Tokenizing을 할 때
어떤 문장이 주어졌을 때, 공백기준으로 + 구두점 제거 등등에 대해서 여러가지 전처리를 해줘야 명확하게 토큰간의 분리를 수행할 수 있다.
하지만 예외적으로 Don't는 Do + ' + not으로 분리를 해줘야한다.
이러한 예외적인 부분에서 어려움을 해결하기 위핸 다른 tokenizer 방법이 필요하다.
(character 단위로 분해한다면 편하겠지만, token에 의미있는 정보를 담을 수는 없다.
(today -> t만으로 파악 어려움) )
이에 Subword Tokenization 알고리즘을 사용하면
1_ 적당한 크기(vocabulary size)로 토큰화된 단어를 사용할 수 있고,
2_ 처음보는 단어도 모델이 처리할 수 있게된다. (OOV 문제)
( 규칙 )
- 자주 쓰이는 문자조합은 더 작은 subword로 분리하면 안된다.
ly,ed등등- 하지만 희귀한 문자조합은 의미있는 더 작은 subword로 분리되어야 한다.
annoyingly = annoying + ly
(출처처처처)
UNK(Unknown Token)
: 단어 집합에 없는, 기계가 모르는 단어(토큰)
OOV(Out-Of-Vocabulary) 문제
: 모르는 단어의 등장으로 인해 문제를 푸는 것이 까다로워지는 상황
서브워드 분리(subword segmentation) 작업 => 서브워드 토크나이저
: 하나의 단어를 더 작은 단위의, 의미있는 여러 서브워드들의 조합으로 분리하는 전처리 작업
ex) birthplace = birh + place
-> 희귀단어, 신조어 문제 완화 가능
🍗 서브워드 분리 알고리즘
1) BPE(Byte Pair Encoding) 알고리즘
: (데이터 압축 알고리즘)
연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합하는 알고리즘 방식
>> 기본적인 BPE
ex) aaab ... 만일 aa=X, ab=Y라면, 앞의 예시는 XY 로 치환 가능하다.
>> 자연어 처리에서의 BPE
예를들어 단어가 다음과 같이 존재한다고 가정한다.
# vocabulary
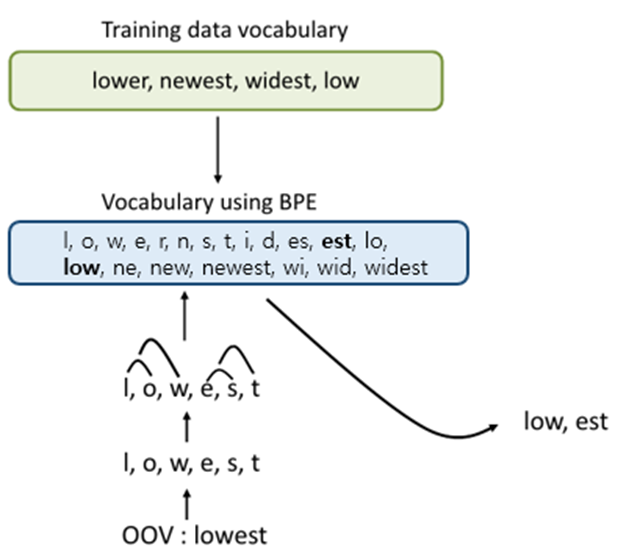
low, lower, newest, widest위의 경우 테스트 과정에서 lowest란 단어가 등장하면, 기계는 이 단어를 학습한적이 없으므로 해당 단어에 대해서 제대로 대응하지 못하는 OOV 문제가 발생한다.
여기에 BPE 알고리즘을 사용하여 lowest를 찾고자 한다면..
우선, 단어의 초기 구성을 글자단위(character)로 분리한다.
# dictionary
l o w : 5, l o w e r : 2, n e w e s t : 6, w i d e s t : 3# vocabulary
l, o, w, e, r, n, s, t, i, dBPE 알고리즘의 동작을 몇회 반복(iteration)할 것인지 사용자가 정한다.
그리고 가장 빈도수가 높은 유니그램의 쌍을 iteration만큼 반복하여 하나의 유니그램으로 통합한다.
- 1회차
위의 딕셔너리에 따르면 빈도수가 현재 가장 높은 유니그램의 쌍은 (e,s)이다.
빈도수가 9로 가장 높은 (e, s)의 쌍을es로 통합한다.
(new es t : 6, wid es t : 3 이므로 (e, s)는 총 9번 나온 것)
# dictionary update!
l o w : 5,
l o w e r : 2,
n e w es t : 6,
w i d es t : 3
# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es- 2회차
(es, t)가 빈도수가 9번으로 다음으로 높은 쌍이다.
이를est로 통합한다.
(new est : 6, wid est : 3)
# dictionary update!
l o w : 5,
l o w e r : 2,
n e w est : 6,
w i d est : 3
# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est- 3회차
(l, o)가 빈도수가 7번으로 그 다음으로 높은 쌍이다.
이를lo로 통합한다.
(new est : 6, wid est : 3)
# dictionary update!
l o w : 5,
l o w e r : 2,
n e w est : 6,
w i d est : 3
# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est- 같은 방식으로 10회 반복하면 딕셔너리와 단어집합은 아래와 같다.
# dictionary update!
low : 5,
low e r : 2,
newest : 6,
widest : 3
# vocabulary update!
l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest- BPE 알고리즘을 사용한 위의 단어 집합에서
lowest는 더이상 OOV가 아니다.
BPE 알고리즘을 거친 후lowest를 기계에 넣는다면,
기계는 위의 단어 집합을 참고로 하여low와est를 찾아낸다.
즉,lowest를 기계는low와est두 단어로 인코딩 하는 것이다.
그리고lowest는 OOV에서 벗어나게 된다.
2) WordPiece Tokenizer
(BPE 변형 알고리즘)
(BERT 에 사용된 알고리즘)
: likelihood를 기반으로 BPE를 수행한 알고리즘
알고리즘 설명
- 유니코드를 character 수준으로 초기화 (쪼갠 단어를 저장할 word unit 저장소 만들기)
- 위 저장소에서 language model(단어 sequence에 확률을 부여하는 것)을 만든다.
- 현재 저장소에서 2개의 유닛을 뽑아서 합치고 새로운 유닛을 만든다.
이후, 위의 저장소에 추가로 저장할 때, 합쳐서 새롭게 만든 것들 중에 확률을 더 많이 증가시키는 새 유닛을 선택한다. - 정해놓은 vocabulary size를 넘거나, 확률이 특정값(threshold) 아래로 떨어지기 전까지 2번으로 돌아가 계속해서 반복한다.
예를 들어
"u" 다음에 "g"가 붙는다면,
"ug"보다 "u"와 "g"를 분할하였을때 Language model의 확률이 더 증가한다면
이 둘을 분할해서 vocabulary에 저장한다는 뜻이다.
3) Unigram Language Model Tokenizer
: base vocabulary(공백기준 분리 단어 등)를 아주 크게 잡고 점차 줄여나가는 방식
과정
각각의 서브워드들에 대해서 손실(loss; 서브워드가 단어 집합에서 제거되었을 경우 코퍼스의 확률이 감소하는 정도)을 계산
-> 계산 후 서브워드들을 손실의 정도로 정렬하여 최악의 영향을 주는 10~20%의 토큰을 제거한다.
-> 반복
(BPE 알고리즘 기반)
- 단독으로 쓰이지 않고, Sentencepiece와 함께 쓰여 transformer에 적용된다.
4) Google의 센텐스피스(SentencePiece)
BPE 알고리즘 기반의 모델들은 공백을 기준으로 단어를 분리한다.
하지만 모든 단어가 단어를 분리하기 위해 공백을 사용하지 않는다.(중국어,일본어)
각 언어마다 그 언어에 적절한 pre-tokenizer를 사용하면 좋지만,
가장 일반적인 방법으로
SentencePiece는 input을 그대로 사용한다.
그래서 사용할 character들의 집합에 공백이 포함되어있다.
모든 토큰을 로 이어붙이고
부분을 공백으로 치환해준다.
5) 서브워드 텍스트인코더(SubwordTextEncoder)
6) 허깅페이스 토크나이저(Huggingface Tokenizer)
