https://arxiv.org/abs/2304.00287
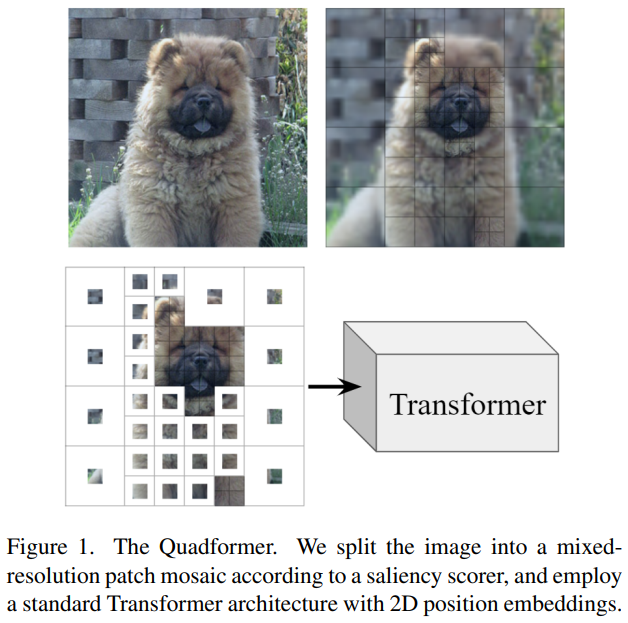
1. Introduction
- 대다수의 vision transformer는 input image를 2-dimension grid로 변환한 다음 이를 1-dimension sequence로 펼치는 방식을 사용
- 자연어 처리에서 input tokenization은 완전히 다름
- 현재 대부분의 text 처리용 모델은 각 token이 임의의 문자 길이의 부분 문자열을 나타내는 sub-word tokenization를 사용
- 본 연구에서는 이 접근 방식을 ViT에 적용하여 standard uniform grid를 대체하는 mixed-resolution sequence의 token으로 image를 표현하는 새로운 image tokenization 체계를 도입
- 이는, 공간적으로 규칙적인 patch grid를 사용하는 대신 image의 낮은 중요도 영역을 낮은 resolution로 처리하고 모델의 더 많은 용량을 중요한 영역으로 routing 하기 위해 patch mosaic를 구축
- Quadformer를 ImageNet-1k classification 데이터셋에서 평가하고, 동일한 아키텍처를 사용하는 일반 ViT 모델과 비교
- Accelerated inference를 위한 전용 도구를 사용하지 않았음에도 inference speed를 제어할 때도 기존 ViT 모델을 최대 0.42 absolute percentage point 까지 능가하는 성과를 보임
2. Background and related work
Efficient Vision Transformers
- Efficient vision transformers에 대한 다양한 효율적인 아키텍처가 제안됨
- 시간 복잡도가 선형인 attention layer를 사용
- 일부 patch를 제거
- 전체 image 에서 중간 token representation을 merge
Vision Transformers with spatially uniform grids
- 일반적인 vision transformer 모델은 input image를 동일한 크기의 patch로 구성된 규칙적인 grid로 나누어 처리
- Pyramid와 같은 경우에도 network가 진행됨에 따라 feature map의 spatial dimension을 점차 compression 하지만, 동일한 feature map 내의 vector는 항상 동일한 크기의 input 영역을 나타냄
- 이는 convolution layer의 제약 사항을 고려하여 일반적으로 CNN과 광범위하게 사용되는 고전적인 설계 선택임
- Transformer 모델은 어떤 종류의 input vector 집합도 처리할 수 있으며, 정의된 위치 관계를 가지는 input을 자연스럽게 처리하기에 적합
- 예를 들어, transformer 언어 모델은 매우 다른 길이의 sub-word를 나타내는 input token을 처리
- BERT 어휘에는 1글자("a", "b")부터 18글자("telecommunications")까지의 길이를 가진 token이 포함되어 있음
Existing methods for image tokenization
- 모든 vision transformer가 standard uniform grid tokenization 체계를 사용하는 것은 아님
- 일부 방법은 input image로부터 representation을 만들기 위해 CNN backbone을 사용하며, activation volume을 token으로 사용
Quadtrees
- Quadtree는 2-dimension 공간을 사분면 tree로 재귀적으로 분할하는 데이터 구조
- 각 내부 node는 정확히 4개의 children을 가짐
- Tree의 각 node는 축에 정렬된 직사각형 또는 정사각형으로 정의된 특정 공간 영역을 나타냄
- Quadtree는 원래 2D point를 빠르게 검색하기 위해 개발됨
- 이후 빠른 image 분석을 위해 빨리 적용되었으며, 나중에는 image compression을 위해 사용되기도 함
Quadtrees and neural networks
- Quadtree 알고리즘을 neural network와 통합하는 시도는 매우 제한적이었고, 아래와 같은 연구들이 있었음
- Quadtree를 사용하여 큰 pathology image를 작은 하위 image로 나누고 각 하위 image를 standard CNN으로 개별적으로 처리
- Jewsbury et al.
- 흑백 스케치를 처리하기 위해 sparse CNN과 함께 quadtree를 사용하며, image의 공백 영역에서의 계산을 피합
- Jayaraman et al.
- ViT의 efficient attention을 제안하였고, 공간적으로 균일한 grid의 각 query vector가 key-value vector의 quadtree에 참여
- Tang et al.
- Quadtree를 사용하여 큰 pathology image를 작은 하위 image로 나누고 각 하위 image를 standard CNN으로 개별적으로 처리
3. Method
3.1. ViTs with mixed-resolution tokenization
- Mixed-resolution patch mosaic는 image를 다양한 크기의 중복되지 않는 patch 집합으로 나누는 것으로 정의
- Patch embedding
- Mosaic 내의 각 patch는 고정된 representation 크기로 조정
- Flatten 이후 shared fully connected layer를 통과
- 모든 patch는 image에서 커버하는 영역에 관계없이 동일한 dimension의 token으로 표현
- Position embedding
- 일반적인 ViT에서 사용하는 1-dimension position embedding은 patch가 규칙적인 grid의 일부가 아닐 때 의미를 잃음
- 대신 2-dimension position embedding을 사용
- x와 y 위치를 별도로 embedding 한 다음, 가장 작은 patch 크기로 결정된 grid 내 patch 중심의 (x, y) 위치를 연결하여 최종 position embedding을 생성
- Patch embedding
3.2. Saliency-based Quadtrees
3.2.1. Quadtrees for RGB images
- RGB image를 나타내는 quadtree에서 각 leaf node는 image patch의 compression 된 표현을 포함하며, 이는 종종 image patch를 미리 결정된 크기로 down-sampling
- RGB image를 위한 quadtree는 아래와 같은 알고리즘 을 사용하여 구성

- 이 알고리즘은 순차적으로 image patch 중 "가장 중요한" image patch를 선택하고, 이를 scoring function에 따라 순위를 매기며, 이를 4개의 patch로 분할
- 이로써 선택한 image 영역을 표현하기 위해 4배 더 많은 pixel을 사용하게 됨
- 이 scoring function을 "patch scorer"라고 부름
- 본 논문에서는 여러 가지 patch scorer를 실험

- Pixel-blur scorer
- Quadtree image compression에 일반적으로 사용
- Feature-based scorer
- 신경 representation을 사용하여 importance를 추정
- Grad-CAM oracle scorer
- label-aware saliency method를 활용
3.2.2. Pixel-blur scorer
- Image compression applications에서 quadtree patch scoring은 보통 image patch와 해당 patch의 compression 된 representation 간의 MSE를 기반으로 함
- 이는 patch를 Quadtree representation 크기로 down-sampling 하여 더 흐릿한 버전으로 만든 다음 원래 크기로 up-sampling 한 것과 같음
- 이 score는 patch의 resolution를 감소시킴으로써 발생하는 pixel 수준의 정보 손실을 추정
- 를 image patch라고 가정
- Pixel-blur scorer는 high-frequency content가 많은 image 영역에 높은 importance를 할당
- High-frequency content는 image compression에 대한 좋은 importance 측정일 수 있지만, object를 식별하려고 할 때는 중요하지 않은 natural image의 세부적인 배경이나 texture가 있는 경우가 많아서 object saliency의 importance 측정으로는 부적절
3.2.3. Feature-based scorer
- Computer vision neural network는 semantically meaningful feature vector를 추출하는 데 자주 사용
- Vision transformer와 CNN 모두 image 영역의 문맥을 고려한 embedding을 생성
3.2.4. Grad-CAM oracle scorer
- Grad-CAM은 다양한 computer vision 모델로부터 얻은 예측에 대한 시각적 설명을 생성하기 위한 방법
- 각 pixel에 할당된 weight가 해당 pixel이 주어진 대상 클래스에 대한 image를 분류하는 데 얼마나 중요한지를 나타내는 pixel-level saliency map을 생성
- Grad-CAM patch scorer로 생성된 고품질 saliency score를 사용하여 학습 및 평가하는 특정 oracle Quadformer를 사용
4. Experiments
Dataset and evaluation metrics
- ImageNet-1K에서 실험
- 모델의 효율성을 평가하기 위해 다음을 측정
- Transformer 모델의 input patch/token 수
- Image 당 GMACs 수
- GeForce RTX 3090 GPU에서의 처리량 (ims/sec) 및 실행 시간 (µ-초/im)
- ViT-Small (22M 파라미터), ViT-Base (86M 파라미터), ViT-Large (307M 파라미터)와 같은 아키텍처를 공유
Fine-tuning
- Pretrained model을 사용하여 모든 fine-tuned model의 weight를 초기화
- 완전히 처음부터 학습하는 것과 비교하여 훨씬 빠른 conversion time을 관찰했기 때문
Patch scorers
- Feature-based patch scorer
- ImageNet-1K에서 학습된 ShuffleNetV2×0.5 모델을 사용
- FCN 바로 전까지만 잘라내어 x32 down-sampling rate를 얻음
- Feature extraction backbone은 342K 파라미터만 가지고 있으며 추가 부담이 거의 없으며 실제 세계의 inference 목적에 실용적
- Grad-CAM patch scorer
- Oracle saliency estimation에는 145M 파라미터를 가진 RegNetY-32GF 모델을 사용
Main results
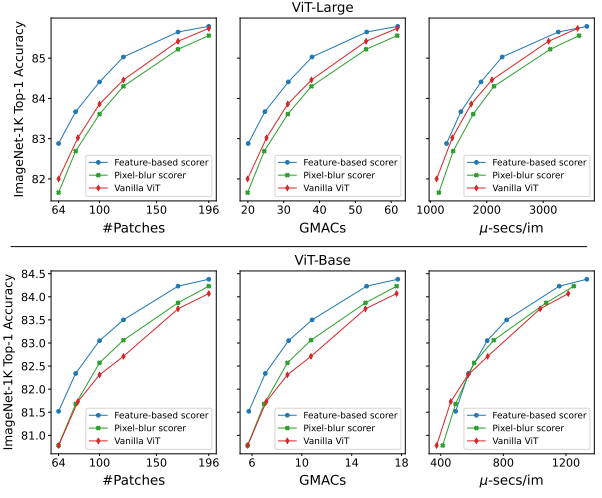
- Feature based scorer를 사용하면 Quadformer 모델은 patch 수나 GMAC 수를 제어할 때 일반 Vision Transformer 대비 최대 0.79(ViT-Base의 경우) 또는 0.88(ViT-Large의 경우)의 absolute percentage point로 일관되게 높은 정확도를 보임
- Accelerated inference를 위한 전용 도구를 사용하지 않았음에도 불구하고 inference speed를 제어하는 경우에도 거의 모든 #Patches 값에 대해 일반 ViT 모델을 넘는 결과를 보임
- Image compression에 사용되는 일반적인 pixel based scorer는 feature based scorer보다 훨씬 나쁜 결과를 내며, surface details보다 semantic meaning의 우수성을 보여줌
Inference-time compute-accuracy trade-off
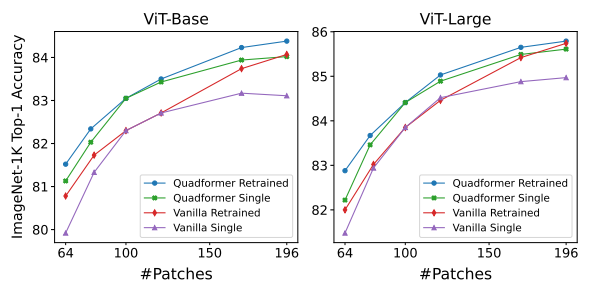
- "Retrained" 라인은 각 #Patches 값에 대해 재학습된 모델을 보여줌
- "Single" 라인은 다른 #Patches로 평가된 단일 모델 (100 patch로 학습)을 나타냄
- Quadformers는 분포 밖의 input 길이에 대해 민감성이 적으며 단일 모델로 더 나은 inference 시 compute-accuracy trade-off를 제공
6. Conclusion
- Vision Transformers를 위한 tokenization 방법을 제안
- Image classification 실험을 통해, 표준 Vision Transformer 모델이 fine-tuning을 통해 mixed resolution tokenization에 adaptation할 수 있는 능력을 보여줌
- Quadformer 모델은 patch 수나 GMACs를 제어할 때 일반 ViTs와 비교하여 상당한 정확도 향상을 달성
- Accelerated inference를 위한 전용 도구를 사용하지 않았음에도 불구하고 Quadformers는 inference speed를 제어할 때 이득을 보임
- 향후 연구에서 mixed resolution ViTs를 다른 computer vision task에 성공적으로 적용할 수 있을 것
- 특히 information densities가 다양한 large image를 다루는 task 및 dense prediction task을 포함하는 task들을 고려

AI Research Engineer