https://arxiv.org/abs/2509.02379
1. Introduction
Medical Imaging and Segmentation Challenges
- Medical Imaging Modalities: Computed Tomography (CT)와 Magnetic Resonance Imaging (MRI)은 현대 방사선학의 핵심으로, 해부학적 구조와 이상 징후를 상세히 시각화
- Organ-at-Risk (OAR) and Tumor Segmentation: 치료 계획과 질병 모니터링에 필수적이나, 수동 Annotation은 노동 집약적이고 시간이 많이 소요됨
- Deep Learning Limitations: 딥러닝은 자동화를 가능케 하지만, 기존 접근법은 개별 데이터셋이나 장기 시스템에 특화된 아키텍처에 의존하며, modality와 기관 간 일반화 성능이 제한적
Foundation Models and Self-Supervised Learning
- Foundation Models (FMs): 대규모 레이블 없는 데이터로 사전 학습된 통합 Vision Backbone으로, 다양한 Downstream 작업에 Adaptation 가능
- Self-Supervised Learning (SSL): Raw pixel 데이터로 수동 Annotation 없이 학습, Transfer 가능한 표현 생성
- DINOv2 and DINOv3: 자연 이미지에서 강력한 Global 및 Local Feature을 생성하며, 분류, 검출, Segmentation 작업에서 뛰어난 성능
- Challenge in Medical Imaging: 개인정보 보호로 인해 의료 Vision Foundation Model을 처음부터 학습하기 위한 수십억 규모 데이터 확보가 불가능
Research Question and Proposed Solution
- Question: 웹 규모 자연 이미지에서 학습된 표현이 방사선 이미징에 효과적으로 Transfer될 수 있는가
- Empirical Finding: DINOv3는 의료 이미지 Segmentation에서 유망한 성능을 보이지만, 두 가지 주요 도전 과제 존재
- Vision Transformers (ViTs) Limitations: ViT 기반 FM은 Dense Prediction 작업에서 강력한 CNN 기준선에 비해 성능이 뒤처짐
- Domain Gap: 자연 이미지와 의료 이미지 간 상당한 Domain 차이로 인해 사전 학습된 표현의 직접 Transfer가 어려움
- MedDINOv3 Proposal: 의료 이미지 Segmentation을 위한 효과적인 프레임워크로, DINOv3를 기반으로 다음과 같은 해결책 제시
- Simple ViT Architecture for 2D Medical Segmentation
- ViT를 재검토하여 2D 의료 이미지 Segmentation에 최적화된 설계 제안
- Multi-Scale Feature Aggregation: 중간 Transformer 블록의 패치 토큰을 재사용해 계층적 표현 생성, ViT의 약한 지역성 바이어스 완화
- High-Resolution Training: 고해상도 학습으로 더 풍부한 공간적 맥락 제공
- 성과: AMOS22 데이터셋에서 ViT-B의 DSC(Dice Similarity Coefficient)가 78.39%에서 85.51%로 향상
- Domain-Adaptive Pretraining on CT-3M
- CT-3M Dataset: 16개 데이터셋에서 수집한 대규모 축상 CT 슬라이스 컬렉션
- Three-Stage Pretraining
- Global/Local Self-Distillation: DINOv2 스타일로 Global 및 Local Feature 학습
- Gram Anchoring: 패치 수준 일관성 유지, Local Feature 붕괴 방지(선택적 적용 가능)
- High-Resolution Adaptation: 방사선 데이터 분포에 모델 정렬, 고해상도에서 부드러운 Feature Maps 생성
- 각 단계의 기여도를 체계적으로 분석하여 Segmentation 성능에 미치는 영향 정량화
- Simple ViT Architecture for 2D Medical Segmentation
Key Contributions
- Simple ViT Architecture for 2D Medical Segmentation
- 중간 패치 토큰을 활용한 다중 스케일 토큰 집계와 고해상도 학습으로 ViT-B 성능 대폭 향상 (AMOS22에서 DSC 78.39% → 85.51%)
- Domain-Adaptive Pretraining on CT-3M
- 16개 데이터셋에서 축상 CT 슬라이스를 수집한 CT-3M으로 DINOv3를 Adaptation, 방사선 데이터에 최적화
- 세 단계 사전 학습(Global/Local Self-Distillation, Gram Anchoring, 고해상도 Adaptation)으로 성능 최적화
- State-of-the-Art Performance
- 4개 공개 CT/MRI 벤치마크(AMOS22, BTCV, KiTS23, LiTS)에서 강력한 CNN 및 Transformer 기준선을 능가 또는 동등
- OAR Segmentation: AMOS22에서 nnU-Net 대비 +2.57% DSC, BTCV에서 +5.49% DSC
- Tumor Segmentation: KiTS23에서 70.68% DSC, LiTS에서 75.28% DSC로 경쟁력 있는 성능
- Domain Adaptation 사전 학습의 효과로 Vision Foundation Model을 방사선학에 성공적으로 Transfer
2. Related Work
2.1. Medical Vision Foundation Models
- Self-Supervised Learning (SSL): 의료 데이터의 Annotation 부족 문제를 해결하기 위해 SSL이 의료 Vision Foundation Model 개발의 핵심 전략으로 부상
- Models Genesis: CT와 MRI에서 Pretext Reconstruction 작업의 이점을 입증
- SwinUNETR with SSL Pretraining: 3D CT 벤치마크에서 상당한 성능 향상
- Masked Image Modeling (MIM): 의료 Domain에 적용, MIM 사전 학습 인코더가 장기 Segmentation 데이터셋에서 성능 크게 개선
- Adapting Natural-Image FMs: DINOv2와 같은 자연 이미지 FM을 방사선학에 Adaptation
- Baharoon et al.: 자연 이미지 SSL Feature가 분류 작업에 잘 Transfer되지만, Segmentation에서는 Domain 사전 학습 모델에 비해 성능이 뒤처짐
- Our Approach: 대규모 Domain Adaptation SSL 사전 학습으로 성능 격차 해소
2.2. Vision Transformers in Medical Image Segmentation
- Vision Transformers (ViTs): 의료 이미지 Segmentation에서 광범위하게 탐구
- TransUNet: U-Net의 병목에 Transformer 레이어 통합
- LeViT-UNet: 효율적인 Attention 메커니즘으로 유사한 설계
- UTNet: 다중 해상도에서 Transformer 블록 사용
- CoTr: 단일 Transformer로 여러 해상도의 Feature 공동 모델링
- UNETR: ViT 인코더 직접 사용, Transformer 중심 설계로 전환
- SwinUNETR: Swin Transformer 통합
- Primus: 복잡한 디코더를 해체하고 인코더 전용 아키텍처로 CNN 성능에 근접
- Benchmark Insights: CNN 기반 nnU-Net이 여전히 강력한 기준선
- Our Goal: ViT의 아키텍처 설계를 개선하고 Domain Adaptation SSL 사전 학습을 통해 의료 Segmentation에서 ViT의 잠재력을 완전히 구현
3. Method
Overview
- Vision Foundation Models (FMs): 대규모 데이터셋에서 사전 학습된 모델은 자연 이미지에서 뛰어난 성능을 보이지만, 의료 이미징에 직접 적용은 표현 차이와 아키텍처 설계 차이로 인해 어려움
- Proposed Approach:
- 의료 이미지 Segmentation을 위한 Vision Transformer의 반복적 개선
- DINOv3를 활용한 CT 이미지 Domain Adaptation 사전 학습
- 학습된 표현을 다양한 의료 Segmentation 작업에 Transfer
- Framework Visualization: 전체 프레임워크는 아래 Figure 2에 제시
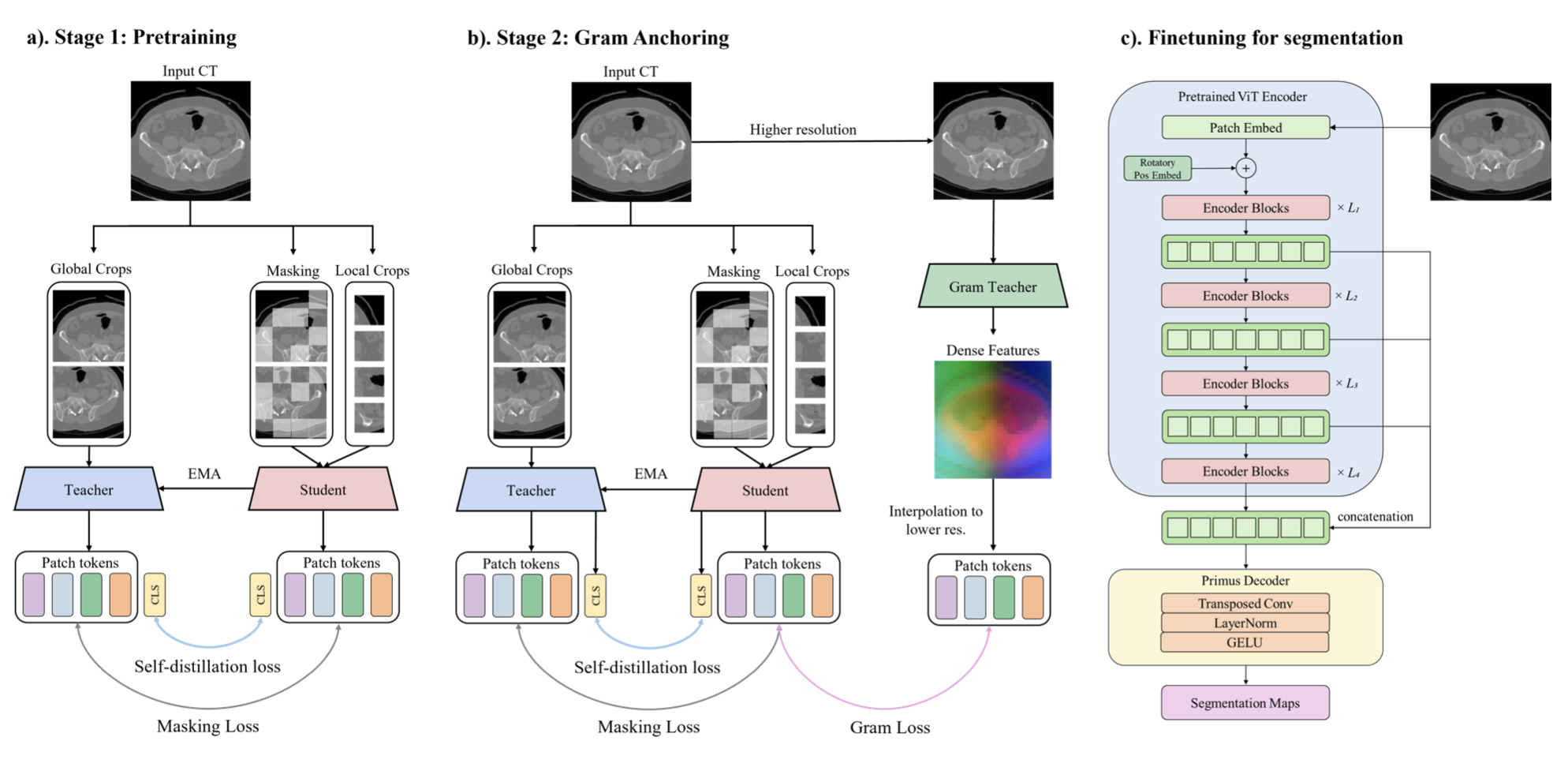
3.1. Rethinking Transformers for Medical Image Segmentation
- Challenges with Vision Transformers (ViTs): 자연 이미지에서 확장 가능성 입증에도 불구, 의료 이미지 Segmentation에서 일관된 성능 향상 미흡
- Transformer 블록은 Segmentation 모델에서 최종 성능에 거의 기여하지 않으며, 강력한 CNN 기준선 대비 성능 저하
- Primus Approach: 경량 Transposed Convolution 디코더를 사용한 단순 Transformer 아키텍처 제안, 3D 체적 Segmentation에서 만족스러운 성능
- Limitations of Primus: 공간적 사전 정보 부족으로 Dense Segmentation에 필수적인 Local Feature 약화, 패치 크기 16에서 8로 변경은 계산 부담 증가 및 DINOv3 스타일 사전 학습에 부적합
- Proposed Refinement: 2D 의료 이미지 Segmentation을 위해 Plain ViT 재검토, DINOv3 Backbone을 효과적인 Segmentation Backbone으로 Adaptation
- Development Datasets:
- AMOS22: 300개 CT 체적과 60개 MRI 체적으로 구성된 복부 장기 Segmentation 데이터셋, 15개 장기 Annotation
- Training Strategy: Primus와 유사하게 5겹 교차 검증의 단일 폴드(80/20 분할)로 학습 및 평가, nnU-Net 기본 설정을 따라 1000 Epoch 학습, Primus에서 가져온 하이퍼파라미터 적용
- Baseline:
- DINOv3 ViT-B 인코더와 Primus 디코더(Transposed Convolution, LayerNorm, GELU 활성화로 구성) 사용
- 패치 토큰을 전체 해상도 Segmentation 맵으로 업샘플링, Convolution 영향 최소화 및 Transformer 표현 영향 극대화
- 무작위 초기화 기준 합리적 성능 제공, 하지만 감독 학습 CNN 대비 뒤처짐
- Leveraging Pretrained DINOv3:
- LVD-1689M에서 사전 학습된 DINOv3로 ViT 인코더 초기화
- 무작위 초기화 대비 DSC 2.96% 향상, 웹 규모 SSL Feature의 의료 Segmentation Transfer 가능성 강조
- Multi-Scale Token Aggregation:
- Observation: Primus는 마지막 Transformer 블록만 디코더 입력으로 사용, 계층적 사전 정보 부족으로 ViT의 강력한 Local Feature 학습 제한
- Proposal: 중간 레이어(블록 2, 5, 8, 11) 패치 토큰 재사용 및 디코더 입력으로 결합
- Effect: ViT의 약한 공간적 사전 정보 보완, AMOS22에서 DSC 2.10% 향상 (아래 Table 1)
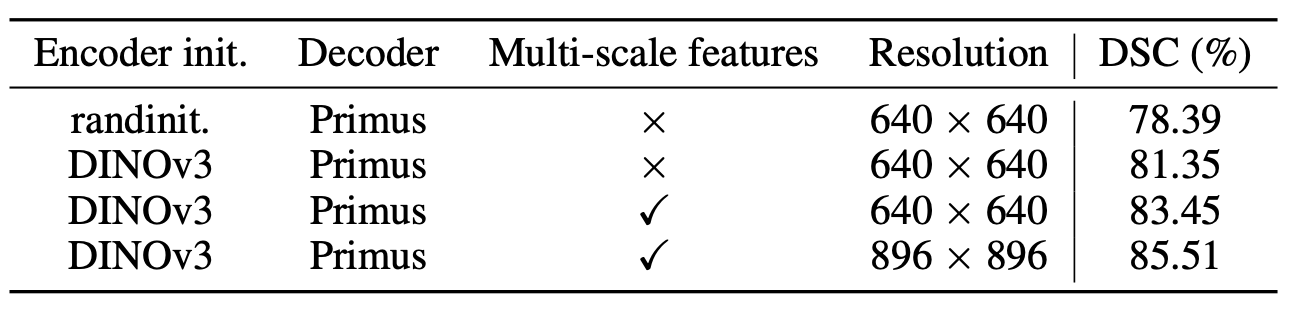
- Higher Resolution Training:
- Primus Limitation: 패치 크기를 16에서 8로 줄여 Local 정보 보존, 하지만 계산 부담 증가로 기존 Vision FM에 부적합
- Proposal: 축상 슬라이스를 더 얇은 간격으로 리샘플링하여 고해상도 Segmentation 학습, DINOv3 따라 입력 해상도 896×896 유지
- Effect: 해상도 640×640에서 896×896으로 증가 시 AMOS22에서 DSC 2.06% 향상 (위 Table 1)
3.2. Domain-Adaptive Pretraining on CT-3M
- Objective: 다양한 대규모 의료 이미징 데이터셋 CT-3M으로 MedDINOv3 사전 학습, 의료 이미징에 표현 정렬
- Data Curation:
- CT-3M Dataset: 16개 공개 데이터셋에서 총 3,868,833개의 축상 CT 슬라이스 수집 (BTCV, Pancreas-CT (TCIA), CHAOS, LiTS, KiTS, WORD, AbdomenCT-1K, AMOS22, Medical Segmentation Decathlon의 5개 CT 작업(Liver, Lung, Pancreas, Hepatic Vessel, Spleen, Colon), CT-ORG, TotalSegmentator, AbdomenAtlas 3.0)
- Coverage: 복부, 흉부, 골반 영역의 100개 이상 구조 포함, Domain Adaptation 사전 학습을 위한 규모와 이질성 확보
- Preprocessing: 모든 3D 체적을 0.45mm×0.45mm 평면 내 간격으로 리샘플링, 256×256 균일 해상도로 크기 조정
- Three-Stage Pretraining (DINOv3 기반):
- Stage 1: Global/Local Self-Distillation:
- DINOv2 손실 사용
- LDINO: Global-Local crop 불변성 강제하는 이미지 수준 목표
- LiBOT: Local 패치 대응 학습하는 패치 수준 잠재 재구성 목표
- LKoleo: 배치 내 Feature가 잠재 공간에서 균일하게 분포하도록 유도하는 정규화 손실
- Loss Function:
- 100k 반복 학습, Learning rate 2e-4
- DINOv2 손실 사용
- Stage 2: Gram Anchoring:
- Observation: DINOv2 학습에서 Global 손실이 학습 진행 시 지배, 패치 수준 품질 점진적 저하
- Solution: 패치 수준 일관성 저하 완화 위해 Gram Anchoring 도입
- Gram Matrix: 이미지의 패치 Feature Matrix에 대한 쌍별 내적 Matrix, Student의 Gram Matrix를 초기 고품질 Gram Teacher(EMA Student 네트워크의 초기 체크포인트)와 정렬
- Loss Function:
- , : 각각 Student와 Gram Teacher의 L2 정규화된 Local Feature Matrix (, : 패치 수, : Feature 차원)
- Implementation: 100k 반복 후 시작, 20k 반복 진행, Gram Teacher에 512×512 고해상도 이미지 입력 후 2배 다운샘플링하여 Student 출력과 공간 차원 일치
- Loss Function:
- Learning rate 5e-5, Gram Teacher는 20k 반복 시점 EMA 모델 사용
- Stage 3: High-Resolution Adaptation:
- 다양한 해상도(Global crop 512–768, Local crop 112–336) 혼합으로 고해상도 이미지 처리 Adaptation
- Gram Anchoring 유지하여 패치 Similarity 구조 안정화
- 10k 반복 학습, Learning rate 2.5e-5
- Effect: 고해상도 Adaptation으로 Dense Feature 품질 크게 향상 (Figure 3)
- Stage 1: Global/Local Self-Distillation:
- Implementation Details:
- 총 120k 반복 학습, Global 배치 크기 512
- LVD-1689M에서 사전 학습된 DINOv3 ViT-B 체크포인트로 초기화
- Stage 1: 100k 반복, Learning rate 2e-4
- Stage 2: 20k 반복 시점 EMA 모델로 Gram Teacher 선택, 10k 반복, Learning rate 5e-5
- Stage 3: Stage 2 모델로 Teacher와 Student 초기화, 10k 반복, Learning rate 2.5e-5
4. Results
4.1. Experiment Settings
- Evaluation Datasets: 2D Segmentation 방법의 포괄적 평가를 위해 4개의 공개 데이터셋에서 광범위한 실험 수행
- Tasks and Modalities: OAR(장기-at-risk) 및 Tumor Segmentation 작업 포함, CT와 MRI 등 다양한 이미징 modality 포괄
- Datasets:
- AMOS22: 복부 장기 Segmentation, 300개 CT 체적과 60개 MRI 체적, 15개 장기 Annotation
- KiTS23: 신장 Tumor 데이터셋, 489개 CT 체적, 신장, Tumor, 낭종 Annotation
- LiTS: 간 Tumor Segmentation, 131개 CT 체적, 간 및 Tumor 클래스 Annotation
- BTCV: 조영제 사용 복부 CT 데이터셋, 50개 스캔, 13개 장기 수동 Segmentation
- Training and Evaluation: 높은 계산 비용으로 인해 기본 5겹 교차 검증에서 단일 폴드(80/20 분할)로 학습 및 평가
- Metrics: Dice Similarity Coefficient (DSC)와 Normalized Surface Dice (NSD) 사용
- Implementation Details:
- Framework: PyTorch 기반 nnU-Net 프레임워크에서 학습 및 평가
- Training Configuration: 모든 모델 1000 Epoch 학습, 각 Epoch 250 스텝, 입력 패치 크기, 배치 크기, Voxel 간격은 nnU-Net 계획에 따름
- Compared Methods:
- nnU-Net: 강력한 감독 학습 CNN 기준선
- Learning rate 1×10⁻², 가중치 감쇠 3×10⁻⁵, 그래디언트 클리핑 12, Nesterov 모멘텀(0.99) 사용 SGD 최적화, PolyLR 스케줄러
- SegFormer: 계층적 Transformer 모델, 경량 MLP 디코더로 다중 레벨 Feature 융합
- Learning rate 5×10⁻⁵, AdamW 최적화
- DINO U-Net: DINOv3 통합 지원 U-Net 아키텍처, 인코더 Backbone 고정, nnU-Net 하이퍼파라미터 사용
- MedDINOv3: 제안 방법, Primus에서 하이퍼파라미터 조정, 입력 해상도 896×896
- Learning rate 3×10⁻⁴, 가중치 감쇠 5×10⁻², DropPath 비율 0.2, LayerScale 값 1×10⁻⁵, AdamW 최적화 (betas: 0.9, 0.98)
- nnU-Net: 강력한 감독 학습 CNN 기준선
4.2. Comparisons with State-of-the-Art Methods
- Benchmark Results:
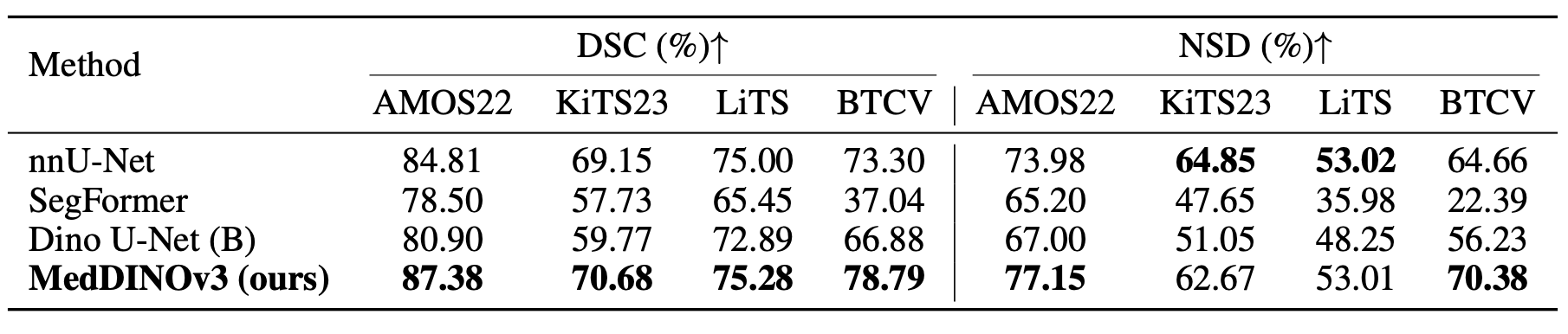
- MedDINOv3 Performance:
- AMOS22에서 nnU-Net 대비 DSC 2.6% 향상
- BTCV에서 nnU-Net 대비 DSC 5.49% 향상
- Tumor Segmentation 데이터셋: KiTS23에서 DSC 70.68, LiTS에서 DSC 75.28로 nnU-Net과 동등
- Boundary Accuracy: OAR Segmentation에서 강력한 NSD 점수 유지, Tumor 데이터셋에서는 nnU-Net에 약간 뒤짐
- DINO U-Net: DINOv3 기반에도 nnU-Net을 초과하지 못함, 계층적 CNN 디코더 의존성 때문으로 추정
- SegFormer: 자연 이미지 Segmentation용으로 개발, 모든 데이터셋에서 성능 저하, 약한 유도 바이어스와 대규모 레이블 데이터 의존성 반영
- MedDINOv3 Performance:
- Conclusion: 아키텍처 개선과 Domain Adaptation 사전 학습 결합으로 의료 이미징에 Transfer 가능한 표현 생성, nnU-Net 기준선을 여러 경우 초월하며 격차 좁힘
4.3. Ablation Study
- Gram Anchoring Analysis:
- CT-3M Pretraining Effect:

- Stage 1: DINOv2 스타일 사전 학습으로 DSC 1.07% 향상, 우수한 Dense Feature 학습 효과 강조
- Stage 2: Gram Anchoring 적용 시 추가 성능 향상 미미, Stage 1에서 패치 토큰 품질 저하가 적었기 때문으로 추정
- Visualization: Figure 4에서 패치 토큰 품질 확인
- Stage 3: 고해상도 Adaptation으로 DSC 0.84% 향상, Feature Map 일관성 유지
- CT-3M Pretraining Effect:
- Findings: Gram Anchoring은 선택적, 고해상도 Adaptation이 Dense Feature 품질과 Segmentation 성능에 더 큰 기여
5. Conclusion
- MedDINOv3 Framework: Vision Foundation Model을 의료 이미지 Segmentation에 Adaptation 시키기 위한 간단하면서도 효과적인 프레임워크 제시
- Architectural Refinements:
- 2D 의료 이미지 Segmentation을 위해 Plain Vision Transformer 개선
- Multi-Scale Token Aggregation: 공간적 사전 정보 강화
- High-Resolution Training: 지역적 세부 구조 보존
- Domain-Adaptive Pretraining:
- CT-3M Dataset: 대규모 CT 데이터셋 구축
- DINOv3 기반 3단계 사전 학습 수행
- Stage 1 (DINOv2-style Self-Distillation): Feature Transfer 가능성 크게 향상
- Stage 3 (High-Resolution Adaptation): Feature Transfer 가능성 추가 개선
- Stage 2 (Gram Anchoring): 본 설정에서 추가 이점 미미
- Performance:
- 장기-at-risk Segmentation에서 강력한 CNN 및 Transformer 기준선 초월 또는 동등
- Tumor Segmentation 작업에서 경쟁력 있는 성능
- Key Insight: 간단한 ViT 기반 아키텍처와 Domain Adaptation 사전 학습 결합으로 전문화된 CNN 성능 격차 좁히거나 초월
- Significance: 타겟 아키텍처 개선과 Domain 정렬 사전 학습으로 Foundation Model을 의료 이미지 Segmentation에 효과적이고 일반화 가능하게 Adaptation, 강력한 솔루션 제공

AI Research Engineer