https://arxiv.org/abs/2106.09685
1. INTRODUCTION
- 많은 자연어 처리 application들은 하나의 대규모, pre-trained 언어 모델을 여러 downstream application에 적용
- 이러한 adaptation은 보통 모든 parameter를 업데이트하는 fine-tuning을 통해 이루어짐
- Fine-tuning의 주요 단점은 새로운 모델이 원래 모델만큼 많은 parameter를 갖는다는 것
- GPT-3의 경우 1750억 개의 학습 가능한 parameter를 가짐
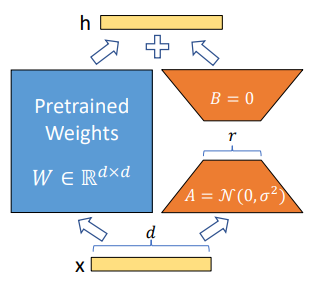
Reparametrization -> A와 B만 학습
-
많은 사람들이 새로운 task에 대해 일부 parameter만 조정하거나 외부 모듈을 학습하여 이 문제를 완화하려 함
-
하지만 기존 기술들은 종종 inference latency를 유발
-
Li et al. (2018a), Aghajanyan et al. (2020)
- 해당 연구에선 Overfitting 된 모델들이 사실 low intrinsic dimension (낮은 내재 dimension)에 있음을 보여줌
-
이러한 사실로부터 Low-Rank Adaptation (LoRA) 접근법을 제안
-
LoRA는
- Dense layer의 변화 대신 rank decomposition matrix를 최적화하여 dense layer의 변화를 간접적으로 학습시킴
- GPT-3 175B를 예로 들면, 매우 낮은 rank(예: r=1 또는 2)로도 충분
LoRA의 주요 장점
- Pre-trained 모델을 공유하고 많은 작은 LoRA 모듈을 다양한 task에 사용 가능
- LoRA는 학습을 더 효율적으로 만들고 하드웨어 장벽을 최대 3배 낮춤
- 간단한 선형 설계를 통해 inference latency 없이 학습 가능한 matrix를 freezed weight로 유지 가능
- LoRA는 여러 사전 기법들과 병합 가능
Terminologies and Conventions
Transformer 아키텍처의 용어와 표준을 사용
- : Transformer layer의 입력 및 출력 dimension 크기
- : self-attention 모듈에서 query/key/value/output projection matrices
2. PROBLEM STATEMENT
Training objective에 구애받지 않으며, 언어 모델링에 초점을 맞춤
-
주어진 pre-trained autoregressive 언어 모델 가 주어짐
-
예를 들어, NLSQL에서 는 natural language query, 는 SQL command
-
Fully fine-tuned 모델은 pre-trained weight 로 초기화되고 반복적으로 아래 수식을 최대화하는 조건부 언어 모델링 objective를 위해 업데이트:
-
각 downstream task에 대해 parameter 를 학습해야하는 단점이 있음
-
의 dimension은 와 같음
-
GPT-3와 같은 큰 모델의 경우, 여러 독립된 fine-tuning 모델을 저장하고 배포하는 것은 어렵거나 불가능함
-
본 논문에서는 더 작은 크기의 parameter 세트 를 사용하여 를 인코딩하는 접근 방식을 채택:
-
LoRA를 사용하여 더 작은 rank representation을 제안하여 메모리 및 연산 효율성을 극대화
3. AREN'T EXISTING SOLUTIONS GOOD ENOUGH?
- 문제는 현재의 해결책이 충분하지 않다는 점
- 효율적인 Adaptation을 위한 두 가지 주요 전략
- Adapter layer 추가 (Houslby et al., 2019; Pfeiffer et al., 2021; Rücklé et al., 2020)
- Input layer activations 최적화 (Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021)
Adapter layer는 inference latency를 유발
- 다양한 adapter variation이 존재
- Houslby et al. (2019)의 원래 디자인은 각 Transformer 블록에 두 개의 adapter layer가 있음
- Lin et al. (2020)의 더 최근 디자인은 블록당 하나의 layer와 추가 LayerNorm이 있음
- Adapter layer를 사용할 때 latency가 증가
Prompt 최적화의 어려움
- Prompt tuning (Li & Liang, 2021)은 최적화가 어려움
- 학습 가능한 parameter 수가 변할 때 성능이 비선형적으로 변화함
4. OUR METHOD
4.1. LOW-RANK-PARAMETRIZED UPDATE MATRICES
- 특정 task에 adaptation 할 때, Aghajanyan et al. (2020)의 연구에 영감을 받아 parameter 업데이트를 낮은 rank로 제약함
- Pre-trained weight 를 로 업데이트하는데, 로 분해
- 이며, 와 는 학습 가능한 parameter
- 위 수식은 pre-trained 모델의 weight 에 low-rank matix 와 로 표현된 변화량 를 더하여 입력 에 대한 출력을 계산
4.2. APPLYING LoRA TO TRANSFORMER
- Transformer 아키텍처에서 LoRA를 사용하여 학습 가능한 parameter 수를 줄임
- 연구는 attention weights에만 적용
- 메모리와 저장 공간 사용이 크게 줄어듦
5. EMPIRICAL EXPERIMENTS
- LoRA의 downstream task 성능을 아래에서 평가
- RoBERTa (Liu et al., 2019)
- DeBERTa (He et al., 2021)
- GPT-2 (Radford et al., b)
- 다양한 task을 커버하는 실험 (NLU, NLG). GLUE 벤치마크에서 RoBERTa와 DeBERTa 평가
- GPT-2에서는 E2E NLG Challenge 사용
- 실험에는 NVIDIA Tesla V100 사용
5.1. BASELINES
- Fine-Tuning (FT):
- 일반적인 adaptation 접근법
- 모델의 모든 parameter가 업데이트됨
- 일부 layer만 업데이트하는 variation 접근법도 포함 (Li & Liang, 2021)
- Bias-only 또는 BitFit: Bias vector만 학습
- Prefix-embedding tuning: 입력 토큰 사이에 특수 토큰 삽입
- Prefix-layer tuning: Embedding layer 대신 Transformer layer의 모든 activation을 학습
- Adapter tuning: Adapter layer를 삽입하여 adaptation
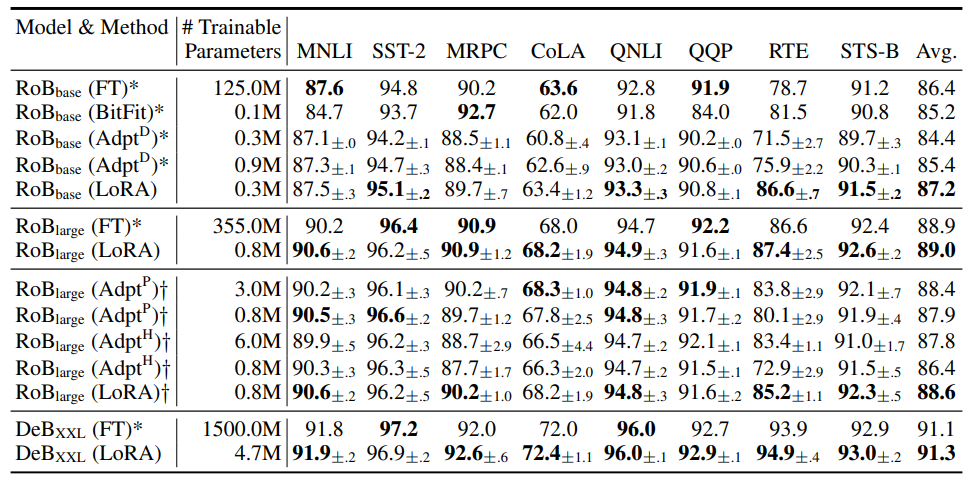
- 위 표는 다양한 adaptation 방법의 성능 비교
- LoRA가 효율적이고 경쟁력 있는 성능을 보임을 확인할 수 있음
5.2. RoBERTa BASE/LARGE
- RoBERTa (Liu et al., 2019)는 BERT의 pre-training 레시피로 최적화한 모델로, GLUE 벤치마크에서 다양한 효율적 적응 방법의 성능을 평가
- 공정한 비교를 위해 Houslby et al. (2019)와 Pfeiffer et al. (2021)의 설정을 복제하고, 동일한 batch size와 sequence length(128)를 사용하여 평가를 진행
5.3. DeBERTa XXL
- DeBERTa (He et al., 2021)는 대규모로 학습된 최신 BERT 변형 모델로, GLUE와 SuperGLUE 벤치마크에서 뛰어난 성능을 보임
- DeBERTa XXL (1.5B) 모델을 사용하여 LoRA의 성능을 평가하고, fully fine-tuned 모델과 비교하여 여전히 높은 성능을 유지하는지 확인
5.4. GPT-2 MEDIUM/LARGE
- LoRA가 NLG 모델 (GPT-2 medium, large)에서도 효과적인지 평가. E2E NLG Challenge 사용
- WebNLG (Gardent et al., 2017), DART (Nan et al., 2020)에서도 결과 확인
5.5. SCALING UP TO GPT-3 175B
- GPT-3 175B 모델로 확장하여 LoRA의 성능을 평가한 결과, 아래 그림과 같이 모든 데이터셋(WikiSQL, MultiNLI-matched, SAMSum)에서 미세 조정 기준과 동일하거나 더 나은 성능을 보임
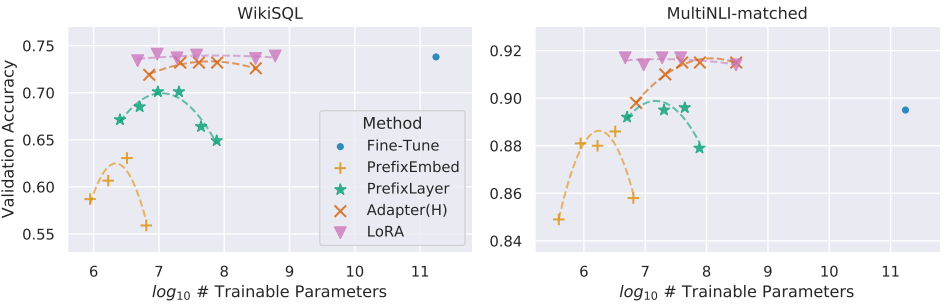
- 학습 가능한 파라미터 수가 많아도 성능이 항상 향상되지 않음을 확인하였으며, 특정 threshold을 초과하면 성능이 저하됨
8. CONCLUSION AND FUTURE WORK
- 대규모 언어 모델의 fine-tuning은 하드웨어 요구 사항 및 독립된 인스턴스를 호스팅하는 저장/전환 비용 면에서 매우 비쌈
- LoRA는 inference latency를 유발하지 않으면서 input sequence length를 줄이지 않고 높은 모델 품질을 유지하는 효율적인 adaptation 전략을 제안
- 서비스로 배포될 때 모델 parameter의 대부분을 공유함으로써 빠른 task 전환이 가능
- 제안된 원칙은 Transformer 언어 모델에 집중되었지만, dense layer가 있는 모든 신경망에 일반적으로 적용 가능
