https://arxiv.org/abs/2304.07193
1. Introduction
Foundation Models in NLP and Computer Vision
- Foundation models: NLP에서 task-agnostic pretrained representations의 표준으로 자리 잡음
- 다양한 다운스트림 작업에서 finetuning 없이도 task-specific 모델보다 뛰어난 성능 달성
- 대량의 원시 텍스트 데이터로 language modeling, word vectors 같은 pretext objectives를 활용해 사전 학습
- 감독 학습 없이도 풍부한 feature 학습 가능
- 컴퓨터 비전에서도 유사한 foundation models 등장 기대
- 이미지 수준(예: image classification)과 픽셀 수준(예: segmentation) 작업에서 즉시 사용 가능한 visual features 생성 목표
- 텍스트 기반 사전 학습이 주류, 텍스트 감독으로 feature 학습 유도
- 그러나 텍스트 캡션은 이미지의 풍부한 정보를 근사적으로 표현, 복잡한 픽셀 수준 정보 포착 한계
- 이미지-텍스트 정렬 데이터 필요, 원시 데이터만으로 학습하는 NLP 모델의 유연성 부족
Self-Supervised Learning as an Alternative
- Self-Supervised Learning (SSL): 이미지 단독으로 feature 학습, language modeling과 개념적으로 유사
- 이미지 및 픽셀 수준 정보 포착 가능
- SSL 특징은 다양한 유용한 속성 보여, 다수 응용 분야 활성화
- 예: 이미지 이해, segmentation, 3D 이해, 비디오 처리, 로보틱스
- 기존 SSL 연구는 주로 ImageNet-1k 같은 소규모 curated 데이터셋에 초점
- 대규모 uncurated 데이터셋으로 확장 시도 있었으나, 데이터 품질과 다양성 제어 부족으로 feature 품질 저하
- 데이터 품질과 다양성은 우수한 visual features 생성에 필수
Objectives of This Work
- 대규모 curated 데이터로 SSL의 general-purpose visual features 학습 가능성 탐구
- 기존 discriminative SSL 접근법 재검토, 특히 iBOT 같은 이미지 및 패치 수준 feature 학습 방법
- 대규모 데이터셋 환경에서 설계 선택 재고
- 기술적 기여
- 모델 및 데이터 크기 스케일링 시 discriminative SSL의 안정성과 속도 개선
- 약 2배 빠른 학습 속도, 3배 적은 메모리 사용으로 기존 SSL 방법 대비 효율성 증대
- 더 긴 학습과 큰 배치 크기 활용 가능
- Data curation
- NLP에서 영감 받은 자동 파이프라인 구축, 외부 메타데이터 없이 데이터 유사성 활용
- 수동 주석 없이 uncurated 이미지에서 데이터 필터링 및 재균형
- 데이터 다양성 확보 및 dominant modes로의 overfitting 방지 위해 naive clustering 접근법 채택
- 1억 4200만 이미지로 구성된 소규모이지만 다양한 데이터 corpus 수집
- DINOv2 Model Family
- 다양한 Vision Transformer (ViT) 아키텍처로 DINOv2 사전 학습
- 모든 모델과 재학습 코드 공개
- 이미지 및 픽셀 수준 컴퓨터 비전 벤치마크에서 DINOv2 성능 검증
- SSL 단독으로 weakly-supervised 모델과 경쟁 가능한 transferable frozen features 학습 가능성 입증
2. Related Work
Intra-Image Self-Supervised Learning
- Intra-image pretext tasks: 이미지 내 신호 추출해 나머지 이미지로 예측하는 self-supervised 방법
- 패치의 context 예측으로 시작, 이후 다양한 pretext tasks 개발
- 예: 이미지 recolorizing, transformation 예측, inpainting, patch re-ordering
- ViT와 inpainting: 패치 기반 ViT 아키텍처 등장으로 inpainting 재조명
- Masked Auto-Encoder (MAE): 마스크된 이미지 영역 재구성, 다운스트림 작업 finetuning 시 성능 향상
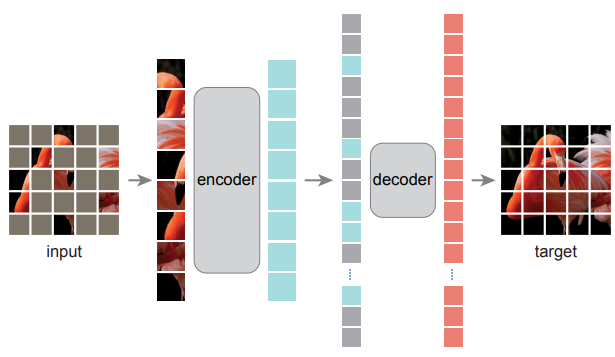
- MAE는 비디오, 오디오, 기타 modality로 확장, 다운스트림 작업에서 강력한 초기화 제공
- 그러나 MAE 특징은 감독 finetuning 필요, 본 연구는 finetuning 없이 즉시 사용 가능한 feature 목표
Discriminative Self-Supervised Learning
-
Discriminative signals: 이미지 또는 이미지 그룹 간 차별적 신호로 feature 학습
- 초기 딥러닝 연구에서 시작, instance classification 기법으로 인기
- Instance-level objectives 및 clustering 기반 개선
- ImageNet 같은 표준 벤치마크에서 frozen features로 우수한 성능
- 대규모 모델로 확장 시 어려움, 본 연구는 대규모 데이터셋과 모델 환경에서 학습 재검토
- iBOT 기반 구축, 스케일링에 적합한 설계 선택
Scaling Self-Supervised Pretraining
- Scaling efforts: 데이터와 모델 크기 스케일링에 초점
- 대량의 uncurated 데이터로 감독 없이 모델 학습
- Discriminative 방법은 데이터 스케일링에 따라 성능 향상, 그러나 데이터 품질 저하로 finetuning 필요
- 충분한 사전 학습 데이터로 모델 크기 스케일링 시 이점 확인
- 본 연구는 최적의 pretrained encoders 생성에 집중, 데이터 품질과 다양성 관리로 성능 극대화
Automatic Data Curation
- Data curation 접근법: 이미지 검색 커뮤니티에서 영감
- Retrieval 기반으로 학습 데이터 증강, semi-supervised learning 맥락에서 연구
- 해시태그, 메타데이터, pretrained vision encoders로 uncurated 데이터 필터링 사례
- 본 연구는 pretrained encoders, 메타데이터, 감독 없이 이미지 간 visual similarity 활용
- NLP 텍스트 큐레이션 파이프라인에서 영감, Wikipedia로 학습된 언어 모델로 uncurated 텍스트 점수화
- 유사하게 이미지 데이터 필터링 및 재균형, 수동 주석 없이 데이터 품질과 다양성 확보
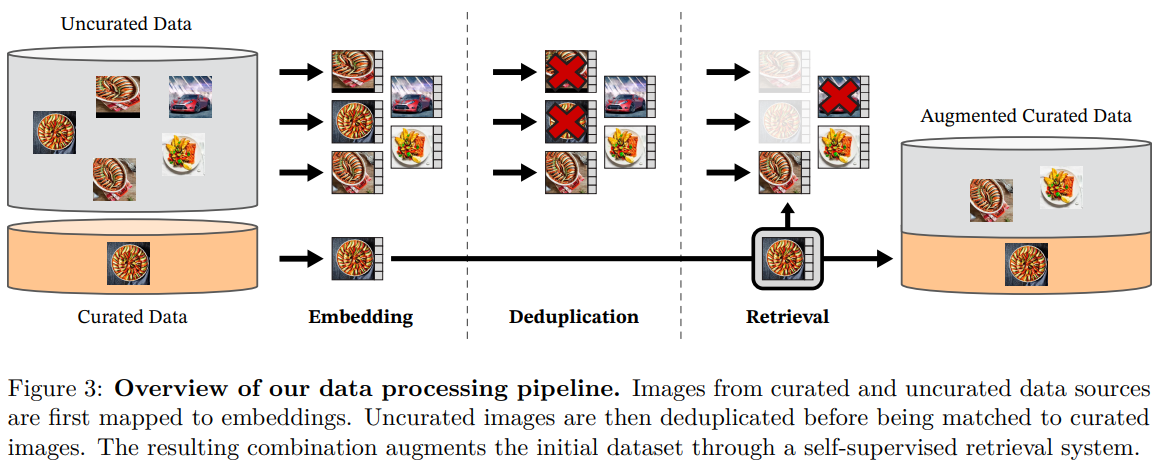
3. Data Processing
Data Sources
- Curated 데이터셋 구축: LVD-142M 데이터셋, 대규모 uncurated 데이터 풀에서 curated 데이터셋과 유사한 이미지 검색
- Curated 데이터셋: ImageNet-22k, ImageNet-1k 학습 분할, Google Landmarks, 다수 fine-grained 데이터셋 포함
- Uncurated 데이터: 공개 웹 크롤링 저장소에서 원시 이미지 수집
- 웹 페이지 img 태그에서 이미지 URL 추출
- 안전하지 않은 URL 및 제한된 도메인 제외
- 다운로드 이미지 후처리: PCA hash deduplication, NSFW 콘텐츠 필터링, 얼굴 식별 블러 처리
- 결과: 12억 개 고유 이미지 확보
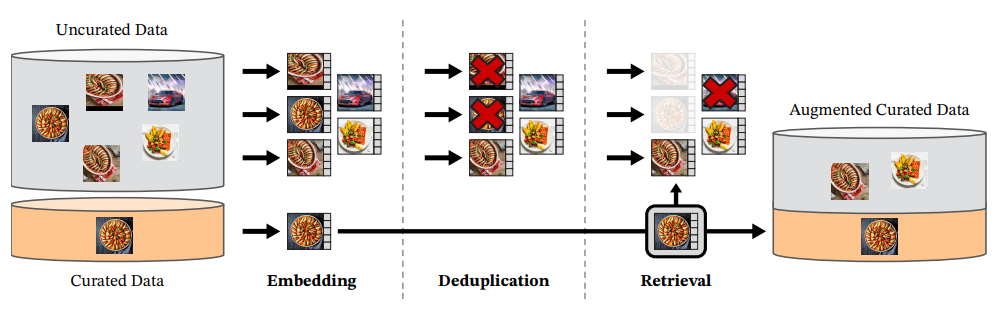
Deduplication
- 중복 제거 파이프라인: Uncurated 데이터에서 근사 중복 이미지 제거
- 데이터 redundancy 감소, 이미지 다양성 증대
- 벤치마크 테스트/검증 세트와 근사 중복 이미지 제거, 평가 공정성 보장
- 고품질 데이터셋 구축으로 학습 효율성 향상
Self-Supervised Image Retrieval
- 검색 기반 큐레이션: Curated 데이터와 유사한 이미지로 LVD-142M 구성
- ImageNet-22k로 사전 학습된 self-supervised ViT-H/16 네트워크로 image embeddings 생성
- Cosine similarity로 이미지 간 거리 측정
- Uncurated 데이터에 k-means clustering 적용
- 검색 전략
- 대규모 쿼리 데이터셋: 각 쿼리 이미지당 4 nearest neighbors 검색
- 소규모 쿼리 데이터셋: 쿼리 이미지의 클러스터에서 M개 이미지 샘플링
- N=4 선택으로 검색 품질과 collisions 간 균형 유지
- Visual inspection으로 검색 품질 검증
Implementation Details
- 효율적 데이터 처리: Faiss 라이브러리 활용, GPU 가속 inverted file indices와 product quantization codes 사용
- 대규모 배치 검색 최적화
- 20개 노드, 각 8개 V100-32GB GPU로 분산 처리
- LVD-142M 데이터셋 생성에 2일 미만 소요
- 메타데이터나 텍스트 없이 이미지 기반 처리, NLP 스타일 데이터 큐레이션에서 영감
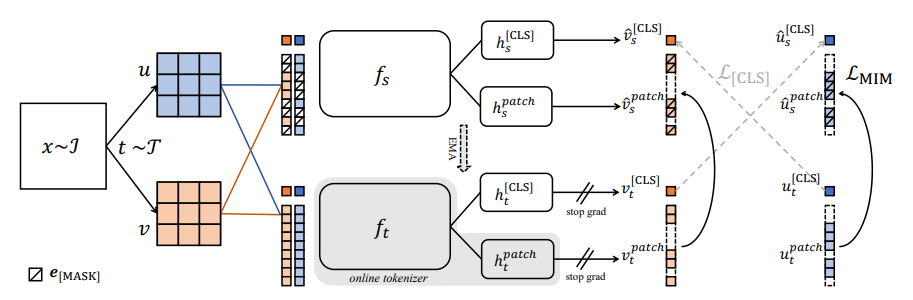
4. Discriminative Self-Supervised Pre-Training
Learning Objectives
- Discriminative SSL 전략: DINO와 iBOT Loss 결합, SwAV의 centering 기법 통합
- KoLeo regularizer로 feature 분포 균일화
- High-resolution 학습 단계로 픽셀 수준 작업 성능 강화
- 상세 구현은 공개 코드 참조
Image-Level Objective
-
DINO loss: Student와 teacher 네트워크의 class token 간 cross-entropy loss
- 동일 이미지의 서로 다른 crop에서 feature 추출
- Student class token은 MLP 기반 DINO head로 prototype scores 생성, softmax 적용해 계산
- Teacher class token은 DINO head로 prototype scores 생성, softmax와 Sinkhorn-Knopp centering 적용해 계산
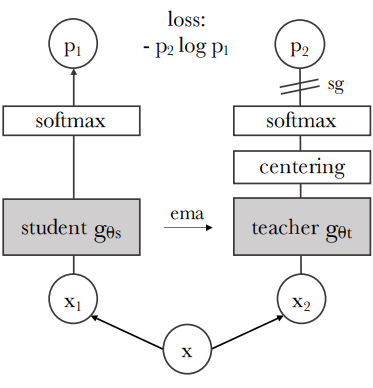
- Loss function:
- Student 매개변수 학습, teacher head는 exponential moving average로 갱신
Patch-Level Objective
- iBOT loss: Student 입력 패치 일부 무작위 마스크, teacher는 마스크 없이 처리
- Student iBOT head로 마스크된 패치 토큰 처리
- Teacher iBOT head로 student의 마스크된 패치에 대응하는 teacher 패치 토큰 처리
- Softmax와 centering 적용
- Loss function:
- i는 마스크된 패치 인덱스
- Student 매개변수 학습, teacher head는 exponential moving average로 갱신
Untying Head Weights
- 독립 head 사용: DINO와 iBOT Loss에 별도 MLP projection head 적용
- 소규모 데이터셋에서는 공유 head가 유리하나, 대규모 학습에서는 별도 head가 성능 우수
- 모든 실험에서 독립 head 사용, 작업별 최적화로 성능 향상
Sinkhorn-Knopp Centering
- Centering 개선: DINO와 iBOT의 teacher softmax-centering을 Sinkhorn-Knopp batch normalization으로 대체
- Sinkhorn-Knopp Centering?
- 정규화 기법으로, SSL 과정에서 모델 출력(Feature 분포)을 더 안정적이고 균일하게 만들어주는 역할
- 즉, 모델이 이미지를 처리할 때 출력되는 특징(feature)들이 특정 방향으로 치우치지 않고, 고르게 퍼지도록 조정하는 역할
- 이 과정은 특히 대규모 데이터셋에서 학습할 때 중요한데, 특징들이 너무 한쪽으로 쏠리면 모델이 특정 패턴에 과적합될 위험이 있기 때문
- 3회 반복 SK 알고리즘 적용
- 수학적으로는 행렬 정규화를 통해 Feature 분포를 "균일화"
- 이를 위해 Sinkhorn-Knopp 알고리즘은 반복적으로 행과 열을 정규화해서 분포가 안정되도록 만듦
- Student는 softmax normalization 유지
- SK centering으로 feature 안정성 강화, 대규모 데이터셋에서 효과적
- Sinkhorn-Knopp Centering?
KoLeo Regularizer
- KoLeo?
- Kozachenko-Leonenko 엔트로피 추정기를 기반으로 설계된 정규화 항(term)
- 이 정규화는 Feature 벡터들이 서로 너무 가깝게 뭉치지 않고, 최대한 균일하게 분포하도록 만듦
- 배치 내 특징의 균일한 분포 유도
- n개 벡터 에 대해 Loss:
- 는 와 배치 내 다른 점 간 최소 거리
- Feature 계산 전 -normalization 적용
- KoLeo로 feature 다양성 증대, 과적합 방지, 일반화 성능 개선
두 방법의 의미
- KoLeo와 Sinkhorn-Knopp Centering은 함께 사용되며, 두 기법 모두 Feature 분포를 안정화하고 균일화하는 데 기여하지만, KoLeo는 특히 Feature 벡터 간의 공간적 분포에 초점을 맞춤
- Sinkhorn-Knopp는 출력 확률 분포를 정규화하고, KoLeo는 Feature 벡터 자체의 분포를 균일화
High-Resolution Adaptation
- 해상도 조정: segmentation, detection 등 픽셀 수준 작업에 필수
- 고해상도 학습은 메모리와 시간 소모 크므로, 사전 학습 마지막에 518×518 해상도 단기 학습
- 세부 공간 정보 포착으로 다운스트림 작업 성능 향상
- 학습 효율성과 고해상도 성능 간 균형 유지 (아래 Fig. 4)

Combined Objective
- 최종 Loss: DINO, iBOT, KoLeo Loss 통합
- Loss function:
- 로 KoLeo 기여도 조정
- DINO는 image-level feature, iBOT는 patch-level feature, KoLeo는 feature 분포 균일화
- Frozen features로 다운스트림 작업에서 즉시 사용 가능한 강력한 성능 제공
- Loss function:
5. Efficient Implementation
Hardware and Software Setup
- 학습 환경: A100 GPU에서 PyTorch 2.0으로 모델 학습
- 코드와 pretrained 모델은 Apache 2.0 라이선스로 공개
- 모델 세부 사항은 부록 Table 17 참조
- iBOT 구현 대비 DINOv2 코드는 약 2배 빠른 실행 속도, 메모리 사용량 1/3 수준
Fast and Memory-Efficient Attention
- 기존 Attention의 문제
- 기존 Self-attention 방법은 큰 모델과 고해상도 이미지(예: 224×224 이상)에서는 메모리 사용량이 급격히 증가하고, 계산 속도가 느려지는 문제가 발생
- 쿼리(Q), 키(K), 값(V) 행렬을 계산한 뒤, Attention score 행렬(QKᵀ)을 모두 메모리에 저장하고 Softmax를 적용하기 때문
- 이 과정은 메모리 소모가 크고, GPU의 HBM을 빠르게 채움
- FlashAttention 최적화
- Attention 연산을 메모리 효율적으로 재구성하여 불필요한 중간 데이터를 저장하지 않고, GPU에서 더 빠르게 처리하도록 최적화
- 온라인 처리: Attention score 행렬을 한 번에 저장하지 않고, 작은 블록 단위로 나누어 처리. 각 블록을 계산한 뒤 즉시 필요한 결과만 저장하고 나머지는 버림
- 단일 패스: Forward와 backward 연산을 하나의 통합된 커널로 처리하여 중간 activation 저장을 최소화
- GPU 최적화: GPU의 SRAM(고속 메모리)을 적극 활용해 데이터를 빠르게 처리하고, HBM(주 메모리) 접근을 줄임
- GPU 특성상 Attention의 Embedding dimension per head를 64의 배수로 설정하면 효율이 극대화
- 그래서 ViT-g의 Embedding dimension을 1408(16 heads, 88 dim/head)에서 1536(24 heads, 64 dim/head)으로 조정
- 이 조정은 정확도에 거의 영향을 주지 않으면서 계산 효율성을 크게 향상
- Attention 연산을 메모리 효율적으로 재구성하여 불필요한 중간 데이터를 저장하지 않고, GPU에서 더 빠르게 처리하도록 최적화
Sequence Packing
- Sequence packing 기법:
- 서로 다른 크기의 이미지 입력(예: 큰 crop(224x224)과 작은 crop(98x98))을 하나의 긴 시퀀스로 묶어서 Transformer 모델에 처리하는 방법
- 이를 통해 계산 효율성을 높이고 메모리 사용을 줄임
- Vision Transformer(ViT)는 이미지를 패치 단위로 나누어 처리하는데, 큰 crop과 작은 crop은 패치 수가 달라 각각 다른 길이의 토큰 시퀀스를 만듦
- 기존 방식에서는 큰 crop과 작은 crop을 각각 별도로 Transformer에 forward/backward 연산을 해야 했기 때문에 계산 비용과 메모리 사용량이 컸음
Efficient Stochastic Depth
- Stochastic depth 개선:
- Stochastic Depth?
- Transformer 모델의 학습 과정에서 일부 레이어(또는 Residual connection)를 무작위로 스킵(drop)하여 계산 효율성을 높이고 메모리 사용량을 줄이는 방법
- 기존 Stochastic Depth는 레이어를 스킵하더라도 해당 레이어의 계산을 먼저 수행한 뒤 결과를 버리는 방식이었는데, 이는 여전히 불필요한 계산을 초래
- Efficient Stochastic Depth?
- 스킵할 레이어의 계산 자체를 아예 수행하지 않도록 개선
- 즉, Drop 된 레이어는 계산하지 않고 바로 Residual connection으로 넘어감
- Drop 확률 를 사용해 약 40%의 레이어를 무작위로 스킵
- 결과적으로, Efficient Stochastic Depth는 학습 안정성을 크게 개선했으며, Linear probe 성능에는 약간의 저하가 있었지만 k-NN 성능과 전반적인 학습 효율성을 높이는 데 기여
- Stochastic Depth?
Fully-Sharded Data Parallel (FSDP)
- Data Parallel (DP)?
- 대규모 모델 학습에서는 모델 파라미터, 옵티마이저 상태(예: AdamW의 1차/2차 모멘트), 중간 activation 등이 GPU 메모리를 많이 차지
- 예를 들어, ViT-g 모델(10억 매개변수)은 단일 GPU에서 학습하려면 약 16GB 메모리가 필요
- 여기에 student와 teacher 네트워크, 옵티마이저 상태까지 포함하면 메모리 요구량이 훨씬 커짐
- 기존 Data Parallel (DP) 방식은 각 GPU가 모델의 전체 복사본을 유지하므로, GPU 메모리가 부족하면 학습이 불가능
- Fully-Sharded Data Parallel (FSDP)?
- 모델 파라미터, 옵티마이저 상태, gradient를 여러 GPU에 분할(shard)하여 각 GPU가 전체 모델의 일부만 저장하도록 함
- 이를 통해 단일 GPU의 메모리 제약을 극복하고, 대규모 모델을 효율적으로 학습할 수 있음
- 계산 과정
- 모델의 파라미터를 여러 GPU에 나눠 저장
- 각 GPU는 전체 모델의 일부 파라미터만 보유
- Forward/Backward 연산 시, 필요한 파라미터를 다른 GPU에서 가져와(all-gather) 계산
- 계산 후 gradient는 다시 각 GPU로 분산(reduce-scatter)되어 저장
- 혼합 정밀도(Mixed Precision):
- 모델의 backbone은 float16으로 계산하여 메모리 사용량을 줄임
- 파라미터는 float32로 저장하여 학습 안정성을 유지하고, gradient는 작업에 따라 float16 또는 float32로 처리(예: MLP head는 float32로 gradient reduce)
- 효율적 통신
- FSDP는 필요한 경우에만 데이터를 모으거나 분산하므로, 기존 Data Parallel(DDP) 방식보다 통신 오버헤드가 약 50% 감소
- 결과적으로, FSDP는 DINOv2 학습에서 메모리 사용량을 약 1/3로 줄이고, 학습 속도를 약 2배 향상시키는 데 기여
- PyTorch FSDP mixed-precision, 대부분 경우 DDP autocast 대비 우수 (아래 Fig. 6)
Model Distillation
- Distillation 전략
- ViT-g(11억 매개변수)를 teacher로 사용하여 ViT-L이나 ViT-S 같은 소규모 모델로 지식(Knowledge)을 전달
- 학습 과정:
- ViT-g는 LVD-142M 데이터셋에서 사전 학습된 상태로 고정
- Student 모델은 DINOv2의 학습 파이프라인(DINO + iBOT + KoLeo loss)을 그대로 활용하여 teacher의 출력에 맞춰 학습
- Masking과 stochastic depth를 제거하고, iBOT loss를 global crop에 적용해 patch-level feature 전달을 강화
- 결과적으로 Model Distillation은 소규모 모델의 성능을 대규모 모델 수준으로 끌어올리며, 계산 효율성을 유지
6. Ablation Studies
Overview
- Ablation 실험: 데이터 파이프라인, 기술적 수정, model distillation의 효과 검증
- Sec. 4의 기술적 개선, 사전 학습 데이터, model distillation 영향 평가
- 다양한 다운스트림 작업(Sec. 7 참조)에서 성능 분석
Improved Training Recipe
- 기술적 개선 평가: iBOT 기반에 Sec. 4의 구성 요소 점진적 추가
- Baseline iBOT 모델에 각 구성 요소 추가, ViT 모델 학습
- ImageNet-1k 검증 세트에서 k-NN 및 linear probe로 Top-1 accuracy 보고 (아래 Table 1)
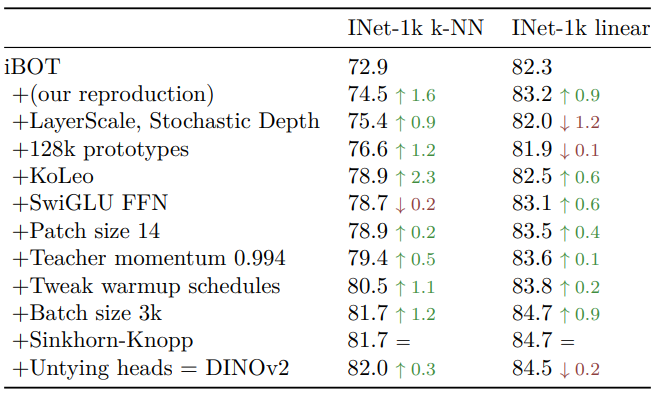
- 각 구성 요소는 k-NN, linear probe 또는 둘 다에서 성능 향상
- LayerScale, Stochastic Depth는 linear probe에서 성능 저하, 그러나 학습 안정성 크게 개선
Pretraining Data Source
- 데이터 품질 영향: LVD-142M, ImageNet-22k, uncurated 데이터 비교
- Uncurated 데이터: LVD-142M과 동일 소스에서 1억 4200만 이미지 무작위 샘플링
- ViT-g/14 모델을 동일 반복 수로 각 데이터셋에서 학습
- ImageNet-22k에서 ImageNet-1k synsets 제거한 변형(INet-22k \ INet-1k) 포함
- 결과 비교 (아래 Table 2)

- Curated 데이터(LVD-142M) 학습이 uncurated 데이터 대비 대부분 벤치마크에서 우수
- ImageNet-22k 대비 LVD-142M은 ImageNet-1k 제외 모든 벤치마크에서 성능 우수
- LVD-142M은 데이터 다양성으로 ImageNet-22k 미포함 도메인 성능 향상
- iNaturalist 2018, 2021, Places205 등 큐레이션 미사용 도메인에서도 성능 개선
- 결론: LVD-142M은 이미지 유형 균형으로 전반적 성능 최적화
Model Size and Data
-
스케일링 효과: 모델 크기와 데이터 크기 상호작용 분석 (아래 Fig. 4)

- 모델 크기 증가 시 LVD-142M 학습이 ImageNet-22k 대비 더 큰 이점
- ViT-g 모델: LVD-142M 학습 시 ImageNet-1k 성능 동등, 기타 벤치마크에서 큰 차이로 우수
Loss Components
-
Loss 구성 요소 분석: 최적 모델에서 KoLeo loss, masked image modeling(iBOT) 제거 효과 평가
- ImageNet-1k linear classifier, ADE20k segmentation linear classifier, Oxford-M nearest-neighbor retrieval 성능 보고
- KoLeo loss 영향 (아래 Table 3a)
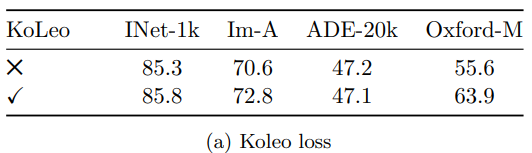
- KoLeo loss로 instance retrieval 성능 8% 이상 향상, 출력 공간에서 feature 분포 균일화
- 기타 지표는 Regularization으로 성능 저하 없음
- iBOT loss 영향 (아래 Table 3b)

- Masked image modeling 제거 시 dense prediction tasks 성능 약 3% 저하
- iBOT loss는 dense tasks에 필수적
Impact of Knowledge Distillation
-
Distillation 효과: ViT-L/14 모델을 scratch 학습과 ViT-g/14 distillation 비교
- Sec. 5의 distillation 절차 사용, 12개 벤치마크 평가 (아래 Fig. 5)
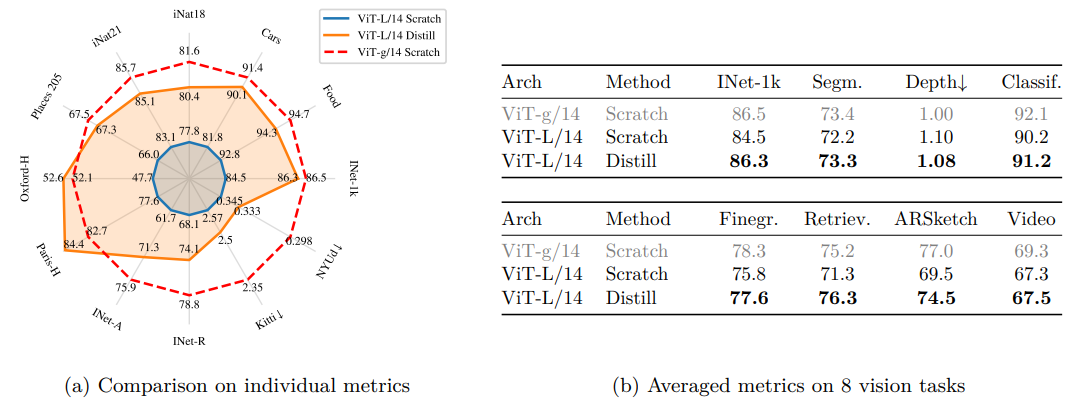
- ViT-g/14를 topline으로 사용
- Distilled 모델은 모든 벤치마크에서 scratch 학습 모델 초월
- 소규모 모델 사전 학습 접근법의 유효성 입증
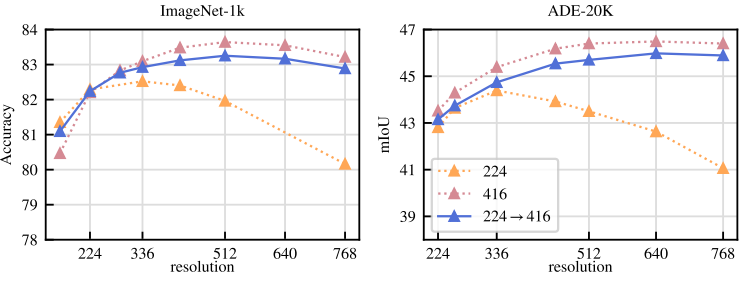
Impact of Resolution
-
해상도 영향: 사전 학습 해상도 변경이 image-level 및 patch-level 특징에 미치는 영향 분석
- ViT-L/16 모델을 ImageNet-1k에서 224×224, 416×416 고정 해상도, 또는 224×224 후 10k 반복 416×416 학습
- ImageNet-1k 및 ADE20k에서 linear probe 성능, 다양한 해상도 평가 (아래 Fig. 6)
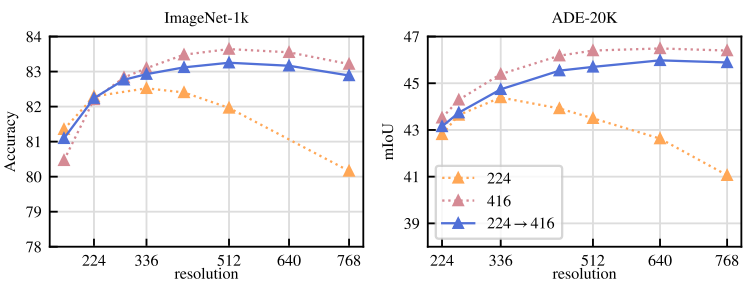
- 고해상도(416×416) 학습 모델이 모든 해상도에서 최적 성능
- 그러나 416×416 학습은 224×224 대비 약 3배 계산 비용 소요
- 224×224 학습 후 10k 반복 고해상도 학습은 유사 성능, 계산 비용 최소화
- 결론: 고해상도 학습을 사전 학습 마지막에 단기 적용, scratch 고해상도 학습 대체
7. Results
Overview
- 실험 평가: 다양한 image understanding tasks에서 모델 성능 검증
- Global 및 local image representations 평가
- 작업: category 및 instance-level recognition, semantic segmentation, monocular depth estimation, action recognition
- 벤치마크 세부 사항은 부록 C 참조
- 평가 목표
- Self-supervised features가 기존 state-of-the-art 초월
- Weakly-supervised 모델과 동등하거나 우수한 성능 달성
- Baselines
- Self-supervised: MAE, DINO, SEERv2, MSN, EsViT, Mugs, iBOT
- 각 방법의 최고 성능 아키텍처(ImageNet-1k Top-1 accuracy 기준) 선택
- Weakly-supervised: CLIP, OpenCLIP, SWAG
- ImageNet-1k 외 평가에서는 SSL 상위 4개, weakly-supervised는 OpenCLIP-G 기준
- Self-supervised: MAE, DINO, SEERv2, MSN, EsViT, Mugs, iBOT
ImageNet Classification
-
Holistic image representation 평가: ImageNet-1k에서 frozen backbone에 linear classifier 학습
- Backbone은 freeze 한 채,간단히 학습 된 linear model 사용, 클래스 비선형 분리 가능성에도 재현성 보장
- ImageNet-1k 검증 성능이 SSL 개발의 디버깅 신호로 사용, ImageNet-ReaL, ImageNet-V2 추가 보고
- 모든 모델에 동일 코드로 평가, 기존 보고 결과와 일치 확인
-
결과 (아래 Table 4)
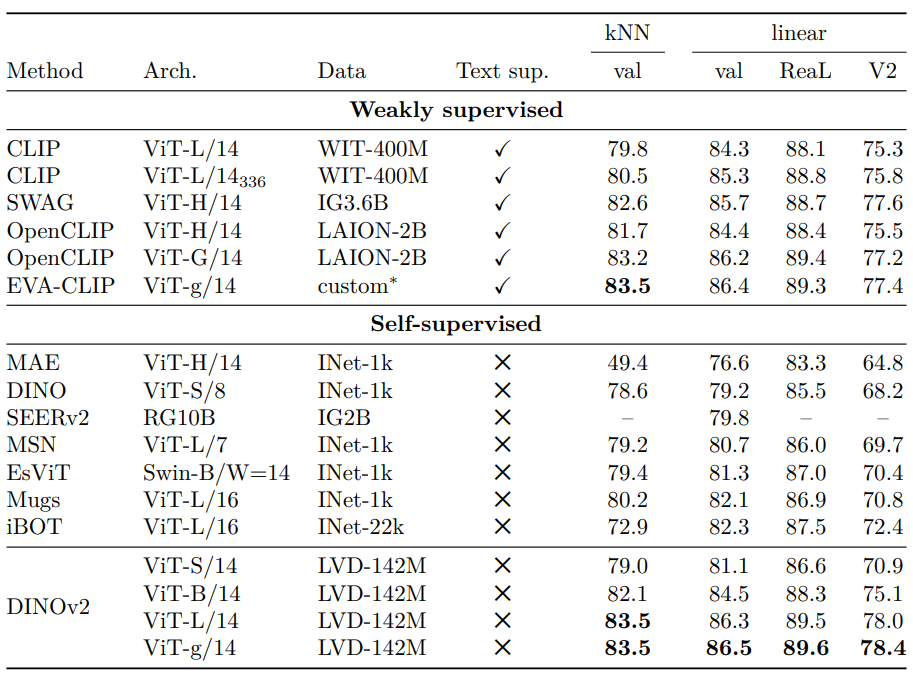
- DINOv2는 iBOT ViT-L/16 (ImageNet-22k 학습) 대비 linear evaluation에서 +4.2% 향상
- ImageNet-V2, ReaL에서 더 큰 성능 증가, 강력한 generalization 입증
- Weakly-supervised 비교: OpenCLIP ViT-G/14 (+0.3%), EVA-CLIP ViT-g/14 (+0.1%) 초월
- ImageNet-V2에서 EVA-CLIP 대비 +1.1%, generalization 우수
- Linear evaluation 세부 사항은 부록 B.3 참조
-
Finetuning 가능성: frozen features 특화 여부 확인 위해 ImageNet-1k finetuning 실험
- 표준 finetuning 파이프라인 적용, 하이퍼파라미터 조정 없이 Top-1 accuracy +2% 이상 향상 (224 및 448 해상도)
- 최고 finetuned 성능 88.9%, SOTA (91.1%)에 근접 (-2.2%)
- Finetuning 선택적, linear 및 finetuning 설정 모두에서 강력한 성능
-
Robustness 분석: domain generalization 벤치마크로 feature generalization 평가
- ImageNet-1k 학습 linear classifier로 추론
- 결과 (아래 Table 6)
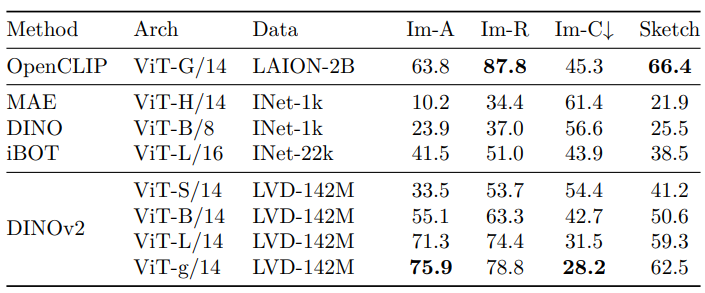
- SSL 대비 robustness 대폭 향상: ImageNet-A (+29.6%), ImageNet-R (+22.1%), Sketch (+23.0%)
- Weakly-supervised OpenCLIP-G 대비 ImageNet-A 우수, R 및 Sketch에서 소폭 뒤짐
Additional Image and Video Classification Benchmarks
-
Downstream classification: fine-grained 및 다양한 데이터셋에서 generalization 평가
- 데이터셋: iNaturalist 2018, 2021, Places205, SimCLR의 12개 image classification tasks
- iNaturalist, Places205: Sec. 7.1과 동일한 데이터 증강으로 linear classifier 학습
- 결과 (아래 Table 7)
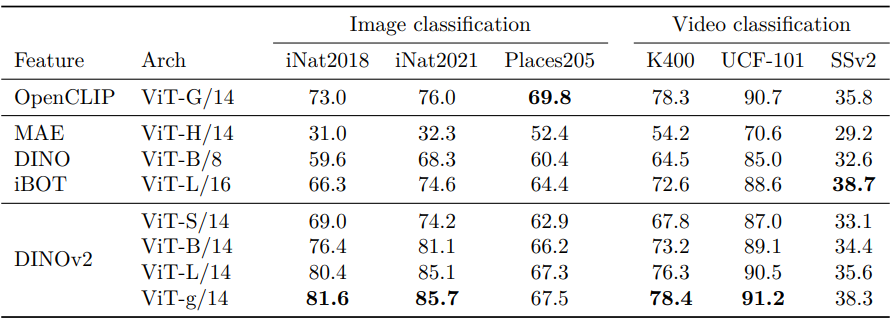
- iNaturalist 2018 (+8.6%), 2021 (+9.7%)에서 OpenCLIP ViT-G/14 크게 초월
- Places205에서 OpenCLIP 대비 소폭 뒤짐 (-2.3%)
-
Video action recognition: 비디오 학습 없이 UCF101, Kinetics-400, Something-Something v2 (SSv2) 평가
- 8개 균등 간격 프레임 선택, UCF 및 K-400은 feature 평균, SSv2는 temporal 정보 보존 위해 feature 연결
- SSL 중 새로운 SOTA 설정
- OpenCLIP과 UCF (+0.1%), Kinetics (+0.5%) 동등, SSv2 (+2.5%)에서 우수
- SSv2는 풍부한 비디오 프레임 이해 필요, DINOv2의 강력한 feature 입증
-
12 transfer classification benchmarks: SimCLR 프로토콜, Birdsnap 대신 CUB 사용
- Logistic regression으로 precomputed features 학습
- 결과 (아래 Table 8)
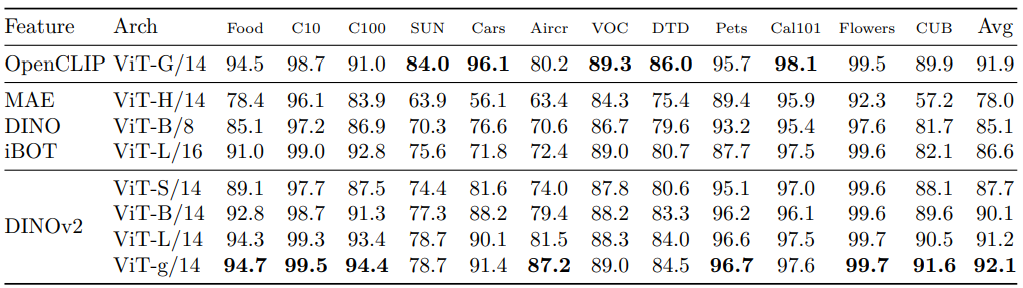
- SSL 대비 큰 성능 향상: Stanford Cars (+14.8% vs DINO ViT-B/8), FGVC Aircraft (+14.8% vs iBOT ViT-L/16)
- OpenCLIP과 대부분 벤치마크에서 경쟁력, SUN (-5.3%), Cars (-4.7%) 제외
Instance Recognition
-
Non-parametric instance recognition: cosine similarity로 데이터베이스 이미지 순위 매김
- 데이터셋: Paris, Oxford (landmark recognition), Met (예술품), AmsterTime (암스테르담 거리 이미지)
- Mean average precision (mAP)으로 성능 측정
- 결과 (아래 Table 9)
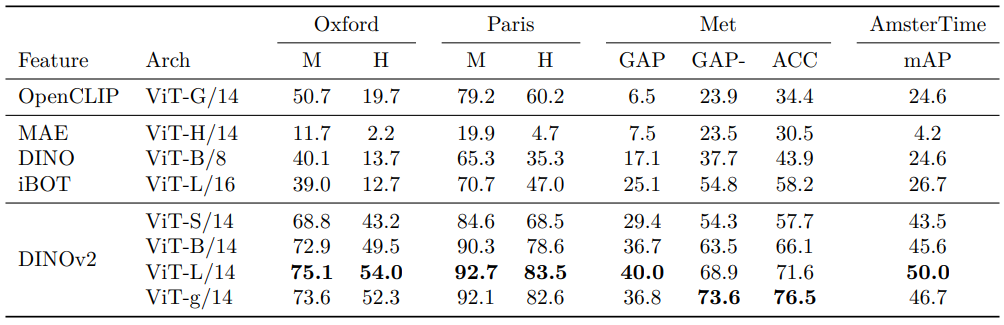
- SSL 대비 +41% mAP (Oxford-Hard), weakly-supervised 대비 +34% mAP
- Category 및 instance-level 작업 모두에서 우수한 성능, off-the-shelf 특징의 강점
Dense Recognition Tasks
-
Patch-level feature 평가: semantic segmentation, monocular depth estimation
-
Semantic segmentation
- 두 설정
- Linear (패치 토큰에서 클래스 logits 예측, 저해상도 logit map 업샘플링)
- +ms (마지막 4개 레이어 패치 토큰 연결, 640 해상도, multiscale test-time augmentation)
- 데이터셋: ADE20k, Pascal VOC, Cityscapes
- 결과 (아래 Table 10)
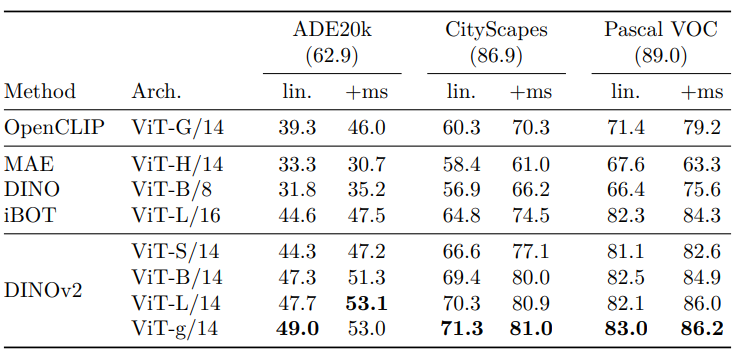
- 모든 데이터셋과 설정에서 우수한 성능
- +ms 설정은 MAE Upernet decoder finetuning (53.0 mIoU)과 동등 (53.6 mIoU)
- Pascal VOC에서 SOTA (89.0 mIoU)에 근접 (86.2 mIoU)
- SOTA pipeline: frozen backbone에 ViT-Adapter와 Mask2former head 결합
- 66% 가중치 frozen, ADE20k에서 60.2 mIoU, SOTA (62.9 mIoU)에 근접
- 16 V100 GPU에서 28시간 학습
- 두 설정
-
Depth estimation
- 데이터셋: NYUd, KITTI, NYUd에서 SUN3d로 zero-shot transfer
- 세 설정
- lin. 1 (마지막 레이어, [CLS] 토큰 연결, 4배 업샘플링, 256 bins classification)
- lin. 4 (다중 레이어 토큰 연결)
- DPT (DPT decoder로 regression)
- 결과 (아래 Table 11)
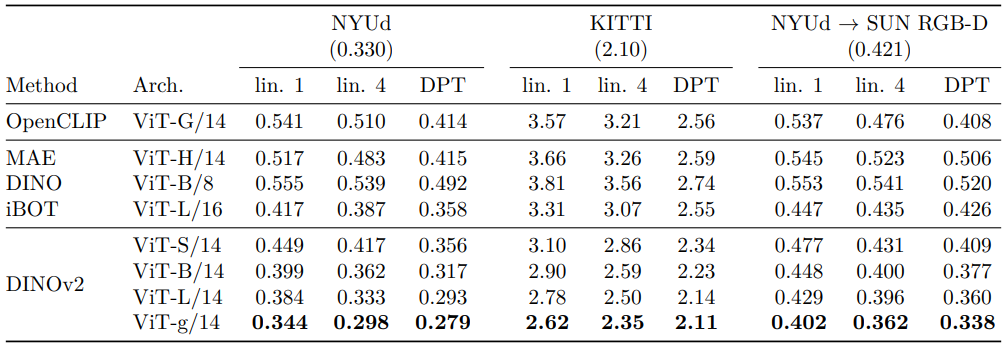
- SSL 및 WSL 대비 명확한 성능 우위
- iBOT ViT-L 대비 OpenCLIP ViT-G 우수, caption 기반 학습은 미세 패턴 포착 한계
- DPT decoder로 SOTA 성능 달성, SUN-RGBd zero-shot transfer에서 강력한 도메인 generalization
Qualitative Results
-
Semantic segmentation 및 depth estimation: ADE20k segmentation, NYUd, KITTI, SUN RGB-D depth estimation (아래 Fig. 7)

- Linear segmentation: DINOv2는 OpenCLIP-G 대비 artifacts 적고 우수
- Depth estimation: DINOv2는 부드러운 예측, OpenCLIP은 객체(예: SUN RGB-D 의자) 무시
- 복잡한 깊이 정보의 선형 분리 가능, DINOv2는 artifacts 최소화
-
Out-of-distribution generalization: 동물, 그림 등 OOD 예제에 linear classifier 적용 (아래 Fig. 8)

- 도메인 간 transfer 성능 우수, 깊이 및 segmentation 품질 유지
-
PCA of patch features: 패치 특징에 PCA 적용, 첫 번째 주성분 임계값으로 foreground/background 분리
- 동일 카테고리 3개 이미지에서 두 번째 PCA, 상위 3개 주성분 색상 매핑 (아래 Fig. 1, 9)

- Unsupervised foreground/background detector로 주요 객체 경계 명확히 구분
- 다른 주성분은 객체 부위 대응, 학습 없이도 부위 파싱 가능
-
Patch matching: foreground 객체 탐지 후 패치 feature 간 Euclidean distance 계산, assignment problem 해결
- Non-maximum suppression으로 salient 매칭 선택 (아래 Fig. 10)

- Semantic regions 매칭: 비행기 날개와 새 날개 연결
- 스타일(이미지 vs 그림), 자세 변화(코끼리)에도 robust
10. Future Work and Discussion
DINOv2 Achievements
- DINOv2 기여: 대규모 curated 데이터로 감독 없이 학습된 새로운 image encoders 제시
- SSL로 weakly-supervised 모델과의 성능 격차 해소, finetuning 없이 다양한 벤치마크에서 SOTA 달성
- 성공 요인
- 개선된 학습 recipe: 최적화된 hyperparameters, regularization
- 대규모 모델: 데이터셋 무관 성능 향상
- 대규모 curated 데이터셋 LVD-142M
- Distillation: ViT-g 성능을 소규모 모델로 전달
- Emergent properties: 객체 부위 이해, scene geometry 파악, 도메인 무관 성능
- Linear classifier로 정보 즉시 추출 가능, feature 접근성 우수
Future Directions
- 스케일링 확장: 모델 및 데이터 크기 증가로 emergent properties 강화 기대
- Large language models의 instruction emergence 유사
- 더 큰 모델과 데이터로 object parts, geometric understanding 향상 계획
- Language-enabled AI: visual features를 word tokens처럼 처리하는 시스템 개발
- Visual features와 언어 통합, grounding된 정보 추출 목표
- DINOv2의 linear separability 활용, 복잡한 vision-language tasks 지원
- 환경적 지속 가능성: carbon-efficient 학습 전략 탐구
- SSL의 낮은 carbon footprint 활용, 친환경 AI 학습 프레임워크 구축
- 데이터센터 효율성 개선 및 재생 에너지 사용 확대
Broader Impact
- 컴퓨터 비전 혁신: DINOv2는 finetuning 없이도 versatile visual features 제공
- 다양한 도메인과 작업에서 즉시 사용 가능한 강력한 feature
- SSL의 잠재력 입증, 수동 주석 의존성 제거
- 응용 가능성: 로보틱스, 의료 영상, 자율 주행 등 다양한 분야로 확장 가능
- Visual understanding의 새로운 표준 설정
- 커뮤니티와의 협업으로 오픈소스 모델 및 코드 공유, 연구 가속화
