https://arxiv.org/abs/2411.03313
1. Introduction
- Large scale image-text dataset을 사용하는 pre-training 방법론은 컴퓨터 vision 분야에 큰 변화를 가져옴
- 그중에서도 CLIP(Constrastive Language-Image Pre-training)은 특히 인기 있으며, 다음과 같은 이유로 두각을 나타냄
- Zero-shot visual recognition 및 다양한 task에서의 finetuning
- Scalability, 즉 model과 data scale이 커질수록 성능이 증가하는 특성
- Text와 image를 이해하고 연결하는 강력한 cross-modal 능력
- CLIP 스타일의 model은 vision backbone을 deep language model과 결합하는 현대 vision language model(VLM)에서 기본 선택지가 됨
CLIP의 한계점
- 최적의 성능을 위해 large scale batch size(64,000 이상)와 높은 computation resource가 필요
- 특히 text encoding 과정에서 높은 계산 요구로 인해 자원이 제한된 연구자들이 접근하기 어려움
본 논문의 접근 방식
- 본 논문에서는 contrastive 방법론을 사용하지 않고 단순한 classification 방법을 도입하여 large scale batch size 및 text encoder의 필요성을 제거해 계산 부담을 줄임
- Large scale image-text pair pre-training을 위한 classification 방식을 재검토
- 이전 연구에서는 Bag-of-Words classification을 사용한 소규모 연구들이 있었으나, data와 model scalability에 대한 증거는 부족
- 본 논문의 접근 방식은 CLIP과 비교할 수 있는 scalability와 성능을 보이며, 1억 개의 고유한 text-image pair과 130억 개의 training sample을 통해 우수한 성능을 보여줌
SuperClass 방법론
- Contrastive learning과 달리 원시 text token을 그대로 supervision 신호로 사용하며, 다음과 같은 전처리 과정이 필요 없음
- 필터링, word 분할, 어간추출, 불용어(stopword) 제거
- 이는 원본 text 설명에서 중요한 정보를 모두 보존할 수 있어 representation learning에 도움이 될 수 있음
SuperClass 접근 개요
- SuperClass는 Super-simple-Classification 접근 방식으로, 원시 text token을 classification하는 방식으로 CLIP과 유사한 scalability 및 성능을 달성
- 실험 결과 text encoder 없이도 classification 방법이 model 성능 및 data scalability 면에서 contrastive 접근 방식과 유사한 성능을 발휘할 수 있음을 보여줌
SuperClass의 장점
- 다양한 visual 전용 및 vision-language task 시나리오에서 contrastive 접근 방식을 일관되게 능가함
- Model 크기와 학습 샘플 수에 따라 contrastive 방법과 비교해 경쟁력 있고 심지어 우수한 scalability를 나타냄
3. A simple classification approach to pretrain vision encoders
SuperClass 개요
- SuperClass는 text를 supervision으로 사용하는 classification 기반 pre-training 방법을 제안
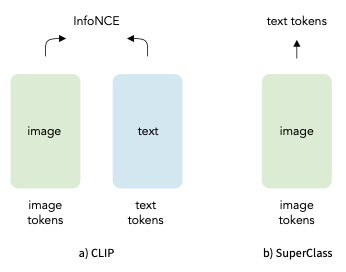
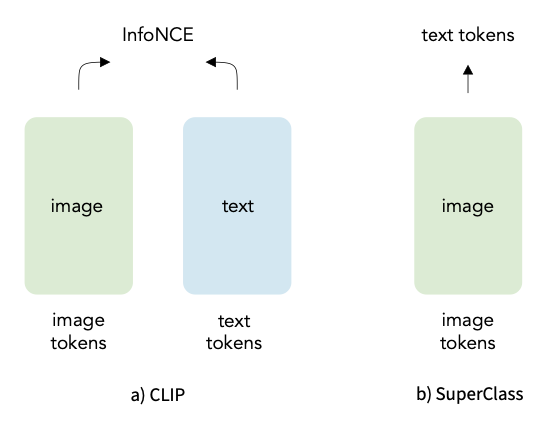
- SuperClass의 일반적인 프레임워크를 먼저 설명하고, text를 categorical label로 변환하여 모든 text가 image encoder 학습에 기여할 수 있도록 함
Loss function 설계
- 각 word의 중요도와 구별력을 고려해 inverse document frequency(IDF)를 class weight로 사용
Objective
- CLIP과 유사한 simplicity, scalability, efficiency를 갖춘 image classification 기반 pre-training 방법을 구축하고자 함
- Vision Transformer(ViT) backbone을 vision encoder로 사용하며, GAP와 linear layer를 거쳐 logit vector 를 출력
- Image와 관련된 text로부터 supervision 신호를 생성하고, text로 유도된 classification label과 예측된 logit vector를 이용해 classification loss을 계산
Texts as Labels
- Text를 직접 K-hot label로 사용하며, 여기서 는 주어진 문장 내 token 수를 의미
- Image-text dataset 에 대해, 기존 방식과 달리 기존 subword 수준의 tokenizer(BERT, CLIP 사용)를 사용하여 text 에서 subword ID 집합 를 생성하고 이를 classification label로 사용
- 의 각 label은 를 만족하며, K-hot 벡터 로 변환됨. 가 에 포함되면 , 아니면
- 기존 방법과 비교해 전처리나 임계값 설정이 필요 없고, 어휘 범위 밖(out-of-vocabulary) 문제를 회피
Classification Loss
- 목적: SuperClass의 주요 목표는 multi label classification 정확도를 최적화하는 것이 아니라, vision encoders를 효과적으로 pre-training 하는 것
- Softmax loss: Multi label 환경에서 Softmax를 확률적 방식으로 적용하여 label을 weight로 표현
- Loss function:
- 여기서 는 정규화된 weighted labeling
- 비교 실험: Softmax, BCE(Binary Cross Entropy), soft margin, ASL, two-way 등 여러 loss를 평가한 결과, Softmax가 가장 우수한 pre-training 성능을 제공
Inverse Document Frequency (IDF)
- Subword 어휘 내에서 각 category의 정보량이 다르며, 일부 word는 visual contents와 관련이 없고, 학습에 비효율적
- 정보량이 많은 word에 더 높은 weight를 부여하기 위해 IDF를 정보 중요도의 척도로 사용
- 샘플 수가 적은 특정 word는 샘플 구별력이 크며, IDF 통계를 통해 각 category에 weight 를 할당
- 여기서 는 image-text pair의 총 수, 는 subword 를 포함하는 text의 빈도
- Online IDF 통계를 사용하여 training 과정 중 IDF를 계산, 사전 학습 시 오프라인 통계의 필요성을 제거
4. Experiment
4.1. Experiment setup
- Datacomp dataset의 표준 하위 집합을 사용해 pre-training을 진행하며, 약 13억 개의 image-text pair를 포함
- SuperClass model에는 batch size 16k, CLIP model에는 90k batch를 적용
- CLIP과의 공정한 비교를 위해 동일한 학습률과 weight 감쇠를 설정하고, AdamW 및 cosine schedule을 사용
4.2. Evaluation protocols
Frozen Representation Evaluation
- Pre-training 방법의 효율성을 잘 보여주기 위해 평가
- Linear probing: ImageNet-1k의 training 세트를 이용해 projection layer를 학습하고 backbone의 parameter는 freeze
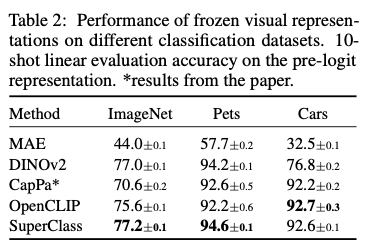
- 10-shot classification: ImageNet-1k, Pets, Cars dataset에서 10-shot classification를 수행하여 평균 및 분산 결과를 비교
- Locked-image Tuning (LiT): pre-training된 vision backbone이 zero-shot classification 및 retrieval 능력을 갖출 수 있도록 image model을 freeze한 상태에서 text model과의 constrastive training을 수행
- Language model과의 collaboration: pre-training된 vision backbone과 text decoder의 collaboration 가능성을 평가, ClipCap 및 LLaVA 설정을 따름
4.3. Main results
- 다양한 pre-training 방법과의 비교: SuperClass model이 constrastive learning, clustering, reconstruction, vision-language pre-training 기반 방법들보다 성능이 우수
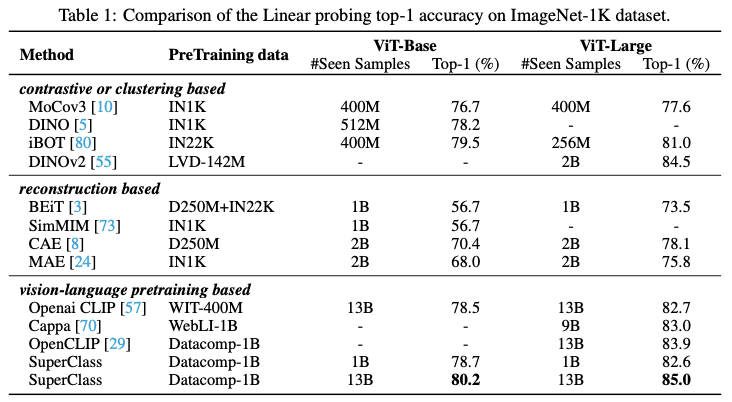
- DINOv2와의 비교: DINOv2는 multi crop, mask image modeling, constrastive learning을 사용하는 반면, SuperClass는 단순한 classification 기반 프레임워크로 0.5% 높은 ImageNet-1K linear probing 정확도를 기록
- CLIP와의 비교: SuperClass는 CLIP 대비 ViT-Base와 ViT-Large backbone에서 더 높은 linear probing 정확도를 보이며, OpenCLIP와 비교해도 IN-1K와 Pets에서 높은 성능 향상을 보여줌
- Zero-shot classification에서의 성능 비교: SuperClass는 ImageNet-1k에서 OpenAI CLIP ViT-L/14보다 높은 zero-shot 정확도를 기록하며, 강력한 visual recognition 성능을 보여줌
- COCO captioning에서의 성능: COCO captioning에서 OpenAI의 CLIP보다는 낮은 CIDEr 점수를 기록했지만, 동일 설정에서 구현한 CLIP model보다 높은 성능을 나타냄
Large scale multi modal model
- SuperClass model과 Vicuna-7B를 결합해 LLaVA 설정을 따르고, 다양한 vision-language downstream task 수행
- VQAv2, T-VQA, MMBench와 같은 OCR 및 세부 recognition task에서 CLIP model보다 더 우수한 성능을 보여줌
Model Scaling Result
- Model 크기에 따른 성능을 평가한 결과, SuperClass는 CLIP 대비 classification 및 LLaVA downstream task에서 더 높은 정확도를 보여줌
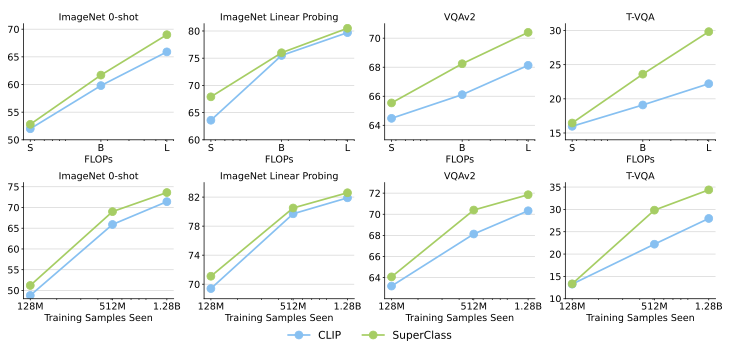
Data Scaling Result
- 같은 수의 학습 샘플을 사용한 경우 SuperClass가 CLIP을 능가하는 정확도를 나타내며, text encoder가 필요 없기 때문에 training efficiency도 더 높음
4.4. Ablations
Word-level Tokenizer vs. Subword-level Tokenizer
- Table 4: 여러 downstream task에서 word level과 subword level tokenizer의 성능 비교

- CLIP에서 사용하는 subword level tokenizer와 약 40,000개의 "gold labels"를 사용하는 CatLIP의 word level tokenizer를 비교
- ViT-S/16에서는 word level tokenizer가 더 나은 classification 정확도를 보였는데, 이는 제한된 model 용량에서 필터링된 clean data가 model 수렴에 더 도움이 되기 때문일 수 있음
- 그러나 model이 커질수록, subword level tokenizer는 classification 및 vision-language task 모두에서 word level tokenizer를 능가
- 전반적으로, subword level tokenizer는 scalability 측면에서 더 우수하고 large scale multi modal model에 더 적합함
다양한 subword level tokenizer 비교
- Table 5: classification 및 LLaVA downstream task에서 서로 다른 subword level tokenizer의 성능 비교
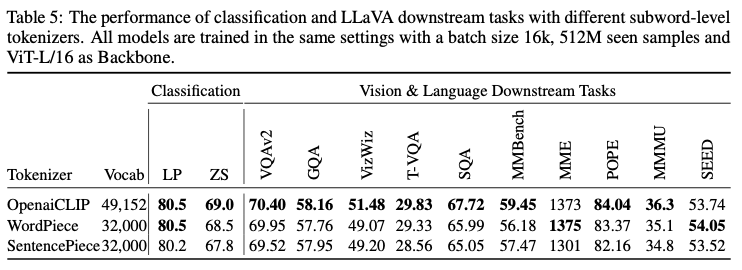
- CLIP에서 사용된 byte pair encoding tokenizer, BERT의 WordPiece tokenizer, LLama의 SentencePiece tokenizer를 비교
- CLIP에서 사용된 tokenizer가 classification 및 LLaVA task에서 최고의 성능을 보여, SuperClass model training에 이 tokenizer를 선택
Classification Loss
- Table 6: ImageNet-1k dataset에서 다양한 classification loss function 성능 비교
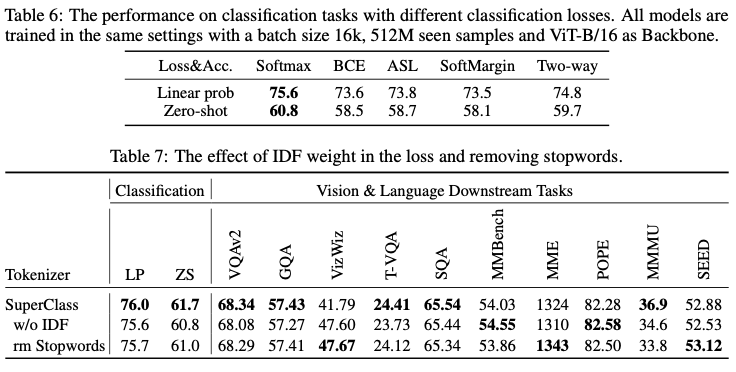
- Softmax, BCE, ASL, Soft margin, Two-way loss 등 여러 multi label classification loss function를 실험
- 단순한 Softmax loss이 다른 multi label classification loss보다 크게 우수한 성능을 보임
- Image-text data는 noise이 많고, text가 image의 모든 내용을 표현하지 못하기 때문에, 더 나은 loss function 설계가 필요
IDF를 class weight로 사용
- Table 7: IDF를 class weight로 사용할 때와 사용하지 않을 때의 성능 비교
- IDF를 사용하지 않으면 classification 정확도가 상당히 감소, LLaVA task에서는 큰 차이가 나타나지 않음
불용어 제거 여부
- Text mining과 NLP에서 불용어는 유용한 정보를 거의 담고 있지 않으므로 제거하는 것이 일반적
- 그러나 Table 7 결과에 따르면, 불용어를 유지하는 것이 classification task에서 더 나은 성능을 보여줌
5. Limitation and Conclusion
Comparison
- Constrastive learning과 classification 기반 pre-training을 비교한 결과, classification 방식으로 pre-training된 model이 CLIP model을 classification 및 vision-language task에서 더 우수한 성능을 보임
- Text encoder가 필요 없어 CLIP보다 학습 효율이 높음
- classification 기반 pre-training 방식은 model과 data의 size가 커질수록 scalability가 유리할 가능성이 있음
Limiation
- 비록 다양한 downstream task에서 좋은 성능을 보여주었으나, word 순서와 object 간 관계를 무시하여 중요한 감독 정보를 잃을 수 있음. 이를 개선하는 것이 향후 연구의 방향이 될 예정
Conclusion
- 단순한 image classification가 image-text data를 사용한 vision backbone pre-training의 효과적인 전략이 될 수 있음을 증명
- 앞으로 classification 기반 pre-training의 가능성과 이점을 탐구하는 연구가 이어지기를 기대

AI Research Engineer