✨ GloVe 등장
Word2Vec 단점 보완목적
Word2Vec과 GloVe 중 무엇이 뛰어난지는 말할 수 없음
👉 GloVe는 단점을 개선하기 위해 각 임베딩의 방식을 부분적으로 차용
✨✨ 최종목표
: Word2Vec과 동일하게 단어의 의미를 임베딩 벡터로 표현하여 유사도 잘 파악
+ 말뭉치 전체의 통계 정보를 잘 반영하자
ex) context에 얼음이란 단어가 나왔을때!
고체라는 단어 등장 확률은 높음!기체라는 단어 등장 확률은 낮음........
💎 GloVe의 구성
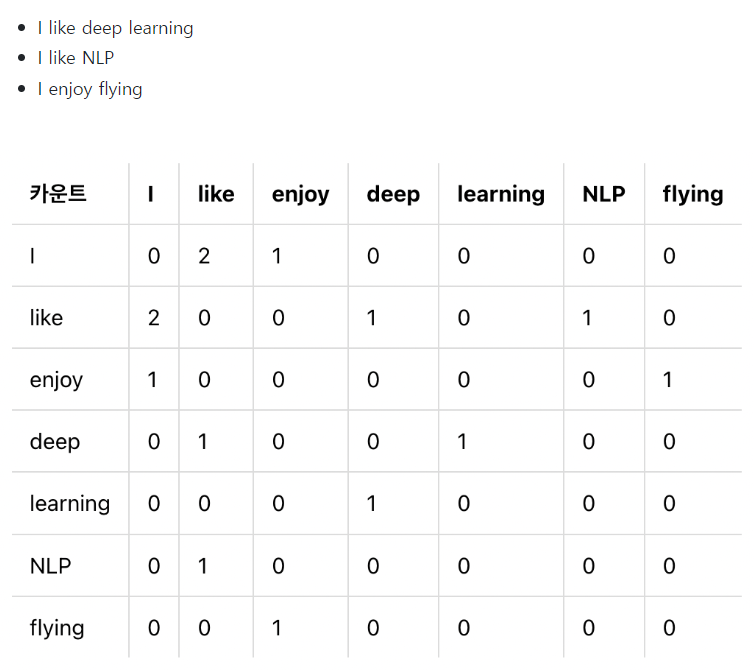
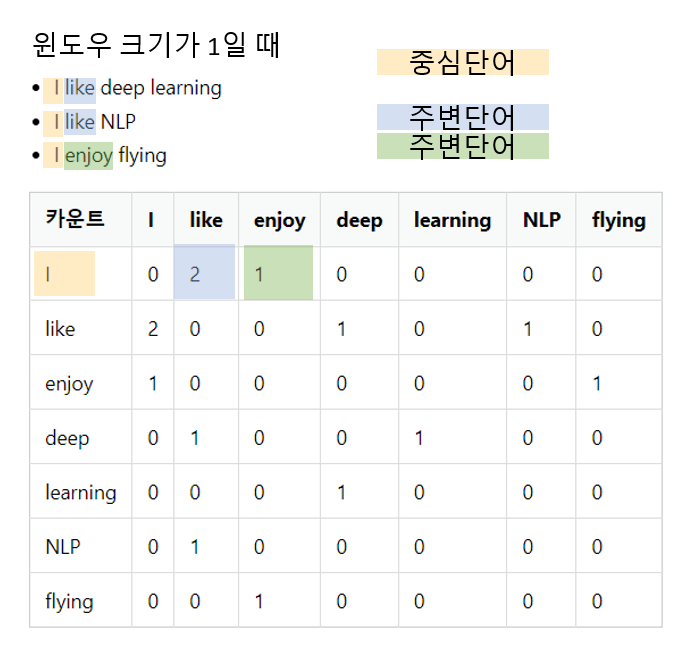
1) 동시 등장(co-occurrence)정보를 기반으로 단어 간의 관계를 학습
동시 등장 행렬
동시 등장 확률
동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고,
특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률
이러한 동시 등장 정보를 수집하여 행렬 형태로 저장
-> 문맥에서 함께 등장하는 단어 쌍의 빈도를 잘 나타냄
-> 행렬 분해 기법시 사용
2) 행렬 분해 기법 사용
행렬 분해
: 행렬을 여러 개의 부분 행렬로 분해하는 기법
(더 작은 크기의 부분 행렬로 표현하고, 이를 통해 행렬의 특징과 구조 파악)
추천 시스템, 정보 검색, 임베딩 등에서 활용
즉, 단어의 동시 등장 행렬을 저차원으로 분해하는 것
-> 잠재 의미 공간 얻음
😶 <행렬분해> 내가 파악한 내용.... 간단하게 정리~~~
행렬 분해란?
행렬곱을 거꾸로 한 것.
행렬1 x 행렬2 = 행렬B면
행렬B를 다시 행렬 행렬1 x 행렬2로 분해하는 것!
행렬 분해의 목적
1) 차원의 수를 줄여 계산 효율성을 키움
2) 행간에 숨어 있는 잠재 의미를 파악
행렬 분해의 목적
3) 잠재 의미 공간
-> 단어의 임베딩 벡터 추정
GloVe VS Word2Vec
GloVe는 전역적인 정보를 기반으로 모델링
- 전체 말뭉치에 대한 통계를 통해, 단어들의 등장 빈도 측정
Word2Vec은 지역적인 정보를 기반으로 모델링
- 전체 말뭉치에 대해 학습하되, 중심단어 주변의 단어들에 초점을 계속해서 맞춘다는 점에서 지역적인 것임.

NLP 공부중