정렬 연산자(Sort)
ORDER BY 절을 사용하여 SELECT 문을 실행한다고 가정하면 SQL Server 엔진이 요청된 데이터를 검색하기 위해 비클러스터형 인덱스를 찾은 다음 SORT 연산자가 실행되는 것을 알 수 있다. SORT 연산자는 SQL Server 실행 계획에서 볼 수 있듯이 비용이 많이 드는 연산자로 이 비용은 ORDER BY 절에 지정된 열에 요청된 주문에 대해 정의된 인덱스가 없기 때문으로 이 정렬 작업이 실제로 필요한지 생각해야 한다.

집계 연산자(Aggregate)
집계 연산자는 주로 집계 열의 값을 그룹화하여 제출된 쿼리의 집계 식을 계산하는 데 사용된다. 집계 표현식에는 MIN, MAX, COUNT, AVG, SUM 연산이 포함되고 집계 연산을 수행하기 위해서는 Group By 절에 지정된 열을 기준으로 값을 정렬하고 집계를 수행한다.
Stream Aggregate 연산자는 이러한 값을 집계하기 전에 GROUP BY 절에 지정된 열을 기반으로 행을 정렬하는데 만약 Seek 또는 Scan 연산자에서 행이 정렬되지 않은 경우 SQL Server 엔진은 아래와 같이 SORT 연산자를 강제로 사용한다.

컴퓨팅 스칼라 연산자(Compute Scalar)
Compute Scalar 연산자는 계산된 값을 생성하는 스칼라 계산 작업을 수행하여 기존 행 값에서 새 값을 계산하는 데 사용된다. 예를들어 두 열의 연결을 수행하여 새 스칼라 값을 반환할때(두개의 열을 문자열로 조합할때 등) 사용되며 비용이 많이 드는 연산자는 아니다.

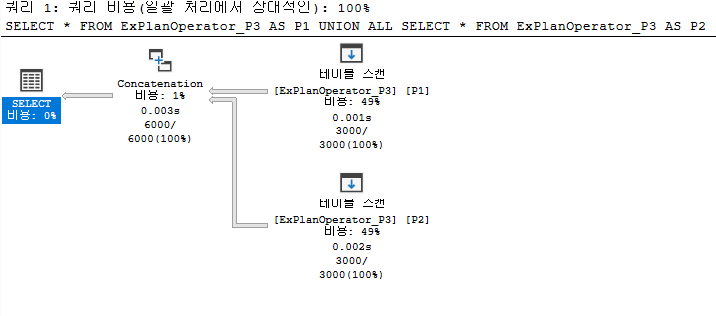
연결 연산자(Concatenation)
연결 연산자는 하나 이상의 데이터 집합을 순서대로 가져와 각 입력 데이터 집합에서 모든 레코드를 반환한다. 이 연산자의 대표적인 예 중 하나는 UNION ALL이다.
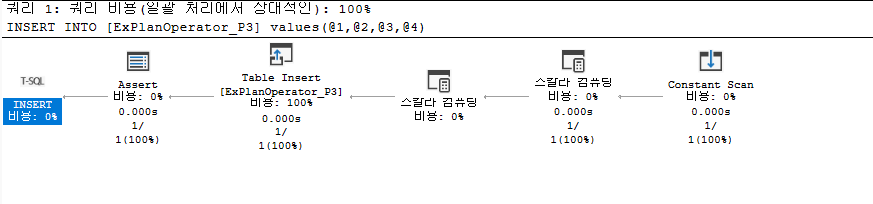
어설션 연산자(Assert)
Assert 연산자는 삽입된 값이 테이블에서 이전에 정의된 CHECK 또는 FOREIGN KEY 제약 조건을 충족하는지 확인하는 데 사용된다. Insert가 발생할때 발생하는 연산자로 조건이 충족되었는지 확인하는 연산자이다.
해시 일치 조인 연산자(Hash Match(Inner Join))
두 테이블을 조인할 때 SQL Server 엔진은 데이터에 빠르게 액세스하기 위해 테이블의 데이터를 버킷이라는 동일한 크기의 범주로 나누는데 이 데이터 구조를 해싱 테이블이라고 한다.
Hash Match에 실행계획을 자세히 보면 SQL Server 엔진이 조인된 두 테이블에서 데이터를 읽은 후 Hash Match Join 연산자를 사용하여 Probe라고도 하는 작은 데이터로 해시 테이블을 채우고 그런 다음 해시 테이블 값에 따라 두 번째 큰 테이블(빌드 테이블이라고도 함)을 처리하여 요청된 데이터에 대한 액세스 속도를 높인다.

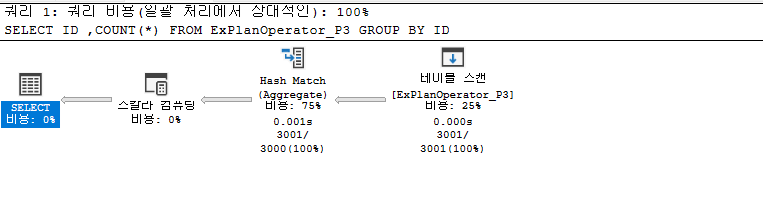
해시 일치 집계 연산자(Hash Match(Aggregate))
Hash Match Aggregate 연산자는 인덱스를 사용하여 정렬되지 않은 큰 테이블을 처리하는 데 사용되며 이 연산자의 대표적인 예 중 하나는 중복 수를 반환하는 Count이다.
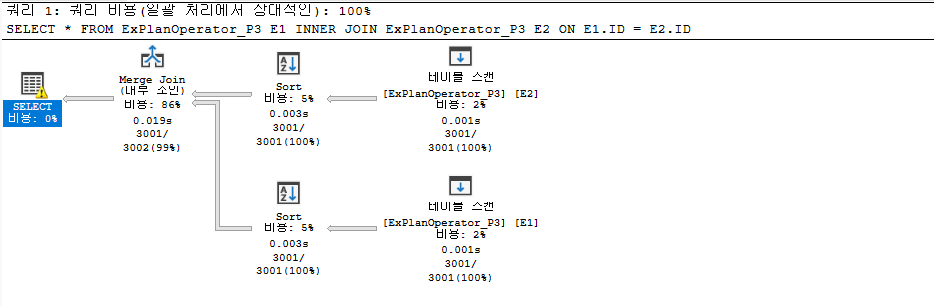
병합 조인 연산자(Merge Join(Inner Join))
병합 조인 연산자는 여러 유형의 JOIN 작업과 함께 사용되지만 두 JOIN 데이터 집합이 조인 조건자에 따라 정렬된 경우에만 사용된다. Merge Join 연산자는 두 개의 입력 데이터 세트에서 동시에 읽고 비교한 다음 일치하는 결과를 반환한다. 즉 해당 테이블에 인덱스 없는 경우 조인 되는 조건의 열로 데이터를 정렬한 다음 두 입력을 조인하므로 이전에 Sort 연산자에서 시작 되는것을 확인할 수 있다.
중첩 루프 조인 연산자(Nested Loops(Inner Join))
상위 입력(외부 입력이라고도 함)을 한 번 실행하여 결합하고 하위 입력(내부 입력이라고도 함)을 다음 횟수만큼 실행하여 결합하는 데 사용된다. 즉, 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 조합하는 조인 방식이다.
NESTED LOOP JOIN은 드라이빙 테이블로 한 테이블을 선정하고 이 테이블로부터 where절에 정의된 검색 조건을 만족하는 데이터들을 걸러낸 후, 이 값을 가지고 조인 대상 테이블을 반복적으로 검색하면서 조인 조건을 만족하는 최종 결과값을 얻어낸다. 따라서 중첩 루프 연산자의 비용은 쿼리의 전체 가중치에 비해 낮지만 해당 연산자의 비용은 외부 입력 테이블의 크기와 내부 입력 테이블의 크기의 곱에 크게 의존한다.
세크먼트 연산자(Segment)
세그먼트 연산자는 값에 따라 입력 데이터를 여러 그룹으로 나누는 데 사용되며 이 연산자의 대표적인 예 중 하나는 순위 함수인 ROW_NUMBER()이다.
테이블 스풀 연산자(Table Spool(Lazy Spool))
TempDB에 임시 테이블을 만들고 지연 방식으로 채우는 데 사용된다. 즉, 상위 연산자에서 개별 행이 필요할 때만 데이터를 읽고 저장하여 임시 테이블을 채운다.
병합 간격 연산자(Merge Interval)
DISTINCT 쿼리를 수행하는 데 사용되며 동일한 값을 두 번 이상 스캔하지 않도록 병합하여 쿼리에서 중복 조건자가 없는 겹치지 않는 간격을 생성한다. SQL Server 엔진이 Merge Interval 연산자를 사용하여 동일한 데이터를 두 번 찾는 대신 한 번의 인덱스 검색 작업을 수행하여 중복을 식별하고 데이터 비교 및 검색 속도를 높인다.
필터 연산자(Filter)
필터 연산자는 입력 데이터를 확인하고 조건자 식을 만족하는 데이터만 반환하는 데 사용된다. 이 연산자의 대표적인 예 중 하나는 Having절 이다.
참고
