실행계획은 쿼리를 실행하기 위해 DB엔진이 결정한 가장 효율적인 출력물이라고 할 수 있다. 쿼리 처리 과정을 보면 다음과 같다.
- 구문분석 -> 표준화 -> 최적화 -> 컴파일 -> 실행
실행계획은 최적화 단계에서 통계, 조각정보 등을 바탕으로 만들어 지고 이때 만들어지는 플랜을 재사용을 위해 메모리에 캐시(플랜 캐시)하므로 실행계획은 예상 실행 계획과 실제 실행 계획으로 구분한다.
| 계획 | 설명 |
|---|---|
| 예상 실행 계획 | 이전에 생성된 통계정보를 바탕으로 플랜을 구성 |
| 실제 실행 계획 | 현재 상태의 통계정보를 바탕으로 플랜을 구성 |
실행계획은 다음의 경우 기존의 실행계획을 사용하지 않고 새로운 실행계획을 생성한다.
- 쿼리에서 참조하는 테이블이나 뷰가 변경된 경우(ALTER TABLE 및 ALTER VIEW)
- 단일 프로시저가 변경된 경우. 이 경우 해당 프로시저의 모든 계획이 캐시에서 삭제된 경우(ALTER PROCEDURE)
- 실행 계획에 사용되는 인덱스가 변경된 경우
- UPDATE STATISTICS등의 문에서 명시적으로 생성되거나 자동으로 생성되어 실행 계획에 사용되는 통계가 업데이트된 경우
- 실행 계획에 사용되는 인덱스가 삭제된 경우
- sp_recompile에 대한 명시적 호출이 된 경우
- 쿼리에서 참조하는 테이블을 수정하는 다른 사용자가 INSERT 또는 DELETE 문으로 키를 많이 변경한 경우
- 트리거가 있는 테이블의 경우 inserted 또는 deleted 테이블의 행 수가 현저하게 증가하는 경우
- WITH RECOMPILE 옵션을 사용하여 저장 프로시저를 실행하는 경우
- 계획에 있는 모든 캐시를 삭제한 경우(DBCC FREEPROCCACHE)
실행계획은 위에서 아래로 오른쪽에서 왼쪽으로 확인하고 이는 쿼리가 실행되는 순서이다. 실행계획의 하나의 노드를 선택하면 다음과 같은 속성을 확인할 수 있다.
| 속성명 | 설명 |
|---|---|
| Physical Operation | 논리 연산자의 지시에 따라 연산을 구현하는 연산자입니다. 모든 물리 연산자는 일반적으로 작업을 수행하는 개체입니다. 몇 가지 예는 Clustered Index Scan, Index Seek 등 입니다. |
| Logical Operation | 이 연산자는 쿼리를 처리하는 데 사용되는 실제 대수 연산을 설명합니다. 예를 들면 Right Anti Semi Join, Hash Join 등 이 있습니다. |
| Estimated Execution Mode | Actual Execution Mode와 유사하나 추정값을 보여줍니다. |
| Storage | 쿼리 최적화 프로그램이 쿼리에 의해 추출되는 결과를 저장하는 방법을 알려줍니다. |
| Estimated I/O Cost | 결과 집합의 입/출력 작업 비용을 알려줍니다. |
| Estimated CPU Cost | 작업을 처리하기 위해 CPU에서 발생하는 비용을 알려줍니다. |
| Estimated Number of Executions | Number of Executions 와도 유사하지만 추정 값입니다. |
| Object | 작업이 수행되는 테이블을 나타냅니다. |
| Estimated Number of Rows Per Execution | 옵티마이저가 연산자에 의해 반환될 것이라고 생각하는 행 수를 나타냅니다. |
| Estimated Number of Rows to be Read | 옵티마이저가 운영자가 읽을 것이라고 생각하는 행 수를 나타냅니다. |
| Estimated Number of Rows for All Executions | Number of Executions 와도 유사하지만 추정 값입니다. |
| Estimated Row Size | 연산자의 각 행에 대한 저장 크기 |
| Estimated Rebinds | |
| Estimated Rewinds | |
| Defined Values | |
| Output List | |
| Parallel | |
| Ordered | 이 속성은 작업을 수행할 데이터 세트가 정렬된 상태인지 여부를 결정합니다. |
| Forced Index | |
| Node ID | 오른쪽에서 왼쪽 , 위에서 아래로 읽는 Execution Plan에서 오퍼레이터가 호출된 순서대로 번호를 자동 할당합니다. |
| TableCardinality | |
| ForceScan | |
| NoExpandHint |
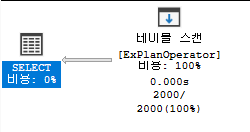
SQL Server 실행 계획 연산자
테이블 스캔(Table Scan)
생성된 SQL 쿼리 실행 계획에서 SQL Server 엔진이 데이터를 검색하기 위해 Table Scan 연산자를 사용하여 모든 전체 테이블 행을 스캔한다는 것을 의미한다. SQL Server 엔진은 WHERE 절을 추가하여 특정 레코드 집합을 가져오려고 할 때 해당 테이블에 생성된 인덱스가 없을때 Table Scan 연산자를 사용하여 모든 전체 테이블 행을 스캔한다.
만약 인덱스가 있는 경우에도 테이블 스캔이 발생 할 수 있는데 이런 경우 다음과 같은 이유때문에 테이블 스캔이 발생한다.
- 인덱스가 유용하지 않은 경우
- 테이블에 적은 수의 행이 포함되어 있는 경우
- 쿼리가 대부분의 행을 반환하는 경우

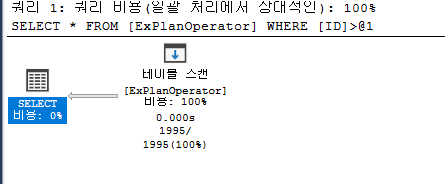
클러스터형 인덱스 스캔(Clustered Index Scan)
SQL Server 엔진은 Clustered Index Scan 연산자 사용은 Table Scan 연산자 작동 방식과 유사하게 모든 인덱스 행을 순회한다.
오래된 통계로 인해 유용한 비클러스터형 인덱스가 없거나 쿼리가 테이블 행의 전부 또는 대부분을 반환하는 경우 SQL Server 엔진은 클러스터형 인덱스 스캔 연산자를 사용하여 모든 클러스터형 인덱스 행을 스캔하는 것이 적합하다고 결정한다.
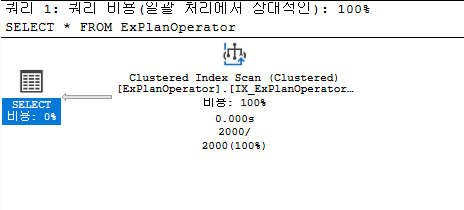
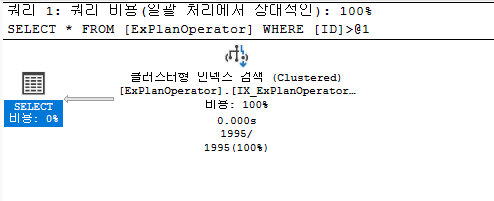
클러스터형 인덱스 검색(Clustered Index Seek)
모든 테이블 행을 순회하는 대신 적절한 클러스터형 인덱스를 찾고 이를 탐색하여 SQL Server 저장소 엔진에 선택한 행의 키 값을 기반으로 필요한 행을 검색한다.
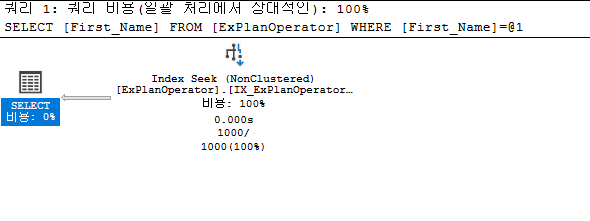
클러스터되지 않은 인덱스 검색(Index Seek(NonClustered))
비클러스터형 인덱스는 인덱스 키 값과 나머지 열에 대한 포인터만 저장해 데이터를 검색한다.
RID 조회 연산자(RID Lookup)
테이블에 클러스터형 인덱스가 없을 경우 테이블은 페이지를 정렬하고 페이지 내의 데이터를 정렬하는 기준이 없는 힙 테이블로 간주된다. 이 경우 WHERE절에 조건을 주어 검색하는 경우 클러스터되지 않은 인덱스 검색(Index Seek(NonClustered))과 RID Lookup이라는 중첩 루프 연산이 발생한다.
RID는 비클러스터형 인덱스를 만들게 되면 비클러스터형 인덱스의 리프레벨에는 데이타의 위치를 가르키는 RID가 기록된다. 즉, 해당 레코드의 위치에 대한 정보를 포함하는 행 로케이터이다. 따라서 비클러스터형 인덱스로 데이터를 찾을 경우에 그래서 "RID Lookup"이 발생하게 됩니다. 만약 클러스터형 인덱스가 있는 테이블에 비클러스터형 인덱스를 만들면 이 인덱스의 리프레벨에는 RID가 아닌 클러스터드 인덱스의 키가 기록된다.

RID 조회 연산자를 보면 해당 연산자의 비용이 계획의 전체 가중치(이 예에서는 50%)와 관련하여 높다는 것을 알 수 있습니다. RID Lookup은 조회되는 레코드의 수에 따라 I/O 오버헤드가 필요하므로 비용이 많이든다. 이 경우 다음과 같은 작업으로 비용을 줄일 수 있다.
- 검색되는 열을 제한
- 해당 쿼리에 대한 커버링 인덱스 생성(포함 인덱스를 생성하여 RID 조회를 제거하면 실행 계획에 Nested Loops 연산자가 필요하지 않음)
키 조회 연산자(Key Lookup)
위에 설명한 클러스터드 인덱스가 있는 테이블에 넌클러스터드 인덱스를 만들면 이 인덱스의 리프레벨에는 RID가 아닌 클러스터드 인덱스의 키가 기록되고 이 경우 key Lookup이 발생한다.
예를 들어 비클러스터형 인덱스에서 검색 작업을 수행하여 EmpFirst_Name 열 값이 'BB'인 모든 직원을 검색한다면 비클러스터형 인덱스에 있는 포인터를 얻고 이 테이블이 해당 테이블의 데이터를 정렬하는 클러스터형 인덱스가 있는 클러스터형 테이블이라는 사실 때문에 Non_Clustered 인덱스 포인터는 기본 테이블을 가리키는 대신 클러스터형 인덱스를 가리킨다. 나머지 열은 SQL Server 엔진이 행을 검색할 수 없기 때문에 중첩 루프 연산자를 사용하여 검색되어 Key Lookup 연산자에서 검색된 데이터와 Index Seek 데이터를 결합한다. 즉, 클러스터형 인덱스 키를 참조로 사용하여 비클러스터형 인덱스에 저장된 클러스터형 키 값을 사용하여 클러스터형 인덱스에 저장된 데이터를 조회한다.

RID 조회 연산자와 유사하게 키 조회는 레코드 수에 따라 추가 I/O 오버헤드가 필요하므로 비용이 많이 발생한다. 따라서 Key Lookup 연산자를 덮거나 포함된 인덱스가 필요하다는 표시이며 Key Lookup 및 Nested Loops 연산자의 필요성을 제거하여 해당 쿼리의 성능을 향상시킬 수 있다.

좋은 정보 감사합니다