seq2seq 란?
: 2개의 RNN을 연결해서 사용하는 인코더-디코더 구조
입력문장과 출력문장의 길이가 다를 경우 사용한다. (ex) 기계번역 )
예 1) 영어문장을 한국어문장으로 번역한다고 했을 때,
입력문장인 영어문장과 번역된 결과인 한국어 문장의 길이가 똑같을 필요는 없다.
예 2) 텍스트 요약의 경우
출력 문장이 요약된 문장이므로 입력 문장보다는 길이가 짧을 것이다.
seq2seq 의 구조
학습과정시 Encoder-Decoder 동작과정
▶ Encoder
- 전체 문장이 단어(토큰) 단위로 끊겨서 source word로 들어오게 된다.
- 매 time step마다 하나의 토큰씩 학습을 하고, hidden state를 업데이트 해준다.
- 모든 토큰에 대하여 위의 작업을 마치게 되었을 때 업데이트 된 hidden state가
context vector가 된다.
▶ Decoder
- 사전에 target sentence에 대하여 문장의 맨 앞에는 를, 문장의 맨 뒤에는 처리를 해준다.
1) <테스트 과정(실사용)> 에서의 seq2seq
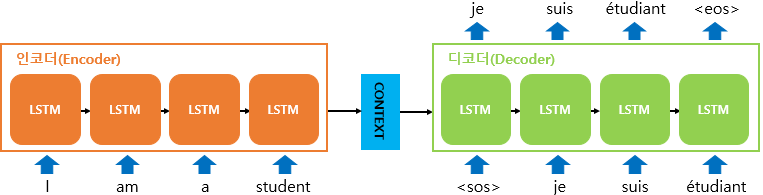
- 인코더는 실제로 바닐라 RNN이 아니라 LSTM 셀 또는 GRU 셀들로 구성됨
< 테스트 과정 >
[입력]
1) 입력 문장은 '단어 토큰화'를 통해 단어 단위로 쪼개짐
[인코더]
2) 토큰화된 단어가 순차적으로 입력
[컨텍스트 벡터]
3) 모든 단어가 입력되었다면, 인코더 RNN셀의 마지막 시점의 은닉 상태를 디코더 RNN셀로 넘겨줌
-> 컨텍스트 벡터는 디코더 RNN셀의 첫번째 은닉 상태에 사용됨
[디코더]
4) [디코더 1]의 초기 입력으로 문장의 시작을 의미하는 심볼 < SOS >가 들어감
5) < sos >가 [디코더 1]에 들어오면, [디코더 1] 에서는 다음에 등장할 확률이 높은 단어(je)를 예측
-> [디코더 2]의 입력으로 보냄
6) [디코더 2]는 je로부터 다음에 올 단어인 suis를 예측
-> 다시 [디코더 3]의 입력으로 suis 보냄
7) 반복 (다음에 올 단어 예측 -> 예측단어를 다음시점의 RNN셀의 입력으로 넣음)
8) 문장의 끝을 의미하는 심볼인 < eos >가 다음 단어로 예측되면 -> 종료
컨텍스트 벡터(context vector)
: 인코더에서 모든 단어를 입력받은 뒤,
인코더 RNN 셀의 마지막 시점에서의 은닉상태
: 인코더에서 모든 단어를 순차적으로 입력 받은 뒤,
마지막에 이 모든 단어 정보들을 압축해서 만드는 하나의 벡터.
압축이 완료되면 인코더는 이 컨텍스트 벡터를 디코더에 전송하고,
디코더는 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력함.
- 컨텍스트 벡터는 seq2seq 모델에서 보통 수백 이상의 차원을 갖고 있음.
2) <훈련 과정> 에서의 seq2seq
🧡 [인코더]
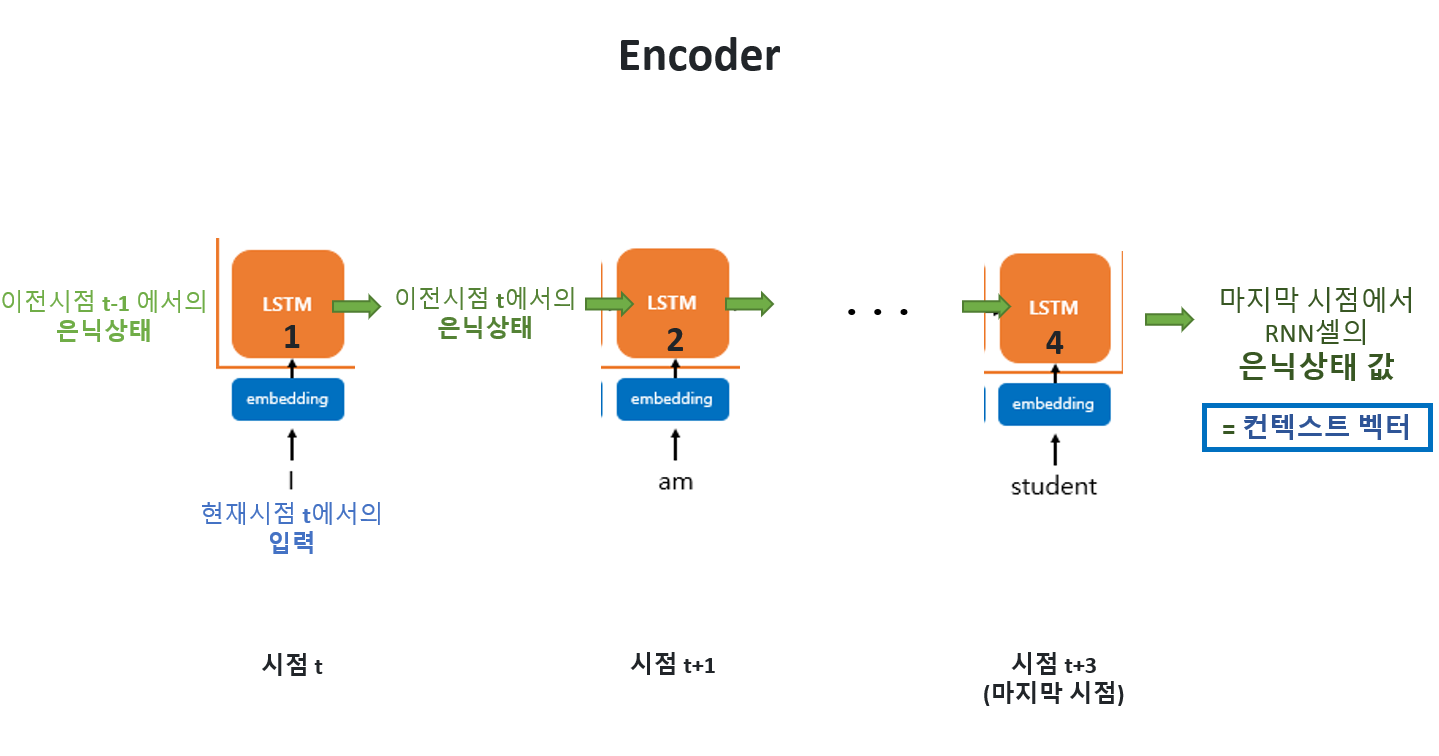
-
매시점 RNN 셀에 두 개의 입력이 들어감.
입력 1 - 현 시점 t 에서의 입력값
입력 2 - 이전 시점 t-1 에서의 은닉상태 값
-
마지막 RNN 셀의 은닉상태 값
= 컨텍스트 벡터
= 이는 과거 시점의 동일한 RNN 셀에서의 모든 은닉 상태의 값들의 영향을 누적해서 받아온 값인 셈
= 입력문장의 모든 단어 토큰들의 정보를 요약해서 담고 있다고 할 수 있다.
💚 [디코더]
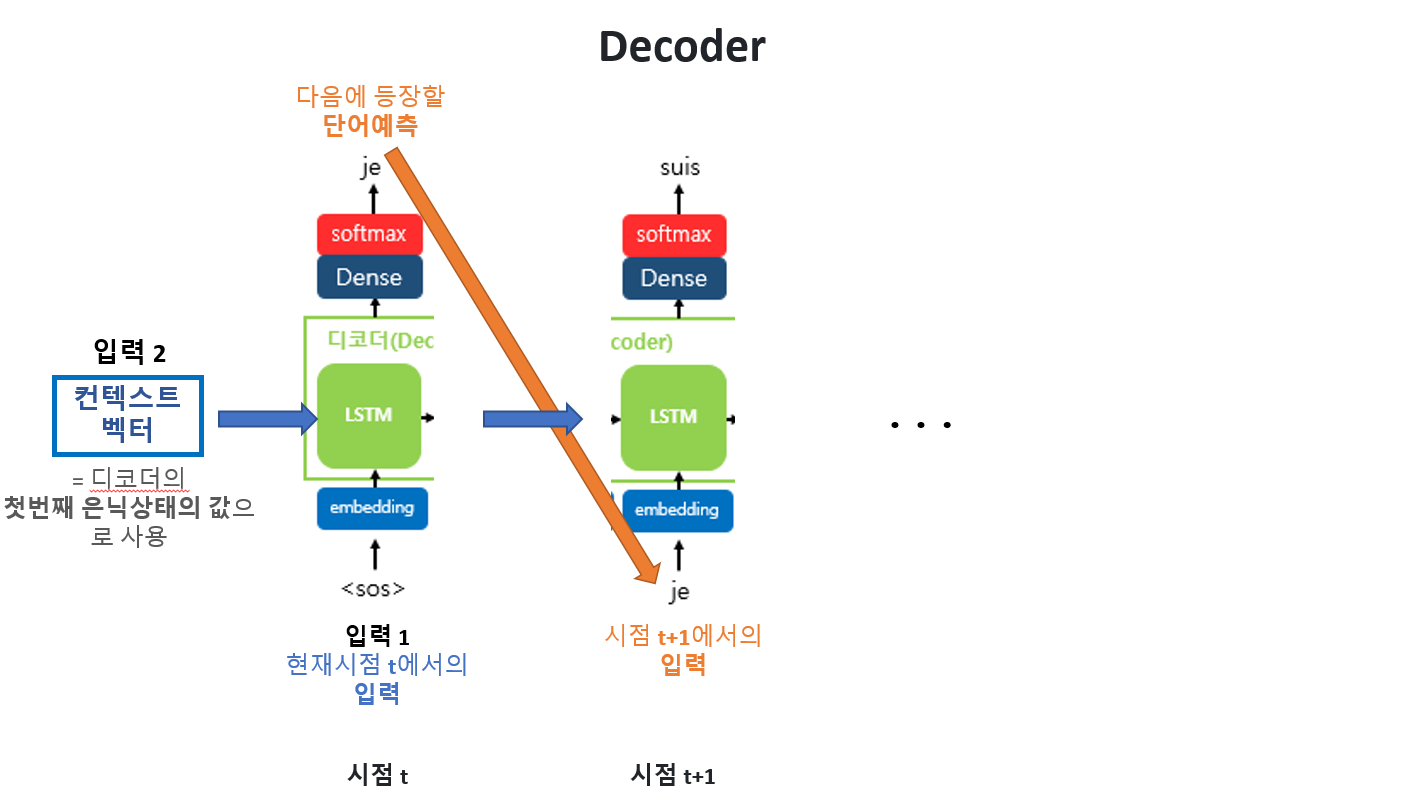
< 첫번째 시점 >
1) 입력1의 입력(단어) -> 임베딩 벡터 값으로 변환
2) RNN 셀에 두 개의 입력
입력 1 (단어 벡터값) - 현 시점 t 에서의 입력값 <SOS>
입력 2 (은닉) - 컨텍스트 벡터 ( : 디코더의 첫번째 은닉상태의 값으로 사용)
3) 입력들이 RNN 셀을 거치면 ~
... 3-1) 은닉상태 -> 다음 시점에서의 은닉상태로 사용 (정보 전달 및 유지 역할)
... 3-2) 출력 벡터(여러 개)가 나옴
4) 출력 벡터들은 softmax 함수를 통해
각 요소를 확률로 정규화하여 총합이 1이 되도록 만들어준다.
-> 토큰들에 대한 확률 분포 얻기!
(출력 시퀀스의 각 단어별 확률값을 반환)
5) 이 분포에서 가장 확률이 높은 단어를 선택하며 출력단어 결정
(=해당 시점의 출력으로 사용)
< 두번째 시점 부터 ~ >
1) 입력1의 입력(단어) -> 임베딩 벡터 값으로 변환
2) RNN 셀에 두 개의 입력
입력 1 - 현 시점에서의 입력값 (= 이전시점에서 예측한 단어)
입력 2 - 이전 시점에서의 은닉상태 값
3) 앞 과정 반복 ~~
🍔
<sos>와<eos>
인코더에서는 사용되지 않음!
디코더가 문장 생성을 시작하고 끝내는 데에 중요한 역할을 하므로 두 특수토큰이 필요한 거임!
😎 교사 강요(teacher forcing)
: RNN의 모든 시점에 대해서 이전 시점의 예측값 대신 실제값을 입력으로 주는 방법
- 위의 seq2seq 설명에서는
이전시점의 디코더 셀의 output을 현재시점의 디코더 셀의 input으로 넣어준다고 했었음
하지만 이전시점의 디코더 셀의 예측(output)이 잘못될경우 💢문제발생!💢
이를 현재시점의 디코더 셀의 input으로 넣게된다면
현재시점의 예측도 잘못될 수 있고, 연쇄작용으로 디코더 전체의 예측을 어렵게 한다.
-> 훈련시간이 느려짐
따라서, 실제값을 입력으로 주며 위의 문제점을 해결하고자 함!
💌 대략적인 동작 과정
- 번역하고자 하는 입력 문장이 인코더에 들어가서 은닉 상태와 셀 상태를 얻습니다.
- 상태와
<SOS>에 해당하는\t를 디코더로 보냅니다. - 디코더가
<EOS>에 해당하는\n이 나올 때까지 다음 문자를 예측하는 행동을 반복합니다.
👒 BLEU Score (Bilingual Evaluation Understudy Score)
: 기계 번역의 성능이 얼마나 뛰어난가를 측정하기 위해 사용되는 방법
(언어모델의 성능 측정을 위한 방법 -> PPL)
BLEU
: 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정 방법
- N-gram 기반
- 성능 평가를 위해 직관적인 방법을 먼저 제시하고, 문제점을 보완해나가는 방식으로 설명함.
1) 단어 개수 카운트로 측정하기(Unigram Precision)

2개의 댓글
디코더의 hidden state 갱신
- 다음 단어 예측을 위해 존재
- 이 hidden state는 손실함수 계산에 큰 역할을 한다.
모델의 가중치 갱신
- 모델이 입력 데이터로부터 올바른 출력 데이터를 생성할 수 있도록 학습.
- 입력 데이터로부터 출력 데이터를 생성하기 위해 매핑 함수의 파라미터를 결정.
매핑? -> 모델이 입력과 출력 사이의 관계를 학습하는 것. 이를 수학적으로 표현한 것이 매핑함수
매핑함수 : 입력 데이터를 받아서 예측된 출력 데이터를 주는 함수
가중치 : 매핑 함수의 특성을 결정하는 파라미터
이 가중치는 모델이 입력데이터를 어떻게 해석하고, 그 결과를 바탕으로 어떤 출력 데이터를 생성할지 결정
따라서, 모델학습의 목표는 가중치를 적절히 조정하는 것
손실 함수 계산의 목적
- 성능 측정 : 예측과 실제 타겟 시퀀스의 차이 측정(손실) -> 모델 성능을 평가하는 기준
- 가중치 조정 : 손실을 최소화하기 위해, 모델의 가중치는 역전파 알고리즘을 통해 조정됨
손실이 낮아지는 방향으로 가중치를 업데이트 함
context vector
Decoder의 hidden state
이후에는 이전타임 스텝의 hidden state와 현재 time step에서 입력된 단어에 기반하여
hidden state가 게속해서 업데이트 됨
즉, 디코더에서의 hidden state는 context vector의 벡터를 받아오는 것이 맞음!!!!!