
07-01 Perceptron
인공신경망은 수많은 머신러닝 방법 중 하나입니다. 초기의 인공 신경망인 퍼셉트론(Perceptron)에 대해서 살펴보겠습니다.
1. Perceptron
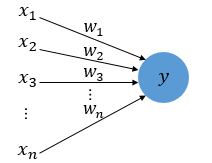
x는 입력값을 의미하며, w는 가중치(Weight), y는 출력값입니다. 그림 안의 원은 인공 뉴런에 해당됩니다. 각각의 인공 뉴런에서 보내진 입력값 x는 각각의 가중치 w와 함께 종착지인 인공 뉴런에 전달되고 있습니다.
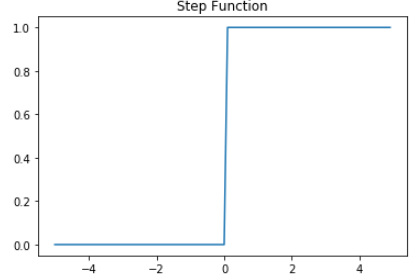
각 입력값이 가중치와 곱해져서 인공 뉴런에 보내지고, 각 입력값과 그에 해당되는 가중치의 곱의 전체 합이 임계치(threshold)를 넘으면 종착지에 있는 인공 뉴런은 출력 신호로서 1을 출력하고, 그렇지 않을 경우에는 0을 출력합니다. 이러한 함수를 계단 함수(Step function)라고 하며, 아래는 그래프는 계단 함수의 하나의 예를 보여줍니다.
이렇게 뉴런에서 출력값을 변경시키는 함수를 활성화 함수(Activation Function)라고 합니다. 초기 인공 신경망 모델인 퍼셉트론은 활성화 함수로 계단 함수를 사용하였지만, 그 뒤에 등장한 여러가지 발전된 신경망들은 계단 함수 외에도 여러 다양한 활성화 함수를 사용하기 시작했습니다.
2. Single-Layer Perceptron
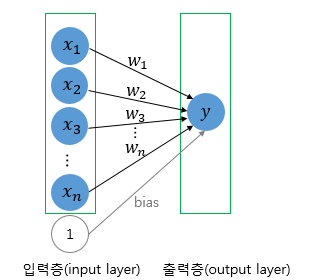
위에서 배운 퍼셉트론을 단층 퍼셉트론이라고 합니다. 퍼셉트론은 단층 퍼셉트론과 다층 퍼셉트론으로 나누어지는데, 단층 퍼셉트론은 값을 보내는 단계과 값을 받아서 출력하는 두 단계로만 이루어집니다. 이때 이 각 단계를 보통 층(layer)이라고 부르며, 이 두 개의 층을 입력층(input layer)과 출력층(output layer)이라고 합니다.
3. MultiLayer Perceptron
다층 퍼셉트론과 단층 퍼셉트론의 차이는 단층 퍼셉트론은 입력층과 출력층만 존재하지만, 다층 퍼셉트론은 중간에 층을 더 추가하였다는 점입니다. 이렇게 입력층과 출력층 사이에 존재하는 층을 은닉층(hidden layer)이라고 합니다. 즉, 다층 퍼셉트론은 중간에 은닉층이 존재한다는 점이 단층 퍼셉트론과 다릅니다. 다층 퍼셉트론은 줄여서 MLP라고도 부릅니다.

위와 같이 은닉층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network, DNN) 이라고 합니다. 심층 신경망은 다층 퍼셉트론만 이야기 하는 것이 아니라, 여러 변형된 다양한 신경망들도 은닉층이 2개 이상이 되면 심층 신경망이라고 합니다.
인공지능이 가중치를 스스로 찾아내도록 자동화시켜야하는데, 이는 머신 러닝에서 말하는 훈련(training) 또는 학습(learning) 단계에 해당됩니다. 학습 단계에서는 손실 함수(Loss function)와 옵티마이저(Optimizer)를 사용합니다. 그리고 만약 학습을 시키는 인공 신경망이 심층 신경망일 경우에는 이를 심층 신경망을 학습시킨다고 하여, 딥 러닝(Deep Learning)이라고 합니다.
**1. Feed-Forward Neural Network, FFNN**
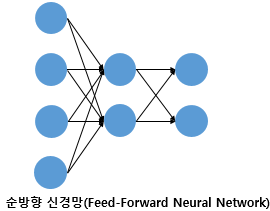
다층 퍼셉트론(MLP)과 같이 오직 입력층에서 출력층 방향으로 연산이 전개되는 신경망을 피드 포워드 신경망(Feed-Forward Neural Network, FFNN)이라고 합니다.

위의 그림은 FFNN에 속하지 않는 RNN이라는 신경망을 보여줍니다. 이 신경망은 은닉층의 출력값을 출력층으로도 값을 보내지만, 동시에 은닉층의 출력값이 다시 은닉층의 입력으로 사용됩니다.
2. Fully-connected layer, FC, Dense layer
다층 퍼셉트론은 은닉층과 출력층에 있는 모든 뉴런은 바로 이전 층의 모든 뉴런과 연결돼 있었습니다. 그와 같이 어떤 층의 모든 뉴런이 이전 층의 모든 뉴런과 연결돼 있는 층을 전결합층(Fully-connected layer) 또는 완전연결층이라고 합니다. 줄여서 FC라고 부르기도 합니다. 위의 그림에서는 다층 퍼셉트론의 모든 은닉층과 출력층은 전결합층입니다.
3. Activation Function
(1) 활성화 함수의 특징 - 비선형 함수(Nonlinear function)
인공 신경망에서 활성화 함수는 비선형 함수여야 합니다. 인공 신경망의 능력을 높이기 위해서는 은닉층을 계속해서 추가해야 합니다. 그런데 만약 활성화 함수로 선형 함수를 사용하게 되면 은닉층을 쌓을 수가 없습니다. 예를 들어 활성화 함수로 선형 함수를 선택하고, 층을 계속 쌓는다고 가정해보겠습니다. 활성화 함수는 y = wx라고 가정합니다. 여기다가 은닉층을 두 개 추가한다고하면 출력층을 포함해서 y = w^2x입니다. k = w^2이라고 정의하면 y = kx로 다시 표현이 가능합니다. 이 경우, 선형 함수로 은닉층을 여러번 추가하더라도 1회 추가한 것과 차이가 없음을 알 수 있습니다.
(3) 시그모이드 함수(Sigmoid function)와 기울기 소실
학습 과정
순전파(forward propagation) 연산 -> loss function
-> gradient 구하기 -> 가중치, 편향 업데이트(역전파)

주황색 구간에서는 미분값이 0에 가까운 아주 작은 값입니다. 초록색 구간에서의 미분값은 최대값이 0.25입니다. 다시 말해 시그모이드 함수를 미분한 값은 적어도 0.25 이하의 값입니다. 시그모이드 함수를 활성화 함수로하는 인공 신경망의 층을 쌓는다면, 가중치와 편향을 업데이트 하는 과정인 역전파 과정에서 0에 가까운 값이 누적해서 곱해지게 되면서, 앞단에는 기울기(미분값)가 잘 전달되지 않게 됩니다. 이러한 현상을 기울기 소실(Vanishing Gradient) 문제라고 합니다.
시그모이드 함수를 사용하는 은닉층의 개수가 다수가 될 경우에는 0에 가까운 기울기가 계속 곱해지면 앞단에서는 거의 기울기를 전파받을 수 없게 됩니다. 다시 말해 매개변수 w가 업데이트 되지 않아 학습이 되지를 않습니다.
sigmoid 외에도 ReLU, softmax, 등 다양한 종류의 활성화 함수가 있습니다. softmax는 각 클래스에 속할 확률을 알기 위해서 사용됩니다.
07-03 행렬곱으로 이해하는 신경망

07-04 딥 러닝의 학습 방법
1. 손실 함수(Loss function)
손실 함수는 실제값과 예측값의 차이를 수치화해주는 함수입니다. 이 두 값의 차이, 즉, 오차가 클 수록 손실 함수의 값은 크고 오차가 작을 수록 손실 함수의 값은 작아집니다. 회귀에서는 평균 제곱 오차, 분류 문제에서는 크로스 엔트로피를 주로 손실 함수로 사용합니다. 손실 함수의 값을 최소화하는 두 개의 매개변수인 가중치 w와 편향 b의 값을 찾는 것이 딥 러닝의 학습 과정이므로 손실 함수의 선정은 매우 중요합니다.
ex) MSE, Binary Cross-Entropy
2. 배치 크기(Batch Size)에 따른 경사 하강법
배치는 가중치 등의 매개 변수의 값을 조정하기 위해 사용하는 데이터의 양을 말합니다. 전체 데이터를 가지고 매개 변수의 값을 조정할 수도 있고, 정해준 양의 데이터만 가지고도 매개 변수의 값을 조정할 수 있습니다.
1) 배치 경사 하강법(Batch Gradient Descent)
배치 경사 하강법은 옵티마이저 중 하나로 오차(loss)를 구할 때 전체 데이터를 고려합니다. 딥 러닝에서는 전체 데이터에 대한 한 번의 훈련 횟수를 1 에포크라고 하는데, 배치 경사 하강법은 한 번의 에포크에 모든 매개변수 업데이트를 단 한 번 수행합니다.
2) 배치 크기가 1인 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
배치 크기가 1인 확률적 경사 하강법은 매개변수 값을 조정 시 전체 데이터가 아니라 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법입니다. 더 적은 데이터를 사용하므로 더 빠르게 계산할 수 있습니다.
3) 미니 배치 경사 하강법(Mini-Batch Gradient Descent)
전체 데이터도, 1개의 데이터도 아닐 때, 배치 크기를 지정하여 해당 데이터 개수만큼에 대해서 계산하여 매개 변수의 값을 조정하는 경사 하강법을 미니 배치 경사 하강법이라고 합니다. 미니 배치 경사 하강법은 전체 데이터를 계산하는 것보다 빠르며, SGD보다 안정적이라는 장점이 있습니다.
3. 옵티마이저(Optimizer)
1) 모멘텀(Momentum)
모멘텀(Momentum)은 관성이라는 물리학의 법칙을 응용한 방법입니다. 모멘텀 경사 하강법에 관성을 더 해줍니다. 모멘텀은 경사 하강법에서 계산된 접선의 기울기에 한 시점 전의 접선의 기울기값을 일정한 비율만큼 반영합니다.
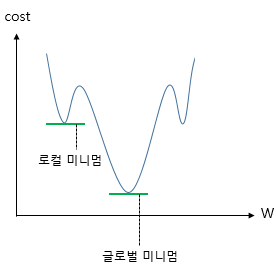
전체 함수에 걸쳐 최소값을 글로벌 미니멈(Global Minimum) 이라고 하고, 글로벌 미니멈이 아닌 특정 구역에서의 최소값인 로컬 미니멈(Local Minimum) 이라고 합니다. 로컬 미니멈에 도달하였을 때 글로벌 미니멈으로 잘못 인식하여 탈출하지 못하였을 상황에서 모멘텀. 즉, 관성의 힘을 빌리면 값이 조절되면서 현재의 로컬 미니멈에서 탈출하고 글로벌 미니멈 내지는 더 낮은 로컬 미니멈으로 갈 수 있는 효과를 얻을 수도 있습니다.
ex) Adam, Adagrad
5. 에포크와 배치 크기와 이터레이션(Epochs and Batch size and Iteration)
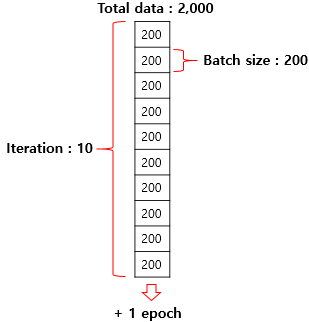
1) 에포크(Epoch)
에포크란 인공 신경망에서 전체 데이터에 대해서 순전파와 역전파가 끝난 상태를 말합니다. 전체 데이터를 하나의 문제지에 비유한다면 문제지의 모든 문제를 끝까지 다 풀고, 정답지로 채점을 하여 문제지에 대한 공부를 한 번 끝낸 상태를 말합니다.
2) 배치 크기(Batch size)
배치 크기는 몇 개의 데이터 단위로 매개변수를 업데이트 하는지를 말합니다. 현실에 비유하면 문제지에서 몇 개씩 문제를 풀고나서 정답지를 확인하느냐의 문제입니다. 인공지능은 실제값과 예측값으로부터 오차를 계산하고 옵티마이저가 매개변수를 업데이트합니다. 여기서 중요한 포인트는 업데이트가 시작되는 시점이 정답지/실제값을 확인하는 시점이라는 겁니다.
사람이 2,000 문제가 수록되어있는 문제지의 문제를 200개 단위로 풀고 채점한다고 하면 이때 배치 크기는 200입니다. 기계는 배치 크기가 200이면 200개의 샘플 단위로 가중치를 업데이트 합니다.
여기서 주의할 점은 배치 크기와 배치의 수는 다른 개념이라는 점입니다. 전체 데이터가 2,000일때 배치 크기를 200으로 준다면 배치의 수는 10입니다. 이는 에포크에서 배치 크기를 나눠준 값(2,000/200 = 10)이기도 합니다. 이때 배치의 수를 이터레이션이라고 합니다.
3) 이터레이션(Iteration) 또는 스텝(Step)
이터레이션이란 한 번의 에포크를 끝내기 위해서 필요한 배치의 수를 말합니다. 또는 한 번의 에포크 내에서 이루어지는 매개변수의 업데이트 횟수이기도 합니다. 전체 데이터가 2,000일 때 배치 크기를 200으로 한다면 이터레이션의 수는 총 10입니다.
위 내용은 아래의 책을 요약한 내용입니다.
자연어처리 입문하기
읽어주셔서 감사합니다~~
