AI Tech 2기 활동
1.[Boostcamp AI Tech] 1주차 Day 1 학습기록

벡터 : 공간에서의 한 점을 의미, 원점으로부터의 상대적 위치숫자를 원소로 가지는 list또는 array로 표현가능벡터의 덧셈: 다른 벡터로 부터의 상대적 이동( x+y인 경우, 벡터 y로부터 상대적으로 x만큼 이동)백터의 뺄셈: -x 값을 더한 것으로 이해하면 쉬움,
2.[Boostcamp AI Tech] 1주차 Day 2 학습기록
학습 내용 경사하강법 미분 : 변수의 변화에 따른 함수의 변화량 numpy.diff 를 통해 미분을 컴퓨터로 계산 가능 미분은 그림으로 나타냈을 때, 특정 x 지점에서의 접선의 기울기를 의미 접선의 기울기를 안다 -> 어느 방향으로 움직여야 함수값이 증가
3.[Boostcamp AI Tech] 1주차 Day 3 학습기록
학습 내용 확률론 기계학습에서 사용되는 손실함수(loss function)들은 데이터들을 통계적으로 해석해서 그에 맞게 유도된 함수들이다. ex) 회귀 분석의 L2-norm : 예측오차의 분산을 최소화 -> 데이터를 가장 잘 표현하는 선을 구함 ex) 분류 문제의 cr
4.[Boostcamp AI Tech] 1주차 Day 4 학습기록
시퀀스 데이터 : 순차적으로 들어오는 데이터(소리, 문자열, 주가 등)자기회귀모델(Auto-regressive model)잠재 AR 모델Backpropagation Through Time(BPTT)시퀀스 데이터는 시간 순서의 영향을 받는다.\-> 미래 정보는 과거 정보
5.[Boostcamp AI Tech] 1주차 Day 5 학습기록
이번 주 강의를 다 들어 새로 기록할 만한 내용은 없다.대신 선택과제를 풀려고 노력하며, BPTT에 대해 이해를 높이려 했다.(풀진 못했다...)선택과제의 BPTT 구현에 대해, BPTT 원리와 수식에 대해 팀원분께서 발표해주셨고 서로 질문하며 이해가 정확한지 확인하
6.[Boostcamp AI Tech] 2주차 Day 1 학습 기록
딥러닝을 위해 필요한 스킬 3가지 : 구현능력, 수학(선형대수, 확률, 통계), 논문딥러닝의 4가지 key componentdata(이미지, 말 뭉치 등)model(학습하는 모델)loss function(모델을 학습시킨다)algorithm(loss function을 최
7.[Boostcamp AI Tech] 2주차 Day 2 학습 기록
Optimization 관련 용어가 많으므로 이를 정확히 이해하고 넘어가는게 중요하다.Gradient Descent : 1차 편미분한 값을 빼 loss function을 줄인다.Generalization일반적으로 Training error가 우하향 곡선을 그리더라도,
8.[Boostcamp AI Tech] 2주차 Day 3 학습 기록
Convolution의 의미2D convolution : convolution의 모양을 해당 image에다 찍는다(ex. Blur, Emboss, outline)Convolution의 파라미터 수filter의 크기와 개수만큼 파라미터가 있다.ex. 5 5 3 의 f
9.[Boostcamp AI Tech] 2주차 Day 4 학습 기록
주어지는 모델 자체가 Sequential model이다.말, 비디오, 행동, ...이전 데이터들이 들어왔을 때, 이를 통해 다음 데이터를 예측고려해야 할 이전 데이터가 너무 많다는 게 문제다.\-> 과거의 몇 개만 보겠다 : Fix the past timespanMar
10.[Boostcamp AI Tech] 2주차 Day 5 학습 기록
단순히 image나 sequence를 만들어내는 게 Generative model의 전부는 아니다.Anomaly detection 용으로도 활용 가능(explicit model)Feature learning으로 활용 가능한 것으로 기대Basic Discrete Dist
11.[Boostcamp AI Tech] 3주차 Day 1 학습 기록
Pytorch와 Tensorflow의 주요 차이점Pytorch : Dynamic computation graphBack propagation을 쓸 때 그래프를 생성하는 방식Tensorflow : Define and run그래프를 먼저 정의하고, 실행 시점에 데이터를 넣
12.[Boostcamp AI Tech] 3주차 Day 2 학습 기록
논문을 보다보면 직접 구현해야 할 경우가 있으므로, Autograd, Optimizer 등 Model과 구성 요소들을 직접 구현 할 줄 알아야 한다.Layer는 Block처럼, 하나하나 쌓아서 다음으로 넘긴다고 생각하면 편함.torch.nn.ModuleLayer의 Ba
13.[Boostcamp AI Tech] 3주차 Day 3 학습 기록
과제 양이 너무 많아 과제에 집중하느라, 강의는 제대로 듣지 않았다. 내일 다 듣고 정리할 것어제 과제로 custom model을 만드는 기술을 배웠다면, 오늘은 dataset을 이해하고 custom dataset을 만드는 기술에 대해 실습을 진행했다.각자 과제에서 이
14.[Boostcamp AI Tech] 3주차 Day 4 학습 기록
기존에 만들어진 모델을 가져와 내 데이터에 맞게 수정해서 학습하는 것이 일반적이다.학습 결과를 지속적으로 저장할 필요가 있다남들에게 공유, 특정 환경(colab)에서 학습 내용 증발 방지model.save()모델 architecture와 parameter를 저장할 수
15.[Boostcamp AI Tech] 4주차 Day 1 학습 기록(P-stage)
EDA는 주어진 데이터를 먼저 분석해보는 것.우리는 처음 데이터를 봤을 때 그게 어떤 건지 잘 알지 못하므로, 임의로 데이터가 어떨지 생각해보며 몇개인지, 어떤 label이 있는지, 필요하면 분포가 어떤지 등등 이것저것 볼 수 있다.중복 찾기, 데이터 형태 확인, 목적
16.[Boostcamp AI Tech] 4주차 Day 2 학습 기록
data 전처리의 중요성과 dataset, dataloader를 쓸 때 고려해야 할 사항들을 몇 가지 짚어주셨다.어제에 이어 전체 classification pipeline을 완성하려고 하였다.계속해서 model이 학습이 잘 안되는 문제가 있었다.학습을 진행해도 mod
17.[Boostcamp AI Tech] 4주차 Day 3 학습 기록
data augmentation이나 데이터 전처리를 신경쓰는 게 성능 향상에 중요할 것 같아서 그와 관련해 albumentation을 검색하였다.transform이 단순 이미지 파일의 수를 늘리는 기법은 아니어서 따로 transform을 이용해 이미지를 늘리는 기능을
18.[Boostcamp AI Tech] 4주차 Day 4 학습 기록
금요일에 적는 목요일 기록대회 팀 결성 마감이 오늘까지로 앞당겨지면서, 오늘이 마지막 개인 제출일 이었기 때문에, 최대한 많은 제출을 하면서 변화에 따른 성능 변화를 체감하는 것을 목표로 하였다.구체적으로, Albumentation을 사용하면서, 여러 transform
19.[Boostcamp AI Tech] 4주차 Day 5 학습 기록
모델 제출을 많이 하기도 힘들고 개인 실력과 완성도를 위해 심화된 구현 능력을 기르는 게 맞다고 생각해, 모델을 수정하진 않고 강의에 집중하였다.Lossloss를 어떻게 선택하느냐에 따라 parameter를 update하는 과정도 달라질 것이다.loss function
20.[Boostcamp AI Tech] 5주차 Day 1 학습 기록
주말동안 VS code로 작업할 수 있는 환경 설정만 하고 크게 공부 안하고 푹 쉬었다. 이번 주는 강의 없이 온전히 대회에만 집중할 수 있다. 대회 진행 지난 주까진 팀원 코드 참조도 별로 안하면서 최대한 기초적인 내용을 습득하고 구현해보는 데 집중했다면, 오늘은
21.[Boostcamp AI Tech] 5주차 Day 2 학습 기록
어제 만든 데이터셋을 유지하며, epoch도 조절하고 구현 상 오류(dataset class에서 path를 잘못 주고 있었다...)도 해결하고 노력했지만 모델에 발전이 없었다. 대회 마감이 다가오고 있어서 모델을 제출해 볼 수 없기 때문에(안 내도 예측치가 이상한 게
22.[Boostcamp AI Tech] 5주차 Day 3 학습 기록
대회가 내일까지 임에 따라, 지금까지 팀원들이 제출한 model 중 성능이 좋았던 모델을 몇 개 골라 Ensemble을 진행해봤다.안한 것 보단 Ensemble을 한 게 확실히 Acc, F1 score 모두 조금씩 올랐다. 다만 어떤 모델들을 ensemble 해야 성능
23.[Boostcamp AI Tech] 5주차 Day 4 학습 기록
어제에 이어 오전부터 모여 Ensemble을 진행하고 제출하며 가장 성능이 좋았던 model을 최종 제출하였다.기존 모델에 더해, 기존 모델에 TTA를 진행한 것도 Ensemble 과정에서 선택하여 제출해 보았으나, 큰 성능 향상을 보진 못했다.private datas
24.[Boostcamp AI Tech] [U-stage] 6주차 Day 1 학습 기록
Image Classification 대회가 끝나고 다시 3주간의 U-stage가 찾아왔다.기존의 팀과 작별하고 새로운 팀에 편성되어 새 출발을 하는 느낌이다.AI : 사람의 지능을 컴퓨터로 구현하는 것시각, 언어, 청각...CV : 이미지나 영상으로부터 현실의 정보
25.[Boostcamp AI Tech] [U-stage] 6주차 Day 2 학습 기록
일반적으로 더 깊은 network가 더 좋은 성능을 보여준다.더 복잡한 feature를 학습 가능하다.Larger receptive field를 가진다.non-linearity를 더 가진다.하지만 무작정 layer를 많이 쌓으면 학습이 잘 안된다.Gradient van
26.[Boostcamp AI Tech] [U-stage] 6주차 Day 3 학습 기록
오늘은 새로 나온 강의는 없어서 어제 피어 세션 때 얘기했던 CutMix, Softmax의 soft labeling, CE와 KL-divergence에 대해 조사하였다.각 class의 이미지 두 장을 mix하는 기법 중 하나한 image의 random 부분을 crop한
27.[Boostcamp AI Tech] [U-stage] 6주차 Day 4 학습 기록
28.[Boostcamp AI Tech] [U-stage] 6주차 Day 5 학습 기록
Object detection은 Semantic segmentation, Instance segmentation, Panoptic segmetation을 위해 필요한 근본적인 기술이다.Object detection : Classification + Box localiz
29.[Boostcamp AI Tech] [U-stage] 7주차 Day 1 학습 기록
CNN은 blackbox system이다 : 학습을 통해 사람이 표현하기 힘든 복잡한 구조를 가진다.CNN Visualization을 통해 CNN에 대한 다양한 정보를 알 수 있다.어떤 식으로 동작하는지어떤 식으로 개선하면 좋을지ZFnet : CNN visualizat
30.[Boostcamp AI Tech] [U-stage] 7주차 Day 2 학습 기록
강의를 들은 건 없고 하루 종일 선택과제만 풀었던 하루였다.CNN visualization에 대한 실습이었다.강의 때 배운 방법들로 지난 P-stage 대회 때 사용한 dataset에 대해 visualization을 해봤으며, grad-CAM도 다뤘다.img의 차원 관
31.[Boostcamp AI Tech] [U-stage] 7주차 Day 3 학습 기록
앞에서 배운 semantic segmentation, object detection 분야는 2018년 이후로 연구가 딱히 진행되고 있지 않다. 이는 더 좋은 기술인 Instance segmentation과 panoptic segmentation이 나왔기 때문이다.Ins
32.[Boostcamp AI Tech] [U-stage] 7주차 Day 4 학습 기록
modal : 하나의 데이터 특성을 의미? 시각, 청각, 언어 등..multi-modal : 여러 형태의 데이터를 사용해 학습하는 방법multi modal로 학습하는 데 어려운 점데이터 형태가 전부 다 다르다.데이터의 feature space간 unbalance가 존재
33. [Boostcamp AI Tech] [U-stage] 7주차 Day 5 학습 기록
우리는 3D 세계에서 살고 있기 때문에 3D 공간을 이해하는 것이 굉장히 중요하다.활용 applicationAR, VR3D printingMedical, chemical application우리가 보는 사진은 3D를 2D로 projection 한 것이다.3D data
34.[Boostcamp AI Tech] 8주차 Day 1 학습 기록
이번 주는 추석 연휴 때문에 이틀 밖에 없어서인지 특강으로만 구성되어 있다. 마음 편하게 들으면서 알아두면 좋을 내용들 위주로 정리하였다.강연자 : 이활석 Upstage CTO님일반적으로 수업/학교/연구에서는 정해진 Dataset/Evaluation 방식 에서 더 좋은
35.[Boostcamp AI Tech] 8주차 Day 2 학습 기록
당일 날 백신 1차 접종을 맞아서 컨디션이 좋지 않아 강의를 제대로 듣지 못했다. 포괄적인 내용만 정리했다.Full stack ML engineer란 Deep learning research를 이해하고 이를 활용해 ML product를 만들 수 있는 엔지니어를 의미한다
36.[Boostcamp AI Tech] [P-stage] 9주차 Day 1 학습 기록
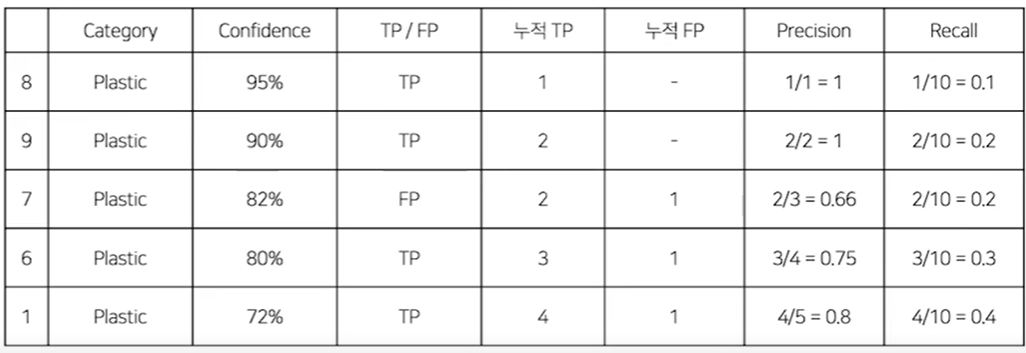
Object detection overview mAP(mean average precision) 각 클래스당 AP의 평균 precision $precision = \frac{TP}{TP+FP} = \frac{TP}{All detections}$ recall $
37.[Boostcamp AI Tech] [P-stage] 9주차 Day 2 학습 기록
강의 내용 2 Stage Detectors 2 Stage Detector 구조는 입력 이미지에 대해 먼저 물체의 위치를 특정하는 Localization을 진행하고, 해당 영역의 class를 지정하는 식으로 되어 있다. 사람으로 비교하면 물체 영역을 보는 것과 물체 이름
38.[Boostcamp AI Tech] [P-stage] 9주차 Day 3 학습 기록
Object detection library는 하나로 통합되어 있진 않고 여러 개의 라이브러리가 사용되고 있다. 그 중에서 주로 활용되는 두 라이브러리가 MMDetection, Detectron2 이다.MMDetection은 Pytorch 기반의 detection 오픈
39.[Boostcamp AI Tech] [P-stage] 9주차 Day 4 학습 기록
Neck은 Backbone과 RPN 사이에 위치하여 특정 작업을 수행하는 network를 의미한다.지난 Faster R-CNN까지를 돌이켜보면, Backbone network를 통과해 나온 Feature map은 RPN에 들어가 RoI를 추출해내고, 이를 Head(cl
40.[Boostcamp AI Tech] [P-stage] 9주차 Day 5 학습 기록
학습 내용 1 Stage Detectors 기존 2 Stage Detector(Fast R-CNN 시리즈,
41.[Boostcamp AI Tech] 9주차 주간학습기록
월요일 : https://velog.io/@bluegun/Boostcamp-AI-Tech-P-stage-9%EC%A3%BC%EC%B0%A8-Day-1-%ED%95%99%EC%8A%B5-%EA%B8%B0%EB%A1%9D화요일 : https://velog
42.[Boostcamp AI Tech] [P-stage] 10주차 Day 1 학습 기록
학습 내용
43.[Boostcamp AI Tech] [P-stage] 10주차 Day 2 학습 기록
classification 문제와 다른 점이 많아 모델을 어떤 식으로 개선하면 더 성능이 좋겠다는 직관적인 생각이 잘 떠오르지 않았다. 예를 들어 classifcation 문제는 결국 최종 output이 class 1개만 나오기 때문에 이를 비교해가며 어느 class를
44.[Boostcamp AI Tech] [P-stage] 10주차 Day 3 학습 기록
학습 내용 현재까지 알게 된 것 대회 특성상 mAP가 높을수록 점수가 높기 때문에, Faster R-CNN처럼 Bbox를 많이 예측하는 게 점수가 높게 나온다. 이런 점에서 Cascade R-CNN은 high quality box를 추출하기 때문에 점수가 낮게 나오는
45.[Boostcamp AI Tech] [P-stage] 10주차 Day 4 학습 기록
대회 진행 내용(무엇을 알게 됐나요?)
46.[Boostcamp AI Tech] [P-stage] 10주차 주간 학습 정리
월 :
47.[Boostcamp AI Tech] [P-stage] 11주차 Day 1 학습 기록
대회 진행 상황
48.[Boostcamp AI Tech] [P-stage] 11주차 Day 2 학습 기록
대회 진행 상황
49.[Boostcamp AI Tech] [P-stage] 11주차 Day 3 학습 기록
대회 진행 상황
50.[Boostcamp AI Tech] [P-stage] 11주차 Day 4 학습 기록 - 대회 회고
회고
51.[Boostcamp AI Tech] [P-stage] 12주차 Day 1 학습 기록
EfficientUNet을 설치하여 EfficientUNet-b5 모델로 돌려보았으나 모델이 background만 보는 문제가 발생하였다. 데이터 비중이 높은 plastic bag나 background만 집중적으로 예측하도록 학습되었기 때문에 발생한 결과이고, 이렇게
52.[Boostcamp AI Tech] [P-stage] 12주차 Day 2 학습 기록
강의 내용 대회 진행 상황
53.[Boostcamp AI Tech] [P-stage] 12주차 Day 3 학습 기록
요약 배운 내용 DeconvNet SegNet 학습 내용 대회 진행 상황
54.[Boostcamp AI Tech] [P-stage] 12주차 Day 4 학습 기록
대회 진행 상황
55.[Boostcamp AI Tech] [P-stage] 12주차 Day 5 학습 기록
대회 진행 상황
56.[Boostcamp AI Tech] [P-stage] 12주차 주간학습정리
느낀 점
57.[Boostcamp AI Tech] [P-stage] 13주차 Day 1 학습 기록
배운 강의 내용HRNet대회 진행 상황HRNet 구현 시도 -> 아직 성공 못함이번 주에 제공된 강의가 HRNet이어 수강하였고, 강의에서 HRNet의 주 아이디어가 고해상도를 유지함으로서 위치 정보를 더 잘 저장하는 것이라 하였고, 이 점이 현재 대회 데이터셋에 적합
58.[Boostcamp AI Tech] [P-stage] 13주차 Day 2 학습 기록
계속해서 HRNet OCR을 해보려고 시도했지만 가져오는 게 잘 되지 않았다. 그리고 HRNet을 써도 생각보다 성능이 많이 안 오른다는 얘기가 있어 우선 순위를 내려야 할 것 같다고 생각했다.팀원들이 MMSegmentation 라이브러리를 활용중인데, 이 중 Swin
59.[Boostcamp AI Tech] [P-stage] 13주차 Day 3 학습 기록
팀원들은 현재까지 학습한 Swin 모델들을 단순한 Augmentation만으로 성능을 끌어올리는 데 한계가 왔다고 판단하셨고, 지금 모델로도 0.7 이상의 score가 나오고 있기 때문에 이를 활용해 Pseudo labeling을 진행하기로 하셨다.나는 이를 도움과 동
60.[Boostcamp AI Tech] [P-stage] 13주차 Day 4 학습 기록
오늘은 비염이 심해지고 머리가 많이 아파 작업은 별로 하지 못하고 많이 쉬었던 하루였다.팀원분들이 Pseudo labeling을 위해 output image와 mask를 저장하고 각 category별로 분류하는 코드를 만들어 각자 결과물을 만들고 계시다고 하셔서, 이미
61.[Boostcamp AI Tech] [P-stage] 13주차 Day 5 학습 기록
train data mask visualizing 작업을 거의 다 한 것 같은데, image별 mask를 생성하는 과정에서 자꾸 막히고 있다. 머리로는 돼야 할 것 같은데 자꾸 논리적으로 오류가 나는 게 알고리즘 문제를 푸는 느낌이 많이 났고, 논리력을 많이 길러야겠다
62.[Boostcamp AI Tech] [P-stage] 13주차 주간 학습정리
월 : https://velog.io/@bluegun/Boostcamp-AI-Tech-P-stage-13%EC%A3%BC%EC%B0%A8-Day-1-%ED%95%99%EC%8A%B5-%EA%B8%B0%EB%A1%9D화 : https://velog.io
63.[Boostcamp AI Tech] [P-stage] 14주차 Day 1 학습 기록
대회 진행 상황
64.[Boostcamp AI Tech] [P-stage] 14주차 Day 2 학습 기록
팀 내에서 성능이 가장 좋은 모델 3개에서 Inference를 진행하고, 이를 활용해 test data image와 prediction mask를 추출하는 코드를 팀원께서 작성해주셔서, 이를 활용해 뽑아낸 각 category별 image들을 다 같이 정리하였다. 최대한
65.[Boostcamp AI Tech] [P-stage] 14주차 Day 3 학습 기록
Ensemble에 대해 조사해봐야 했지만, 주중에 다른 일이 생겨 많이 조사하지는 못했다.일단 soft voting을 하려면 팀원들이 모델 output을 수정하여야 해 번거롭기도 하고, segmentation 특성상 모델 3개 이상이면 hard voting으로도 어느정
66.[Boostcamp AI Tech] [P-stage] 14주차 Day 4 학습 기록
Ensemble은 Hard voting을 활용하기로 하였다. 어제 생각한 대로 Hard voting으로도 성능 향상을 기대해 볼 수 있다 생각했고, soft voting을 하기에는 팀원들께서 여유가 없어 부탁드리기 힘들었다.Hard voting 방법으론 모델 3개를 사
67.[Boostcamp AI Tech] [P-stage] 14주차 Day 5 대회 회고
주제 : 10가지 재활용 품목 분류를 위한 Object Setection 모델 개발사용한 방법Swin HTC, UPerNet 모델을 EnsemblePseudo labeling, Test Time Augmentation으로 성능 향상지난 Detection 대회를 진행한
68.[Boostcamp AI Tech] [데이터 제작] 15주차 Day 1 학습 기록
요약 배운 강의 내용 강의 내용 최종 프로젝트 준비
69.[Boostcamp AI Tech] [데이터 제작] 15주차 Day 2 학습 기록
말곤 무엇을 했나요?
70.[Boostcamp AI Tech] [데이터 제작] 15주차 Day 3 학습 기록
요약 무엇을 했나요? 최종 프로젝트 관련 조사 가능할 만한 주제 : OCR, 시각 장애인 보행보조, 자율주행, ... 활용 가능한 데이터셋 : AI Hub에서 사용가능 무엇을 했나요? 대회는 내일부터 열리고 강의는 어제 다 들었기에 오늘은 어제에 이어 Annotation 실습을 몇 장 더 진행하고 최종 프로젝트로 무엇을 할 지, 어떻게 할 지에...
71.[Boostcamp AI Tech] [데이터 제작] 15주차 Day 4 학습 기록
요약 대회 진행 상황 Baseline 코드 분석 캠퍼들이 제작한 Annotation 데이터셋 합치기 + EDA 필요 무엇을 했나요? 오늘부터 대회가 시작되어 baseline 분석부터 시작하였다. 기존의 대회와는 다르게 xml파일을 읽어오고 EAST 모델을 사용하여서 이에 맞게 전처리를 하는 과정이 있어, 오늘 안에 이해하기는 쉽지 않았다. 코드는 수시로 ...
72.[Boostcamp AI Tech] [데이터 제작] 15주차 Day 5 학습 기록
요약 무엇을 했나요? 최종 프로젝트 주제 고민 -> OCR 힘들듯, 시각 장애인 Task 데이터셋 발견 계속 baseline 분석, XML 파일을 못찾아 제출을 못하는중 무엇을 했나요? 대회 baseline을 계속 분석하는데, EAST 모델을 이해하기가 어렵다. 시간이 많이 걸릴 것 같아 포기하고 대략 전체 구조만 이해하는 데 시간을 투자했다. 데이터셋 ...
73.[Boostcamp AI Tech] [데이터 제작] 16주차 주간학습정리
1주 동안 최종 프로젝트 주제 선정과 세부 목표를 설정하는 데 스트레스도 받고 뭐라도 해야하는데 아무것도 하기 싫은 상태가 이어져 한 주 동안 학습을 많이 진행하지 못했고 일일 회고도 하지 못했다. 일일 회고를 지키기 못한 점은 아쉽지만 앞으로 부스트캠프가 끝날 때 까지라도 회고를 매일 할 수 있도록 다시 노력해야겠다. 무엇을 했나요? 최종 프로젝트 시각...
74.[Boostcamp AI Tech] [모델 최적화] 17주차 Day 1 학습 기록
요약 강의 내용 간단한 대회 소개 및 최적화, AutoML 이론 최종 프로젝트 각자 EDA한 자료들 정리할 방법 의논 stratified dataset 가능한지 의논 무엇을 했나요? 대회 최적화 대회가 시작되었다. 최적화 대회의 목표는 성능과 속도를 종합해 일정 기준 치를 넘는 것으로, 둘 다 고려해야 한다는 점이 주요 포인트 같다. 아직 어떤 식으로 최...
75.[Boostcamp AI Tech] [모델 최적화] 17주차 Day 2 학습 기록
강의 내용경량화 : On-device로 낮은 사양의 기기에서 모델을 돌릴 수 있게 하거나, 비슷한 성능을 더 적은 자원으로 사용할 수 있게 함.경량화 종류 : AutoML, Pruning, KD, Quantization...피어세션최종 프로젝트 역할 분담 -> 나는 모
76.[Boostcamp AI Tech] [모델 최적화] 17주차 Day 3 학습 기록
요약 강의 내용 AutoML AutoML 라이브러리인 Optuna에 대한 코드 및 실습 무엇을 했나요? baseline 코드에 Optuna를 적용시킬 방법 연구 피어 세션 기업 파트너 ART Lab 발표세션 내용 공유 데이터의 중요성 DEVIEW 얘기 최종 프로젝트 client 관련 대화 강의 내용 AutoML 기존의 ML 학습 방법 : Mode...
77.[Boostcamp AI Tech] [모델 최적화] 17주차 Day 4 학습 기록
무엇을 했나요?제공받은 Optuna + baseline 코드를 보면서 Optuna의 활용 방식과, Optuna 라이브러리의 이해를 위해 Reference 및 Github에서 코드 분석피어 세션분석한 Optuna baseline 코드를 다른 팀원들에게 설명어제 혼자서는
78.[Boostcamp AI Tech] [모델 최적화] 17주차 Day 5 학습 기록
요약 무엇을 했나요? 마스터님의 대회 조언을 보고 trial의 수와 epoch 수를 줄이고 hyperparameter를 고정하여, 모델 변화에 따른 차이만 두고 학습 진행중 코드 분석 및 Optuna tutorial을 참고하며 해야 할 일 정리(DB 연동, Pruning 적용, Visualizing 적용, early stopping 적용) 무엇을 했나요?...
79.[Boostcamp AI Tech] [모델 최적화] 18주차 Day 1 학습 기록
요약 무엇을 했나요? 주말동안 서버에 PostgreSQL 설치 후 Optuna와 연동 -> study를 DB에 저장하고 load하여 기존 trial에 이어서 trial 가능! Optuna visualization 시도 -> 뭔가 에러가 나옴(zero weight), 해결 못함 Trial 중 mean time이 가장 낮은 모델의 파라미터를 대입해 yaml 파...
80.[Boostcamp AI Tech] [모델 최적화] 18주차 Day 2 학습 기록
요약 무엇을 했나요? 어제 학습한 모델 제출 -> 속도는 조금 느려졌지만 더 높은 성능의 모델 depth 파라미터를 최대치로 고정시키고 optuna optimize -> 기존과 성능은 큰 차이 없는데 파라미터 수만 엄청 늘어나서 중지 기존 trial 중 현재 모델과 비교해 조금 느리지만 성능이 좋게 나온 파라미터로 재학습 무엇을 했나요? 일어나서 어제 ...
81.[Boostcamp AI Tech] [모델 최적화] 18주차 Day 3 학습 기록
요약 무엇을 했나요?
82.[Boostcamp AI Tech] [모델 최적화] 18주차 Day 4 학습 기록
요약 무엇을 했나요?
83.[Boostcamp AI Tech] [모델 최적화] 18주차 Day 5 대회 회고
84.[Boostcamp AI Tech] [Product Serving] 19주차 Day 1 학습 기록
드디어 마지막 stage인 Product serving에 도달하게 되었다. 이전부터 자주 글로 소통하시던 마스터님이셔서 그런지 강의도 엄청나게 많고 내용도 많아보였다. 최종 프로젝트와 같이 병행해야 해서 모든 지식을 습득할 수 있을 지 걱정되지만, 두 마리 토끼 다 잡도록 노력하자. 요약 강의 듣는 거 보단 최종 프로젝트부터 진행하는게 좋다고 판단함. ...
85.[Boostcamp AI Tech] [Product Serving] 19주차 Day 2 학습 기록
요약 오늘도 강의 대신 최종 프로젝트에 집중했다. 무엇을 했나요? 어제까지 완료한 Pytorch to ONNX 작업에 이어, ONNX 파일을 Tensorflow를 거쳐 TFLite로 변환하는 코드 작성 무엇을 했나요? 어제에 이어 Pytorch 모델을 .tflite 파일로 변환하는 작업을 완료하였다. Pytorch model -> ONNX -> Ten...
86.[Boostcamp AI Tech] [Product Serving] 19주차 Day 3 학습 기록
요약 Pytorch to TFLite 변환 성공(.tflite 파일 추출), 앱 개발 파트에 넘겼으나 dimension error가 났음. 무엇을 했나요?
87.[Boostcamp AI Tech] [Product Serving] 19주차 Day 4 학습 기록
요약 하루종일 Input dimension 바꿀 방법 찾는데 못하고있음 Pytorch to ONNX : ONNX로 변환할 때 방법이 일단 Pytorch 모델을 한 번 Inference하고 그 과정을 Graph로 기록하는 것이기에, Pytorch 모델에 맞는 Input shape을 넣어줘야 가능함. ONNX to Tensorflow : 변환 함수에 Axis...