💙💙 Mechanism 설명

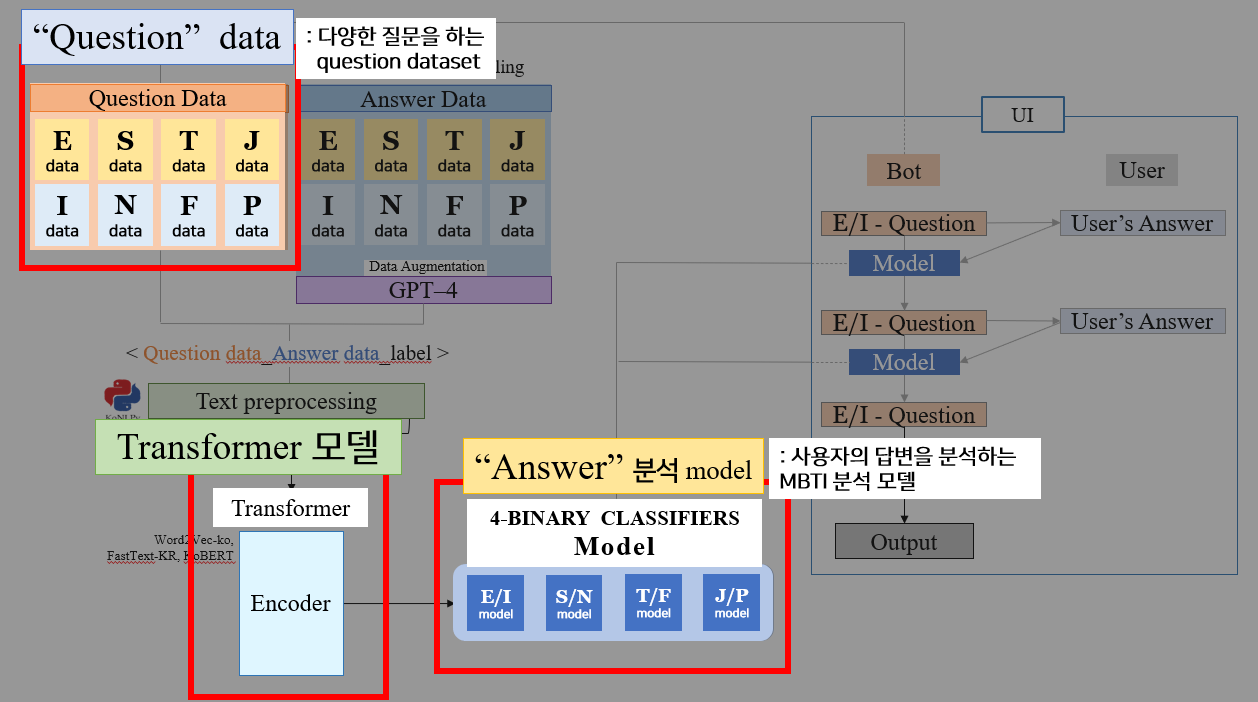 구조는 크게 3가지로 구분할 수 있다.
구조는 크게 3가지로 구분할 수 있다.
1) "Question" Data
: 질문 데이터 셋
2) "Answer" 분석 모델
: 사용자의 답변을 분석하는 MBTI 분석 모델
3) Transformer - Encoder 모델
: Answer 분석 모델의 기반이 되는 학습 모델
1. “Question” data

1) 사전에 준비된 질문
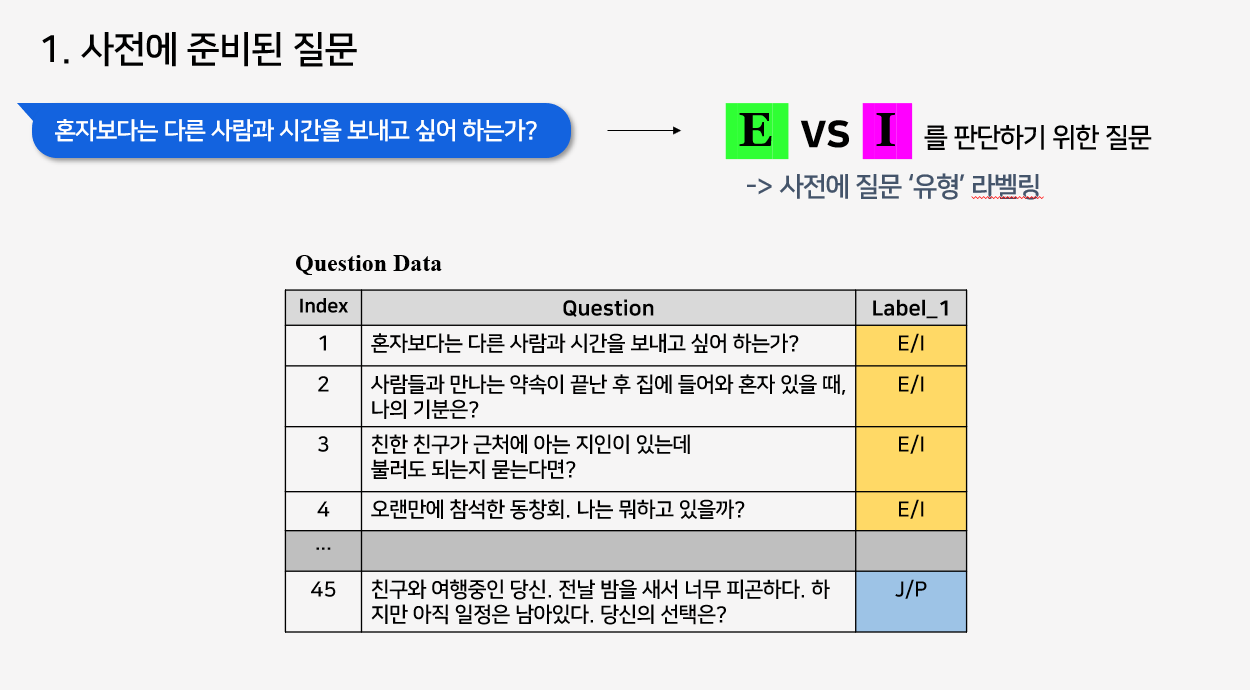
- 질문은 내가 직접 모두 작성도록 한다.
- 모든 질문은 사전에 유형별로
labeling해 놓는다.
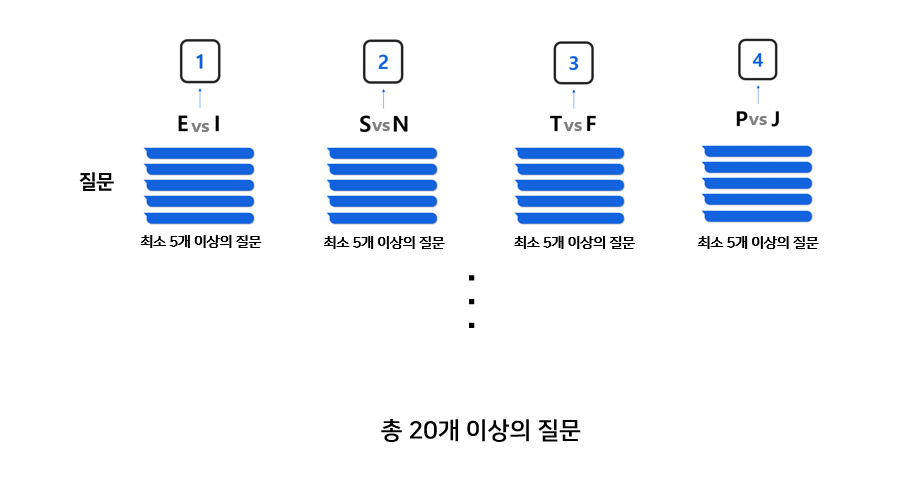
각 유형에 대한 질문은 최소 5개 이상이다.
홀수로 하는 이유는, 짝수로 했다면 EEII가 나왔을 때 이 사람의 MBTI가 무엇인지 알 수가 없기 때문이다. (물론 아직은 한 답변에 대한 Bot이 인식하는 것을 1 혹은 0으로 쓸 것이지만, 나중에 어느정도 완성이 되고나면 실수로 좀더 정확하게 개선하는 방향도 고려해 볼 것이다.)
이런식으로 5개씩 4개의 유형에 대해 사용자는 질문을 받게된다.
즉, User은 총 최소 20개 이상의 질문을 받게 된다. (추후 수정할수도!)
2) 특별한 상황을 가정한 질문
< 가장 마지막 단계에 진행예정(어려울 것이라 예상) / 개발 초안 / 개발 미정 >
 기존 MBTI 검사와 같이 딱딱한 질문만을 계속하는 건 재미가 없을 것 같았다.
기존 MBTI 검사와 같이 딱딱한 질문만을 계속하는 건 재미가 없을 것 같았다.
그래서 참신함을 더해 상황을 가정하여, 그 상황에서 MBTI를 구분할 수 있는 여러가지 질문을 하는 질문방식도 일부 추가해보려고 한다.
1) 사전에 준비한 질문

가상 환경과 그에 따른 질문 모두 직접 만드는 것이다.
예상되는 문제점으로는
- 정말 다양한 답변이 나올 수 있기 때문에, 답변이 기존에 학습된 데이터와 완전히 어긋나서 제대로 모델이 판단을 못할 수 있다.
- 질문과 질문 사이에 맥락이 이어지지 않아 어색할 수 있다.
- 질문 생성에 한계가 있을 수 있다.
- 사용자가 답변으로 오히려 질문하는 등의 행위를 했을 때 오류가 발생할 수 있다.
2) KoGPT를 사용한 질문 자동생성
 위의 경우는 카카오에서 개발한 KoGPT를 이용해서 자동으로
위의 경우는 카카오에서 개발한 KoGPT를 이용해서 자동으로 상황 가정+상황에 따른 질문을 생성하는 방식을 적용할 예정이다. 정말 많은 질문들과 답변들이 나올 수 있기때문에 정확도가 굉장히 낮아질 수도 있다.
- 문장 자동생성 GPT같은 경우는 데이터 부족 등의 문제로 만드는 데 한계가 있기때문에 GPT API를 수정하여 이용하고자 한다.

2. “Answer” 분석 model

ANSWER 모델은 이 프로젝트의 핵심 부분을 담당한다.
이부분을 잘 만드는게 가장 중요하다고 보면 된다.
나올 수 있는 Answer 유형을 크게 3가지로 나눠서 모델을 구성해봤다.
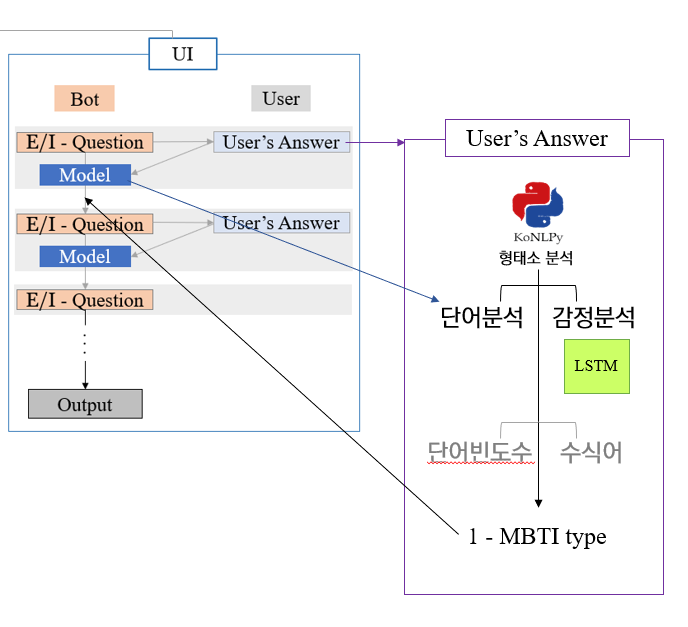 1) 일반적인 응답
1) 일반적인 응답
2) 중립적으로 대답
3) 완전히 다른 대답 (else)
1) 일반적인 응답 (핵심)
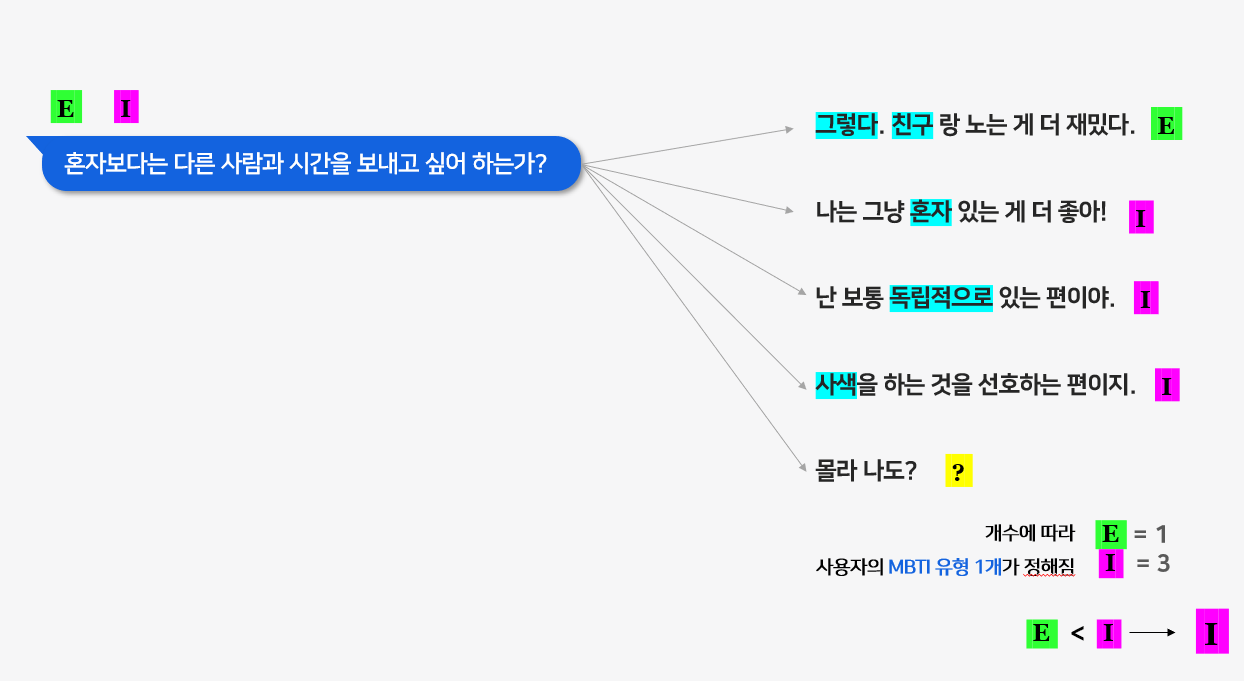 한 질문마다 정말 무한가지의 답이 나올 수 있다.
한 질문마다 정말 무한가지의 답이 나올 수 있다.
Model은 오직 User의 Answer만을 분석하여 MBTI 유형을 판단한다.
그렇기에 User의 다양한 답변이 필요하다.

GPT를 사용하지 않고, 학부생의 신분으로 데이터를 엄청나게 끌어오는 건 현실적으로 불가능하다.
이에 예상되는 답변들의 공통적인 판단 기준을 세운 뒤, 이를 바탕으로 모델이 기준에 따른 특징들만 분석하는 것이 적합하다고 생각했다.
ANSWER의 판단기준은 다음과 같다.
- 단어의 임베딩 벡터값
- 감정분석
- 단어 출현 빈도수
- 수식어- 부사
위의 기준에 의거하여 답변을 분석하고 MBTI를 분석해 낼 것이다.
GPT와 같은 API를 사용하면 굉장히 편리하지만, 모든 데이터와 모델을 직접 구성하겠다는 졸업작품의 취지와는 맞지않다.
각 기준에 대해 조금 더 자세히 설명하자면,
-
단어의 임베딩 벡터값
: 응답 분석Model이다.
이 모델을 통해 E인지 I인지, S인지 N인지 등등 구분이 가능하다.
이 모델은Transformer의 Encoder로 사전에 학습시킨 임베딩 벡터값을 바탕으로User의 Answer을 분석할 것이다.
(혹은워드 임베딩 도구를 일부 사용할 것이다.)
(추후 구체화) -
감정분석 (긍/부정)
User의 응답에 질문의 MBTI유형과 유사한 임베딩 벡터값이 있다 하더라도, 그 문장이 부정이 되어버린다면 질문의 MBTI유형과 반대되는 답변을 한 것이 된다.
예를 들어,당신은 밖에 나가는 것을 즐깁니까?란 질문에밖에서 노는 건 별로 선호하지 않습니다.라고 대답했다 가정하자.
밖이라는 E유형에 해당되는 임베딩 벡터값이 검출됐다 하더라도 그뒤에 이어지는 단어들은별로 선호하지 않는다.이다. 그렇기에 E유형 + (부정) = I유형이 된다.
(왜냐하면 E의 반대는 무조건 I이기 때문)
그렇기에긍/부정을 구분할 수 있어야 제대로 된 문장 판단이 가능할 것이다.
감정분석으로는LSTM을 사용할 생각이다.
- 단어 출현 빈도수
예시)나는 집에 있는 것이 좋지만, 그와 동시에 친구들과 밖에서 신나게 파티를 즐기는게 좋다.
I유형 -집
E유형 -친구밖파티
E유형에 대해서는 관련 단어가 무려 3번이나 언급됐다.
그만큼 E유형에 대해 작성할 말이 많고, 이는 I유형보단E유형에 더 해당된다 라는 결론으로 이어질 수 있다.
- 수식어- 부사
가중치에 해당하는 기준이다.
예를 들면,나는 집에 있는 것보다 밖에 나가는게훨씬 좋다.
이훨씬이란 단어(부사)에 가중치를 더하여집 < 밖임을 모델에게 인식시켜줘야 한다.
이 가중치의 값은Attention Score로 할 수 있을 것 같다.
위의 기준들을 바탕으로 실제 대답 분석 작업을 임의로 진행해봤다.
 위의 질문에 대한 답변을 작성하고,
위의 질문에 대한 답변을 작성하고,
답변을 Konlpy를 이용해서 형태소 단위로 분석하여 출력하였다.
여기서 중요한 단어의 품사를
체언 용언 부사 어근이라고 지정했다.
나머지 단어들은 모두 불용어이다. (추후 수정될 수도 있음!)
 뽑아낸 단어들만 다음과 같이 정렬하였다.
뽑아낸 단어들만 다음과 같이 정렬하였다.
위의 판단기준에서 3번과 4번은 부가적인 요소이기에 추후에 작업하도록 하고, 가장 중요한 1), 2)에 대해서만 기준을 세워보았다.
체언, 어근과 같이 명사에 해당되는 것들은 문장의 핵심 키워드와 같은 존재이기에 1) 워드 임베딩 벡터값을 판단하는 데 사용된다.
ex) 조용, 집, 친구, 사람 ...
2) 감정분석같은 경우는 보통 형용사, 동사이 포함된 용언에 해당된다.
ex) 좋다, 싫다, 즐겁다 ...

,을 기준으로 문장이 반전될 수 있기에 문장을 2개로 나누었다.- 1문장과 2문장에 대해서 기준 1과 기준2에 해당되는 단어들만을 뽑아냈다.
1문장 같은 경우
조용(I: 0.9) + 즐기(긍정) =I 0.9
로 출력했다.
2문장 같은 경우는
인연(I: 0.5) + 즐기(긍정) =E 0.5
로 출력할 수 있다.
(각 임베딩 벡터값은 임의로 설정한 것이다.)
따라서, 위의 문장은E 0.5I 0.9이므로I 유형에 더 가까운 답변이라 해석할 수 있다.
2) 중립적으로 대답
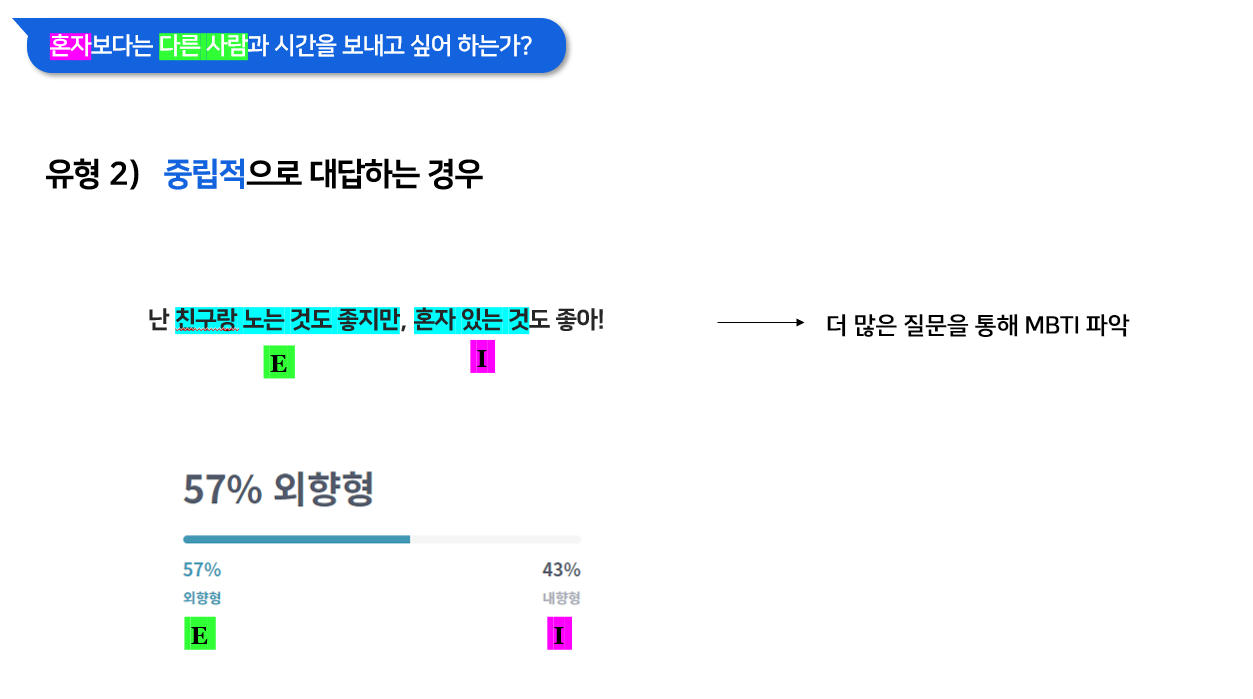 중립적으로 대답하는 경우는
중립적으로 대답하는 경우는
만일 질문이 E와 I를 구분하는 질문이었는데
E의 행동, I의 행동 둘다 좋다! 라고 답하는 경우이다.
이는 필자와 같이 E:I = 57:43 정도의 수치를 가지는 사람일 것이다.
그렇기에 이같은 경우는 E/I에 대한 질문을 조금더 많이 할 필요가 있다고 판단할 것이다.
3) 완전히 다른 대답 (else)
 완전히 엉뚱한 대답을 할 경우
완전히 엉뚱한 대답을 할 경우 적절하지 않은 답변이라고 판단하여 다시 질문하게 된다.
만일, 새로운 장소와 같이 E와 I를 구분하기 어려운 애매한 답변을 할 시에도
명확하게 자신의 의도를 드러내지 않았기 때문에 잘못된 답변이라고 판단할 것이다.
갑자기 생각난건데
일정비율의 임베딩 벡터값을 넘지 못하면 모두 잘못된 문장으로 판단하고자 한다.~~~
나중에 참고해보자!
3. Transformer

사실,,,,,, 아직 Transformer 모델에 대해 잘 모른다..
그래서 대략적인 방식만 생각해두고 트랜스포머의 세부 모델에 대해서는 잘 모르겠다..ㅎㅎ
-
Transformer을 사용하여 MBTI를 판단하는 4개의 Model을 만들 것이다.
-
Transformer 모델에서 Encoder에 해당하는 부분만 사용할 것이다.
(BERT와 같이 인코더 부분만 사용할 것이다.)
나는 번역이나 문장생성 같은 프로젝트를 하는 것이 아닌,
단순히 잘 학습된 임베딩 벡터값만 뽑아내는 것이기 때문에
Decoder까지는 필요가 없다.
Encoder 자체만으로도 Self-Attention을 통해 높은 성능의 벡터값을 구할 수 있을거리라 생각한다.
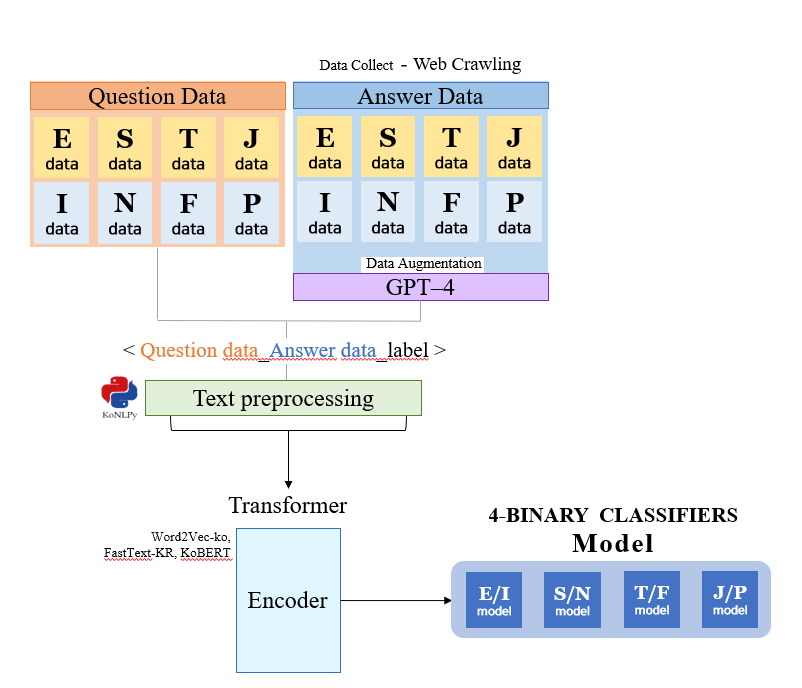
>> Data SET 구성
일단 지금 단계에서 생각할 수 있는 건 데이터 셋의 구성이다.
Transformer모델에는 <Question, Answer> 데이터 셋을 통째로 Input으로 넣어서 셀프 어텐션하는 것이라 대충 알고있어서 그렇게 데이터를 구성하고자 한다.
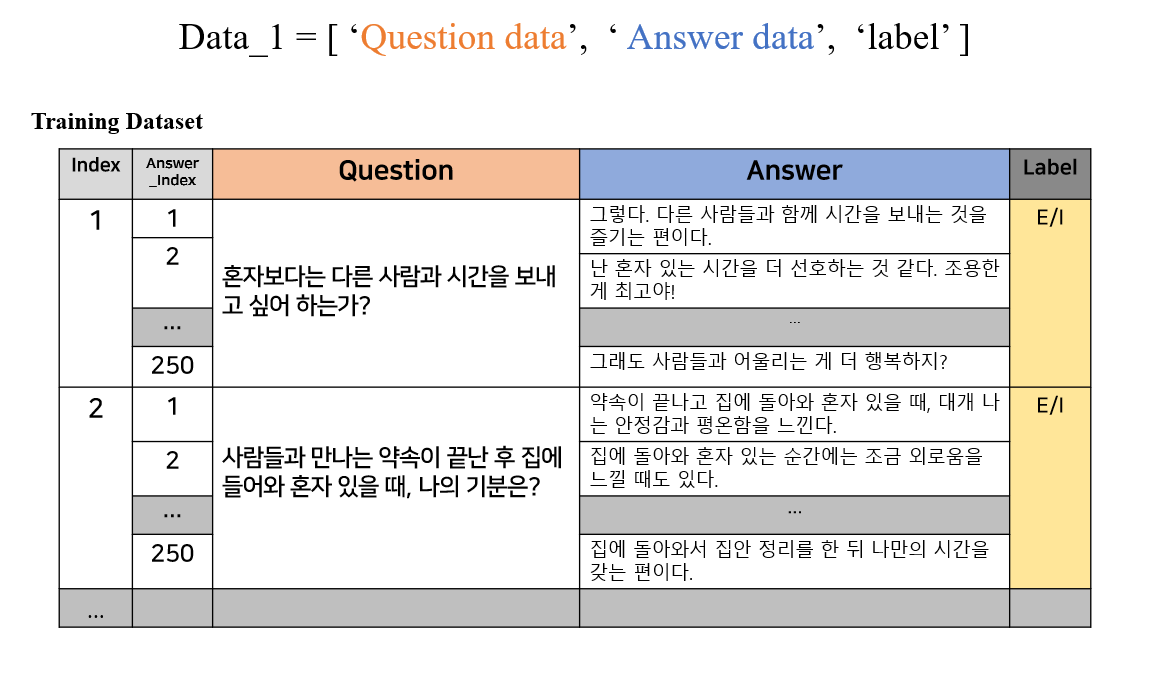 필자는
필자는 labeling(MBTI 유형분류)가 반드시 필요하므로
Question Answer Label에 대한 데이터들을 한 데 모아 하나의 데이터로 만들어 줄 것이다.
아까 언급했다 싶이 Question 데이터는 직접 만들 것이고,
Answer에 해당하는 데이터 구성이 문제이다.
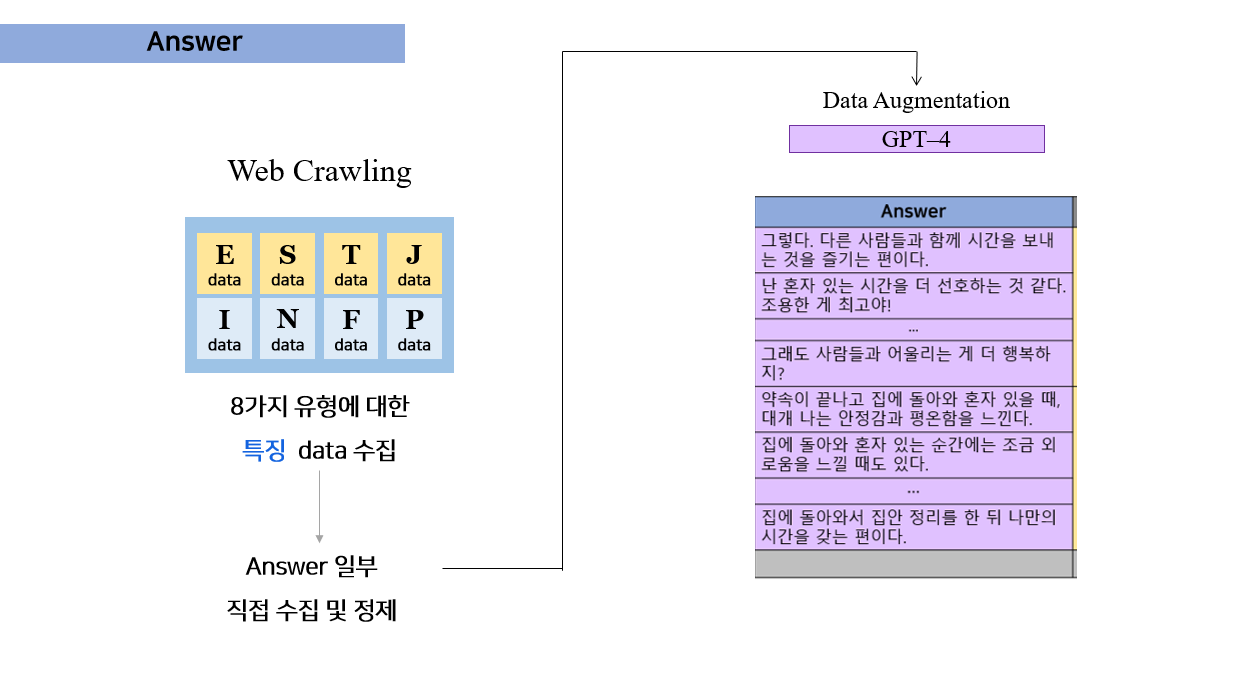 Answer 데이터 같은 경우에는
Answer 데이터 같은 경우에는
Web Crawling을 통해서 각 유형에 대한 특징들을 뽑아낼 것이고,
Answer을 몇 개 작성할 것이다.
그 뒤, GPT-4 API를 사용해 볼 생각이다!!!!!!
질문과 내가 직접 작성한 답변을 바탕으로 기존 GPT API넣어서 직접 답변을 작성하도록 할것이다.
이렇게 데이터를 증식시키고 증식시킨 답변+내가 만든 답변을 바탕으로 위의 트랜스포머 모델의 Input으로 넣어 학습시킬 계획이다!!
💜 마치며
교수님께 엄청난 칭찬을 받았다. (23.08.09일자)
주제도 굉장히 참신하고 (감사합니다 누구씌..^^),
전체적인 기획? 구조?도 굉장히 마음에 든다고 하셨다. 그냥 피드백은 없고 무한 칭찬만 하셨다.
요즘 세미나 열심히 하고 있어서 칭찬만 받긴 했지만, 이렇게 엄청난 칭찬을 받을줄은 몰랐다..
오히려 MBTI란 주제가 그렇게 정형화된 검사는 아니기에 빠꾸 먹을줄 알았다ㅠㅠ
일주일내내 이것만 한 보람이 있다. (세미나 전날 새벽 세시에 집갔다..)
교수님께서는 플젝으로 논문 작성을 넘어서 사업성까지 논하셨다. (창업 얘기도 하셨다ㅋㅋㅋ)
근데 내가 봐도 잘 한 것 같긴하다.
PPT도 나중에 종설때 쓸거라 이를 갈면서 만들었고
학원 알바하면서 틈만 생기면 구조도 그리고, 답변 분석방법을 생각했다.
뿌듯하다.
이제 시작이다!! 2개월을 목표로 달려서 꼭 내 성에 차는 멋진 졸업 작품을 선보이겠다!
