1. Voting Classifiers
Suppose you have trained a few classifiers, each one achieving about 80% accuracy.
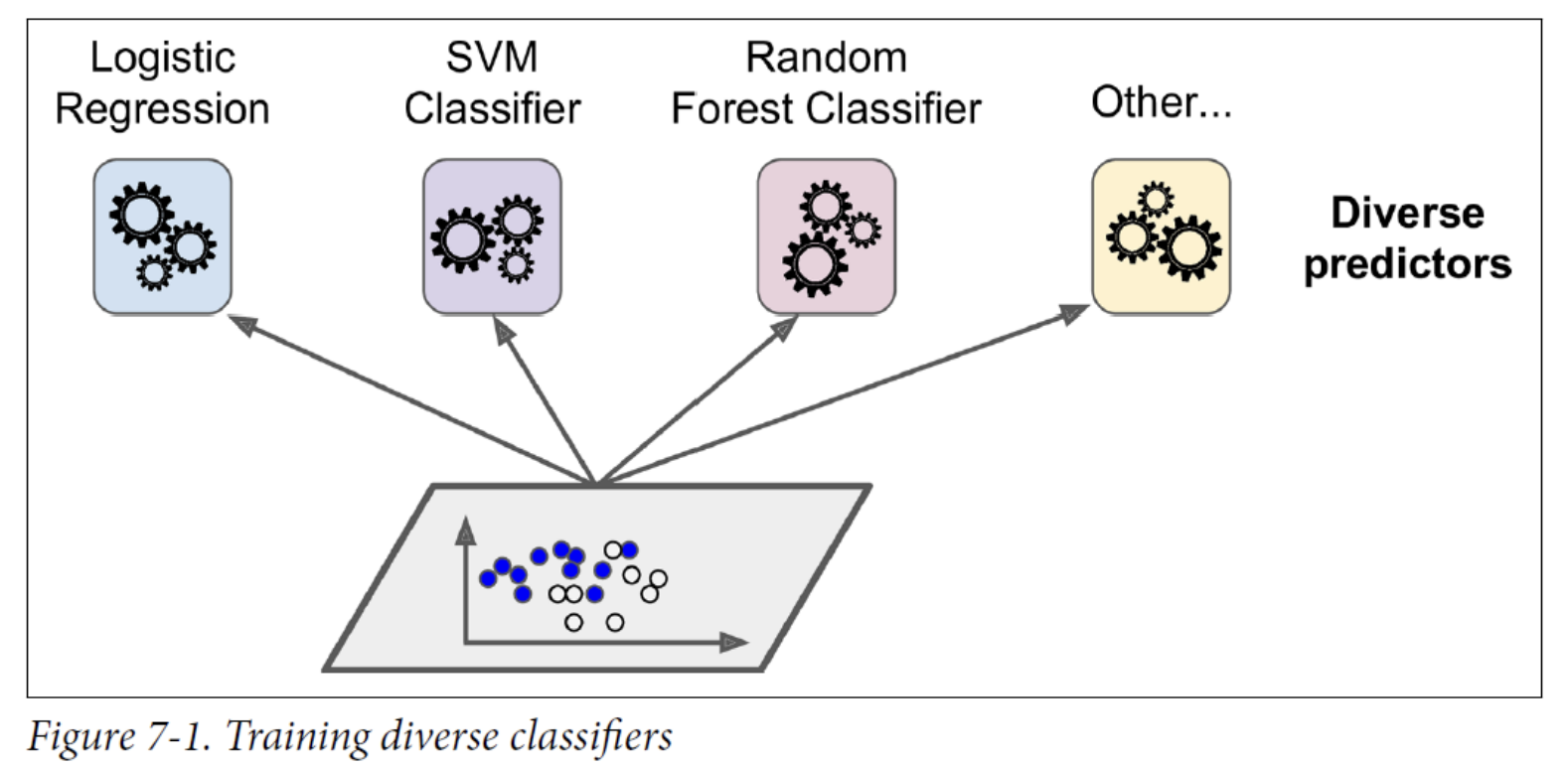
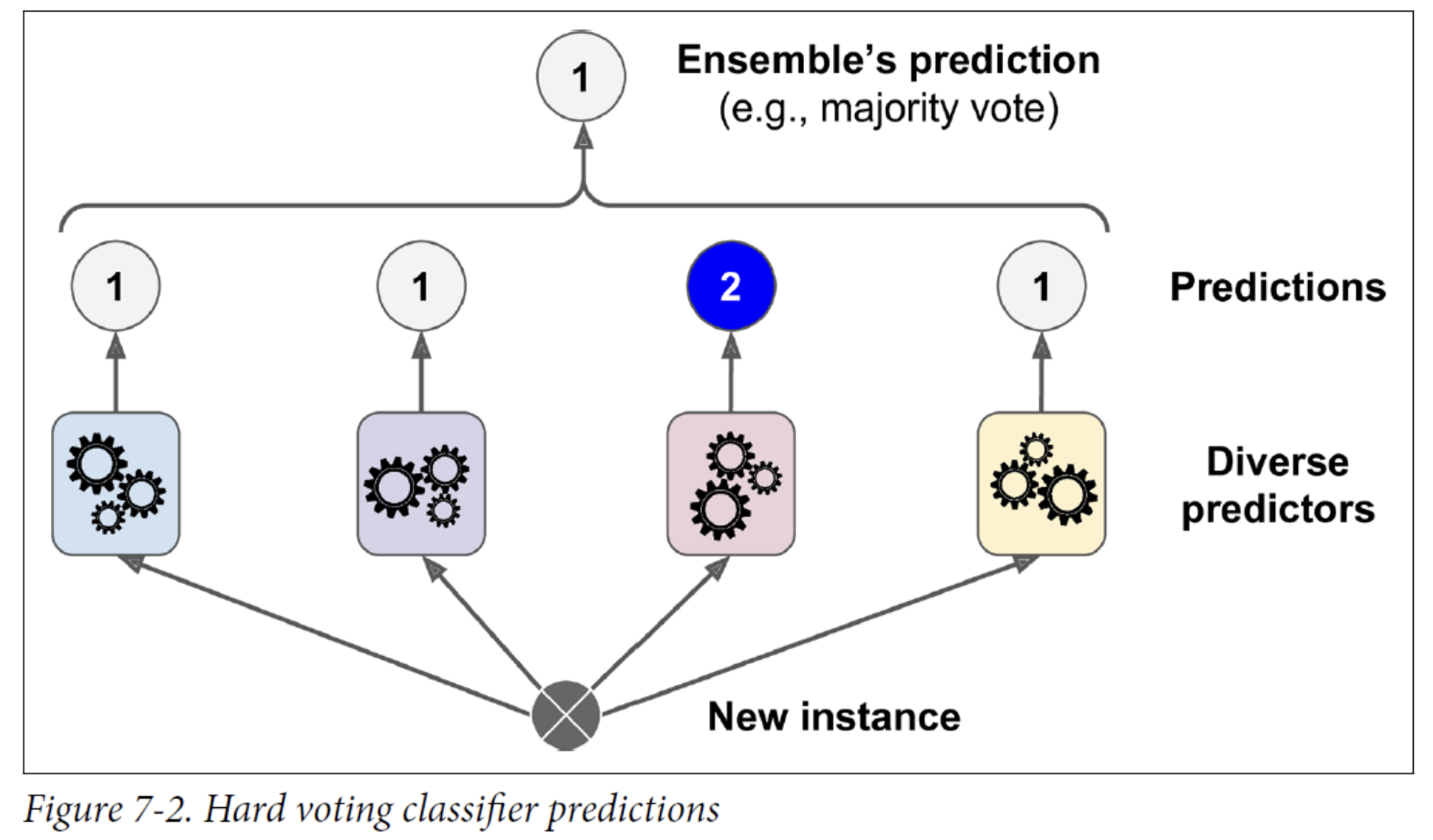
A very simple way to create an even better classifier is to aggregate the predictions of each classifier and predict the class that gets the most votes.
- This majority-vote classifier is called a hard voting classifier
Similarly, suppose you build an ensemble containing 1,000 classifiers that are individually correct only 51% of the time (barely better than random guessing).
However, this is only true if all classifiers are perfectly independent, making uncorrelated errors, which is clearly not the case because they are trained on the same data.
- They are likely to make the same types of errors, so there will be many majority votes for the wrong class, reducing the ensemble’s accuracy.
Ensemble methods work best when the predictors are as
independent from one another as possible.
You can tell Scikit-Learn to predict the class with the highest class probability, averaged over all the individual classifiers.
- This is called soft voting.
- All you need to do is replace voting="hard" with voting="soft" and ensure that all classifiers can estimate class probabilities.
- This is not the case for the SVC class by default, so you need to set its probability hyperparameter to True (this will make the SVC class use cross-validation to estimate class probabilities, slowing down training, and it will add a predict_proba() method).
2. Bagging and Pasting
Another approach is to use the same training algorithm for every predictor and train them on different random subsets of the training set.
When sampling is performed with replacement, this method is called bagging (short for bootstrap aggregating). When sampling is performed without replacement, it is called pasting.
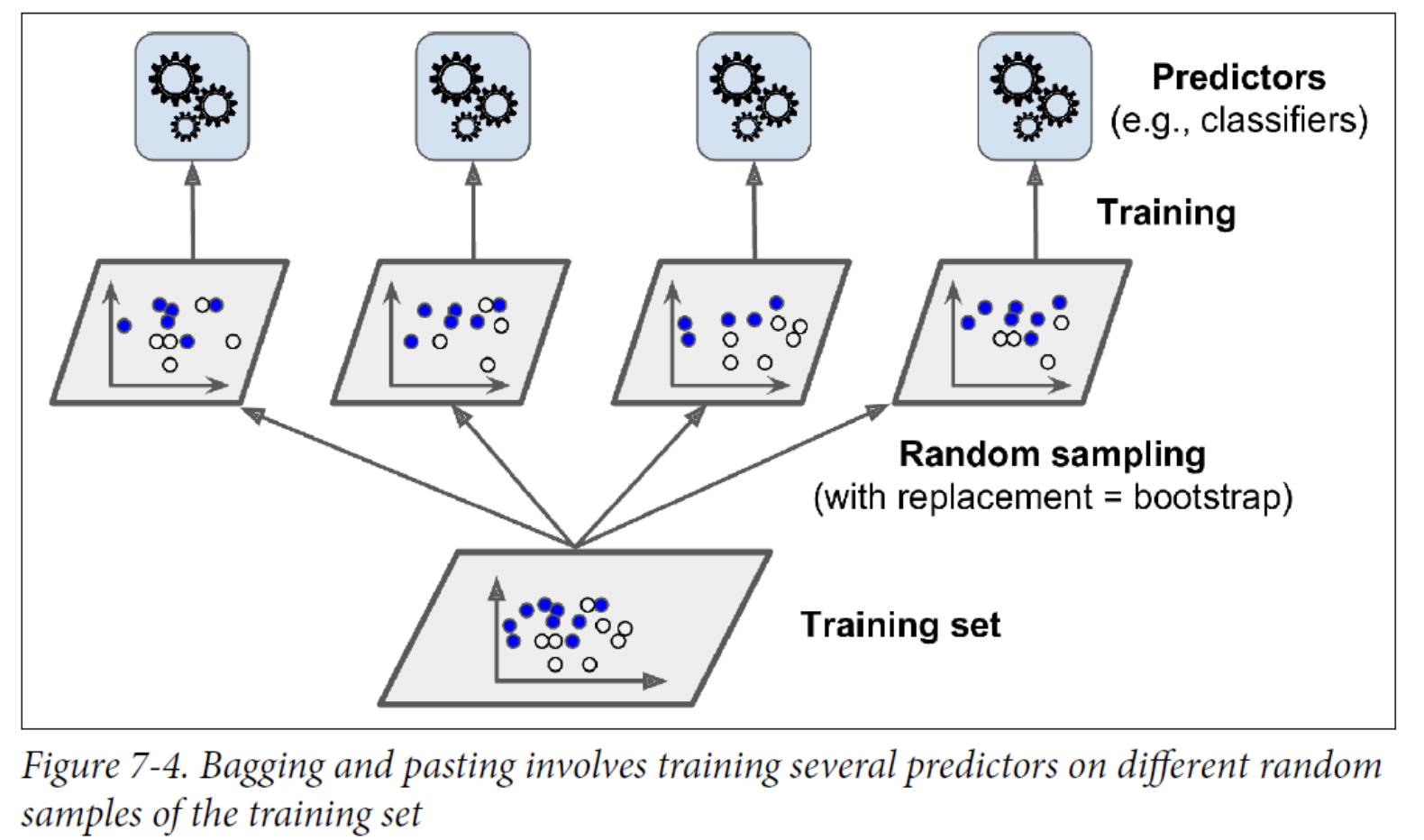
Each individual predictor has a higher bias than if it were trained on the original training set, but aggregation reduces both bias and variance.
- Generally, the net result is that the ensemble has a similar bias but a lower variance than a single predictor trained on the original training set.
With bagging, some instances may be sampled several times for any given predictor, while others may not be sampled at all.
Since a predictor never sees the oob instances during training, it can be evaluated on these instances, without the need for a separate validation set.
3. Random Patches and Random Subspaces
The BaggingClassifier class supports sampling the features as well. Sampling features results in even more predictor diversity, trading a bit more bias for a lower variance.
4. Random Forests
The Random Forest algorithm introduces extra randomness when growing trees; instead of searching for the very best feature when splitting a node, it searches for the best feature among a random subset of features.
- The algorithm results in greater tree diversity, which (again) trades a higher bias for a lower variance, generally yielding an overall better model.
Another great quality of Random Forests is that they make it easy to measure the relative importance of each feature.
- Scikit-Learn measures a feature’s importance by looking at how much the tree nodes that use that feature reduce impurity on average (across all
trees in the forest). - More precisely, it is a weighted average, where each node’s weight is equal to the number of training samples that are associated with it.
Scikit-Learn computes this score automatically for each feature after training, then it scales the results so that the sum of all importances is equal to 1.
5. Boosting
Boosting (originally called hypothesis boosting) refers to any Ensemble method that can combine several weak learners into a strong learner.
- The general idea of most boosting methods is to train predictors sequentially, each trying to correct its predecessor.
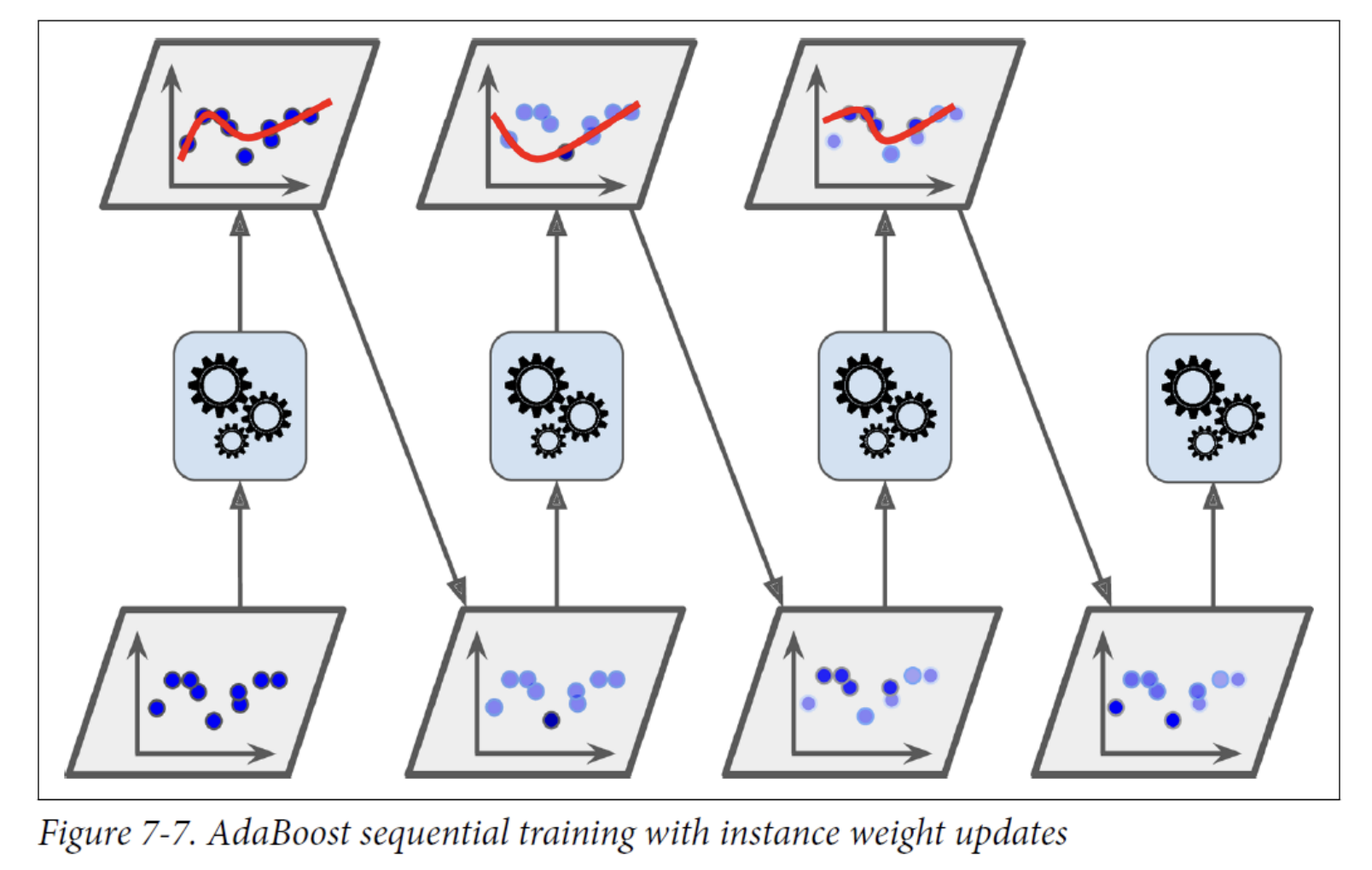
AdaBoost
One way for a new predictor to correct its predecessor is to pay a bit more attention to the training instances that the predecessor underfitted.
- This results in new predictors focusing more and more on the hard cases.


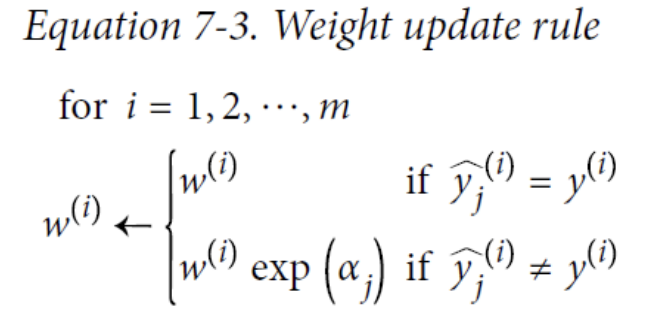

Gradient Boosting
Just like AdaBoost, Gradient Boosting works by sequentially adding predictors to an ensemble, each one correcting its predecessor.
However, instead of tweaking the instance weights at every iteration like AdaBoost does, this method tries to fit the new predictor to the residual errors made by the previous predictor.
6. Stacking
Stacking (short for stacked generalization)
- It is based on a simple idea: instead of using trivial functions (such as hard voting) to aggregate the predictions of all predictors in an ensemble, why don’t we train a model to perform this aggregation.
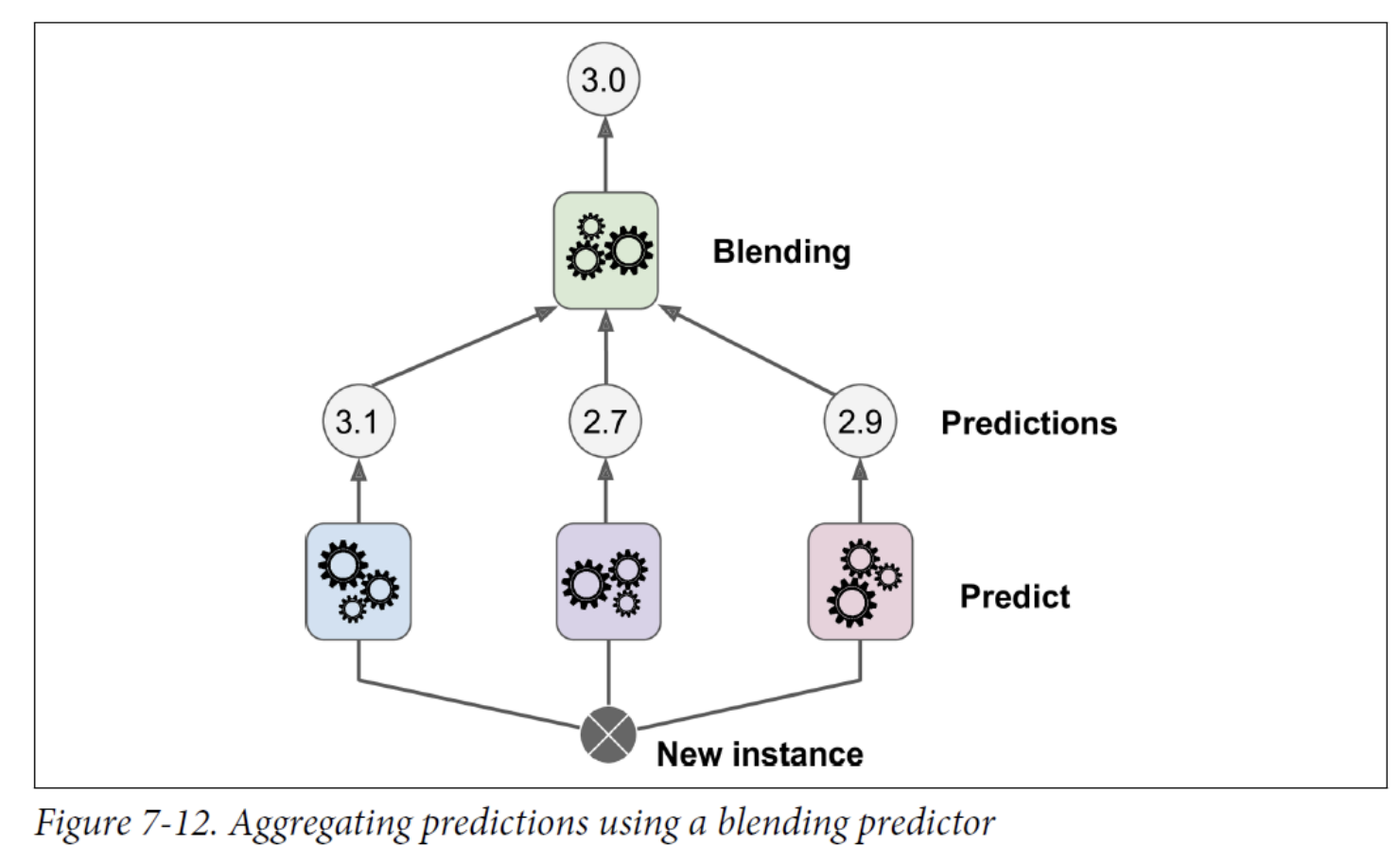
The following regression task: Each of the bottom three predictors predicts a different value (3.1, 2.7, and 2.9), and then the final predictor (called a blender, or a meta learner) takes these predictions as inputs and makes the final prediction (3.0).
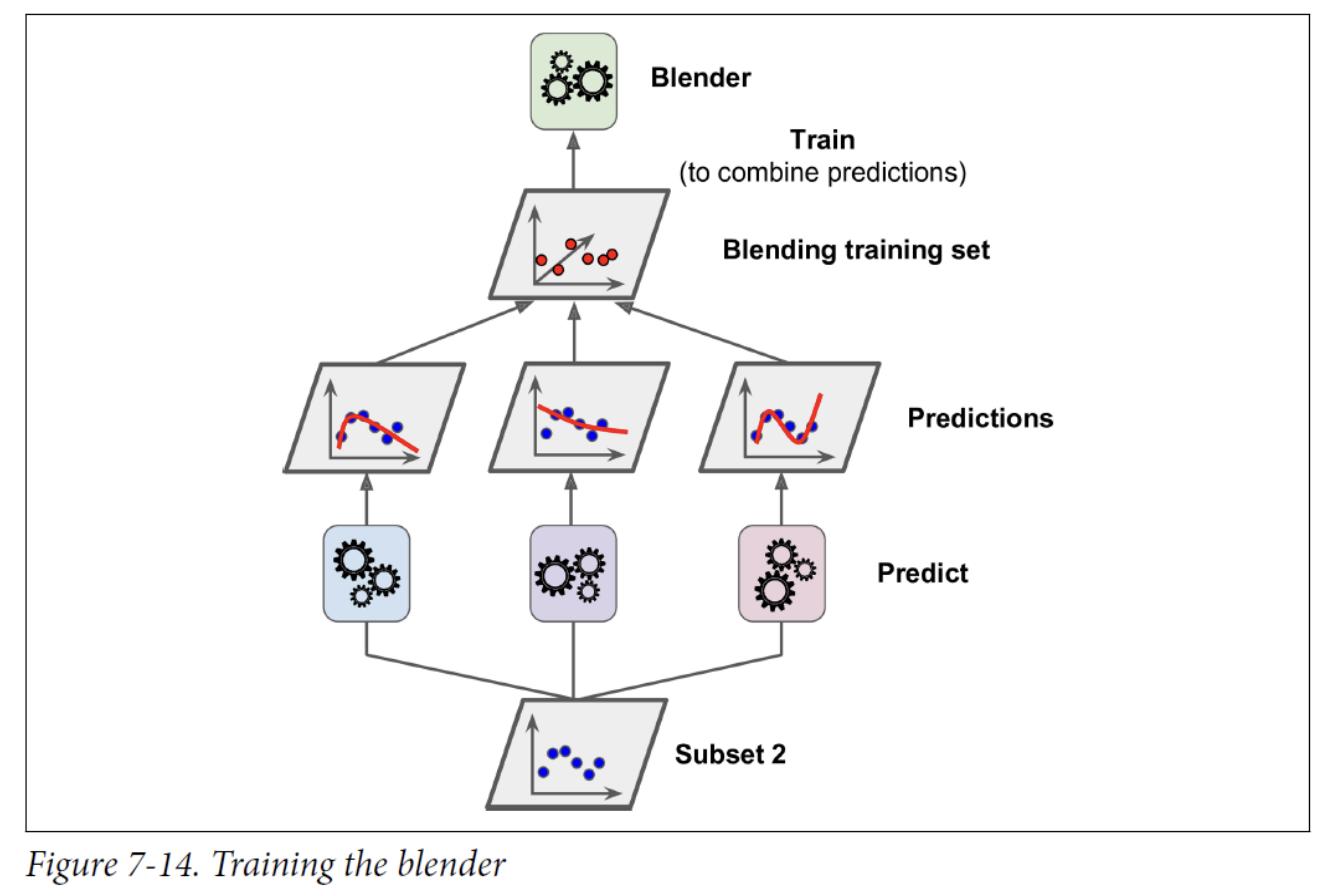
To train the blender, a common approach is to use a hold-out set.
- First, the training set is split into two subsets. The first subset is used to train the predictors in the first layer.
- Next, the first layer’s predictors are used to make predictions on the second (held-out) set. This ensures that the predictions are “clean,” since the predictors never saw these instances during training.
- We can create a new training set using these predicted values as input features (which makes this new training set 3D), and keeping the target values.
- The blender is trained on this new training set, so it learns to predict the target value, given the first layer’s predictions
It is actually possible to train several different blenders this way (e.g., one using Linear Regression, another using Random Forest Regression), to get a whole layer of blenders.

