강의의 목적
- 기본 개념과 이론에 대한 이해
- 태블로, EDA, 머신러닝 수업 등에 대한 기초 마련
- 데이터 분석 업무를 하기 위한 기초 통계에 대한 이해
강의 목차
- Introduce
- 데이터의 이해
- 확률 이론
- 확률 분포
- 모집단과 표본 분포
- 추정
- 가설 검정
- 범주형 자료분석
- 상관 분석과 회귀 분석
- 분산 분석
- Machine Learning 알고리즘과 실제 활용 소개
1. Introduce
-
통계학(statistics) : 산술적 방법을 기초로 하여, 주로 다량의 데이터를 관찰하고 정리 및 분석하는 방법을 연구하는 수학의 한 분야
-
기술통계학(desciptive statistics) : 데이터를 수집하고 수집된 데이터를 쉽게 이해하고 설명할 수 있도록 정리 요약 설명하는 방법론
-
추론통계학(inferential statistics) : 모집단으로부터 추출한 표본 데이터를 분석하여 모집단의 여러가지 특성을 추측하는 방법론
-
통계 : 가설 -> 검증 / 기술 통계 분석 / 추론 통계 분석
-
데이터 마이닝 : 군집, 연관 분석 / 예측 모델링 / 텍스트 마이닝
-
빅데이터 : 머신러닝 / 딥러닝
-
AI : 빅데이터 / 머신러닝 / 딥러닝
데이터 수집 및 처리 : 오라클, 하둡, 스파크 등등
분석 툴 : sas, Rstudio, python, tensorflow 등등
시각화 : excel, tableau 등등

- 데이터 마이닝 : 데이터로부터 유효한 정보를 취득해서 예측한다
- AI : 기존의 사람이 분석하고 사람이 해석하는 방식에서 사람이 원하는 결과를 컴퓨터를 학습을 시켜서 자동으로 산출할 수 있도록 하는 방법
- 데이터 수집 및 처리 : 오라클같은 RDBMS로 데이터를 처리해왔는데 요즘엔 하둡이 등장하고 하둡을 많이 사용하는 추세, 점점 업그레이드하고 있는 중
- 분석 툴 : sas가 많이 사용되었었는데 최근엔 R 혹은 python이 각광받는 중
- 시각화 : self BI툴
- 엑셀은 기본 소양
데이터의 이해
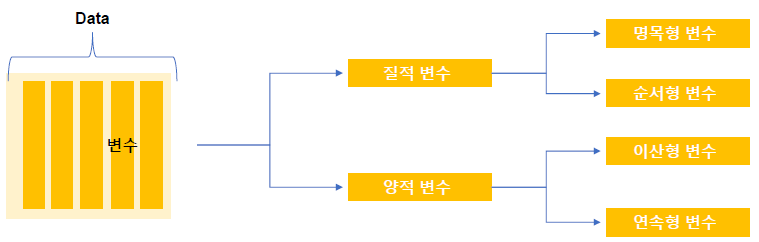
변수(Variable)
-
통계학에서의 변수는 조사 목적에 따라 관측된 자료값을 변수라고 한다. 해당 변수에 대하여 관측된 값들이 바로 자료(Data) 가 된다. 쉽게 말하면 컬럼이라 할 수 있다
-
질적 자료 : 관측된 데이터가 성별, 주소지(시군구), 업종 등과 같이 몇 개의 범주로 구분하여 표현할 수 있는 데이터를 의미한다. 데이터 입력시 1은 남자, 2는 여자로 표현 가능하나 여기서 숫자의 의미는 없다(순서형 변수: 교육수준, 건강상태처럼 숫자에는 의미없고 순서에만 의미있는 변수)
-
양적 자료 : 관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있다. 숫자를 표현할 때는 이산형 데이터와 연속형 데이터로 구분할 수 있다. 숫자가 깔끔하게 떨어지는 경우 이산형 데이터(성적 등), 실수처럼 숫자가 쭉 이어지는 데이터를 연속형 데이터(키, 몸무게 등)
EDA(Exploratory Data Analysis)
- 데이터를 탐색하는 분석 방법으로 도표, 그래프, 요약 통계 등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법
- 분석 초기에 가장 많이 사용하는 분석 방법 중 하나
- 목적
-데이터 분석 프로젝트 초기에 가설을 수립하기 위해 사용
-데이터 분석 프로젝트 초기에 적절한 모델 및 기법의 선정
-변수 간 트렌드, 패턴, 관계 등을 찾고 통계적 추론을 기반으로 가정을 평가
-분석 데이터에 적절한가 평가, 추가 수집, 이상치 발견 등에 활용
데이터 시각화
- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정을 말한다. 데이터 시각화의 목적은 도표(graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달하는 것이다

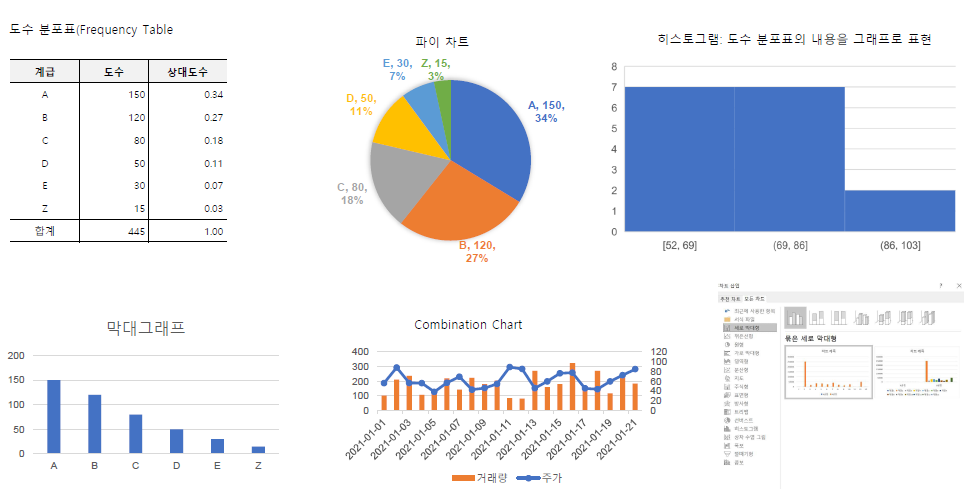
-
데이터를 얼마나 잘 디자인해서 데이터가 가지고 있는 스토리를 다른 사람에게 얼마나 적절하게 공유해줄 것이냐라는 개념이 중요
-
시간 시각화 : 시간의 흐름에 따라서 데이터가 어떻게 흘러가는지 효과적으로 전달할 것냐라는 개념이다
-
분포 시각화 : 데이터가 어떠한 분표의 형태를 가지고 있는지 판단하는 개념, 어디에 쏠려있고, 어디에 뭉쳐있고, 어디에 적은지 쉽게 볼 수 있어야 한다
-
관계 시각화 : 변수간의 관계를 보여줄 때 많이 사용한다
-
비교 시각화 : 히트맵을 많이 사용, 변수간에 데이터가 쏠려있는 점을 비교해서 볼 수 있다
-
공간 시각화 : 지도에 차트를 맵핑해서 사용한다
데이터 기초 통계량
- 기초 통계량
-통계량(statistic)은 표본으로 산출한 값으로, 기술통계량이라고도 표현한다
-통계량을 통해 데이터(표본)가 갖는 특성을 이해할 수 있다 - 중심 경향치
-표본(데이터)를 이해하기 위해서는 표본의 중심에 대해서 관심을 갖기 때문에 표본의 중심을 설명하는 값을 대표값이라 하며 이를 중심경향치라고 한다
-대표적인 중심 경향치는 평균이며, 중앙값, 최빈값, 절사 평균 등이 있다
-목적이나 데이터 성격에 따라서 무엇을 사용하냐가 결정된다
-평균의 함정같은 경우 때문에 중앙값을 사용하는 경우가 있다 - 평균은 모집단으로부터 관측된 n개의 x가 주어졌을 때 아래와 같이 정의된다
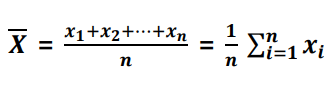
-
평균은 표본으로 추출된 표본 평균(sample mean)이라고도 하며, 모집단의 모평균이라고 한다
-
중앙값(median)
-평균과 같이 자주 사용하는 값으로 표본으로부터 관측치를 크기순으로 나열했을 때, 가운데 위치하는 값을 의미한다
-관측치가 홀수일 경우 중앙에 취하는 값이고, 짝수일 경우 가운데 두개의 값을 산술 평균한 값이다
-이상치가 포함된 데이터에 대해서 사용한다(너무 편차가 심한 데이터가 있을때)

- 최빈값(mode)
-관측치 중에서 가장 많이 관측되는 값
-옷사이즈와 같이 명목형 데이터의 경우 사용
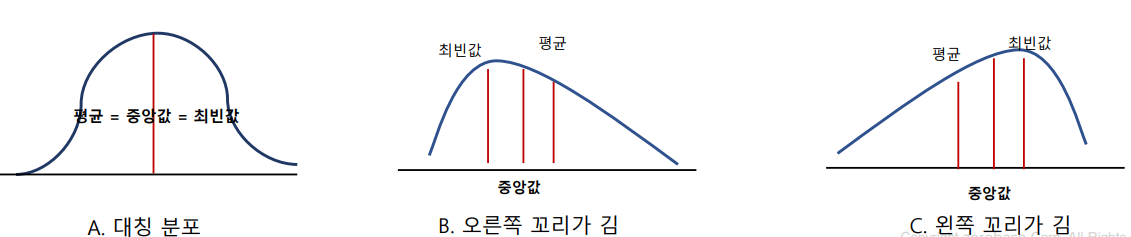
-보통 통계학에서 가장 선호하는 것도 A같은 대칭분포
-최빈값 - 중앙값 - 평균 순으로 나타나면 오른쪽으로 꼬리가 길다
-평균 - 중앙값 - 최빈값 순으로 나타나면 왼쪽으로 꼬리가 길다
- 산포도
-데이터가 어떻게 흩어져 있는지를 확인하기 위해서는 중심경향치와 함께 산포에 대한 측도를 같이 고려해야 한다
-데이터의 산포도를 나타내는 측도로는 범위, 사분위수, 분산, 표준편차, 변동 계수 등이 있다
- 범위(range)
-데이터의 최대값과 최소값의 차이를 의미한다
-
사분위수(quartile)
- 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫 번째를 제1사분위수(Q1), 두 번째를 제2사분위수(Q2), 세 번째를 제3사분위수(Q3)이라고 한다
-사분위수 범위(interquartile range): IQR = 제3사분위수(Q3) - 제1사분위수(Q1)
-데이터가 1부터 100까지 있다고 치면 25, 50, 75라고 봐도 무방하다 -
백분위수(percentile) :
-전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값을 말하며, 제p백분위수는 p%에 위치한 자료 값을 말함
-데이터를 오름차수로 배열하고 자료가 n개가 있을 때, 제(100*p) 백분위수는 아래와 같음
1) np가 정수이면, np번째와 (np + 1)번째 자료의 평균
2) np가 정수가 아니면, np보다 큰 최소의 정수를 m이라고 할 때 m번째 자료 -
분산(variance)
-산포도에서 가장 중요한 개념
-데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도이다
-데이터의 각각의 값들의 편차 제곱합으로 계산하며 수식은 아래와 같다
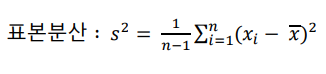
각각 관측된 자료를 평균으로 뺀 다음 제곱합으로 계산
그냥 더하면 0으로 맞춰져서 제곱을 한다
- 표준 편차(standard deviation)
-분산의 제곱근으로 정의하며 수식은 아래와 같음

- 분산
-시그마라고 한다

- 변동계수(Coefficient of Variation: CV)
-평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용한다
-데이터가 얼마나 흩어져있는지 비교할 때 사용
-두 모집단의 분산을 비교할 때 쓰는 개념
-변동계수는 표준편차를 쳥균으로 나누어서 산출하여 단위나 조건에 상관 없이 서로 다른 그룹의 산포를 비교하며 실제 분석에서 자주 사용한다
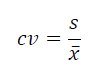
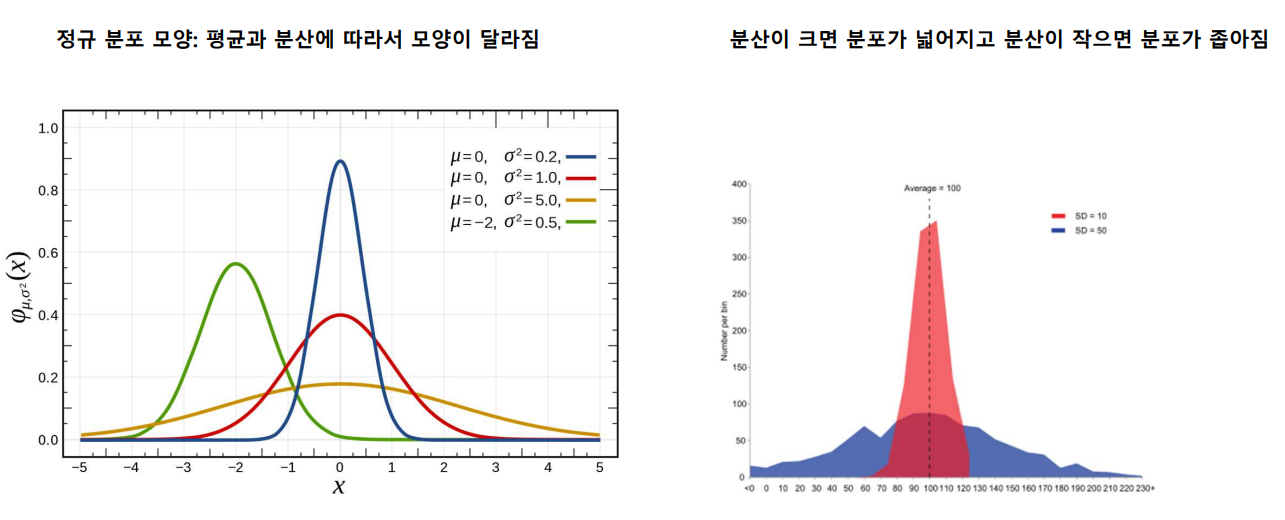
정규 분포 모양
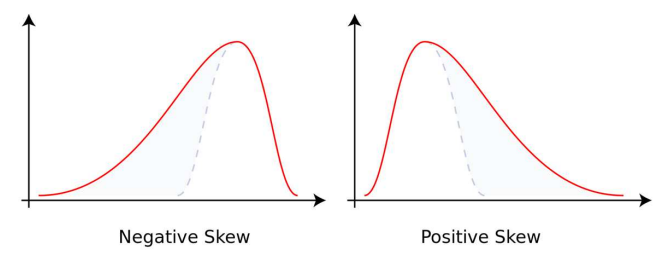
- 왜도(skew)
-자료의 분포가 얼마나 비대칭적인지 표현하는 지표이다
-왜도가 0이면 좌우가 대칭이고, 0에서 클수록 우측꼬리가 길어지고 0에서 작을 수록 좌측 꼬리가 길어짐
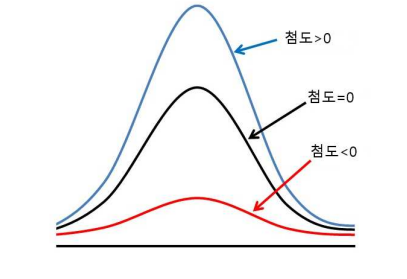
- 첨도(kurtosis)
-확률분포의 꼬리가 두꺼운 정도를 나타내는 척도이다
-첨도값(K)이 3에 가까우면 산포도가 정규분포에 가깝다
-3보다 작을 경우에는(K < 3) 산포는 정규분포보다 꼬리가 얇은 분포로 생각할 수 있다
-첨도값이 3보다 큰 양수이면(K > 3) 정규분포보다 꼬리가 두꺼운 분포로 판단
확률 이론
확률
-
모든 경우의 수에 대한 특정 사건이 발생하는 비율이다. 대체로 수학 외에서는, 0과 1 사이의 소수 혹은 분수나 순열 등으로 나타내기 보다는, 다른 비율을 나타낼 때처럼 0과 1 사이의 확률에 100을 곱하여 0과 100 사이의 백분율(%)로 나타내거나 옛날처럼 할푼리로 나타내기도 한다.
-
확률의 고전적 정의
-어떤 사건의 발생 확률은 그것이 일어날 수 있는 경우의 수 대 가능한 모든 경우의 수의 비이다. 단, 이는 어떠한 사건도 다른 사건들보다 더 많이 일어날 수 있다고 기대할 근거가 없을 때, 그러니까 모든 사건이 동일하게 일어날 수 있다고 할 때에 성립한다.
- 표본 공간(Sample Space)
-어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합
동전 던지기의 경우 S = {앞면, 뒷면}, 주사위 던지기 S = {1,2,3,4,5,6}
- 사건 A가 일어날 확률을 P(A)라고 하고, 표본 공간(S)가 유한집합일때 표본 공간의 모든 원소들이 일어날 확률이 같으면

1) 주사위를 던저서 6이 나올 확률
2) 트럼프 카드 52장중 A가 나올 확률
3) 로또 1등에 당첨될 확률

- 통계적 확률 정의

확률의 성질
-합사건(union) : 사건 A 또는 사건B가 일어날 확률
-곱사건(intersection) : 사건 A와 사건B가 동시에 일어날 확률
-배반사건(mutualy exclusive event) : 사건 A와 사건B가 동시에 일어날 수 없는 경우
-여사건(complement) : 사건A가 일어나지 않을 확률
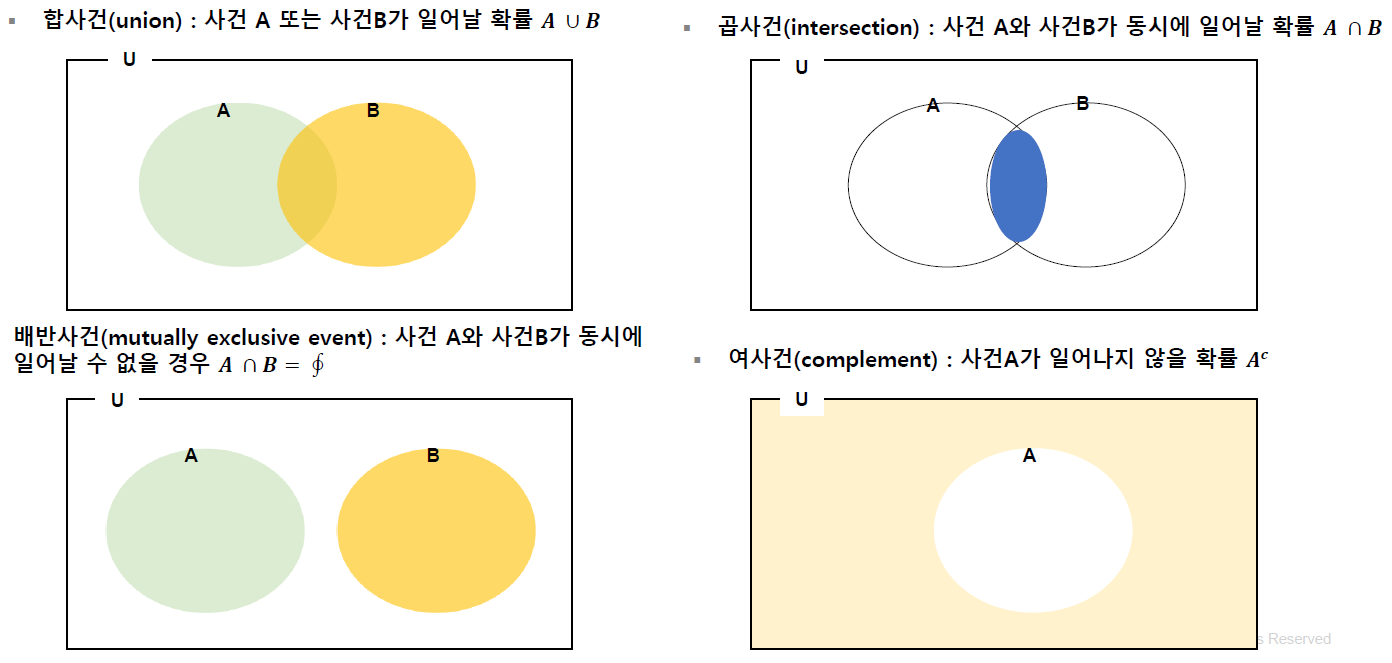
- 확률의 성질


조합과 순열

조건부확률
- 어떤 사건A가 발생한 상황(주어졌을 때) 또 하나의 사건B가 발생활 활률
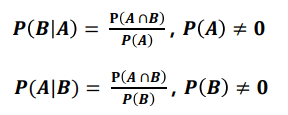
- 확률의 곱셈법칙

- 베이즈 정리(Bayes' Theorem)
-표본 공간 S에서 서로 배반인 사건 B1,B2,...,Bk에 의하여 분할 되어 있을 때, 임의의 사건 A에 대하여 다음이 성립한다
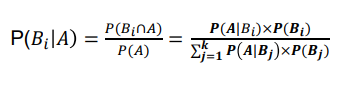
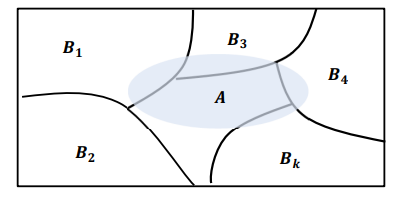
- 예제) 자동차 보험의 고객의 분포 A등급 30%, B등급 50%, C등급 20%이고, 각 고객 등급별로 1년내 사고의 확률은 A등급 0.1 B등급 0.2 C등급 0.3이라면
a) 임의의 한 고객을 선택했을때, 그 고객이 1년 이내에 사고를 낼 확률을 구하시오
b) 어떤 고객이 1년내 사고를 낸 고객이라면, 그 고객이 A등급일 확률을 구하시오

-> 한 고객이 A등급이면 B등급일 수 없으니까 각 등급은 서로 배반 사건
확률 변수
-
표본공간에서 각 사건에 실수를 대응시키는 함수이다
-
확률 변수의 값은 하나의 사건에 대하여 하나의 값을 가지며, 실험의 결과에 의하여 변한다
-
일반적으로 확률 변수는 대문자로 표현하며, 확률변수의 특정값을 소문자로 표현한다
-확률 변수 : X, Y 등 대문자 표현
-확룰 변수의 특정값 : x, y 등 소문자로 표현
-이산 확률 변수(discrete random variable) : 셀 수 있는 값들로 구성되거나 일정 범위로 나타나는 경우
-연속 확률 변수(continuous random variable) : 연속형 또는 무한대와 같이 셀 수 없는 경우
-
확률 변수 예시
(a) 반도체 1000개의 wafer중 불량품의 수 X
(b) 공장에서 생산하는 전구의 수명 T
(c) 주사위를 던질 때 나오는 눈의 수 V -
확률 변수의 평균 : 기대값이라고 표현하기도 하며, 수식은 아래와 같다
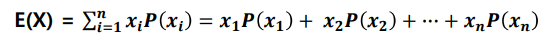
- 주사위를 던졌을 때의 기대값
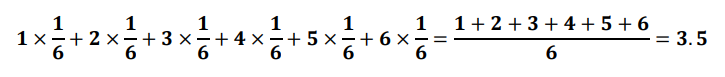
- 확률 변수의 분산
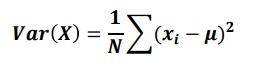
기대값의 성질

분산의 성질

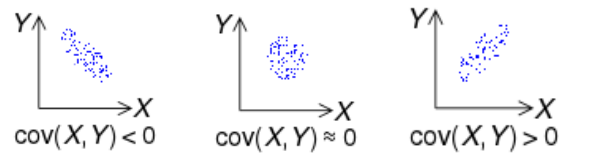
공분산
- 2개의 확률변수의 선형 관계를 나타내는 값으로, 하나의 값이 상승할 때 다른 값도 상승한다면, 양의 공분산을 가지고 반대로 하나의 값이 상승할 때 하락한다면 음의 공분산을 가진다
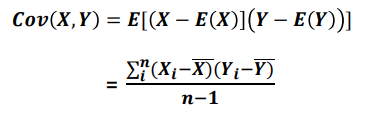

확률 분포
- 확률 분포(probability distribution) : 확률 변수 X가 취할 수 있는 모든 값과 그 값을 나타날 확률을 표현한 함수
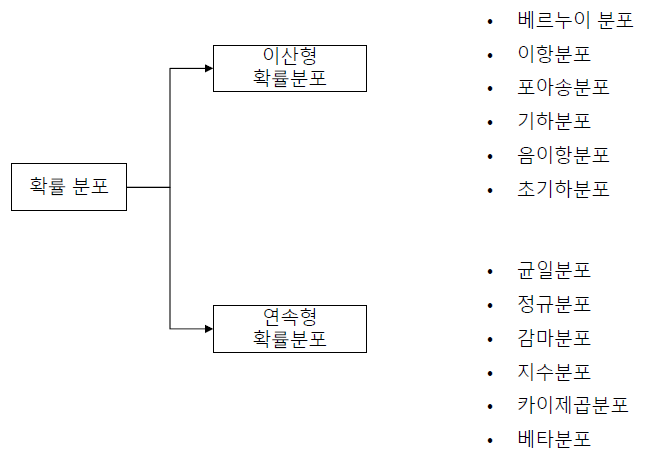
- 이상형 확률 분포 : 확률분포 X가 유한 개(예를 들어, 1부터 100까지 자연수)
- 연속형 확률 분포 : 확률분포 X가 무한대 (예를 들어, 1부터 100까지 실수)
- 분포에 대한 정의와 그 분포가 어떤 함수식으로 정의되고 그것들이 어떤 예시를 가지고 있는지 확실하게 인지해야 유리하다
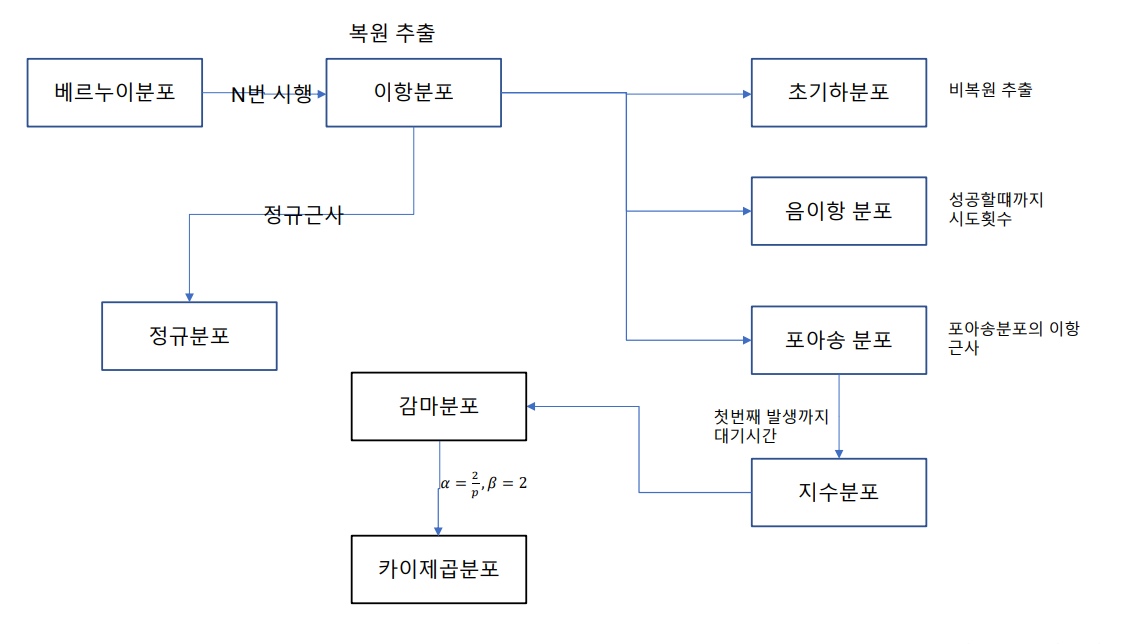
- 모든 분포들은 서로간의 관계를 가지고 있다. 베르누이 시행 -> 베르누이 분포 -> 이산형 분포 -> 정규 분포
이산형 확률 분포
이산형 균등 분포
- 이산형 균등 분포(discrete uniform distribution): 확률 변수 X가 유한개이고, 모든 확률 변수에 대하여 균일한 확률을 갖는 분포를 이산형 균등 분포라고 함
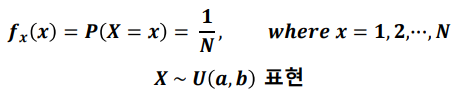
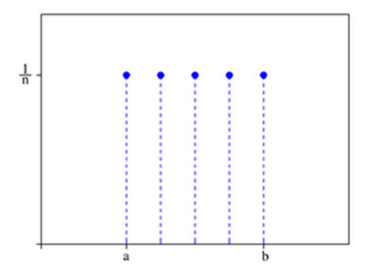
- 주사위를 한번 굴려서 나오는 숫자를 확률 변수 X라고 하면, 확률 변수 X는 아래와 같다

- 이산형 균등분포의 기대값

베르누이 분포
-
베르누이 시행(Bernouli trial) : 각 시행의 결과가 성공, 실패 두가지 결과만 존재하는 시행을 베르누이 시행이라고 한다
-
예) 슛을 차서 슛이 골이 될 확률, 노골이 될 확률 / 물건을 샀는데 물건이 정상일 확률, 불량품일 확률 등등
-
베르누이 시행에서 성공이 '1', 실패가 '0'의 값을 갖을 때 확률 변수 X의 분포를 베르누이 분포라고 하고 다음과 같이 정의한다
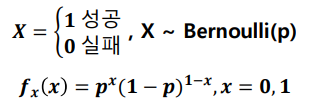
- 베르누이 분포의 평균
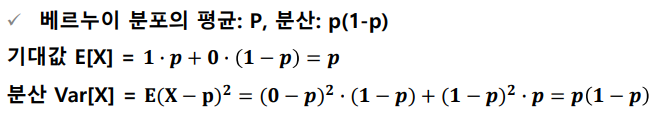
- 파란공 7개, 빨간공 3개가 들어있는 주머니에서 공 하나를 뽑을 때, 파란공이면 성공 빨란공이라면 실패인 실험을 한다고 가정하자. 이때 베르누이 분포를 정의하면
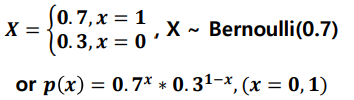
이항분포
-
이항 분포(Binomial distribution) : 연속적인 베르누이 시행을 거처 나타나는 확률 분포
-
서로 독립인 베르누이 시행을 n번 반복해서 실행했을 때, 성공한 횟수 X의 확률 분포
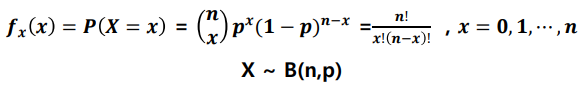
- 축구 선수의 패널티킥 성공률이 80%일 때, 10번의 기회에서 성공횟수와 그 확률을 구하면 아래와 같다
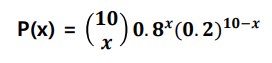
- 이항분포의 기대값

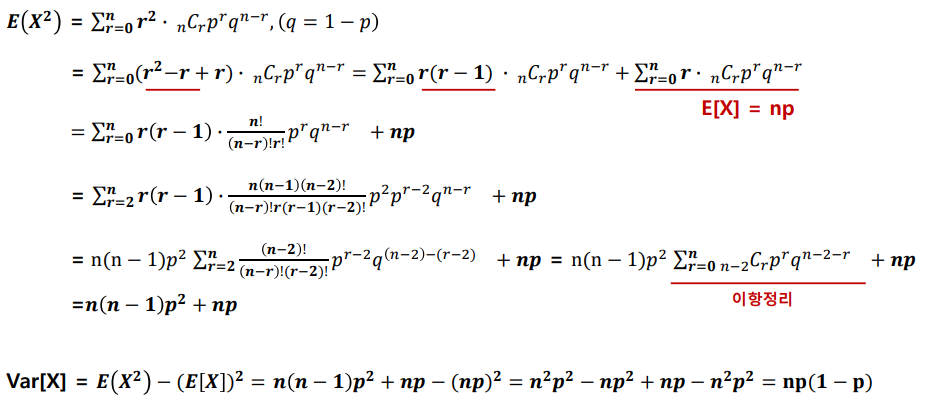
- 반도체 공장에서 불량이 발생할 확률이 10%라고 하자. 10개의 제품을 생성했을 때 불량이 2개 이하일 확률을 구하시오
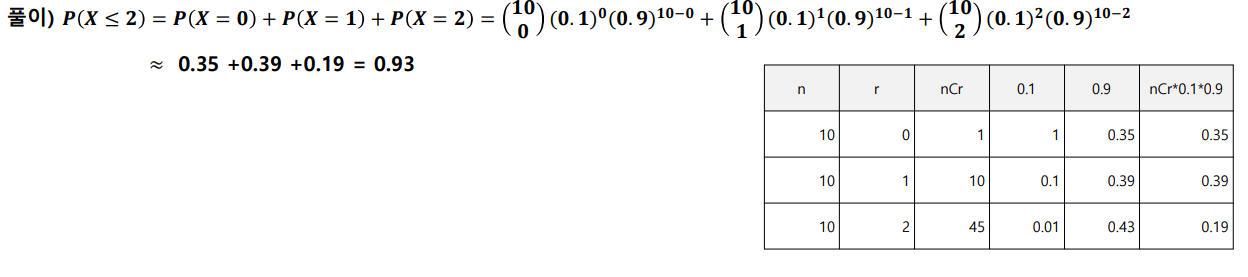
포아송 분포
-
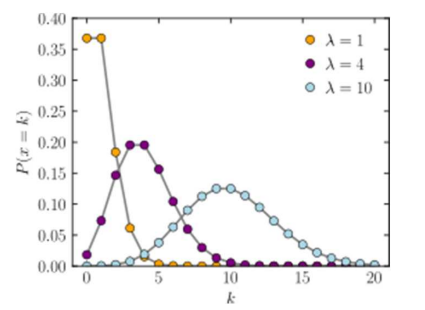
포아송 분포(Poisson distribution) : 어느 휘귀한 사건이 어떤 일정한 시간대에 특정한 사건이 발생할 확률 분포
-
예시) 야구장에서 파울볼을 잡을 횟수, 버스 정류장에서 특정 버스가 5분 이내에 도착한 횟수, 1년간 지구에 1미터 이상의 운석이 떨어지는 수 등
-
포아송 분포의 조건
- 어떤 단위구간(예, 1일)동안 이를 더 짧은 작은 단위의 구간(예:1시간)로 나눌 수 있고 이러한 더 짧은 단위구간 중에 어떤 사건이 발행할 확률은 전체 척도 중에서 항상 일정
- 두 개이상의 사건이 동시에 발생할 확률은 0에 가까움
- 어떤 단위구간의 사건의 발생은 다른 단위구간의 발생으로부터 독립적임
- 특정 구간에서의 사건 발생확률은 그 구간의 크기에 비례함
- 포아송 분포 확률 변수의 기댓값과 분산은 모두 λ(람다) 임
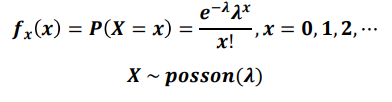
- 야구장에서 경기당 홈런볼을 잡는 관객이 평균 3명이라고 가정하자
- 오늘 경기에서 2명 이상이 홈런볼을 잡을 확률을 구하시오
- 오늘과 내일 동안 경기에서 홈런볼을 잡지 못할 확률을 구하시오

- 이항 분포의 포아송 근사
-확률 변수 X가 X ~ B(n,p)이고, n이 충분히 크고(통계학에선 일반적으로 충분히 크다의 기준을 30이상으로 잡고 있다), p가 아주 작을 때, X의 분포는 평균이 λ = np인 포아송 분포로 근사시킬 수 있다. 보통 n이 클 때, np<5를 만족하게 p가 작으면 근사 정도가 좋다고 한다 X ~ Poisson(np)
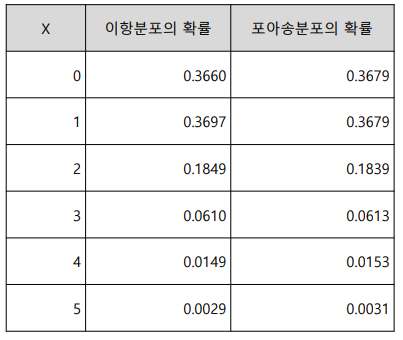
- 이항 분포와 포아송 비교
-아래의 표는 엑셀로 가능하며 분포를 표현하는 함수식으로 작성해 보시오.
n = 100, p = 0.01인 이항 분포 X~B(100,0.01)를 포아송 근사하면 X ~ Poisson(1)이 된다. (λ = 100 * 0.01 = 1)

기하 분포
- 기하분포(geometric distribution) : 어떤 실험에서 처음 성공이 발생하기 까지 시도한 횟수 X의 분포, 이때 각 시도는 베르누이 시행을 따른다
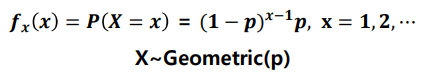
- 예시) 축구선수 손흥민의 필드골 성공 확률이 30%일 때, 5번째 슛팅에서 골을 넣을 확률 분포

- 기하 분포의 기대값

음이항 분포
- 음이항 분포(negative binomial distribution) : 어떤 실험에서 성공확률이 p일 때, r번의 실패가 나올 때까지 발생한 성공 횟수 X의 확률 분포
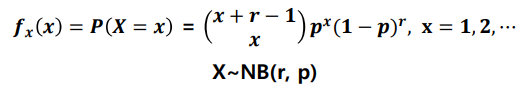
- 예시) 농구 선수 허훈의 자유투 성공 확률이 90%일 때, 3번째 실패가 나올 때까지 성공시킨 자유투가 10번일 확률
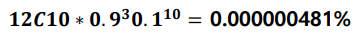
- 기하분포의 기대값
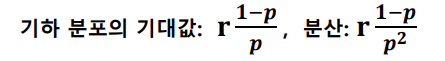
summary
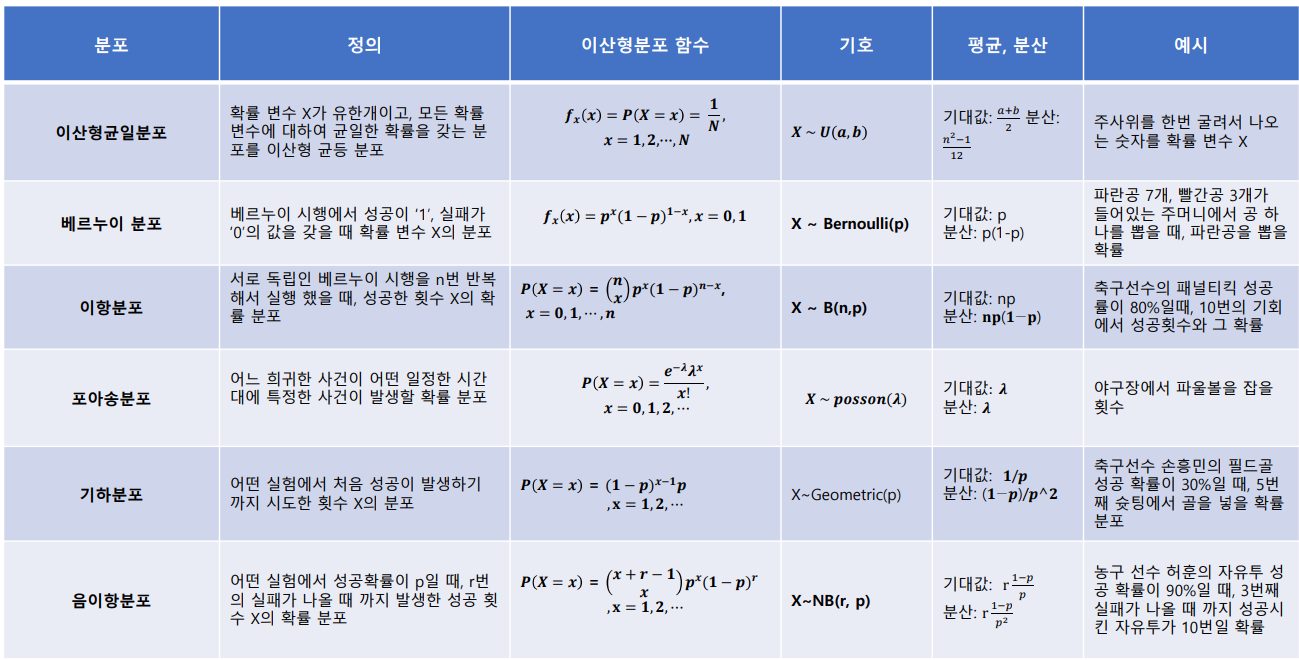
- 이중 이항분포가 정말 중요하고 나머지도 공식들은 잘 외우자!
연속형 확률 분포
확률밀도함수
- 확률밀도함수(probability density function, pdf): 연속형 확률 변수 X에 대해서 함수 f(x)가 아래의 조건을 만족하면 확률밀도함수라고 한다
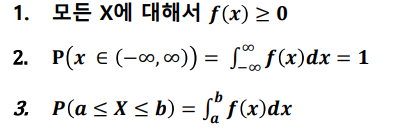
-> 적분을 할 수 있어야 함
- 확률밀도함수의 성질
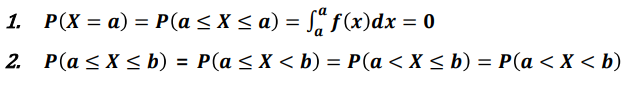
-> 한 점에 있을확률은 0이다. 선은 면적이 없다
- 확률밀도수의 평균과 분산
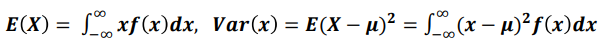
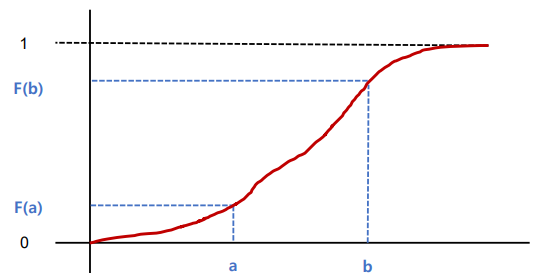
누적분포함수
- 누적분포함수(cumulative density function, cdf) : 확률밀도함수를 적분하면 누적분포함수가 된다
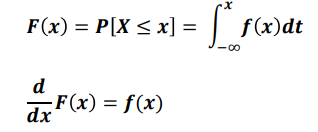
-> d / dx = 미분하라, cdf 미분 -> pdf
- 누적분포함수의 성질

-> cdf는 무조건 증가하는 함수라서 (2.) 성립
(3.) 은 F(b) - F(a)는 X가 a와 b사이에 있을 확률이다라는 의미
균일 분포
- 균일분포(uniform distribution) : 확률 변수 X가 a와 b사이에서 아래와 같은 확률밀도함수를 갖는다
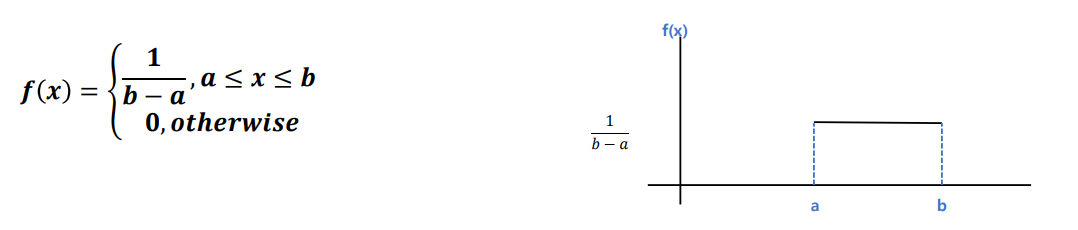
-> a와 b사이에서 같은 확률을 가진다( 1 / (b - a))
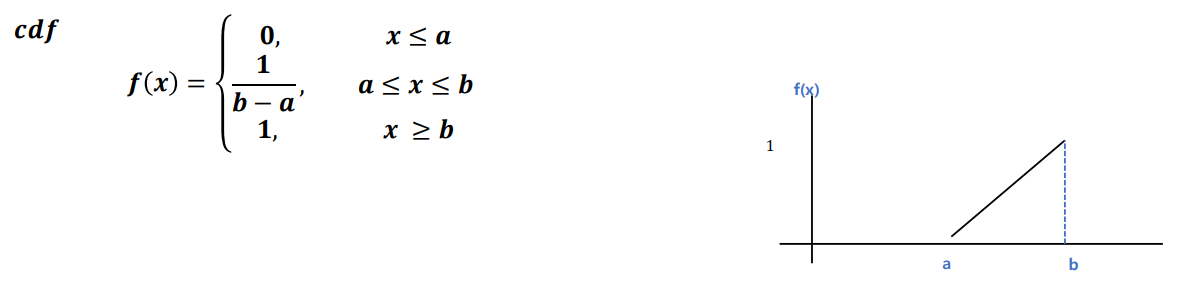
-> a이하에선 0, a부터 b사이에선 1 / (b-a), b에선 1을 가진다
- 균일 분포의 평균, 분산
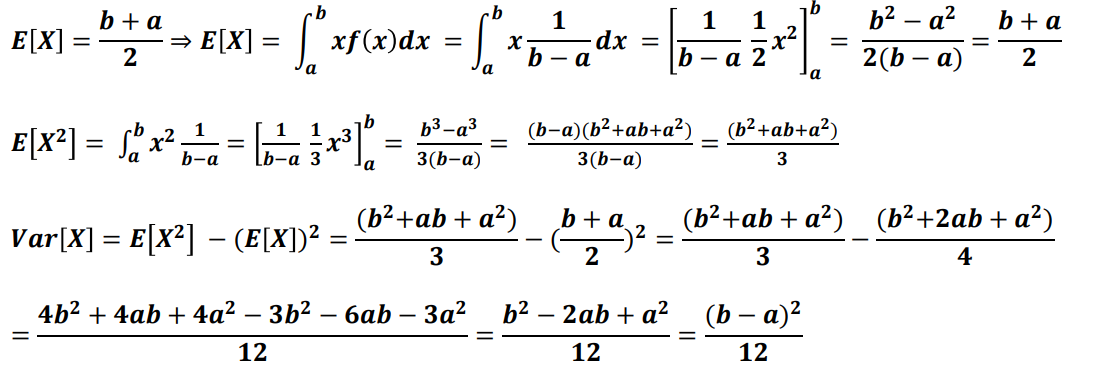
정규 분포
- 정규 분포(normal distribution) : 19세기 최대 수학자라고 불리는 독일의 가우스에 의해 제시된 것으로 가우스 분포라고도 한다.
- 통계에서 가장 중요한 분포
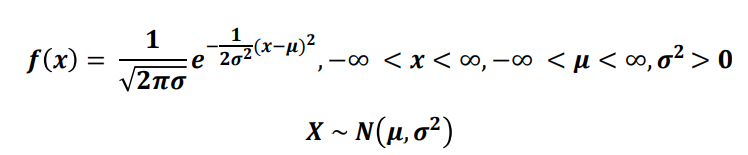
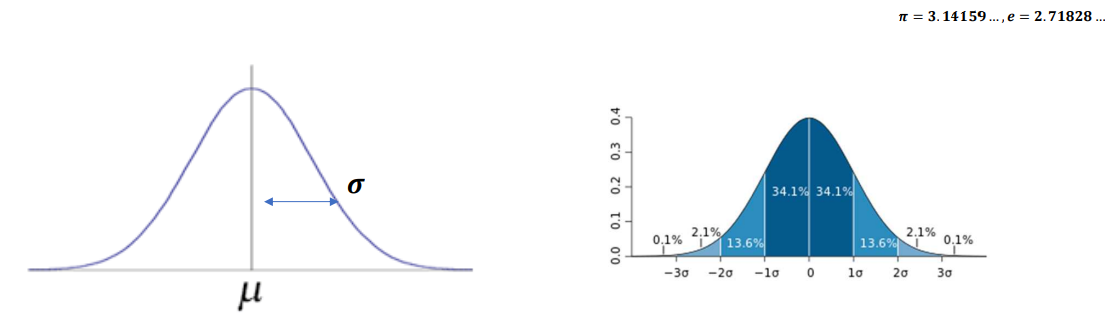
- 중심이 뮤(평균)이 되고 중심을 기준으로 좌우 대칭
- f(x)의 값이 가장 큰 값 = 평균에서 가장 높은 값
- 면적의 합이 1, 절반은 0.5
- 시그마(편차)
- 정규 분포의 평균과 분산
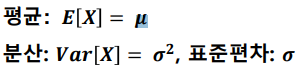
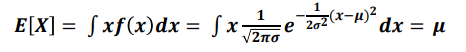
- 파라메터의 따른 정규 분포 모양 비교
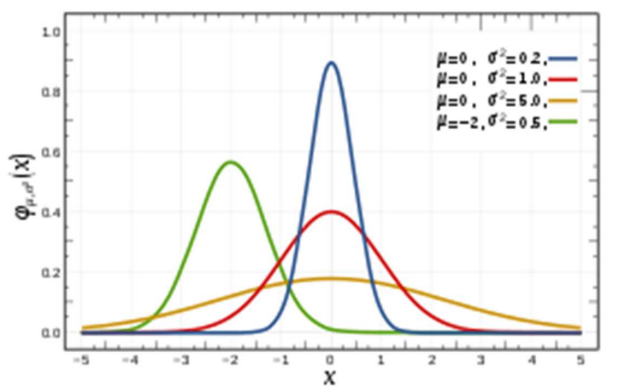
- 뮤나 시그마에 따라 모양이 다르다
- 시그마가 클수록 옆으로 늘어진 모양(노란색)
- 작을수록 뾰족(파란색)
- 평균을 중심으로 좌우대칭
- 표준 정규 분포(standard normal distribution)

- 표준화
-데이터를 표준화한다 -> 데이터를 분석하거나 예측 모델링, 혹은 두가지 데이터에 대해서 비교가 안될 때 표준화를 많이 한다
-성질이 다르기 때문에 성질을 같게 만들어서 비교한 다음에 예측을 하거나 활용을 한다. 예측할 때는 다시 돌려놓고 한다.
-예를 들어 한국과 미국의 온도를 비교할 때 한국과 미국이 사용하는 단위가 다르기 때문에 표준화를 통해 성질을 통일하고 분석한 후에 다시 원래대로 되돌려놓고 예측을 진행하는 게 순서다
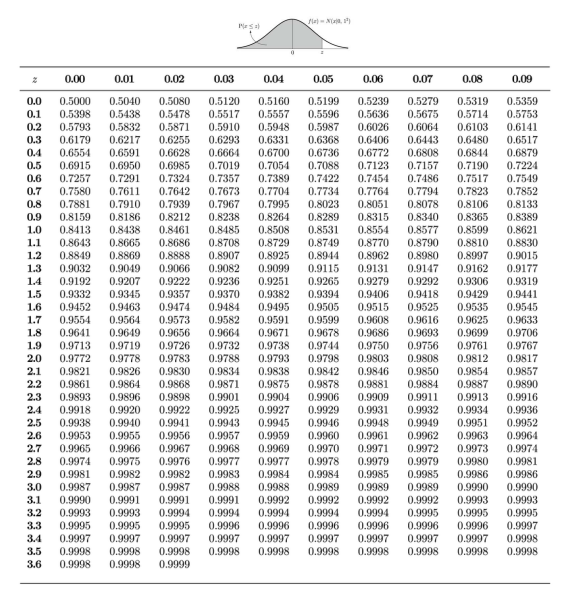
- 정규 분포의 성질

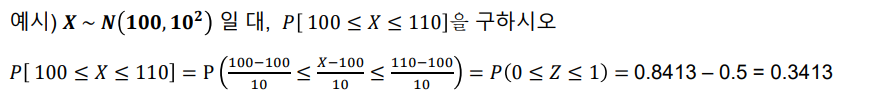
- 이항분포의 정규 근사

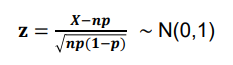
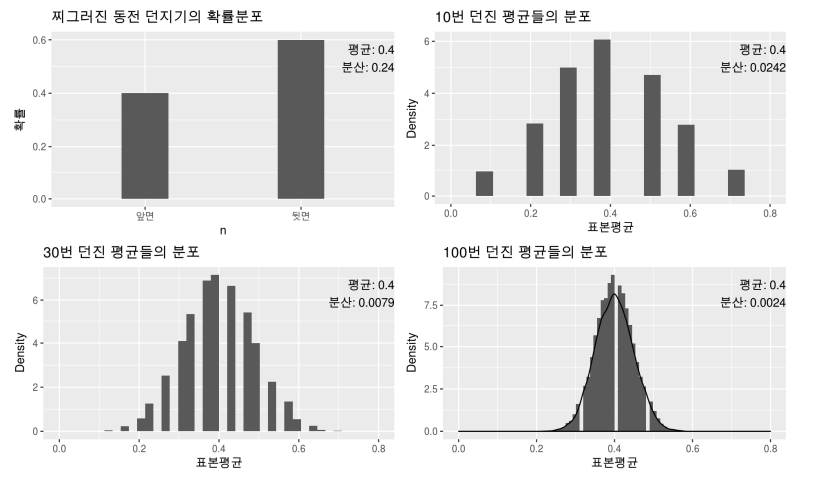
- 실습

지수 분포
-
지수 분포(exponential distribution) : 단위 시간당 발생할 확률 λ인 어떤 사건의 횟수가 포아송 분포를 따른다면, 어떤 사건이 처음 발생할 때까지 걸린 시간 확률 변수 X는 지수 분포이다
-
예시) 버스 정류장에서 100번 버스가 도착하는 횟수가 포아송 분포를 따른다면, 첫 번째 버스가 도착할 때까지 대기 시간의 분포가 지수분포이다
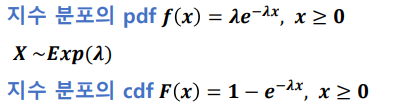
-
지수 분포는 연속 되는 사건의 사이의 대기 시간도 지수 분포이다
-
즉 앞의 예시에서 두 번째 버스가 도착하고 세 번째 버스가 도착할 때까지 대기 사긴의 분포도 지수 분포이다
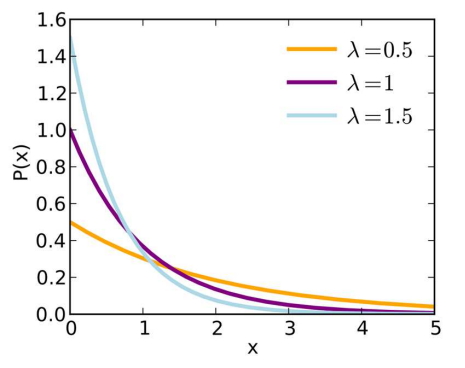
- 지수 분포의 평균과 분산
- 예시) 버스 정류장에 A버스가 평균 시간당 6대가 정차한다고 가정하자
1) 10분 이상 대기할 확률은?
2) 10분에서 20분 대기할 확률은?
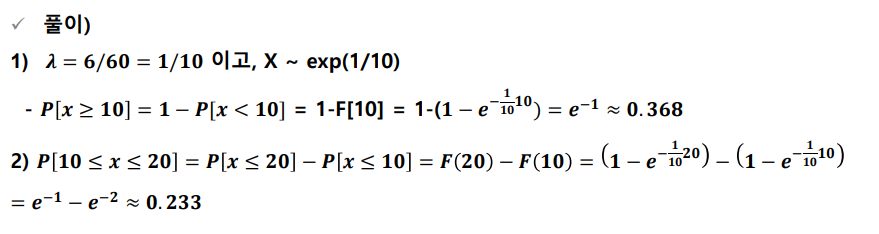
- 지수 분포의 무기억성(Memoryless Property)
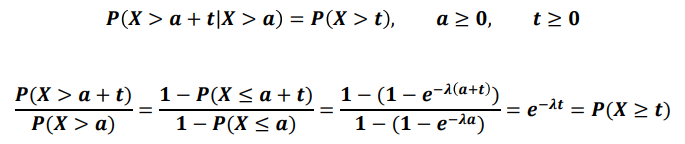
-
어떤 시점부터 소요되는 시간은 과거 시간에 영향을 받지 않는다
-
예시) 버스를 기다리는 대기시간은 먼저 기다린 사람과 확률이 같다
전구를 한달 동안 사용했을 때 남은 수명은 한달 간 사용했던 영향을 받지 않음, 즉 새 전구와 한달 간 사용한 전구의 남은 수명은 같다고 생각한다
이런 문제로 실제 적용에 문제가 있고, 생존 분석에서는 Weibull분포 또는 log-normal 분포를 사용하여 예측한다 -
지수 분포와 포아송 분포의 관계
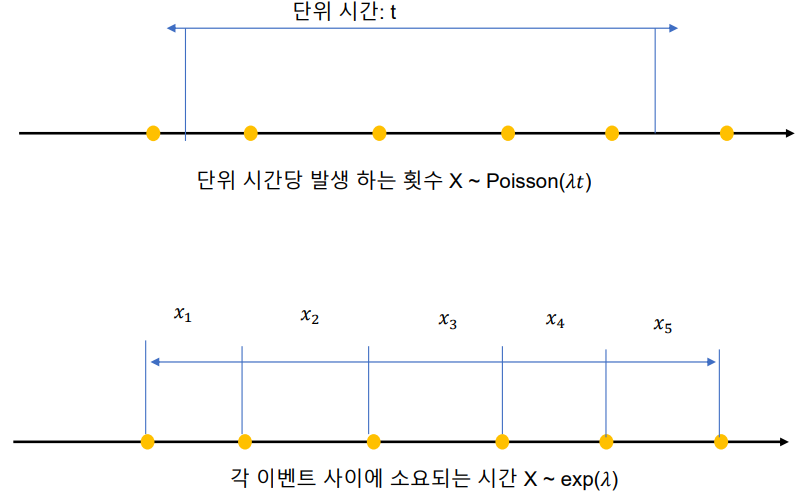
- 확률 분포의 관계도