Stack
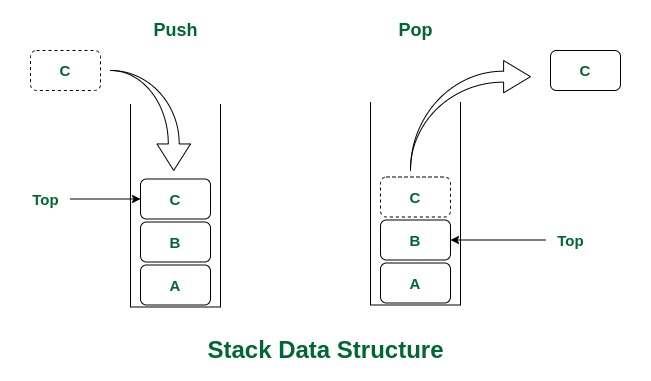
먼저 스택은 한 쪽 끝에서만 자료를 넣고 빼는 작업이 이루어지는 자료구조입니다. LIFO (Last In First Out) 방식으로 동작하며 가장 최근에 스택에 삽입된 자료의 위치를 top이라 합니다.
스택의 stack.push()는 top 에 새로운 데이터를 추가하고, stack.pop()은 가장 최근에 삽입된 데이터가 스택에서 삭제됩니다.
스택의 맨 위 요소, top 에만 접근이 가능하기 때문에 top 이 아닌 위치의 데이터에 대한 접근, 삽입, 삭제는 모두 불가능합니다.
스택이 비어있을 때 stack.pop()을 시도하는 것을 stack underflow 라 하고 스택의 크기가 비어있을 때 stack.push()를 시도할 때 stack overflow가 발생한다.
시간복잡도
top 위치의 데이터에 바로 접근이 가능하기 때문에 데이터 삽입, 삭제의 시간 복잡도는 O(1)입니다. 마지막에 삽입한 자료만 읽을 수 있기 때문에 검색의 경우 O(n)입니다.
장단점
top 을 통해 접근하기 때문에 데이터 접근, 삽입, 삭제가 빠릅니다. top 위치 이외의 데이터에 접근할 수 없기 때문에 탐색이 불가능하다. 탐색하려면 모든 데이터를 꺼내면서 진행해야 합니다.
활용
- 웹 브라우저 방문기록 (뒤로 가기) : 가장 나중에 열린 페이지부터 다시 보여준다.
- 실행 취소 (undo) : 가장 나중에 실행된 것부터 실행을 취소한다.
- DFS(Depth First Search)
Queue
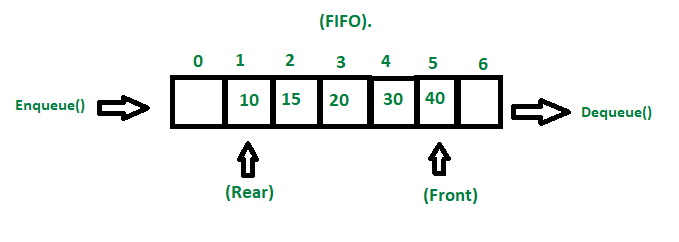
Queue 의 사전적 의미는 (무엇을 기다리는 사람, 자동차 등의) 줄 , 혹은 줄을 서서 기다리는 것을 의미합니다.
일상생활에서 놀이동산에서 줄을 서서 기다리는 것, 은행에서 먼저 온 사람의 업무를 창구에서 처리하는 것과 같이 선입선출(FIFO, First in first out) 방식의 자료구조를 말합니다.
삭제연산만 수행되는 곳은 프론트(front), 삽입연산만 이루어지는 곳은 리어(rear)입니다. 이때, 큐의 리어에서 이루어지는 삽입연산을 Enqueue, 프론트에서 이루어지는 삭제연산을 Dequeue라고 부릅니다.
시간 복잡도
큐 역시 front, rear 의 위치로 데이터 삽입 삭제가 바로 이루어지기 때문에 원소 삽입, 삭제의 시간 복잡도는 O(1)입니다. 검색은 stack과 마찬가지로 O(n)입니다.
장단점
데이터 접근, 삽입, 삭제가 빠르다.
큐 역시 스택과 마찬가지로 중간에 위치한 데이터에 대한 접근이 불가능하다.
활용
- BFS(Breadth First Search)
- 프로세스 관리
Stack vs Queue vs LinkedList
| Stack | Queue | LinkedList | |
|---|---|---|---|
| 삽입 | O(1) | O(1) | O(1) |
| 삭제 | O(1) | O(1) | O(1) |
| 검색 | O(n) | O(n) | O(n) |
데이터를 추가/삭제하는 작업이 빈번하다면 LinkedList를 사용하는 것이 좋습니다. 반면, 후입선출이나 선입선출 구조가 필요한 경우에는 Stack이나 Queue를 사용하는 것이 좋습니다.
Appendix(Priority Queue)
큐(Queue)는 먼저 들어오는 데이터가 먼저 나가는 FIFO(First In First Out) 형식의 자료구조입니다.
우선순위 큐(Priority Queue)는 먼저 들어오는 데이터가 아니라, 우선순위가 높은 데이터가 먼저 나가는 형태의 자료구조입니다. 내부가 힙으로 구현되어 있는 것이 가장 효율적입니다.
Heap
모든 요소들을 고려하여 우선순위를 정할 필요 없이 부모 노드는 자식노드보다 항상 우선순위가 앞선다는 조건만 만족시키며 완전이진트리 형태로 채워나갑니다.
부모노드와 자식노드간의 관계만 신경쓰면 되기 때문에 형제 간 우선순위는 고려되지 않습니다. 이러한 정렬 상태를 흔히 반정렬 상태라고 합니다.
cf) 완전이진트리(complete binary tree)는 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있는 트리입니다.
- 최대 힙 (Max Heap)
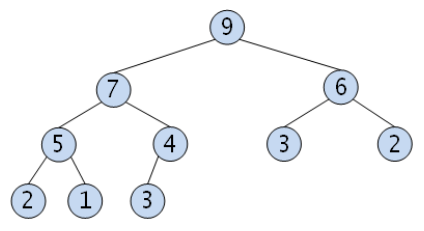
부모 노드의 키 값이 자식 노드보다 크거나 같은 완전이진트리입니다.
key(부모노드) ≥ key(자식노드)
- 최소 힙
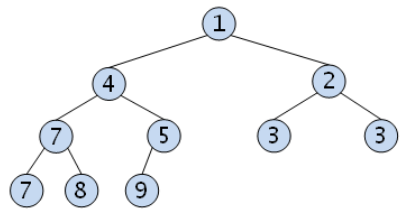
부모 노드의 키 값이 자식 노드보다 작거나 같은 완전이진트리이다.
key(부모노드) ≥ key(자식노드)
