
Overfitting이란?
머신 러닝 모델이 공원 밖에서 찍힌 개가 포함된 사진만을 훈련 데이터(training data)로 사용하면, 모델은 개를 분류하기 위한 특성으로 잔디와 같은 공원의 요소를 학습할 수 있습니다. 그러나 이렇게 훈련된 모델은 방 안에서 찍힌 개의 사진을 제대로 인식하지 못할 수 있고, 이로 인해 특정 상황에서만 작동하는 한계를 가질 수 있습니다.
💡 모델은 training data에서는 잘 수행되지만, test data에 대해 잘 수행되지 않음을 의미합니다.
Overfitting 원인
- 적은 traning data
훈련 데이터가 적으면 모델은 모든 가능성을 탐색할 기회를 얻지 못하게 됩니다. 이로 인해 모델은 주어진 데이터에만 적합하게(fitting) 되지만, 이전에 보지 못한 데이터를 도입하면 예측의 정확도가 떨어지고 분산도 증가하게 됩니다.
cf) 풀었던 문제(아는 문제)를 계속 푸는 학생과 틀렸던 문제, 새로운 문제, 아는 문제 모두 골고루 푸는 학생 중 누가 성적이 잘 나올까요?
- model의 복잡성
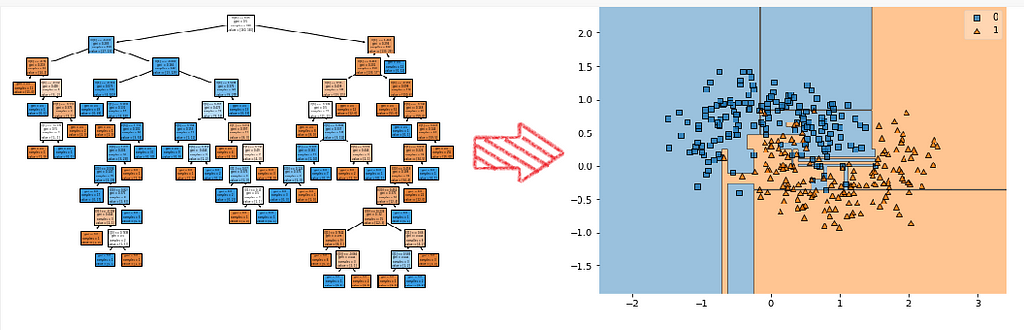
다음 그림은 Decision Tree입니다. 네모와 세모를 복잡하게(정밀하게) 분리하려고 해서 경계가 매끄럽지 않은 모습입니다.
Overfitting 해결법
Early stopping, Pruning, Regularization, Ensembling, Data augmentation
Regularization
Dropout

모든 훈련 단계에서 모든 뉴런(입력 뉴런은 포함되지만 출력 뉴런은 제외)은 일시적으로 "드롭아웃"될 확률 p를 가지며, 이는 해당 훈련 단계 동안 완전히 무시될 것임을 의미합니다. 테스트 중에는 다시 활성화됩니다.
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(300, activation="elu", kernel_initializer="he_normal"),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal"),
keras.layers.Dropout(rate=0.2),
keras.layers.Dense(10, activation="softmax")
])코드에서 rate가 p이고 계층을 지나갈 때마다 드롭아웃을 합니다.
💡 Dropout은 효과가 뛰어나다고 알려져 있습니다. 왜 효과가 뛰어날까요?
🙋 회사 직원들에게 매일 아침 동전을 던져 출근 여부를 결정하라고 한다면 성과가 좋아질까요?
회사는 당연히 조직 구조를 조정해야 할 것이며, 커피 머신을 채우거나 다른 중요한 업무를 수행할 특정 인원에 의존할 수 없게 될 것입니다. 따라서 이러한 전문 업무는 여러 사람에게 분산되어야 할 것입니다. 직원들은 소수의 동료와만 협력하는 것이 아니라 많은 동료와 협력할 수 있어야 할 것이며, 회사는 그 결과로 훨씬 더 유연해질 것입니다. 한 사람이 퇴사한다 해도 크게 문제가 되지 않을 것입니다. 이런 방식이 회사에게 실제로 적용될지는 알 수 없지만, 신경망에는 확실히 통용됩니다. 드롭아웃을 통해 훈련된 뉴런은 이웃 뉴런과 공동으로 적응할 수 없으므로, 개별적으로 최대한 유용해져야 합니다. 또한 소수의 입력 뉴런에 지나치게 의존할 수 없으므로, 모든 입력 뉴런을 고려해야 합니다. 그 결과로, 입력의 약간의 변화에 덜 민감한, 더욱 견고하고 일반화 능력이 높은 네트워크가 만들어집니다.

학교에서 배운 내용이 새록새록 기억나네요 ㅎㅎ 잘 읽었습니다