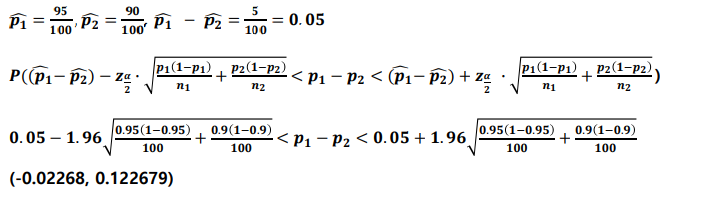모집단과 표본
모집단과 표본
- 모집단(Population), 표본(Sample)
-> 가설검증, 회귀분석 등에 이해하는데 중요하다
- 표본추출(Sampling) : 모집단으로부터 표본을 추출하는 것을 Sampling이라고 하며, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론(=추정)하고자 함
모집단에서 표본을 추출하는 방법
-
복원추출(Sampling with replacement) : 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출될 수 있음
-
비복원추출(Sampling without replacement) : 모집단에서 데이터를 추출할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법
-
Random Sampling : 모집단에서 데이터를 추출할 때 주의할 점은 편향되지 않아야 함, 각 개체가 모두 동일한 확률로 추출하는 방법
불균형 데이터(Imbalanced Data)의 문제
-
데이터가 불균형 데이터일 경우 문제가 생김
-
우리가 예측모형을 만드는 목적은 관심이 있는 대상이 발생할 확률을 예측하는 경우가 대부분임, 그런데 예측 대상이 전체 대비 아주 낮다면? 모형의 성능이 괜찮을까? (ex: 신용 평가 모형 개발, 제조 불량 예측 등)
1) Sampling 기법을 통하여 해결
2) 모델을 통한 성능 개선(ex: Cost-seneitive learning)
-
Sampling 기법: 관심의 대상의 아주 비율이 낮은 경우
-
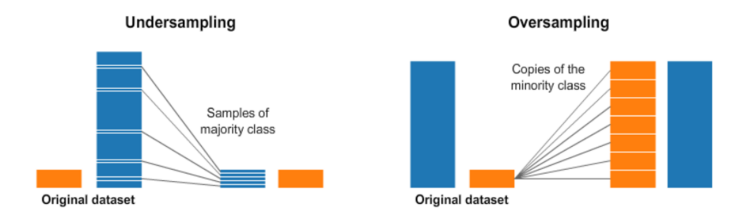
Over Sampling: 타겟 데이터 적은 class의 수를 많은 class의 비율만큼 증가 시킴(일정 비율로 복원추출하는 개념), 과도적합의 문제 발생할 수 있음
-
Under Sampling: 타겟 데이터의 많은 class의 수를 적은 class의 비율만큼 감소시킴, 임의로 뽑은 데이터가 viased(편향)될 수 있고, 모형의 성능이 떨어질 수 있음
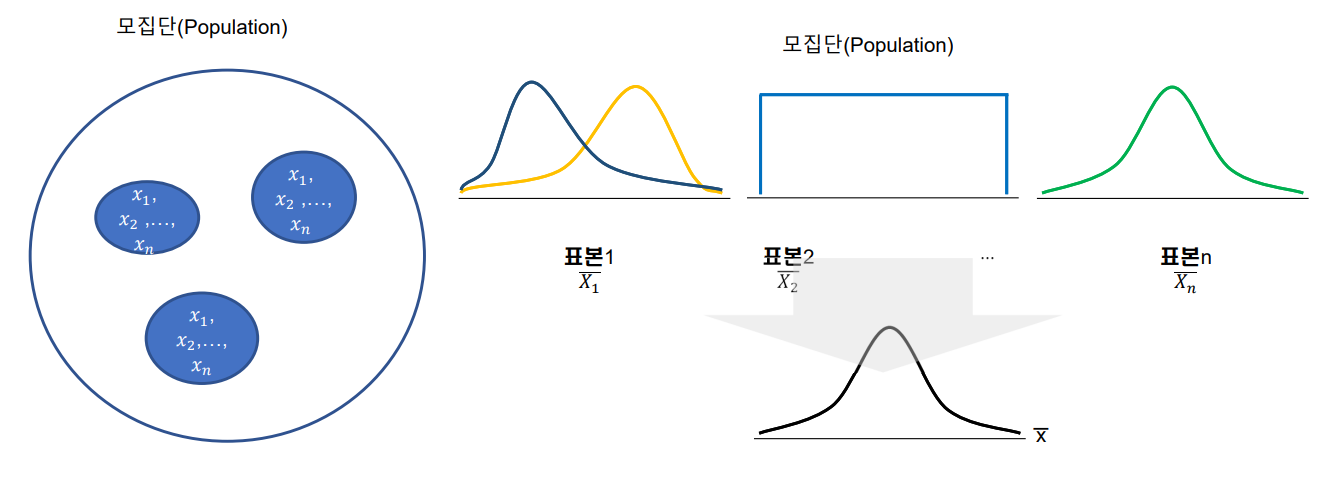
표본 분포
- 통계량(Statistic) : 표본에 기초하여 계산되는 수치 함수를 통계량이라고 함
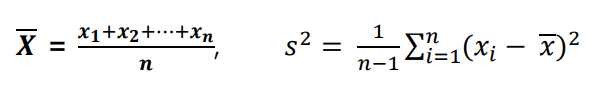
- 표본분포(Sampling distribution) : 통계량들이 이루는 분포를 표본 분포라고 함
표본 평균
- 표본 평균(Sample mean)
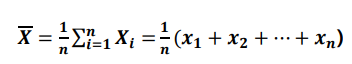
- 표본 평군의 기댓값
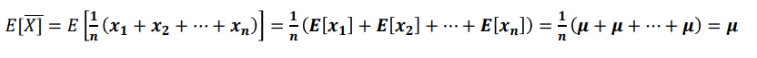
- 표본 평균의 분산
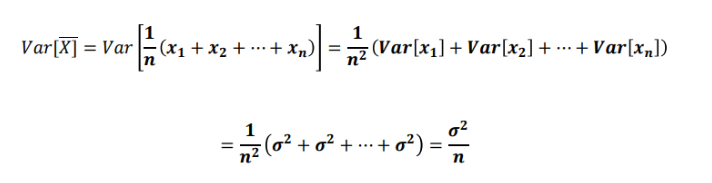
예시

-> iid : 모든 펴본이 서로 독립이고 동일한 분포에서 뽑는다
중심극한 정리(central limit theorem)
- 평균이 μ 이고 σ²인 임의의 모집단에서 랜덤 표본 X₁, X₂ ,... Xn을 추출할 때 표본의 크기 n이 충분히 (n≥30) 크면, 표본 평균 X바 는 근사적으로 정규분포 N(μ, σ²/n)을 따른다
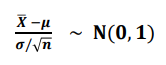
예시

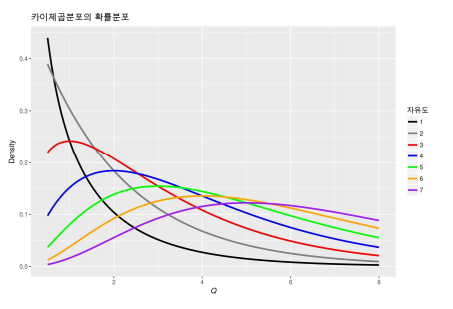
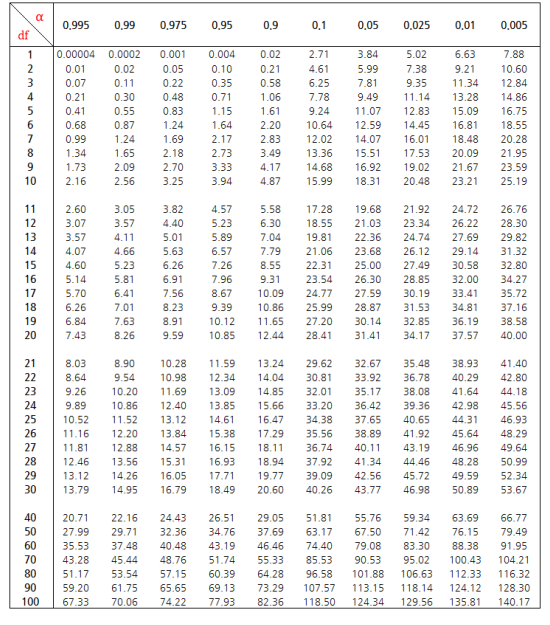
카이제곱분포

- 카이제곱 분포는 감마 분포에서 α = ν / 2, λ = 2와 같음
- 카이제곱 분포는 범주형 자료 분석에서 활용함
예시
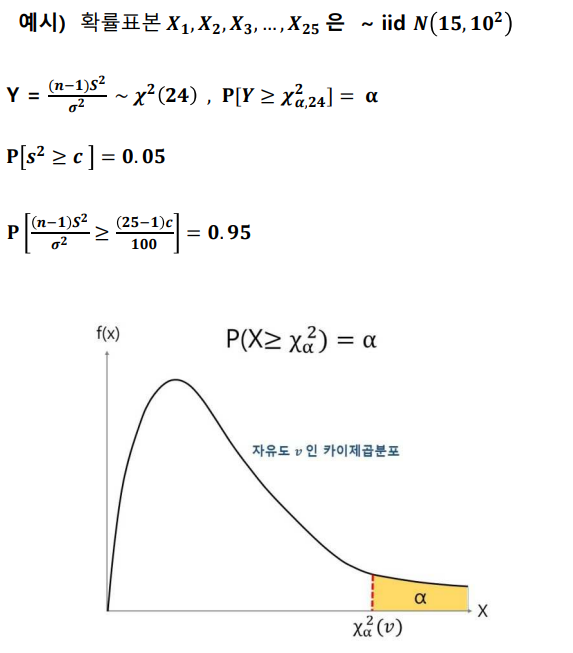
자유도(degree of freedom)
- 표본수 - 제약조건의 수 또는 표본수 - 추정해야 하는 모수의 수를 의미하며, 일반적으로 n-1을 사용함
- 예시적으로 설명하면 표본의 크기가 5이고, 표본 평균이 3으로 정해졌다면, 숫자 4개는 자유롭게 정할 수 있으나 마지막 하나의 숫자는 나머지 네 개의 숫자에 의해 결정. 1,2,3,4를 골랐다면 마지막 숫자는 자동으로 5가 되야 평균이 5로 정해져 있음
- 카이제곱 분포는 자유도 v의 크기에 따라 모양이 달라짐 자유도가 커질수록 분포가 좌우 대칭 형태로 됨
- 카이제곱 분포는 자유도가 커지면서 표준정규 분포에 근사하며, v≥ 30이면, 확률을 근사적으로 정규분포로 구할 수 있음
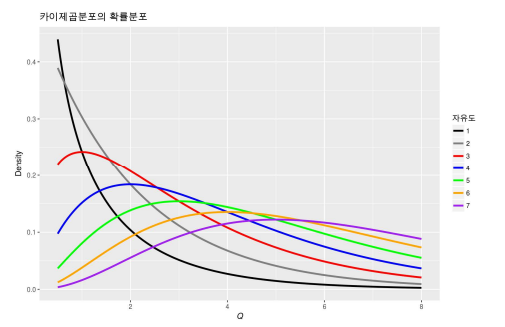
T분포

- 만약 모표준편차 σ를 모른다면, σ를 대신해서 표본표준편차 s를 이용해서 확률변수 Z를 정의함
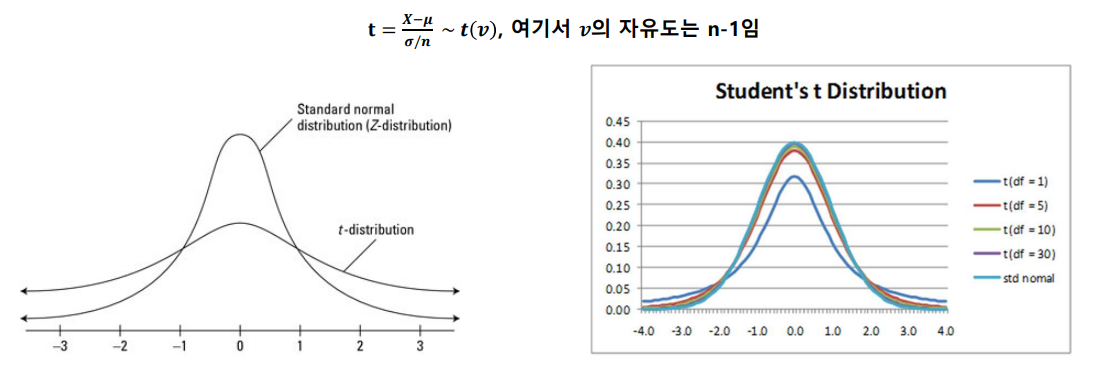
예시

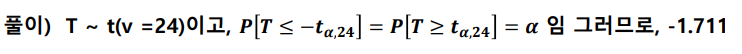
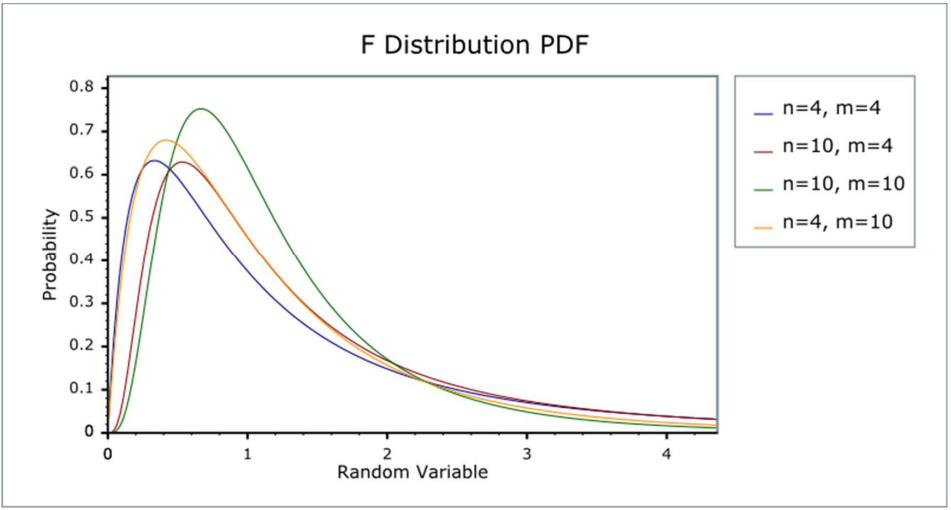
F분포

- 서로 독립인 두 정규모집단의 분산 또는 표준편차들의 비율에 대한 통계적 추론, 분산분석 등에 활용됨
예시

추정
-
추정(estimation): 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것을 추정이라고 한다
-
추정량(estimator): 표본 평균으로 모평균을 추정할 때 표본 평균에 대한 추정량이라고 함
-
모수를 추정하는 방법에는 점 추정(point estimation)과 구간 추정(interval estimation)이 있음
-
점추정: 모수를 하나의 특정값으로 추청하는 방법
-
구간 추정: 모수가 포함될 수 있는 구간을 추정하는 방법

점추정
- 대표적인 성질
구간 추정
-
신뢰구간(confidence level) : 추정값이 존재한느 구간에 모수가 포함될 확률
-
신뢰 수준은 100 * (1 - α)%f로 계산하며, α는 오차 수준임
-
신뢰 수준 95%라는 것은 구간 추정된 값의 오차가 발생할 확률이 5%라는 것을 의미함
-
이 오차를 유의 수준(significant level)이라고 하며, p=0.05라고 함
-
신뢰구간은 신뢰 하한, 신뢰 상한으로 표시하며 아래와 같은 수식으로 표현( 추정하는 모수가 θ)
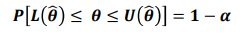
- 모평균 μ를 추정한다면, 표본평균이 x바이고 표준오차가 sd라고 하면 신뢰구간은 아래와 같다
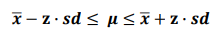
예시
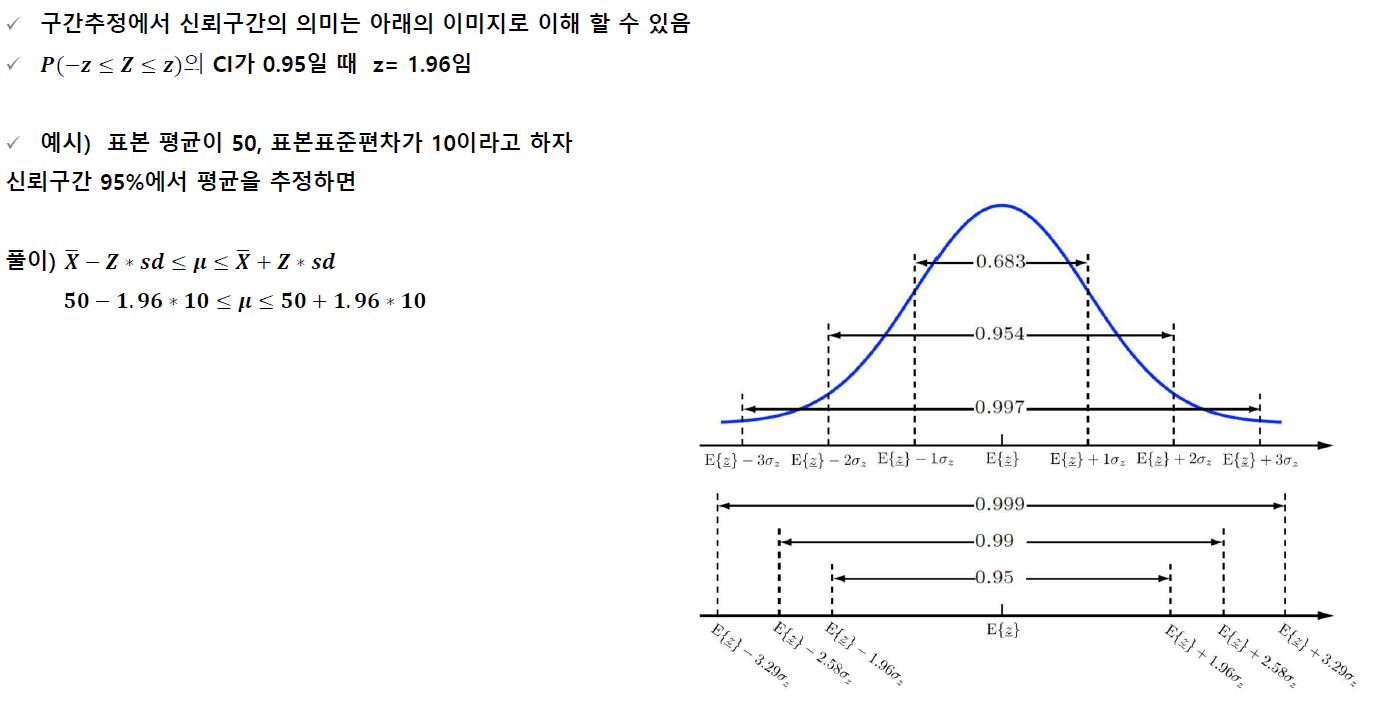
모평균의 구간 추정
- 모집단의 분산을 아는 경우

- 모집단의 분산을 모르는 경우

- 표본의 크기 결정
허용 오차(permissible error) : 추정한 값이 틀려도 허용할 수 있는 오차
정규분포의 신뢰구간을 통해 허용 오차를 계산
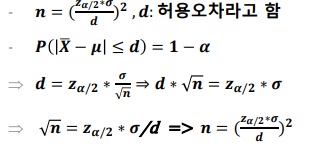
모비율의 추정
- 모비율의 구간 추정
예시) 20대 전체의 A사 핸드폰 사용률을 알기 위해서 무작위로 500명을 대상을 조사한 결과 212명이 A사 핸드폰을 사용 중이었다. 20대 전체의 A사 핸드폰 사용률에 대한 추정값을 구하고 95% C.I를 구하시오

- 모비율의 표본 크기(대표본일 경우)
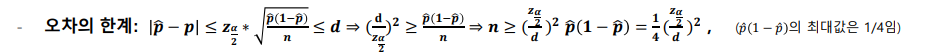
예시) 20대 전체의 A사 핸드폰 사용률을 알기 위해서 A사용률을 추정에 대한 95% 신뢰구간으로 오차의 한계를 0.01로 하기 위한 표본의 크기는?
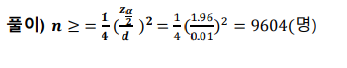
- 모평균 차이의 추정(점추정)
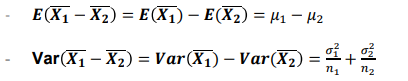
- 모평균 차이의 추정(구간추정: 대표본)
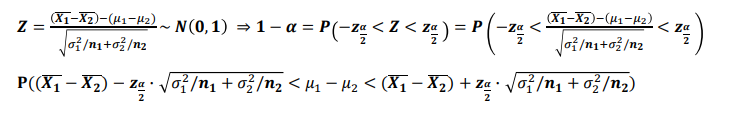

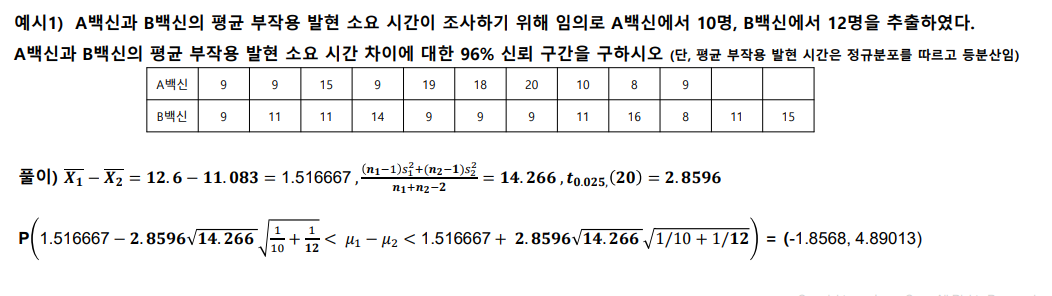
- 모평균 차이의 추정(구간추정:소표본, 모분산을 모르는 경우)

예시

- 모비율 차이의 추정(점추정)
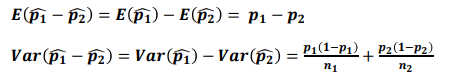
- 모비율 차이의 추정(구간추정)
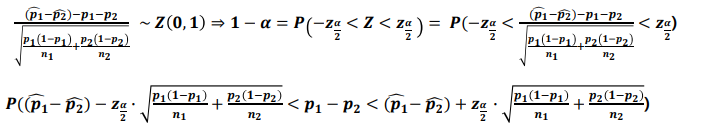
- 모비율 차이의 추정
예시) ) 20대 남녀 코로나 백신 접종률에 차이가 있는지 보기위해서 100명씩 각각 추출해서 남자의 경우 95명이, 여자의 경우 90명이 접종한것으로 조사되었다. 남녀의 백신 접종률 차이에 대해서 점추정치와 95% 신뢰구간을 구하라