강의 내용
2 Stage Detectors
2 Stage Detector 구조는 입력 이미지에 대해 먼저 물체의 위치를 특정하는 Localization을 진행하고, 해당 영역의 class를 지정하는 식으로 되어 있다. 사람으로 비교하면 물체 영역을 보는 것과 물체 이름 맞추기를 따로 하는 것이다.
R-CNN
R-CNN은 CNN을 통해 Object detection을 풀고차 했던 가장 초창기의 모델이다. 이 후 모델들도 R-CNN을 기반으로 발전하였다.
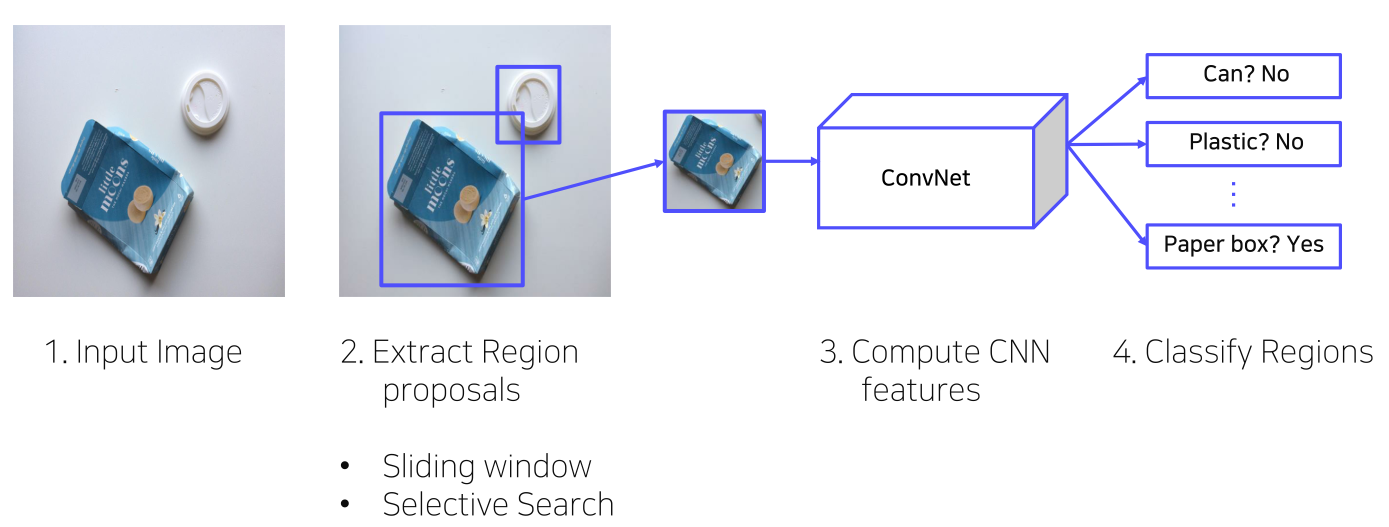
- 입력 이미지로부터 2000개의 RoI를 뽑는다.
- RoI는 대충 영역 후보라고 생각할 수 있고 sliding window, selective search 등의 기법으로 뽑을 수 있는데, R-CNN에선 selective search를 사용하였다.
- 영역 후보를 일정 크기로 resize한다.
- 뒤에 통과시킬 CNN의 마지막이 FC layer여서 resize를 함
- CNN을 통과시켜 feature를 추출한다.
- 각 region마다 4096-dim feature vector를 추출(2000 x 4096)
- R-CNN에선 Pretrained AlexNet을 사용하였다.
- 추출한 feature를 SVM을 통해 객체인지, 객체이면 어떤 class인지 분류한다.
- output : class(C+1) + confidence score
- 클래스 개수 C + 배경 여부 1개로 총 C+1개 예측
- Bbox regression을 통해 bounding box 예측
- RoI는 rough한 영역을 잡은 것이므로, GT 동일한 형태가 되도록 변형해야 한다. 이를 위해 RoI를 GT로 바꾸기 위해 크기 변화량, 위치 변화량을 학습한다.
R-CNN을 Training할 때,
- AlexNet을 Domain specific하게 fine-tuning하였다.
- AlexNet Dataset은 IoU를 기준으로 IoU > 0.5는 Positive sample, IoU < 0.5는 negative sample로 하여, 한 batch를 32 positive samples, 96 negative samples로 구성하였다.
- SVM Dataset은 GT를 positive sample, IoU < 0.3을 negative sample로 하여, 한 batch를 32 positive samples, 96 negative samples로 구성하였다.
- SVM에 hard negative mining 기법을 활용하였다. 이는 배경으로 식별하기 어려운 sample들을 강제로 다음 배치의 negative sample로 추가로 포함시켜 학습하는 방법이다. 보통 negative sample로는 배경 이미지가 많기 때문에, hard negative(0인데 1로 예측, 배경을 물체로 예측)를 최대한 포함시켜줘 negative sample의 퀄리티를 올리기 위해 사용하였다.
- Bbox regressor는 IoU > 0.6을 positive sample로 Dataset을 구성하며, MSE Loss를 사용하였다. negative sample은 box가 없기 때문에 포함시키지 않았다.
R-CNN의 단점
- 2000개의 Region을 각각 CNN에 통과시켜, CNN 연산이 엄청 많이 이루어져 속도가 느리다.
- 강제 warping(resize)을 사용하여, 객체 정보가 손실되어 성능 하락의 가능성이 있다
- CNN, SVM classifier, Bbox regressor를 따로 학습하였기 때문에 End-to-End 구조가 아니다.
SPPNet
R-CNN에서의 2000개의 Region을 각각 CNN에 통과시키는 점과 resize해야하는 부분을 개선하였다. 1번의 CNN 연산 이후 feature map으로부터 2000개의 RoI를 추출하며, Spatial Pyramid Pooling layer를 통해 고정된 size로 변환한다. RoI를 추출하는 RoI pooling은 Fast R-CNN에서 설명하고 우선 Spatial Pyramid Pooling을 설명하겠다.

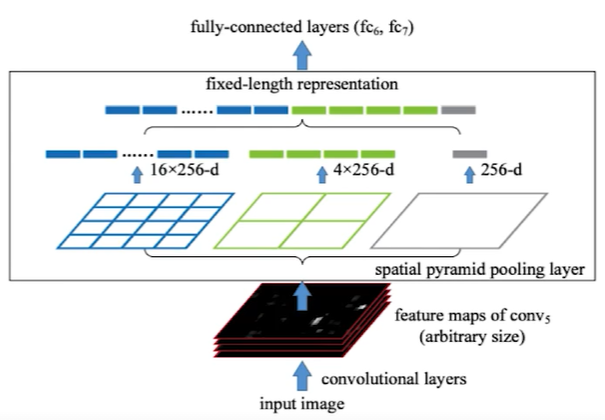
쉽게 생각하면 pyramid의 한 cell을 patch로 생각하여, RoI 영역을 patch 수에 맞게 나누고 pooling을 통해 각 영역의 값을 정한다. 이 후 flatten을 통해 값들을 1차원으로 정렬한다.

spatial pyramid pooling layer는 여러 개의 pyramid를 구성하는 여러 크기의 map들로 구성되어 있고, convolution layer를 통과해 나온 feature map들을 각 pyramid에 넣어 나온 output들을 전부 flatten하여 concatenate하였다. 이렇게 하면 RoI 크기에 상관 없이 pyramid의 크기는 고정되어 있으므로 FC layer를 사용할 수 있다.
Fast R-CNN
RoI Pooling 기법을 사용하여 성능과 속도를 향상시켰다.
- CNN을 통과시켜 feature map을 추출한다.(VGG16 사용)
- RoI Projection을 적용해 RoI들을 feature map에 mapping 시켜준다.
- RoI는 R-CNN과 동일하게 원본 이미지에서 selective search를 통해 추출한다.(feature map에 selective search를 사용하기는 힘들기 때문)
- RoI 영역을 feature map에 mapping 시키는데, 원본 이미지 대비 feature map 크기의 변화에 따라 RoI 영역 크기도 그만큼 변화를 시켜야 한다. pooling이 없어 feature map 크기가 원본 이미지와 동일하면 RoI 크기도 동일하고, 크기가 만약 1/10 으로 줄었다면 RoI 크기도 1/10으로 줄여 projection해야 한다는 의미이다.
- RoI pooling을 통해 일정한 크기의 feature를 추출한다. SPPNet에서 사용한 SPP(Spatial Pyramid pooling)과 동일하며, SPPNet은 1x1, 2x2, 4x4 등의 grid를 썼다면 Fast R-CNN은 7x7 grid 1개만 사용했다는 점이 다르다.
- 이 후 FC layer를 거쳐, Softmax classifier를 통해 class 예측, Bbox regressor를 통해 Bbox 예측을 한다.
Fast R-CNN Training 과정에서,
- multi task loss(classification loss + bounding box regression)을 사용하였다. 이를 통해 selective search를 제외하곤 End-to-End 구조로 구현할 수 있었다.
- loss function으론 classification은 cross entropy, BB regressor는 Smooth L1을 사용하였다. Smooth L1은 L1이나 L2에 비해 outliar에 대해 덜 민감하다.
- IoU > 0.5를 positive sample, 0.1 < IoU < 0.5를 negative sample로 하여, 25% positive sample, 75% negative sample로 Dataset을 구성하였다.
- Hierarchical sampling을 적용하였다. R-CNN의 경우 RoI들을 전부 저장해두고 이로부터 batch를 만들어 학습에 사용했는데, 이 때문에 다른 이미지들의 RoI가 한 batch에 섞이는 경우가 생겼다. Fast R-CNN에선 한 배치에 한 이미지의 RoI만 포함하여 한 배치 내에서 연산과 메모리를 공유할 수 있었다.
selective search를 따로 계산해야 하기 때문에 완벽한 End-to-End는 아닌 모델이다.
Faster R-CNN
Fast R-CNN - selective search + RPN
Fast R-CNN에서 selective search로 region을 추출하던 부분을 제거하고 RPN(Region Proposal Network)를 사용하여 완벽한 End-to-End 구조로 디자인하였다. RPN 또한 하나의 network로서 학습이 가능하다.
RPN에선 Anchor box란 개념을 활용하였다. RoI를 구하기 위해 가장 쉽게 생각하면 CNN을 통과한 feature map의 각 위치마다 box가 하나씩이라고 생각할 수 있는데, 이 경우 다양한 크기에 대응하지 못하고 feature map의 크기로 box size가 고정이 된다. 따라서 각 cell마다 다양한 크기와 비율의 box를 정해두고 사용함으로서 다양한 객체 크기에 대해 대응할 수 있게 된다.
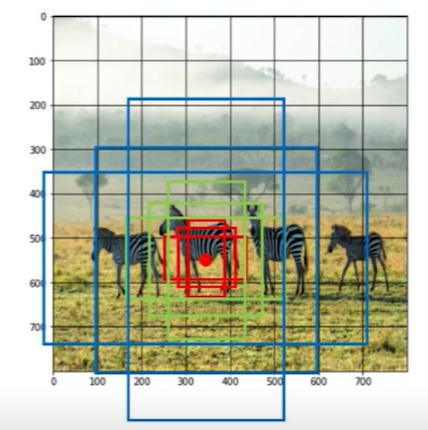
다만 이렇게 되면 각 cell에 대해 k개의 anchor box들을 적용해야 하므로 너무 많은 RoI들이 생길 수 있다. 따라서 RPN에선 anchor box가 객체를 포함하고 있는지 아닌지 판단하고, 포함하고 있다면 객체를 기준으로 얼만큼 이동하고 얼만큼 scale을 조정해야 하는지를 계산한다.
RPN에선 classification head와 coordinate head가 각각 class와 coordinates를 각 feature map의 각 anchor box마다 계산한다.
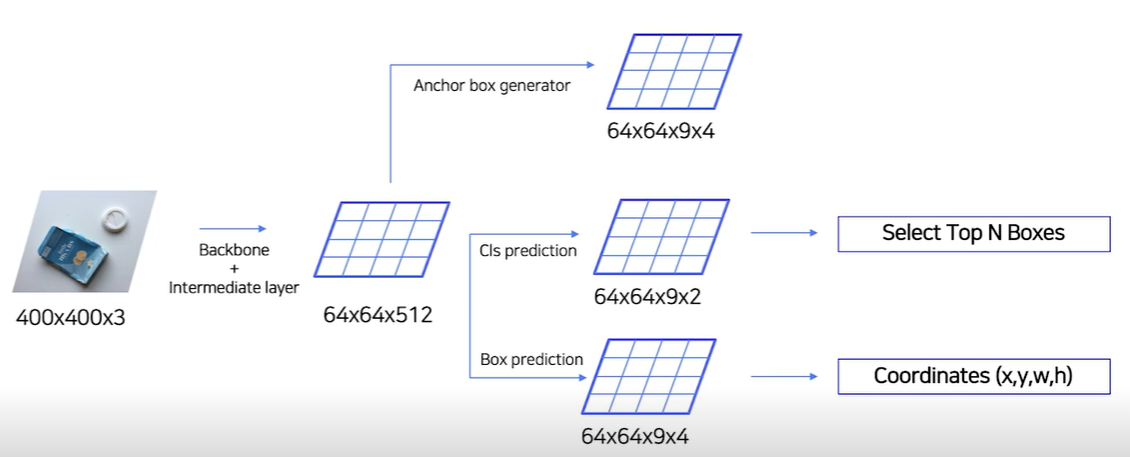
세부적인 RPN의 구조로,
- feature map을 input으로 받아, 3x3 convolution with 512 channels을 수행하여 intermediate layer를 생성한다. channel을 512로 맞춰주는 역할을 한다.
- classification head에서 1x1 convolution with 18 channels을 수행한다. 2(object or not) x 9(num of classes)로 되어 있어, binary classification 역할을 한다.
- bounding box regressor를 위해 1x1 convolution with 36 channels를 수행한다. 4(bounding box) x 9(num of anchors)로 되어 있기 때문에 36 channel이다. num of anchor가 9인 것은 Faster R-CNN 논문에서 서로 다른 모양 3개, 서로 다른 스케일 3개 총 9개의 anchor box를 사용하였기 때문이다.
정리하자면, input image로부터 backbone network와 intermediate layer를 통과해 나온 n x n x 512의 feature map에 대해 Anchor box generator(n x n x 9 x 4, 9: anchor box 수, 4: x,y,w,h)로 anchor box를 구하고, anchor box들을 classification head(n x n x 9 x 2, 9: anchor box 수, 2: object or not)와 coordinates head(n x n x 9 x 4, 9: anchor box 수, 4: x,y,w,h를 각각 얼마나 바꿔야 하는지)를 통과시킨다.
나온 anchor box의 class score를 통해 해당 anchor box가 객체를 포함하고 있을 확률을 알 수 있고, 이를 정렬 해 높은 순서대로 Top N개를 선택할 수 있게 된다.
유사한 RPN Proposal들이 많기 때문에, 비슷한 proposal들은 제거해 줄 필요가 있다. 이를 위해 class score를 기준으로 proposal을 정렬 후, 높은 class score부터 다른 proposal들과 비교하여 IoU가 70% 이상인 경우 제거한다. 이를 NMS라 한다.
요약하자면, backbone network를 통과해 나온 feature map을 RPN에 넣어 region proposal을 얻고 이를 feature map에 투영시킨다. 이 후 과정은 Fast R-CNN과 동일하게 진행한다.
RPN의 training 단계에서,
- 앵커박스를 positive/negative sample 구분을 한다.
- IoU > 0.7이거나 0.7보다 작더라도 highest IoU with GT이면 positive sample이고, IoU < 0.3을 negative sample로 사용하였다. 나머지 경우는 학습데이터로 사용하지 않았다.
논문에 따르면, Fast R-CNN보다 성능이 우수하고 속도도 10배 정도 빠르다. 속도가 빨라진 부분은 region proposal 부분에서 엄청나게 시간 단축을 해서 그렇다.
Faster R-CNN까지 오면서 R-CNN에 비해 성능 및 속도 향상이 많이 있었지만, 2-stage라는 근본적인 특성 상 real-time으로 detection이 가능할 정도의 속도는 나오지 않는다는 한계가 있다.
