지그재그 Personalize 분석
지그재그
- 여성 쇼핑몰 서비스로 동대문 시장 상품 크롤링하여 데이터를 모아서
■ 상품 통합검색
■ 상품몰 랭킹
■ 찜한 상품 모아보기 등이 있습니다
But
3700개 + 입정 쇼핑몰
300만 + 월간이용자(MAU) 가 점차 늘어나면서 ```
빅데이터에 대한 구조와 활용이 필요해짐
개인화 시스템(Personalize System)
Rule-Based
-시스템구현하기 쉬움
-데이터가 많아질수록 성능이 떨어짐
-유지보수가 어려움
👉 **대부분이 좋아하는것만을 추천 **Collaborative Filltering, Factorization Machine
-개인화 추천을 위해 많이 사용되는 알고리즘
-구현을 위해 제공되는 리소스가 많아서 쉽게 적용 가능
Deep Learning
-사용자 이벤트의 연속성을 고려
-대용량 데이터에서도 좋은 성능을 유지
개인화 추천 구현 시 어려운점
-Cold Start 문제 : 신규유저, 신규상품의 데이터가 없음
-실시간 이벤트 처리
-빅데이터 스케일링
-Machine Learning 전문가
Amazon Personalize 란?

머신러닝 딥러닝에 대한 지식이 없어도 모델 학습부터 배포까지 모든과정을 진행할 수 있습니다
딥러닝 알고리즘
1.HRNN(유저들 맞춤 상품)
2.CF(상품간의 유사도 기반) 👉데이터는 S3에 저장합니다
지그재그 Personalize 구성도

AWS 분석용 파이프라인 갖추었다.
Amazon S3 와 AWS Glue를 이용해서 데이터 lake 쉽고 빠르게 구축
Airflow을 이용해서 시간에따라 전처리 Kinesis를 이용 실시간 데이터를 구축
Athena AWS/EMR을 통해서 머신러닝에 이용되고 있다.
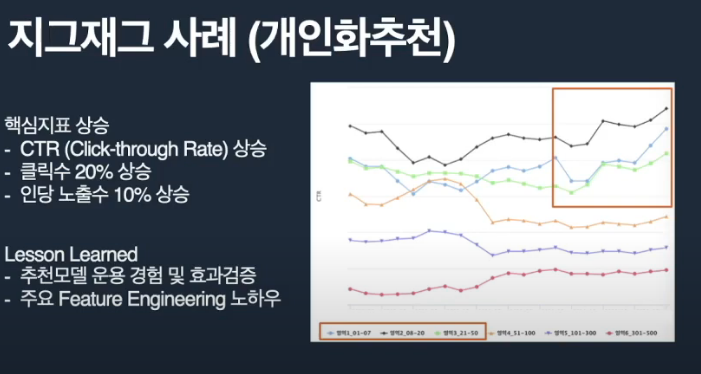
지그재그 기능
- 지표의 추천에 대해 나아가 추천에 대한 비즈니스 전략을 수립
- 시스템 고도화에 대한 실패와 성공에 대한 반복이 필요
마무리
- AWS Personalize 는 스타트업 초기 구축하기에는 무리가 있으며, 빅데이터를 만들기전에 초기 데이터 수집이 가장 필요한 부분이다.
- 만약 앱을 관리한다면 데이터가 커짐에 따라 순서 알고리즘은
Rule-Basesd(Categorical Data) -> CB > CF > LF 형식으로 관리할 것이다.- 머신러닝을 정교화해서 추천화 알고리즘을 만드는것 보다 일단 모델을 집어넣고 모델의 기능을 향상시키는 Personalize 시스템이 가장 인상 깊었다.

Developer-Android-CK