시작하기 전에 혹시 진도를 못 따라잡을까 걱정했지만
부랴부랴 하면서 다행히 아직은 그런 일이 없다.
앞으로도 힘내자!
새로 배운 내용
흠 스크롤샷을 할 수 있는 확장프로그램으로 캡쳐 해봤는데 아주 깔끔하게 처리되진 않네...
아무튼 많아보이지만 사실 체감상 빠르게 지나가서 남은 것이 별로 없다.
이번 주차는 복습을 꾸준히 해야할 것 같은 예감이 든다.
왜냐하면 숙제할 때 워낙 애먹었기 때문에.
키워드로 요약하자면 이번에는 Python으로 mongoDB를 활용하는 법을 배웠다.
Python은 익숙했으나 mongoDB라니... 처음 들어본 용어가 살짝 겁이 나기도 했다.
수업 도중 DB에 관련된 이론도 다뤘는데,
여러 강의나 채용 공고에서 들어본 것 같은 SQL, NoSQL이 있었다.
아무래도 실무에 주로 쓰이는 DB인 듯 하다.
Robo 3T로 DB 관리
3주차는 특히나 다운받아야할 프로그램이 많아서 기대되면서 걱정도 됐다.
이번엔 또 어떤 새로운 것을 배울까 하는 기대와
내 노트북이 잘 버틸 수 있을까하는 걱정...
(TMI)
어제 숙제할 적에 팬 돌아가는 소리에 식겁해
이음새 근처를 만져보았더니 정말 뜨거웠다.
그래서 중간에 발열 해결 조치도 취했고,
혹시 몰라 메모리도 한 번 싹 정리했다.
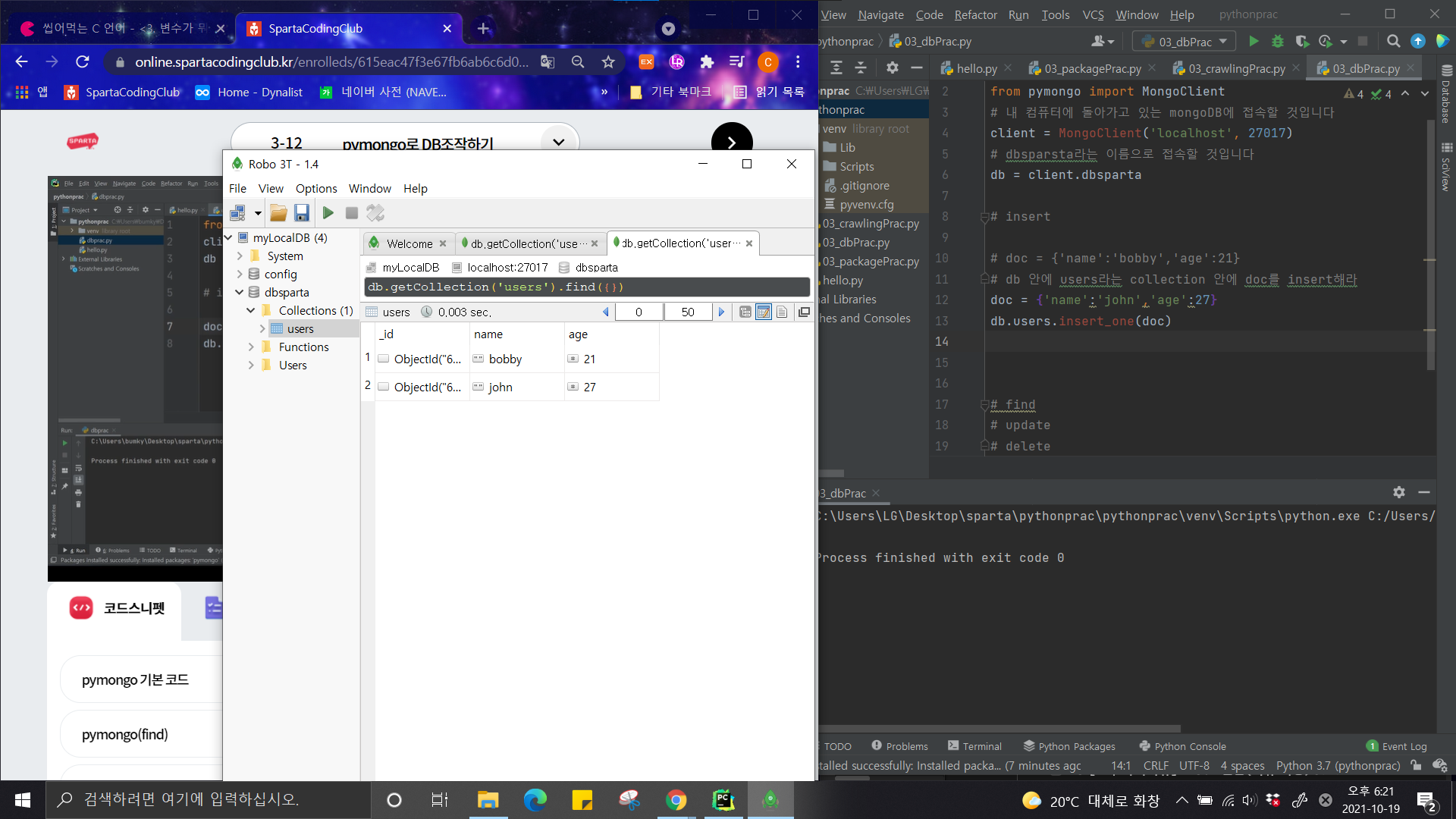
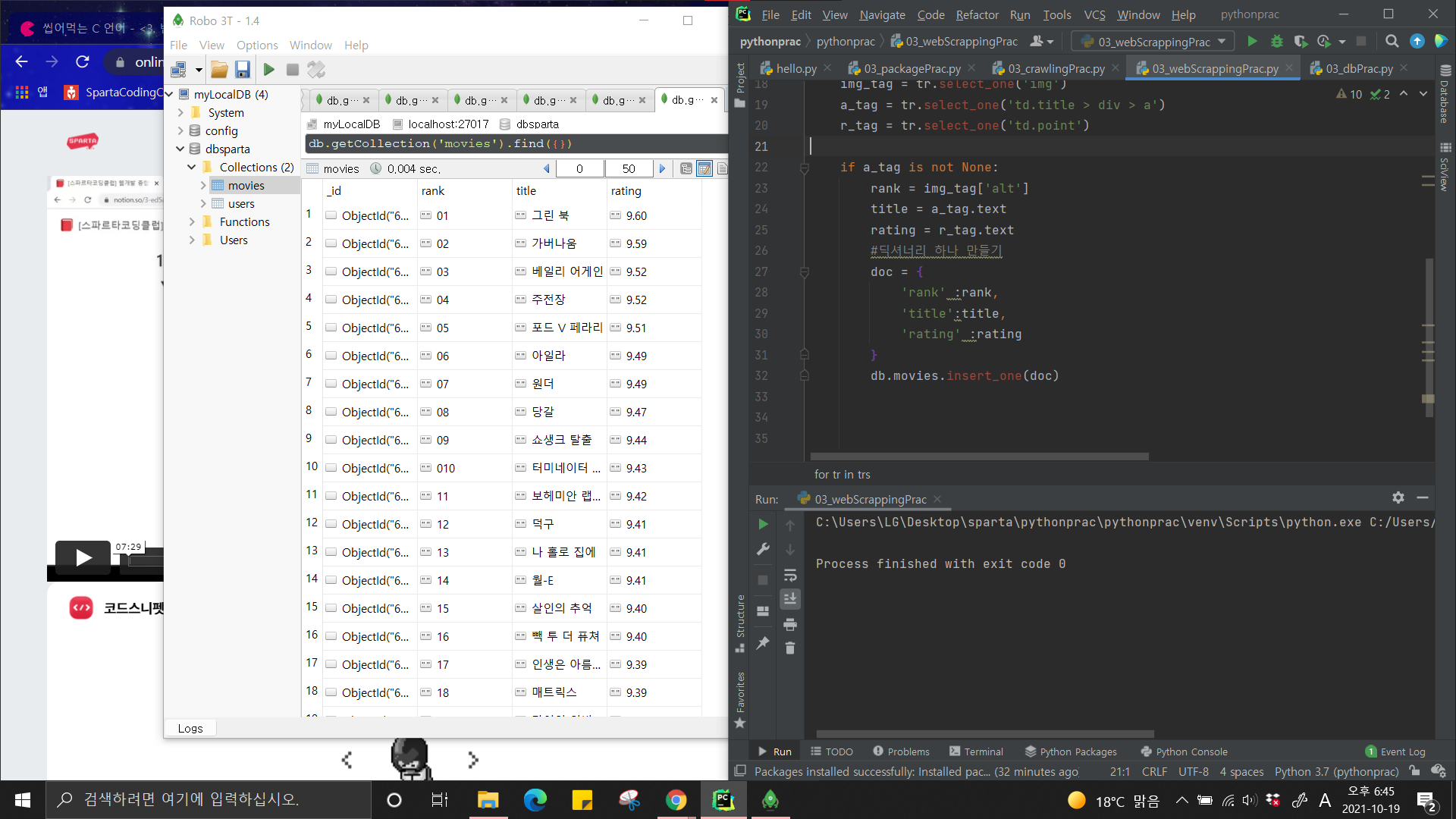
Robo 3T는 보이지 않는 DB를 보여주는 프로그램으로 이해했다.
위 사진의 중간에 위치한 창을 보면 Python에서 pymongo라는 프로그램으로 데이터를 insert한 결과를 볼 수 있다.
print를 하지 않아도 그때그때 새로고침하면 DB 현황을 바로 파악할 수 있다.
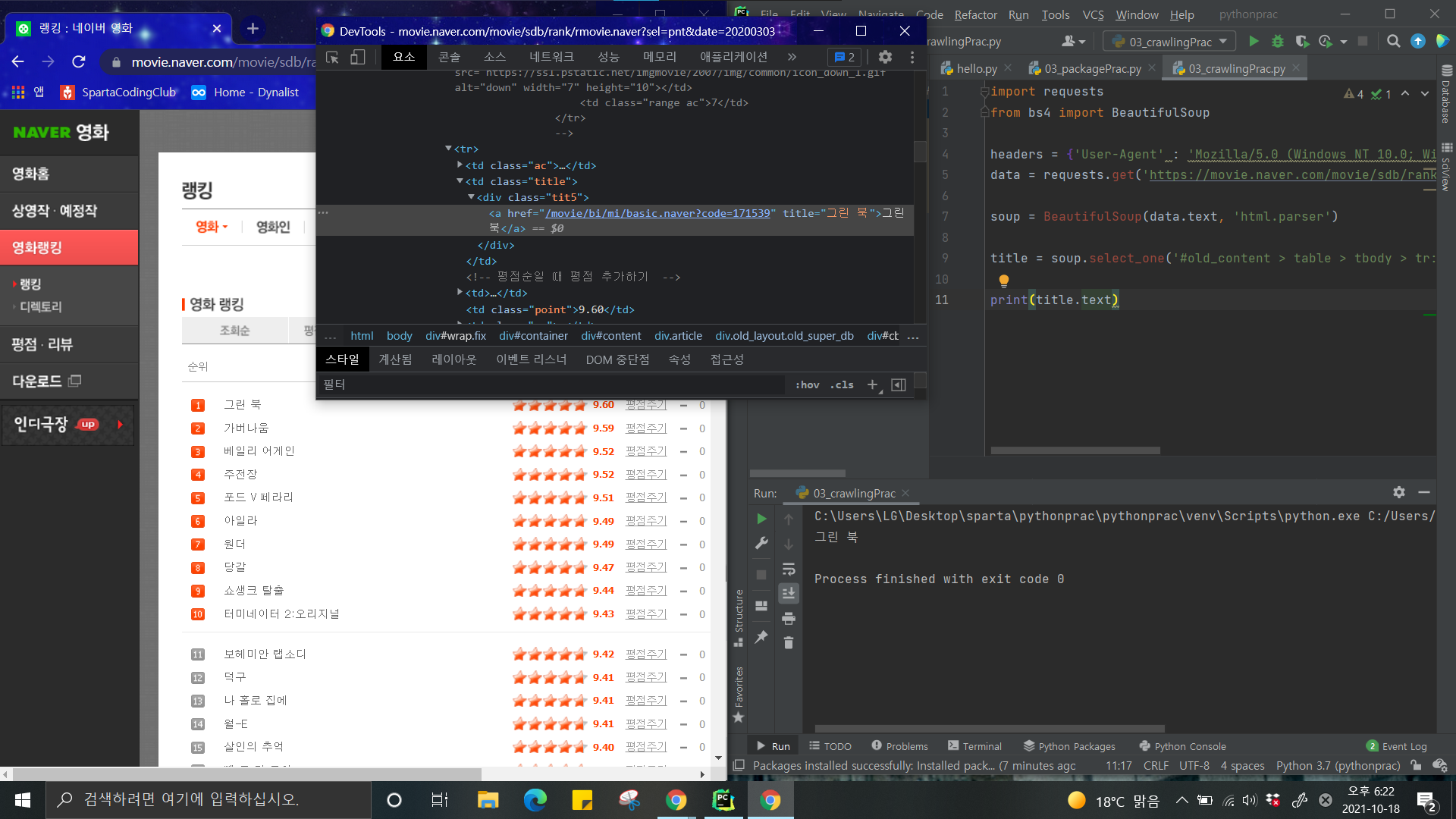
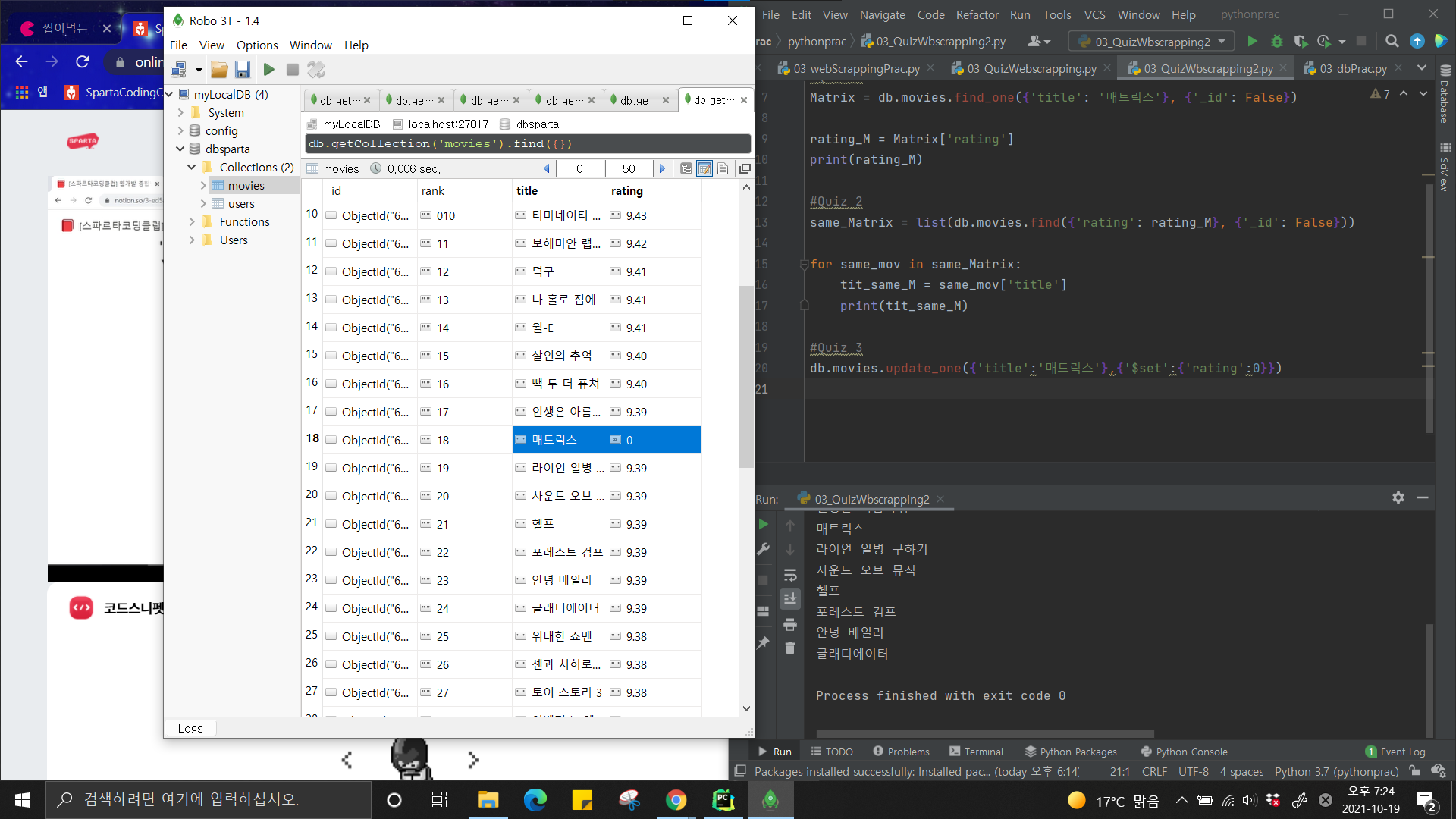
그래서 이렇게 실제 웹페이지의 경로를 정해두고, 적절한 값만 뽑아내
딕셔너리를 만들고, DB를 만들면
위 사진처럼 Robo 3T로 바로 확인할 수 있다.
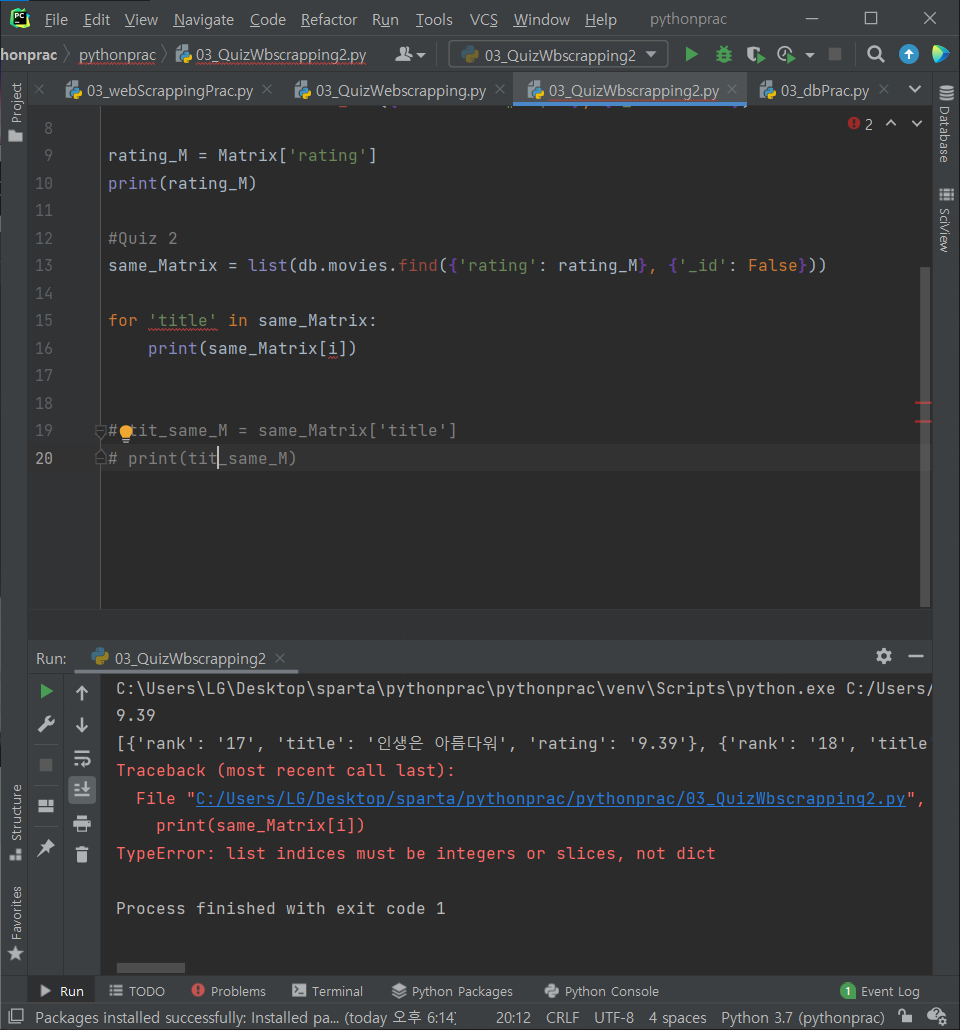
물론 가져온 데이터를 파이썬 내에서 변경하는 것도 가능했다.
냅다 내 인생 영화 매트릭스 평점 0점으로 만들어버리기...
고민한 내용
이건 강의 중 풀어야했던 Quiz 중 하나인데,
결과값이 매트릭스와 동일한 평점을 가진 영화 제목들을 출력하는 것이었다.
'동일한 평점을 가진' -> 이건 어떻게 해야할지 감이 잡혔다.
DB에서 딕셔너리 key가 rating(평점)에서 value가 rating_M(매트릭스의 평점)인 것들을 찾으면 됐다.
그런데 영화 제목 출력 -> 이걸 찾느라 조금 헤맸다.
분명 list로 나왔으니깐 반복문으로 출력하면 됐는데,
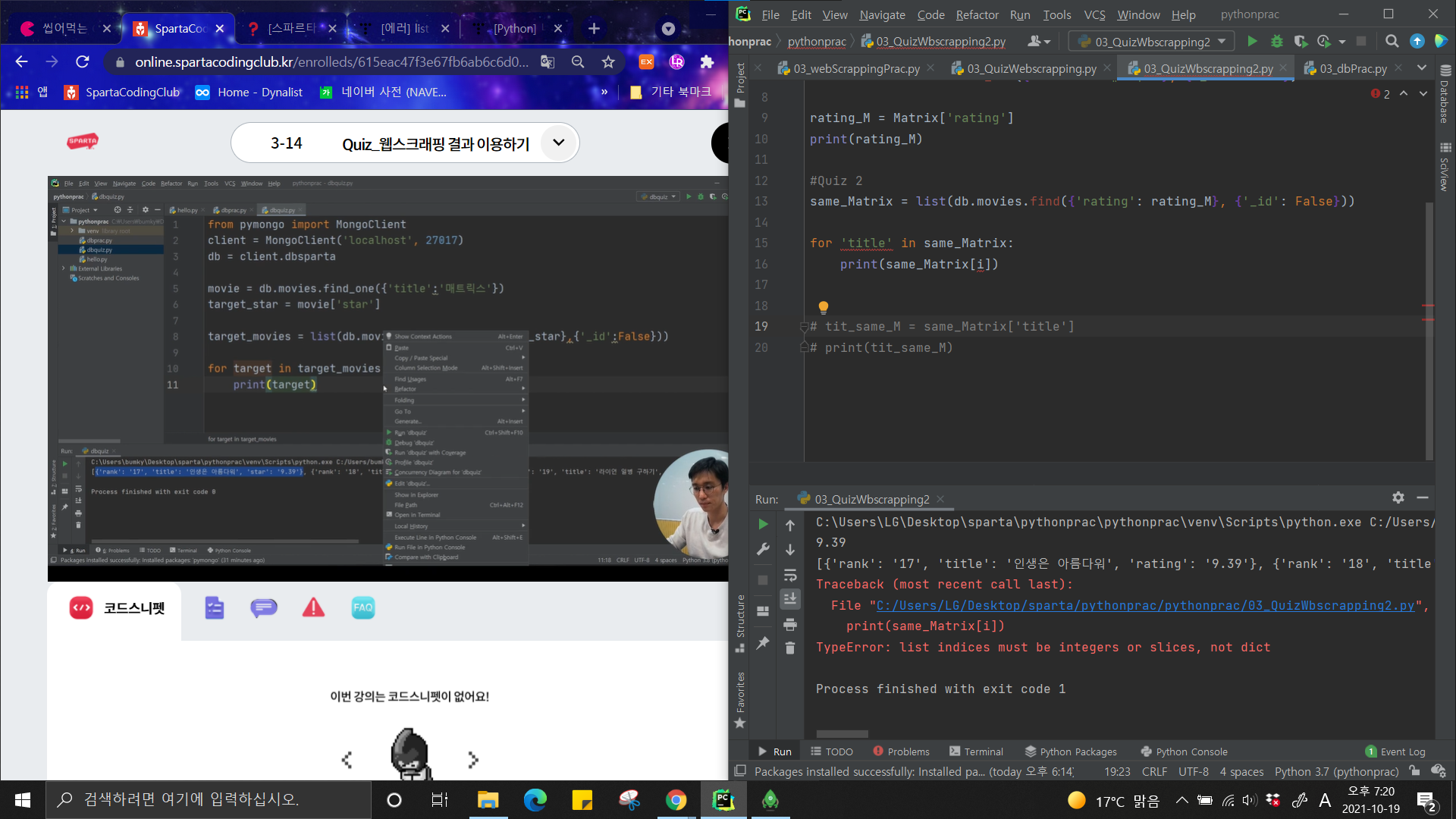
왼쪽의 Quiz 답과 비교했을 때, 아쉽게도 반복문의 형태를 잘못잡아
애를 먹었던 것이다.
아무래도 반복문 개념이 완전히 잡히지 않았거나 많이 해보지 않아서 그런 걸수도 있겠다.
에러는 참고로 same_Matrix[i]에서 i를 반복문 시작 때 정의내리지 않았던 것.
아마
for i in num:
이런 구문과 헷갈린 것 같다.
3주차 퀴즈에 대한 잡다한 고민
import requests
from bs4 import BeautifulSoup
# pymongo
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank_tag = tr.select_one('td.number')
ti_tag = tr.select_one('td.info > a.title.ellipsis')
art_tag = tr.select_one('td.info > a.artist.ellipsis')
if ti_tag is not None:
rank = rank_tag.text
title = ti_tag.text
artist = art_tag.text
r_rank = rank.strip()
r_title = title.strip()
r_artist = artist.strip()
print(r_rank, r_title, r_artist)
#순위 selector
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
#제목 selector
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
#아티스트 selector
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
위 코드의 결과물
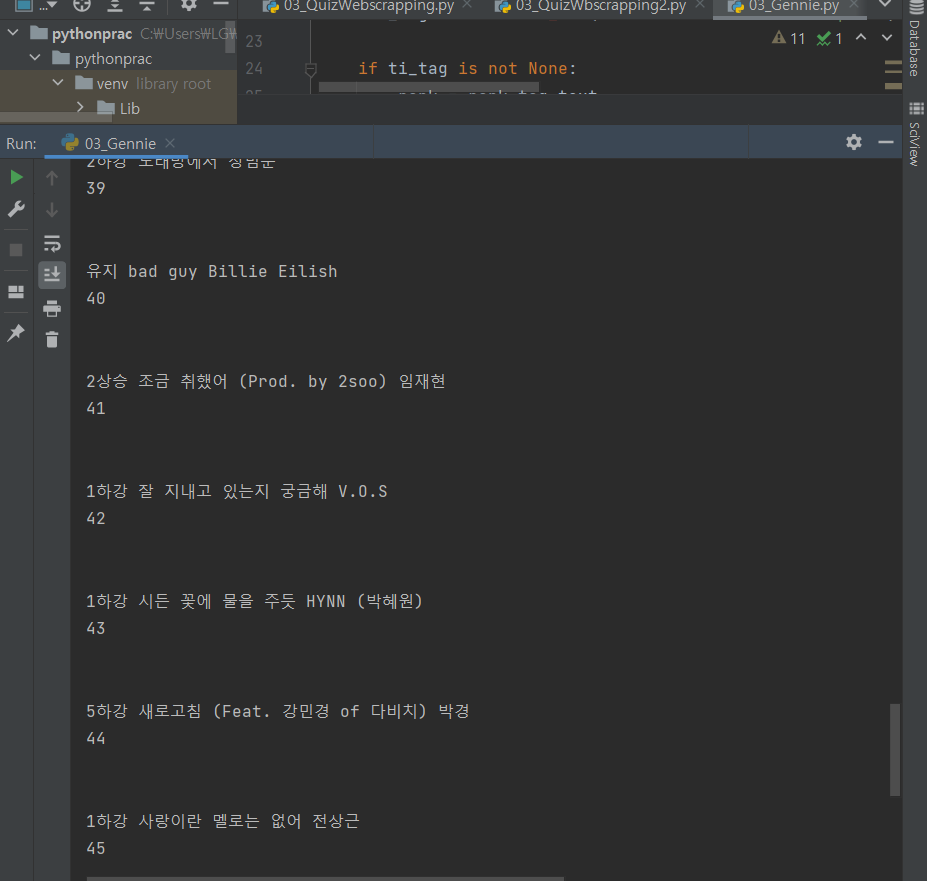
보다시피 저 넓은 여백과 '~상승', 유지, '~하강' 이런 건 없애야 한다.
아니 지니 뮤직에서 스크랩핑할 때,
순위만 뽑아낼 건데, 자꾸 1하강, 유지, 3상승 이런 것까지 달려와서 솔직히 좀 짜증났다.
나도 이걸 안 지 얼마 안돼서 구체적으로 이걸 왈가왈부할 자격을 안되지만,
숙제를 하는 학생으로서 봤을 때, 어떤 느낌이었나면,
음악 순위 리스트 폴더\음악 순위 폴더\음악 순위 숫자&음악 순위 변동 폴더
다른 요소들(음악 제목, 아티스트)은 별도의 폴더가 있어
하나의 코드로 충분히 뽑아낼 수 있는데
음악 순위가 위의 사진처럼 문제가 있었다.
'음악 순위 숫자'만 폴더에서 추출하고 싶었는데,
이 음악 순위랑 음악 순위 변동 요소는 한 폴더에 묶여 있어서
한 코드로 뽑아내기가 어려웠다.
그래서 이것저것 찾아보다가 문자열 자르기를 참고했으나
내가 원하는 결과물을 내지 못해
그 폴더에 있는 것 중 맨 앞 그리고 그 다음 문자열을 뽑아내는 것으로 했다.
돌이켜보면 약간 비합리적이다.
지금 이 상황일 때만 쓸 수 있고,
만약 노래 순위가 100위 이상으로 넘어가면 또 요리조리 바꿔야 된다.
if ti_tag is not None:
rank = rank_tag.text
title = ti_tag.text
artist = art_tag.text
rank_list = list(rank)
#print(rank_list[0], rank_list[1])
real_rank = rank_list[0]+rank_list[1]
rr_rank = real_rank.strip()
#print(rr_rank)
#real_rank = list(rank)
#print(real_rank[0])
#r_rank = rank.strip()
r_title = title.strip()
r_artist = artist.strip()
print(rr_rank, r_title, r_artist)
#print(rank, title, artist)
#print(r_rank, r_title, r_artist)이렇게 저렇게 튀기고 볶아서 출력해 본 고뇌의 흔적
참고한 블로그/사이트
바로 위의 내용을 고민할 때 검색했던 블로그
웹스크래핑 Quiz 풀 때, beautifulsoup 특정 태그 안의 속성값 가져오기
https://www.jungyin.com/168
이건 3주차 마지막 Quiz 풀 때, 문자열 공백 제거 관련 검색했던 블로그
https://appia.tistory.com/234
문자열 자르기 참고했던 블로그
https://wikidocs.net/2839
자체 피드백
복습의 중요성
현재 C, html/css, python을 동시에 공부하고 있는데, 당연하게도 정말 헷갈린다.
아무래도 한 언어만 주로 공부해야할까 싶기도 한데,
일단 C는 컴퓨터언어의 기본이자 이후 알고리즘, 자료구조 공부를 하기 위해 필요하기 때문에
차근차근히 하고,
python부터 정확한 문법, 그리고 어떻게 쓰이는지 자주 보고 돌려봐야겠다.
야메(?)를 두려워 말자
3주차 과제는 이전 과제들에 비해 정석을 따르지 않고
내가 하고 싶은대로 코드를 짜봤는데,
튜터님은 어떻게 했나 싶어서 답안 영상을 봤더니,
많이 다른 점은 없었다.
문자열을 뽑아내는 방식은 유사했으나 이용했던 코드가 조금 달랐다.
<문자열 인덱싱 및 슬라이싱>을 이용했다.
>>> mystring = 'hello world'
>>> mystring[0:5]
'hello'
>>>참고한 블로그 출처: https://wikidocs.net/2838
그리고 튜터님이 알려주신 답안
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select.one('td.info > a.title.ellipsis').text.strip()
rank = tr.select.one('td.number').text[0:2].strip()
artist = tr.select.one('td.info > a,artist,ellipsis').text
print(rank, title, artist)사실 해당 정보를 정수로 전환하거나 순위 숫자 데이터만 따로 불러내는 등의 방식이 정답이라고 생각했으나,
생각보다 답도 그닥 합리적인 방향이 아니라서 의아했다.
결론은 답이 나올 수만 있다면 비합리적인 방법도 한 번 시도해보자!
협업에 대한 생각
이번 주차에는 주로 웹스크래핑, 크롤링을 했었는데,
주제 성격때문인지 별다른 협업에 대한 아이디어는 없었다.
프로젝트 아이디어
이번 웹 개발 강의나 다른 프로그래밍 강의 듣기 전에
목차를 개인 메모장에 복사해서 편집한 적이 있는데,
냅다 드래그>붙여넣기>여백 일일이 지우기
잘만 활용하면 이번 주차에 했던 스크래핑 방식으로 깔끔하게 가져올 수 있지 않을까?
다음 주차부터는 서버 만들기를 한다고 한다!
다음 주차도 파이팅!
