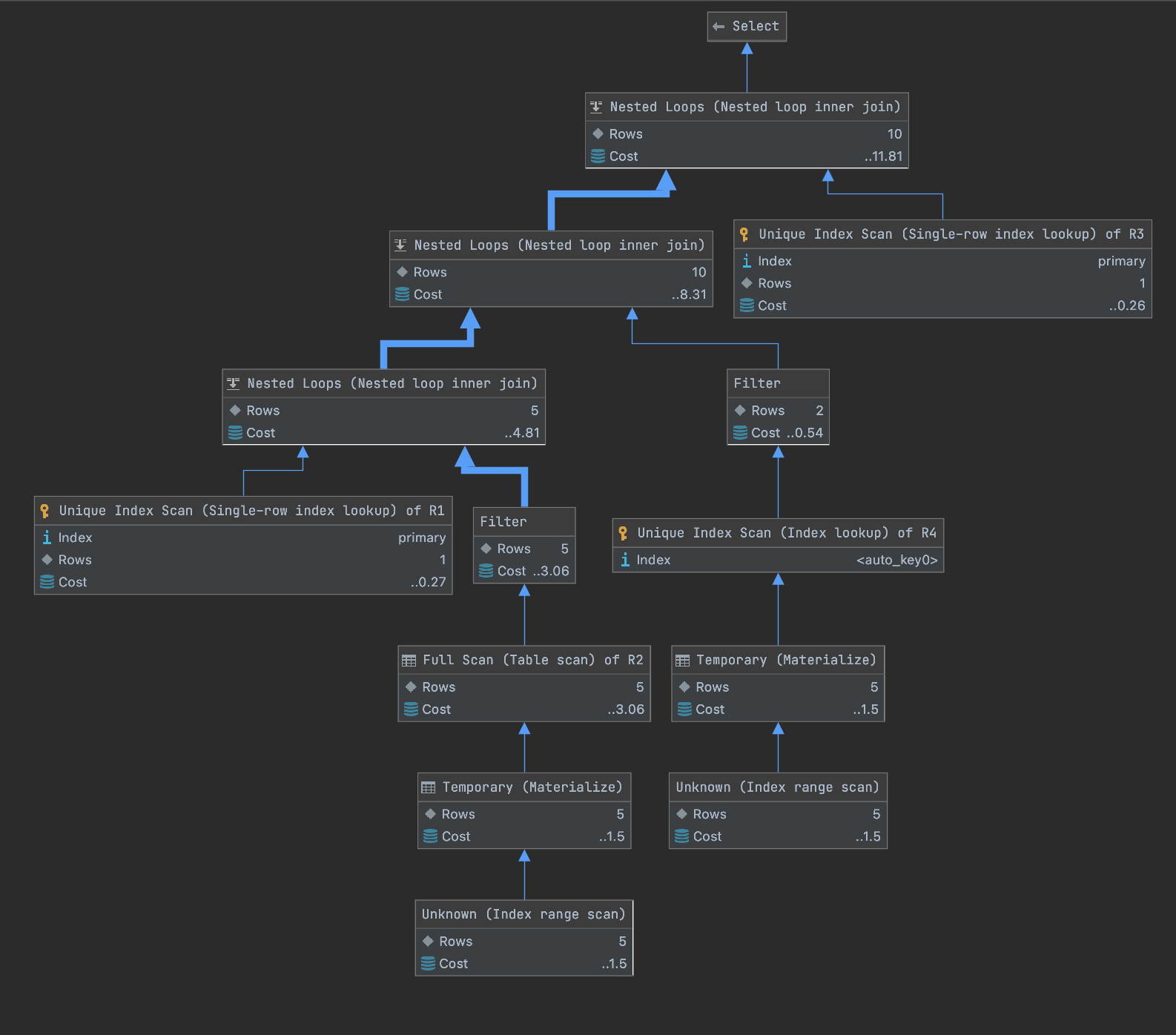
Nested Loops, Index Scan, Full Scan, Temporary 등의 키워드들이 보이는데 Nested Loops는 한쪽 테이블을 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 다른 쪽 테이블에서 찾는 방식이다. 즉 이름 그대로 중첩 반복이 이루어진다. Temporary는 쿼리 실행에 있어서 임시 테이블을 생성해서 사용하는 것이다. 실행 계획에서 해당 키워드가 보인다면 이 역시 피하도록 하는 것이 좋다. Full Scan 역시 row를 전체 도는 것으로 피하는 것이 좋다.
마치며
공부한 걸 정리하기 위해 쓰는 글이면서 공부할 게 산더미라는 걸 알려주는 글인 듯 하다. 해당 내용에 대해 조금 더 완벽하게 숙지하고 글을 쓰고 싶었지만 부족함을 깨달으며 더욱 열심히 공부해야 겠다는 생각이 든다.
모두들 긴 글 읽어주셔서 감사하고 파이팅하길 바랍니다.

감사합니다