https://arxiv.org/abs/2401.04716
CVPR 2024
1. Introduction
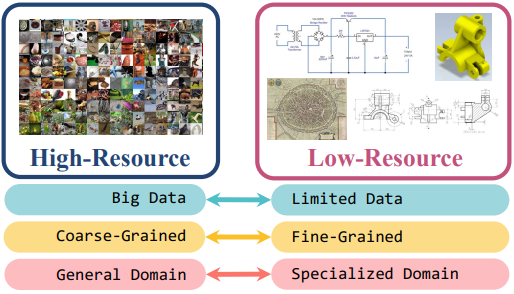
- 많은 연구들이 low-resource natural language processing을 다루어 왔으며, 이들 연구들은 적은 데이터와 덜 흔한 언어들을 대상으로 함
- Computer vision에서는 limited labeled data 시나리오에 대한 학습 방법이 많이 탐구됨 (meta-learning, few-shot learning, generative modeling 포함)
- 기존 연구들은 high-resource image domains에 초점을 맞추며, 수천 장의 이미지가 동일 도메인에서 사용 가능한 경우를 다룸
- 본 논문에서는 데이터가 부족한 low-resource vision task를 조사하며, 이 task는 몇 백 개의 example 만을 가지고 모델 학습을 해야 함
Contributions
- Low-resource vision의 challenge task를 연구하고 low-resource image benchmark를 수집
- circuit diagrams, historic maps, mechanical drawings
- Low-resource vision의 주요 challenge task (limited data, fine-grained difference, specialized domain)를 발견
- Foundation model은 low-resource image를 인식하고 검색하는 데 어려움을 겪음
- 이를 해결하기 위해 세 가지 간단한 baseline을 제안
1) Generative models를 사용하여 다양한 데이터를 생성함으로써 limited data 문제를 해결
2) 선택된 sub-kernels를 통해 local pattern에 초점을 맞추어 fine-grained difference를 발견
3) Specialized domain에 대한 attention을 학습하여 specialized domain을 극복 - 실험 결과는 기존 transfer learning, data augmentation, fine-grained methods 보다 나은 성능을 보임
- Low-resource vision에 대한 향후 연구를 위한 방향을 제시
2. Low-Resource Image Transfer Evaluation
- Low-resource vision task를 연구하기 위해 기존 데이터의 일부를 low-resource로 사용해선 안 됨
- 온라인에서 이용 가능한 이미지를 수집하여 LITE (Low-Resource Image Transfer Evaluation) 벤치마크를 제시
- 이 벤치마크는 세 가지 low-resource vision task를 다룸
2.1 Tasks
- 벤치마크는 세 가지 task를 포함
- (i) circuit diagram classification
- (ii) image-to-image retrieval with historic maps
- (iii) image-to-image retrieval with mechanical drawings
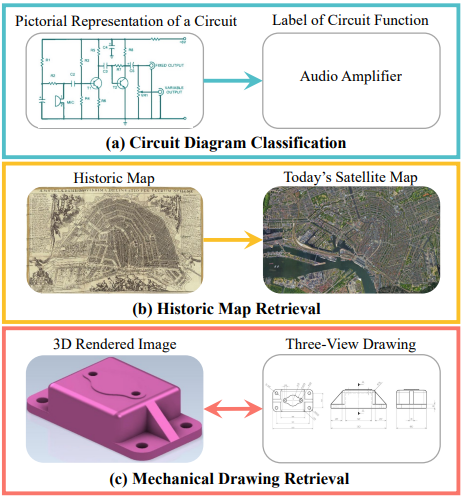
(a): 회로도를 보고 어떤 기능을 하는지 분류
(b): 옛 지도와 현대 위성 지도를 비교하여 검색
(c): 3D 렌더링된 이미지와 three-view drawing을 상호 검색
Task I: Circuit Diagram Classification
- 목표: 회로도가 어떤 기능을 하는지 분류
- 책과 웹사이트에서 circuit images와 label을 수집
- 총 32개의 "기능" 클래스가 동등하게 표현
- 작은 변화가 기능에 큰 영향을 미침으로, 세부적인 레이아웃 변화를 탐지하는 것이 challenges
- 성능은 Top-1 및 Top-5 정확도로 측정
Task II: Historic Map Retrieval
- 목표: 각 historic city map에 해당하는 현대 위성 이미지를 검색
- Old Maps Online에서 데이터를 수집하고 Google Maps에서 해당 위성 이미지를 자름
- 시간의 경과로 인해 도시 레이아웃이 상당히 변경되었음
- 성능은 Recall@1, Recall@5, mean rank으로 측정
Task III: Mechanical Drawing Retrieval
- 목표: 3D-rendered component 이미지와 일치하는 mechanical drawing을 검색 (또는 그 반대)
- TraceParts와 GrabCAD에서 mechanical drawings와 렌더링 이미지를 수집
- 세트 간의 큰 시각적 차이로 인해 challenges가 됨
- Recall@1, Recall@5, mean rank으로 측정

- 위 테이블에서 벤치마크 통계를 요약
- 각 task에 대해 자유롭게 이용 가능한 데이터를 최대한 많이 수집했지만, 데이터 양은 여전히 매우 적음
2.2 Low-Resource Vision Challenges
- LITE 벤치마크를 구성하는 세 가지 low-resource task는 매우 다양함
- 세 가지 공통적인 challenges를 식별
Challenge I: Data Scarcity
- Low-resource 시나리오를 위한 모델 학습에 사용할 수 있는 데이터가 극도로 제한적임 (Table 1 참조)
Challenge II: Fine-Grained
- Low-resource 데이터는 고도로 specialize 되어 있어 fine-grained details에 대한 주의가 필요함
- e.g. 회로도의 구성 요소 기호는 회로의 목적을 나타냄, 레이아웃이 아님
Challenge III: Specialized Domain
- 사용 가능한 데이터가 제한적일 뿐만 아니라 일반적인 자연 이미지와는 매우 다른 외관을 가짐
- 이는 기존 데이터셋으로 low-resource task의 학습 데이터를 bootstrap하는 것을 어렵게 만듦
- 각 challenges는 vision에서 별도로 연구되었음
- few-shot learning, fine-grained classification, domain generalization
요약하자면,
- 각 challenges (limited data, fine-grained difference, specialized domain)는 개별적으로도 어려운 문제들이지만, 이들이 결합된 상황은 low-resource vision task에만 특별히 나타나는 문제임
- 이러한 복합적인 challenges를 해결하기 위해서는 foundation models이 가장 유망한 접근 방식
- Foundation models은 다양한 상황에 적용될 수 있는 일반화된 능력을 가지고 있기 때문
3. Baselines for the Low-Resource Challenges
목표는 대규모 데이터셋으로 사전 학습된 foundation models을 low-resource task에 adaptation시키는 것
- Foundation model 는 LoRA나 AdaptFormer와 같은 소수의 transfer learning parameters 로 adaptation될 수 있음
- Low-resource vision에서 adaptation을 더 잘 다루기 위해 Section 2에서 강조한 각 challenges마다 하나의 baseline을 도입
- Limited data 문제를 해결하기 위해 generative models를 사용하여 학습 샘플을 증가시키는 방법 제안 (Section 3.1)
- fine-grained details에 초점을 맞추기 위해 selective tokenization을 사용하여 token patch 크기를 줄이는 방법 제안 (Section 3.2)
- specialized domain에 대한 attention을 도입하여 더 나은 모델 adaptation을 달성하는 방법 제안 (Section 3.3)
- Low-resource task에서 fine tuning 시, foundation model 를 고정하고 transfer learning, tokenization, attention을 위한 parameter를 학습
3.1. Baseline I: Generated Data for Data Scarcity
- Objective
- Low-resource vision의 주요 challenges인 limited data을 해결하기 위해 generative models를 사용하여 더 많은 학습 데이터를 생성
- Novelty
- 이전 연구들은 label이 유지되는 이미지를 생성하는 데 중점을 둠
- 그러나 본 논문은 label이 깨진 다양한 이미지를 생성하여 데이터 다양성을 높이는 방법을 제안
Method
- Label-preserving augmentation: 작은 값을 사용하여 원본 이미지와 유사한 이미지를 생성 (Stable Diffusion의 가우시안 노이즈 사용)
- Label-breaking augmentation: 큰 값을 사용하여 원본 이미지와 크게 다른 이미지를 생성
- Objective function:
- Label-breaking augmentation을 위한 contrastive loss 사용
- Contrastive loss를 통해 Label-breaking augmentation 이미지 쌍들 간의 feature vector가 서로 유사하지 않도록 학습
- 이는 모델이 다양한 이미지 데이터에 대해 잘 일반화할 수 있도록 유도
-
Overall learning objective:
-
Lambda를 통해 loss term의 중요도를 조절
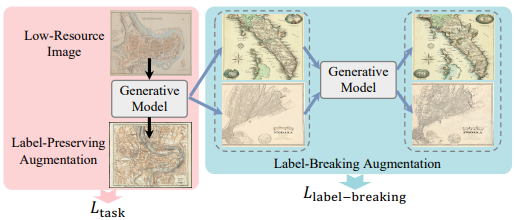
- Label-Preserving Augmentation: 원본 이미지와 유사한 augmentation 이미지 생성
- Label-Breaking Augmentation: 원본 이미지와 크게 다른 augmentation 이미지 생성
- Label-preserving augmentation 이미지는 task loss에 사용
- Label-breaking augmentation 이미지는 contrastive loss에 사용
생성 모델을 사용하여 low-resource 이미지에서 더 많은 학습 데이터를 생성함으로써, limited data 문제를 완화할 수 있음
Label-Preserving Augmentation 이미지는 학습 작업의 일관성을 유지하고, Label-Breaking Augmentation 이미지는 모델의 다양성을 향상시키는 데 기여
3.2. Baseline II: Tokenization for Fine-Grained
Objective
- Low-resource vision의 두 번째 주요 Challenge는 서로 다른 이미지를 구별하는 fine-grained details
- 이 문제를 해결하기 위해, tokenization 크기를 줄여서 모델이 low-resource 입력 이미지의 details에 주의를 기울이도록 함
Novelty
- 제한된 데이터로 인해, 새로운 toknizer를 처음부터 학습할 수 없음
- 대신, 원래의 linear projection kernel을 더 작은 sub kernel로 나누어 이미지 patch에 적용
- 각 patch level의 feature를 학습된 weight를 사용하여 결합하여 fine-grained recognition을 가능하게 함
Method
- Vision foundation models은 입력 이미지를 큰 patch로 나누고 이를 linear projection 하여 feature로 변환
- Linear projection 메커니즘을 sub kernel로 나누어 더 작은 patch에 적용
- Patch level feature를 결합하여 모델 학습에 사용
- : patch level feature
- : 학습된 weight
- : sub kernel로부터 얻은 feature vector
3.3. Baseline III: Attention for Specialized Domains
Objective
- Low-resource domains에 맞추어 foundation model feature을 adaptation 시키는 것이 목표
- Transformer attention은 fine-grained low-resource 도메인에서 중요한 영역을 구별하는 데 어려움을 겪음
Novelty
- 필요한 attention 유형이 각 도메인마다 다르지만, 서로 다른 이미지와 patch에서도 공유될 수 있음
- 예: 회로도에서는 세로와 가로의 주변 환경이 중요, 옛 지도에서는 local neighbor가 중요
- Parameter 수를 줄이기 위해, 샘플과 feature token 간에 attention map을 공유하여 global attention maps 학습
Method
- C개의 attention maps 학습
- 각 feature token에 대해 global attention maps에서 부분 map을 잘라 사용
- Softmax를 적용하여 attention 값을 계산하고, 학습된 vector 를 사용하여 feature을 weight로 조정
-
위 수식을 통해 여러 attention map을 사용해 input feature의 중요도를 가중 평균하여 최종 feature vector를 계산
-
: 특정 도메인에 대한 attention을 통해 얻은 feature
-
: multi-head self-attention에서 사용된 값
-
: multi-layer perceptron
- : 두 attention을 균형 맞추기 위한 학습된 parameter
4. Related Work
High-Resource Vision
- 대부분의 computer vision 연구는 데이터가 풍부한 high-resource settings에 초점을 맞춤
- 다양한 high-resource images 벤치마크가 제안됨
- 이들 이미지들은 인터넷에서 수집되거나, 저자들이 직접 캡처함
- Label은 coarse-grained 또는 fine-grained로 제공됨
- High-resource vision은 주로 온라인에서 풍부하게 사용 가능한 자연 이미지를 다룸
- 다른 도메인(X-ray, underwater, medical, satellite)에서도 이미지 수집
- 본 논문에서는 제한된 샘플만으로 학습 가능한 low-resource settings에 초점을 맞춤
Vision Foundation Models
- Vision foundation models은 high-resource 웹 크롤링 이미지로 pre-training
- 이러한 모델들은 다양한 downstream task에서 인상적인 일반화 능력을 보여줌
- 여러 연구들이 text-image pair를 학습하거나 다양한 modality 데이터를 사용하여 더 나은 성능을 보임
- 그러나, foundation model은 visual task에 대해서만 학습
Low-Shot Vision
- 제한된 학습 데이터로 여러 연구들이 low-shot 학습 시나리오를 탐구
- Few-shot learning과 zero-shot 시나리오를 포함
- 이러한 연구들은 모델 학습에 필요한 데이터 양을 줄이는 중요한 단계를 만듦
- 그러나, 이러한 연구들은 low-resource vision의 limited data, fine-grained difference, highly specialized domain의 결합 문제를 다루지 않음
5. Results and Discussion
5.1. Difficulties for Vision Foundation Models
- 현재의 vision foundation model이 low-resource vision task를 얼마나 잘 해결하는지 이해하기 위해, LITE 벤치마크에서 zero-shot 성능을 평가
- 여섯 개의 vision foundation model을 고려
- 각 task에서 입력 이미지와 실제 이미지 또는 텍스트 사이의 feature embedding 간의 similarity를 계산
Results
- 아래 테이블에서, 이러한 foundation model 중 어느 것도 low-resource task에서 좋은 성능을 보이지 않음
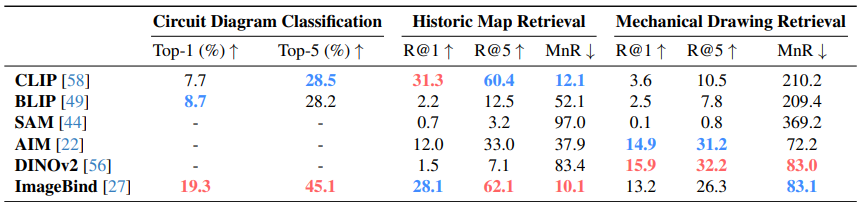
- 위 테이블에서, 현재의 vision foundation model이 low-resource vision task에서 전반적으로 좋은 성능을 보이지 않음을 보여줌
- Low-resource 데이터는 온라인에서 부족하여, foundation model의 학습 데이터에 포함되지 않음
- Low-resource 데이터의 특수성은 자연 이미지와 상당히 달라, foundation model이 이 데이터에 adaptation하는 데 어려움을 겪음
- 모델이 low-resource 데이터에 익숙하지 않기 때문에, 세밀하고 task 관련 details에 주의를 기울이는 데 어려움이 있음
- 따라서, vision foundation model은 low-resource task에 adaptation이 필요함
5.2. Challenge Results
Setup
- ImageBind가 low-resource 벤치마크에서 최고의 zero-shot 성능을 기록하여, 이를 사용함
- Section 2에서 정의한 세 가지 challenge를 위해 제안된 baseline 또는 기존 방법을 AdaptFormer [16]과 함께 추가함
- Foundation 모델은 고정 상태로 유지
- 본 논문의 baseline은 서로 독립적이며, input, tokenization, attention의 다른 영역에 집중
- 이들은 쉽게 결합할 수 있으며, 개별적으로 및 결합하여 테스트함
Challenge I: Data Scarcity
- 아래 테이블에서 low-resource vision에서 limited data 문제를 해결하기 위한 기존 솔루션의 성능을 보여줌
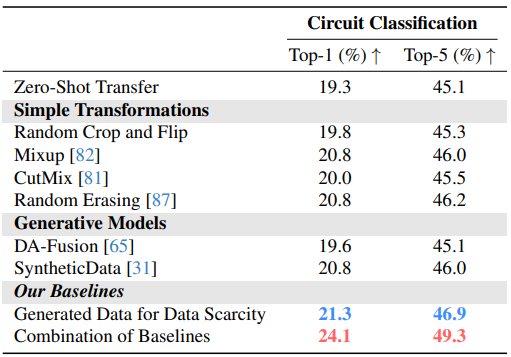
- 전통적인 데이터 augmentation 방법(예: random crop, flip, CutMix)은 LITE 벤치마크에서 어려움을 겪음
- Mixup과 SyntheticData는 샘플을 혼합하고 생성 모델을 사용하여 더 다양한 학습 데이터를 생성하여 더 나은 성능을 발휘함
- 본 논문의 baseline은 label-preserving 및 label-breaking 생성 이미지를 모두 고려하여 더 많은 데이터 포인트를 제공하여 low-resource vision task에 유리함
Challenge II: Fine-Grained
- 아래 테이블에서 low-resource vision의 fine-grained 문제를 해결하기 위한 state-of-the-art 방법들을 조사
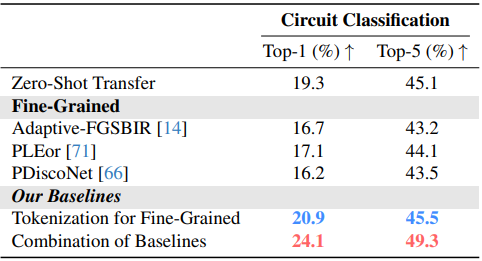
- 회로도 분류의 결과를 보여줌
- Fine-grained method들은 충분한 데이터가 있을 때 더 잘 동작하지만, low-resource 환경에서는 overfitting 으로 인해 성능이 저하됨
- 본 논문의 tokenization 방법은 fine-grained difference를 주의 깊게 다루면서 추가 parameter를 최소화하여 성능을 향상시킴
Challenge III: Specialized Domain
- Low-resource vision task의 specialized domain에 adaptation 하기 위해 여러 state-of-the-art transfer learning 방법들을 고려
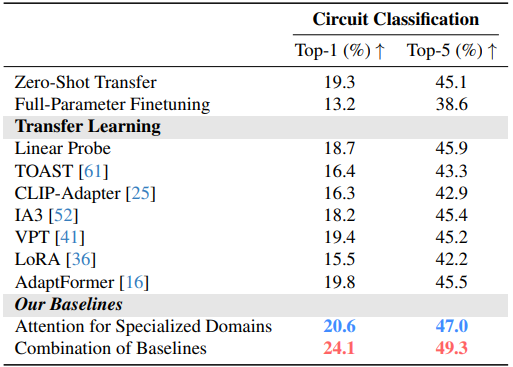
- 위 테이블에서 결과를 보여줌
- 기존 baseline은 zero-shot transfer보다 개선되지 않으며, AdaptFormer만 약간의 개선을 보임
- 본 논문의 attention 방법은 더 나은 일반화를 가능하게 하면서 최소한의 parameter를 도입하여 성능을 향상시킴
- 세 가지 주요 challenge를 모두 고려한 본 논문의 baseline 조합은 결과를 더욱 개선
5.3. Our Baselines on Different Foundation Models
- 아래 테이블에서 본 논문의 low-resource baseline이 다른 foundation model에도 적용될 수 있음을 보여줌
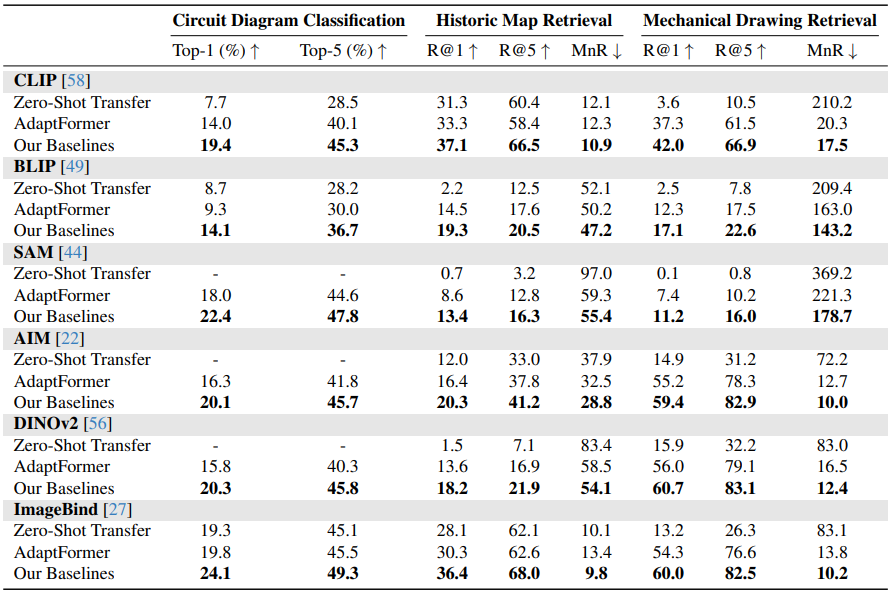
- 모든 여섯 개의 foundation model은 low-resource task에 adaptation하여 큰 향상을 보임
- AdaptFormer를 추가하여 여러 모델에서 성능이 크게 향상됨
- 본 논문의 간단한 baseline을 추가하여 성능을 더욱 개선
- 그러나 여전히 일부 low-resource task는 해결되지 않았으며, 추가 연구가 필요함
5.4. Discussion
Qualitative Results
- 아래 그림에서 Qualitative result를 제시
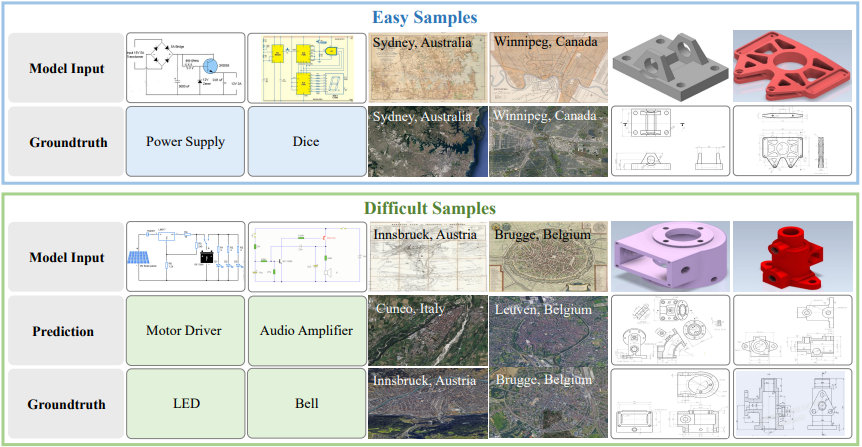
- 본 논문의 모델은 이미지의 일부가 label을 명확히 나타내는 경우를 잘 처리
- 그러나, 여러 이미지 영역 간의 관계가 중요한 경우에는 본 논문의 baseline이 어려움을 겪음
Opportunities for Future Work
- 본 논문의 baseline은 foundation model을 low-resource vision task에 adaptation시키기 위한 첫 걸음이지만, 여전히 해결되지 않은 문제가 많음
- 더 다양한 생성 데이터를 만들고, 관련 없는 기존 데이터가 low-resource task에 도움이 될 수 있는지 탐구 필요
- 여러 이미지 영역 간의 관계를 고려하여 더 나은 세밀한 구분을 해야 함
- Prompt learning이나 기타 기술을 통해 input 데이터를 foundation model에 더 적합하게 만드는 것도 고려할 수 있음
- Low-resource vision의 다른 challenge들에 대한 추가 연구 필요
6. Conclusion
- Low-resource vision을 연구하고, 세 가지 challenge를 확인
- Extremely limited data
- Fine-grained differences between images
- Highly specialized domain
- Foundation model이 low-resource vision task에서 어려움을 겪는 것을 발견
- 각 challenge 별로 세 가지 baseline을 제안하여 성능을 개선
- Baseline은 다양한 foundation model에 쉽게 적용 가능
- Low-resource vision은 여전히 미개척 분야로, 향후 연구 기회가 많음

AI Research Engineer