1. 행렬과 벡터 with numpy
머신러닝을 배우기 전에 가장 먼저 배워야하는 부분이 바로 행렬과 벡터이다. 머신러닝에서는 학습을 위해서 다양한 데이터를 사용하는데 이런 데이터를 쉽게 표현할 수 있는게 행렬이다.
이런 엑셀을 생각하면 이해가 쉬울거다. 숫자를 표현할 때 한개 혹은 한줄로 표현하는 것이 아닌 표처럼 2차원의 구조를 가지고 표현하는 것이 행렬이다.
벡터는 이러한 행렬의 일부분으로 행렬에서 1 X N 혹은 N X 1의 차원을 가지는 행렬이다. 저 표에서는 왼쪽의 열을 표현하는 숫자들이 한개의 벡터라고 할 수 있다.
그럼 이제 이런 데이터구조들을 직접 다뤄보겠다.

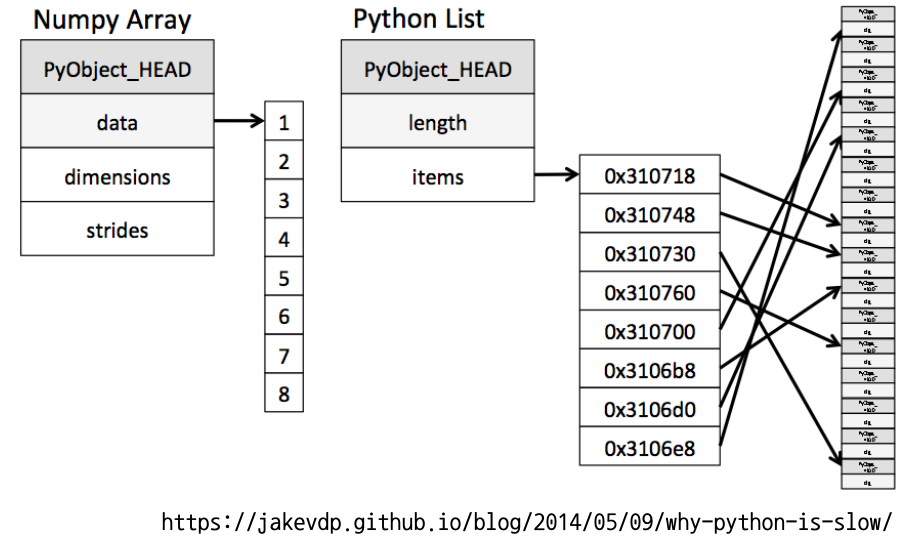
numpy는 파이썬에서 행렬과 벡터 같은 다차원 배열을 쉽게 다룰 수 있도록 도와주는 파이썬의 라이브러리이다. 파이썬에서도 다차원너 배열은 쉽게 만들 수 있지만 포인터를 통해 각기 다른 변수들에 참조하는 방식을 사용하다보니 속도가 느리고 연산이 쉽게 이뤄지지않는다.
넘파이를 실습해보기 위해선 우선 라이브러를 다운받아준다.
pip install numpy라이브러리를 사용할 때는 np라는 이름으로 Import 해준다.
import numpy as np1) ndarray
넘파이에서 가장 핵심적인 기능은 바로 ndarray 이다. 다차원 배열 구조의 클래스이며 실제 파이썬의 list 와 출력이 동일하다. 사용은 다음과 같이한다.
a = [1, 2, 3]
vector = np.array()
print(a)
print(vector)위의 코드를 실행하면 ',' 를 제외한 출력이 동일하게 나타나는 것을 확인할 수 있다.
언뜻보면 동일해보이지만 내부적인 구조는 리스트는 링크드리스트의 형태이고 ndarray 는 배열의 형식으로 구현됨을 참고하자

또한 ndarray 와 list 에는 결정적인 차이가 1가지 존재한다. 바로 내부 원소의 타입인데 list는 linked list이기 때문에 각 원소의 타입에 차이가 있어도 괜찮지만 ndarray에서는 허용되지 않는다. 다음을 출력해보자
a = [1,2,'3']
vector = np.array(a)
print(a)
print(vector)리스트의 출력은 입력한 그대로 나타나는 것을 볼 수 있지만 ndarray의 데이터는 전부 문자로 변경된 것을 확인할 수 있다. 실제 사용시에는 이부분을 주의하여 사용하자
다음은 2차원 배열을 만들어보자
matrix = np.array([[1,2,3],[4,5,6]])
print(matrix)[[1 2 3]
[4 5 6]]array 함수에는 1개의 리스트만 허용하기에 마지막에 항상 대괄호로 감싸줘야한다.
2개의 차원으로 나눠진 ndarray 가 생성된걸 확인할 수 있다. 또한 넘파이의 배열에는 축의 개수와 크기라는 개념이 존재하는데 머신러닝에 있어서 데이터의 크기를 아는 것은 매우 중요한 요소이다. 같이 확인해보자
vector = np.array([1,2,3,4,5,6])
matrix = np.array([[1,2,3],[4,5,6]])
print(vector.ndim, vector.shape)
print(matrix.ndim, matrix.shape)1 (6,)
2 (2, 3)ndim은 축을, shape는 크기를 나타낸다. 축은 해당 배열이 몇차원의 배열인지를 뜻하고 크기는 해당 차원마다 몇개의 값이 존재하는지를 뜻한다.
ndarray를 선언할 때 항상 리스트의 값을 직접 넣어줄 필요는 없다. 간단하게 선언하는 방법들을 알아보자
zero_arr = np.zeros(2)
one_arr = np.ones(2)