지금까지 모든 학습 데이터들은 time과 연관이 없었음
만약, H E L L O 자동완성 프로그램을 만든다면
H->E
E->L
L->L
L->O
가 나와야하는데
L이 입력됐을때 출력값이 L 혹은 O가 나오도록 해야한다.
즉, 똑같은 Input에 다른 output이 존재하는 것이다.
앞으로 L이 2번 연속 나왔을때는 O라는 결과값을 줘라~
이것이 시계열 데이터(과거의 값이 현재의 값에 영향을 미친다.)
순환 신경망(RNN)
: 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델
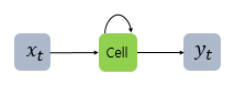
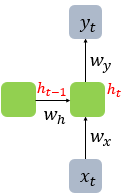
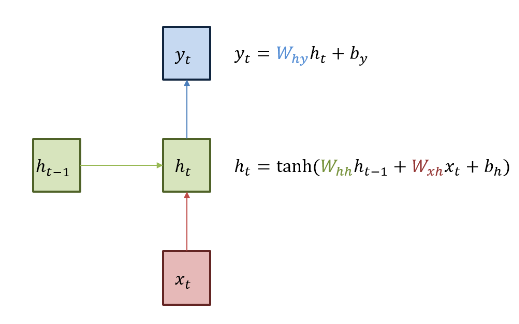
x : 입력층의 입력벡터
y : 출력층의 출력벡터
cell(셀) : 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할(= 메모리 셀, RNN 셀)
t : 현시점
은닉층 : 결과값 출력층으로 보내기 or 다시 은닉층 노드의 다음 계산의 입력으로 보냄
은닉상태 : 메모리 셀이 다음 시점인 t+1의 자신에게 보내는 값
(t시점 메모리 셀은 t-1시점의 메모리 셀이 보낸 은닉 상태값을 사용한다)
👳♂️ RNN의 다양한 형태
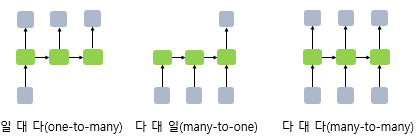
- RNN은 입력과 출력의 길이를 다르게 설계할 수 있다.
- RNN 셀의 보편적인 단위는 '단어 벡터'이다.
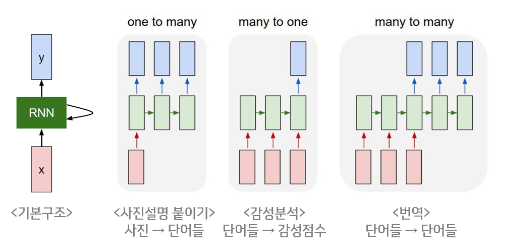
일 대 다(one-to-many)
- 하나의 이미지 입력에 대해서 사진의 제목을 출력하는 이미지 캡셔닝(Image Captioning)
다 대 일(many-to-one)
- 입력 문서가 긍정적인지 부정적인지를 판별하는 감성 분류(sentiment classification),
- 메일이 정상 메일인지 스팸 메일인지 판별하는 스팸 메일 분류(spam detection)
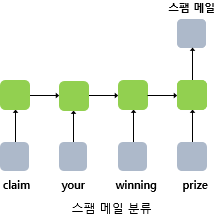
다 대 다(many-to-many)
- 번역된 문장을 출력하는 번역기
- 태깅 작업
🎅 RNN 수식

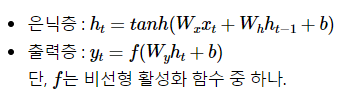

🚌 RNN의 기본구조
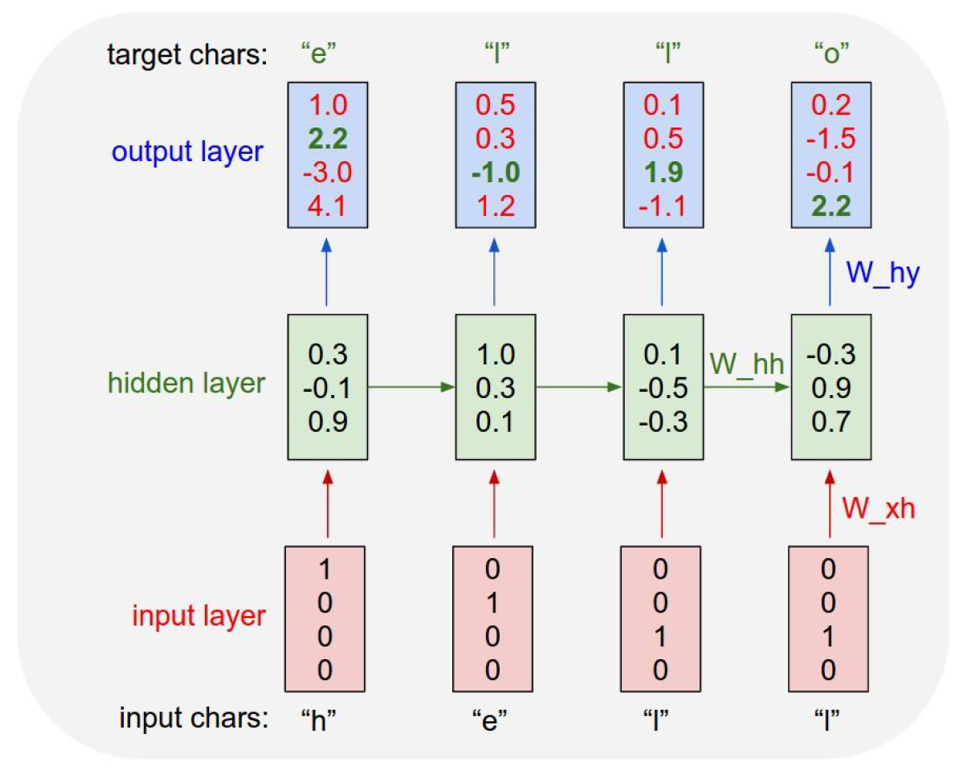
(출처:https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/)
- 첫번째 h_0은 존재하지 않기 때문에 랜덤 값을 집어넣는다.
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
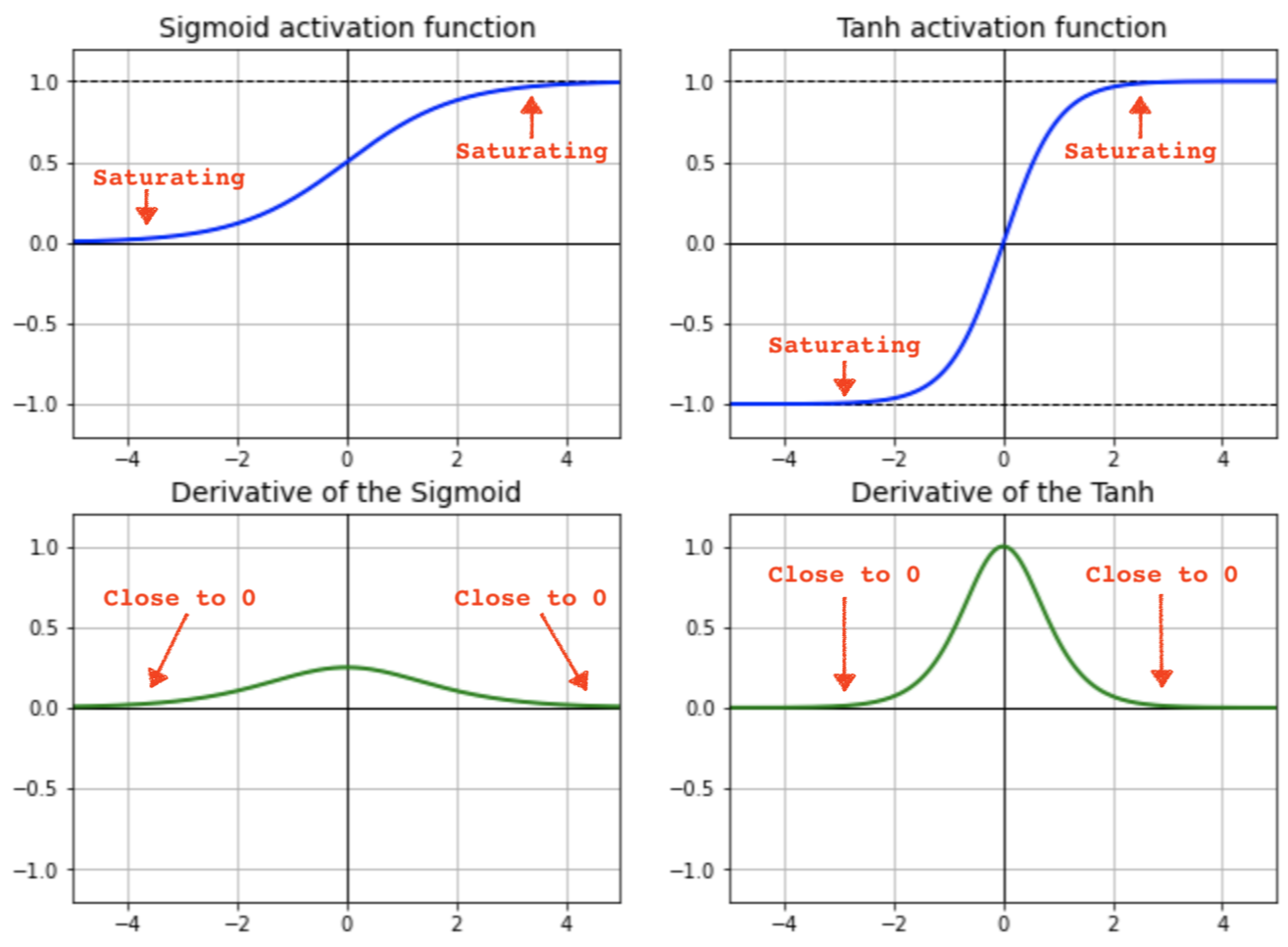
⛔ 여기서 왜 tanh을 사용하는가?
sigmoid는 Deep 해질수록 Vanishing Gradient 발생
ReLU는 RNN 특성상 계속 순환하는 구조이기 때문에 값이 1보다 크게되면 ReLU 특성상 값이 발산할 수도 있어서 적합하지 않음
즉, ReLU는 양수일때 기울기가 항상 일정한 값을 가지므로 RNN의 학습 특성과는 맞지 않기 때문에(계속 순환해서 값을 갱신해나가야하는데 양수일때 1이 되어버리면 순환 학습이 의미가 없음) tanh을 사용하는듯
sigmoid VS tanh
ReLU
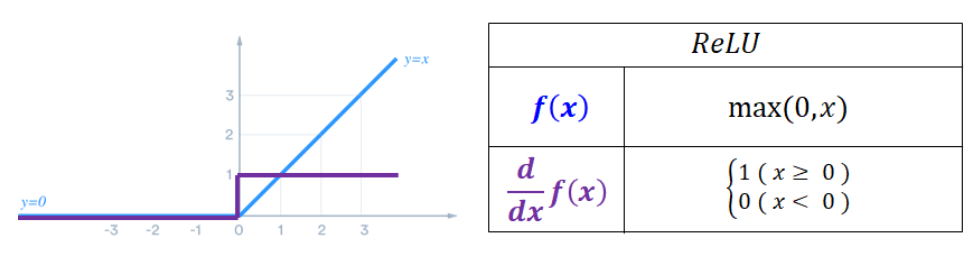
RNN에서는 비선형 함수를 사용하는 이유
word2vec에서는 선형함수를 사용하였다.
하지만 RNN에서 비선형함수를 사용하는데
이 모델이 시퀀스 데이터의 복잡한 관계를 처리하고 장기적인 의존성을 학습할 수 있도록 하기 위해서 비선형 함수를 사용한다.
⛔ 계산방법이 아직은 정확하게 이해가 안감
⛔ 그리고 밑 코딩부분 아직 안함~~
