
Introduction
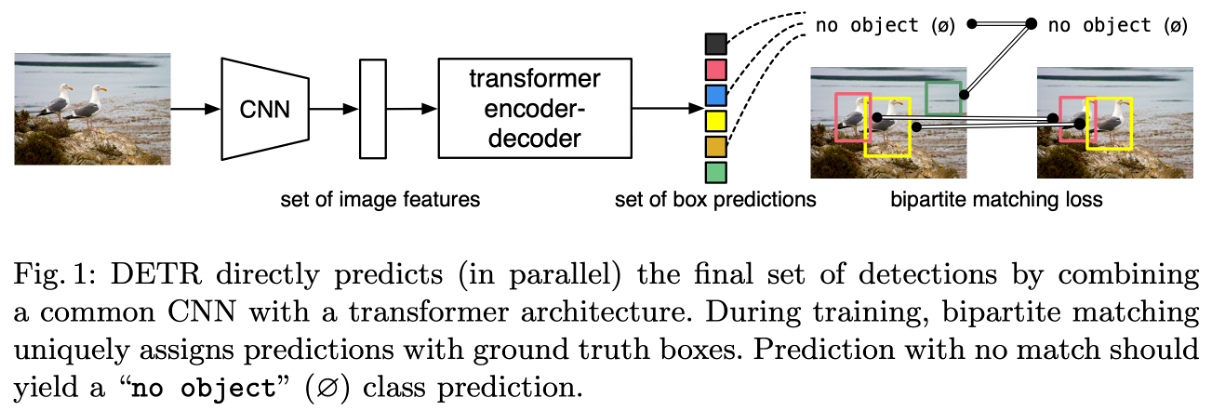
Object Detection의 목표는 bounding box의 좌표와 카테고리 레이블을 예측하는 것입니다. 기존 인공지능 모델은 이러한 set prediction task를 regression과 classification 문제로 나누어서 간접적으로 접근했습니다. 기존 인공지능 모델과 달리 DETR은 CNN과 트랜스포머 아키텍처를 결합하여 집합을 한 번에 예측합니다.
집합은 이미지 내에서 감지된 모든 객체의 모음을 의미합니다. 각 객체는 일반적으로 바운딩 박스(bounding box)와 카테고리 레이블(category label)로 표현됩니다.
Related work
집합 예측(set prediction)은 멀티레이블 분류(multilabel classification) 문제의 일종으로, 이 문제에서 가장 큰 도전은 서로 거의 동일한 예측이나 중복된 예측을 피하는 것입니다. 기존의 객체 탐지 모델들은(Faster RCNN, YOLO) 비최대 억제(Non-Maximum Suppression, NMS)라는 후처리 과정을 사용하여 중복된 예측을 제거합니다.
반면에 글로벌 추론(global inference)은 이미지 안의 모든 객체를 한 번에 인식하고 분석합니다. DETR은 이미지 전체를 종합적으로 보고 객체를 탐지합니다. 이 모델은 이미지 전체의 정보를 사용하여, 강아지의 머리와 몸통이 서로 연결되어 있다는 것을 이해하고 한 마리의 강아지로 정확히 인식할 수 있습니다.
이러한 글로벌 추론은 Transformer 모델과 병렬 디코딩(parallel decoding) 방식을 사용하여 구현됩니다. Transformer는 self-attention 메커니즘을 사용하여 데이터의 전체적인 context을 한 번에 파악하고, 병렬 디코딩을 통해 모든 예측을 동시에 수행합니다.
손실 함수는 Hungarian algorithm을 기반으로 한 bipartite matching loss을 사용합니다. 이는 각각의 실제 대상 요소가 예측과 일대일로 매칭되도록 하여 중복을 효과적으로 방지합니다.
Transformers (Perfect Memory): 트랜스포머 모델은 모든 입력 정보를 기억하고, 이를 기반으로 전체적인 추론을 수행할 수 있는 "완벽한 기억" 능력을 가집니다.
Auto-Regressive Models (Prohibitive Inference Cost): 자동회귀 모델은 한 번에 하나의 출력만을 생성하기 때문에, 병렬 처리가 불가능하고 추론 비용이 높습니다.
Parallel Decoding (Simultaneously): 트랜스포머는 모든 객체를 동시에 병렬로 디코드할 수 있어, 추론 시간을 대폭 단축시키고 효율성을 높입니다.
The DETR model
Object Detection set prediction loss
- Bipartite Matching (이항 매칭): 먼저, 모델의 예측과 실제 객체 사이의 최적 매칭을 찾아야 합니다. 이를 위해 모든 가능한 매칭 조합을 고려하여, 예측과 실제 데이터 사이의 매칭 비용 L_match을 최소화하는 최적의 매칭 σ을 찾습니다. 이 과정에서 헝가리안 알고리즘이 사용됩니다.
- Matching Cost (매칭 비용): 매칭 비용은 예측된 객체와 실제 객체 사이의 비용을 측정합니다. 클래스 레이블에 대한 예측이 정확하면 비용이 낮아지고, 바운딩 박스의 위치가 실제와 정확히 일치하면 또한 비용이 낮아집니다. 만약 예측된 객체가 "no object" 클래스라면, 이에 대한 비용은 계산되지 않습니다.
- Loss Function (손실 함수): 이항 매칭을 통해 결정된 최적의 매칭을 바탕으로, 모델의 전체 손실을 계산합니다. 이 손실은 모든 예측된 객체에 대해 계산되며, 클래스 레이블에 대한 예측 손실과 바운딩 박스의 손실을 모두 포함합니다.
- Bounding Box Loss (바운딩 박스 손실): 각 예측된 바운딩 박스와 실제 바운딩 박스 사이의 차이를 측정합니다. 이 손실은 일반적으로 IoU 손실과 L1 거리 손실을 포함하여 계산되며, 이러한 각각의 손실에는 가중치 λ가 적용됩니다.
이러한 4단계를 통해, DETR 모델은 이미지 내의 각 객체에 대해 정확한 클래스 레이블을 할당하고, 각 객체의 위치를 정확하게 예측하는 방법을 학습합니다. 손실 함수는 모델이 잘못된 예측을 할 때마다 페널티를 부여하여, 모델이 실제 객체의 정확한 클래스와 위치를 더 잘 예측하도록 돕습니다. 전체 학습 과정에서 모델은 이 손실을 최소화하는 방향으로 파라미터를 조정합니다.
The DETR model Architecture

- Backbone (CNN): DETR은 이미지에서 고차원 특징을 추출하기 위해 전통적인 CNN 백본을 사용합니다. 이 백본은 2차원 이미지를 입력으로 받아 처리합니다.
- Positional Encoding: Transformer 구조는 입력 embedding의 순서와 상관없이 같은 출력값을 생성하기 때문에 encoder layer 입력 전에 입력 embedding에 positional encoding을 더해줍니다.
- Transformer Encoder: 포지셔널 인코딩이 추가된 특징들은 트랜스포머 인코더를 거치게 됩니다. 인코더는 이 특징들 사이의 관계를 이해하고, 이미지 전체의 컨텍스트를 포착하기 위해 자기 주의(self-attention) 메커니즘을 사용합니다.
- Object Queries: Object query features는 이미지 내의 객체를 식별하기 위한 초기 prediction을 제공하고, object query positional embeddings는 디코더가 해당 객체의 위치에 attention할 수 있도록 도와줍니다.
- Transformer Decoder: 디코더는 인코더의 출력과 오브젝트 쿼리를 기반으로 하여, 각 객체의 위치와 클래스에 대한 예측을 생성합니다.
Experiments
Comparison with Faster R-CNN

- GFLOPS: Giga Floating Point Operations Per Second의 약자로, 모델이 수행하는 부동소수점 연산의 수를 기가 단위로 나타냅니다. 낮은 GFLOPS는 모델이 더 적은 계산으로 동작한다는 것을 의미합니다. 즉, 모델이 더 효율적이라는 것을 뜻합니다.
- FPS: Frames Per Second의 약자로, 모델이 초당 처리할 수 있는 이미지 프레임 수입니다. 높은 FPS는 더 빠른 추론 속도를 의미합니다.
- #params: 모델이 가진 파라미터의 총 수로, 모델의 크기와 복잡성을 나타냅니다.
- AP (Average Precision): 모델이 객체 탐지 작업을 수행하는 정확도를 나타냅니다. AP는 PR-curve 그래프 아래 면적입니다.
- AP50, AP75: 이는 IoU(Intersection over Union)가 0.5 또는 0.75일 때의 AP입니다. IoU는 예측된 바운딩 박스와 실제 바운딩 박스의 오버랩 정도를 측정하며, AP50과 AP75는 이러한 IoU 임계값에서 모델의 정확도를 나타냅니다.
- AP_S, AP_M, AP_L: 이는 각각 작은(Small), 중간(Medium), 큰(Large) 크기의 객체에 대한 모델의 AP를 나타냅니다. 이 지표들은 모델이 다양한 크기의 객체를 얼마나 잘 탐지하는지를 보여줍니다.
표에 따르면, DETR 모델은 기존의 Faster R-CNN 모델들과 비교하여 상대적으로 낮은 GFLOPS와 높은 FPS를 가지며, 적은 수의 파라미터로도 높은 AP 점수를 달성했습니다. 특히, 큰 객체(AP_L)에 대해서는 Faster R-CNN 모델들보다 높은 성능을 보여준 것으로 나타납니다. 이는 DETR이 효율적인 모델 구조를 가지면서도 높은 정확도를 제공할 수 있음을 의미합니다.
Comparison with UPSNet and Panoptic FPN

- PQ (Panoptic Quality): Panoptic Segmentation 작업에 대한 성능을 측정하는 지표로, 물체 탐지(object detection)와 세그멘테이션(segmentation)의 정확성을 모두 고려합니다. PQ는 높을수록 모델의 성능이 좋다는 것을 의미합니다.
- SQ (Segmentation Quality): 탐지된 각 객체의 세그멘테이션 마스크의 정확성을 평가합니다. SQ는 주로 세그멘테이션의 정밀도를 나타냅니다.
- RQ (Recognition Quality): 얼마나 많은 객체가 정확하게 분류되었는지를 측정합니다. RQ는 객체 인식의 정확도를 평가합니다.
- PQ^th (Things Panoptic Quality): ‘things’ 클래스(일반적으로 이산적인 객체를 의미함)에 대한 PQ를 나타냅니다.
- SQ^th (Things Segmentation Quality): ‘things’ 클래스에 대한 SQ를 나타냅니다.
- RQ^th (Things Recognition Quality): ‘things’ 클래스에 대한 RQ를 나타냅니다.
- PQ^st (Stuff Panoptic Quality): ‘stuff’ 클래스(일반적으로 연속적인 영역 또는 배경을 의미함)에 대한 PQ를 나타냅니다.
- SQ^st (Stuff Segmentation Quality): ‘stuff’ 클래스에 대한 SQ를 나타냅니다.
- RQ^st (Stuff Recognition Quality): ‘stuff’ 클래스에 대한 RQ를 나타냅니다.
- AP (Average Precision): 객체 탐지에서 사용되는 지표로, 모델이 객체의 클래스와 위치를 얼마나 잘 예측하는지를 평가합니다.
표에 따르면, DETR 모델은 다양한 백본(ResNet-50, ResNet-101)과 결합하여, ‘things’와 ‘stuff’ 카테고리 모두에서 괜찮은 PQ를 달성하며, 특히 ‘things’ 카테고리에서 높은 SQ와 RQ를 보여줍니다. DETR은 상대적으로 적은 파라미터로 이러한 성과를 달성하여, 모델의 효율성과 성능의 균형을 잘 보여줍니다.
Conclusion
DETR: Transformers와 bipartite matching loss를 활용하여 직접적인 set prediction을 가능하게 하는 Object Detection System입니다. COCO 데이터셋에서 최적화된 Faster R-CNN과 비슷한 수준의 성능을 보이며, 유연한 아키텍처를 바탕으로, 경쟁력 있는 결과를 제공하면서 panoptic segmentation까지 확장할 수 있습니다. Self-attention을 통한 전역 정보 처리로 인해 Large Objects에 대한 성능이 향상되었으나, Training, optimization, 그리고 Small Objects에 대한 성능은 향후 개선이 필요합니다.

👍👍