태깅 작업
: 각 단어가 어떤 유형에 속해있는지를 알아내는 작업
🎇 태깅 작업의 구성
-
RNN의 Many-to-Many 구조 이용
(RNN-스스로 반복하면서 이전 단계에서 얻은 정보가 지속되도록 하는 것) -
양방향 LSTM 사용(앞,뒤 시점의 입력을 모두 참고)
양방향 LSTM (Bi-LSTM)
정방향으로 학습하되 -> 마지막 노드에서 역방향으로 실행되는 다른 LSTM 추가 (hidden layer 추가)
결론적으로 각 시점의hidden state(h_t)가 이전 시점과 미래 시점의 정보를 모두 갖는 효과가 있어서 모델을 전체 시계열 데이터로부터 학습하는 경우 유용함
🚚 태깅 작업의 종류
- 개체명 인식(Named Entity Recognition)
각 단어의 유형이 사람, 장소, 단체 등 어떤 유형인지 - 품사 태깅(Part-of_Speech Tagging)
각 단어의 품사가 명사, 동사, 형용사인지
🌌 태깅 작업의 구조 (간략하게)
1) 훈련 데이터
- x와 y데이터 쌍은 병렬구조
쌍 1
x_train(x 훈련데이터)
y_train(y 훈련데이터)
쌍 2
x_test(x 테스트데이터)
y_test(y 테스트데이터)
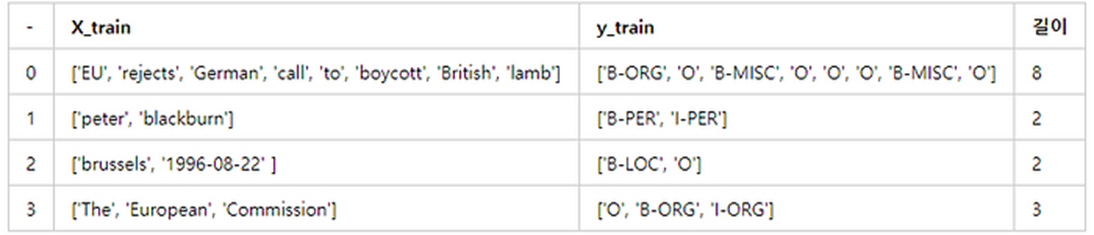
병렬 관계를 가지는 각 데이터는 정수로 인코딩 -> 모든 데이터의 길이를 동일하게 맞춰줌 (패딩)
2) 시퀀스 레이블링
: 입력 시퀀스 x에 대하여 레이블 시퀀스 y를 부여
3) 양방향 LSTM 사용
model.add(Bidirectional(LSTM(hidden_size, return_sequences=True)))
4) RNN의 Many-to-Many
RNN Many-to-Many에서
return_sequence=True로 설정하여 출력층에 모든 은닉 상태값을 보낸다.
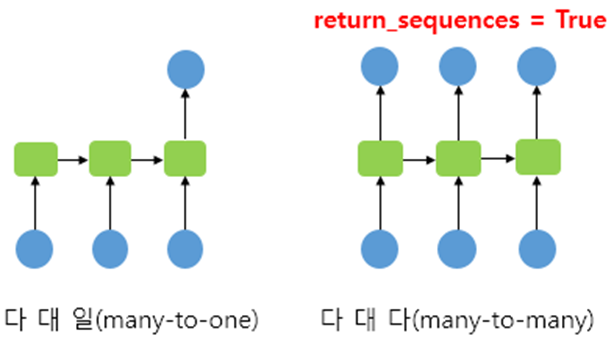
<< 최종형태 >>
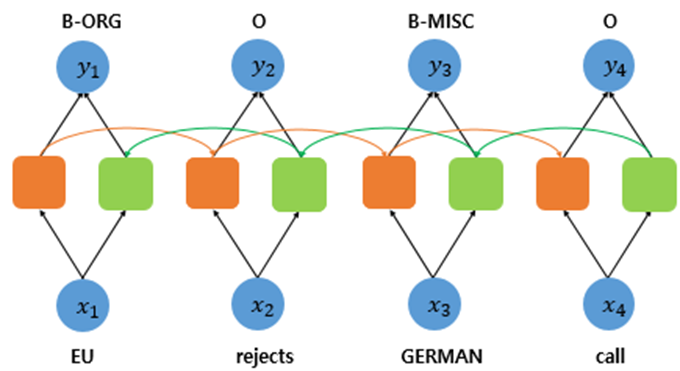
주황 - 순방향
연두 - 역방향
(상세 ver)
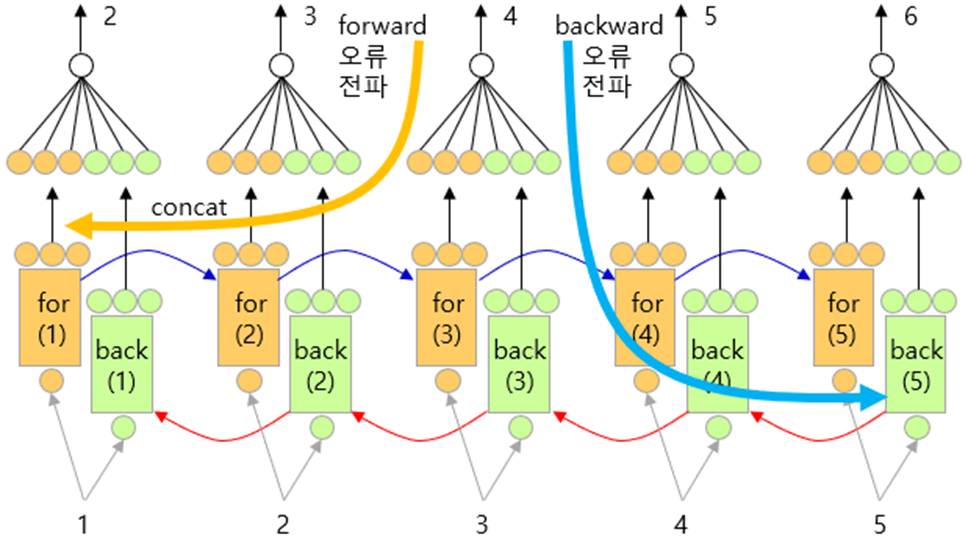
-
각 step의 출력(순+역)은 합쳐진다(concatenate).
-
1 step 의 경우
순방향의 첫 부분for(1)+ 역방향의 마지막 부분back(5)
(for(1)정보량 적음 -> 초기상태이기에!)
(back(5)정보량 많음 -> 1~5까지의 정보가 반영된 상태이기에!) -
5 step 의 경우
순방향의 마지막 부분for(5)+ 역방향의 첫 부분back(1)
(for(5)정보량 많음 -> 1~5까지의 정보가 반영된 상태이기에!)
(back(1)정보량 적음 -> 초기상태이기에!)
-
따라서 각 스텝에서 합쳐진 값들에는 반영된 정보가 균등하게 분산되어 있다.
(중간 스텝에서는 forward와 backward가 균등하게 분배돼있음)
xInput = Input(batch_shape=(None, 5, 1))
xBiLstm = Bidirectional(LSTM(3, return_sequences=True), merge_mode = 'concat')(xInput)
xOutput = TimeDistributed(Dense(1))(xBiLstm)??? 그래서 태깅이 하고자 하는 것!
??? 양방향과 다대다 기능을 써서 태깅작업을 어케하는가?
??? 태깅작업 예시 코드 살피기

https://omicro03.medium.com/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-nlp-21%EC%9D%BC%EC%B0%A8-%EC%96%91%EB%B0%A9%ED%96%A5-lstm%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EA%B0%9C%EC%B2%B4%EB%AA%85-%EC%9D%B8%EC%8B%9D-68f21ade304d
참고하기