https://arxiv.org/abs/2508.10104
1. Introduction
Foundation Models and Self-Supervised Learning (SSL)
- Foundation model: 현대 Computer vision에서 단일 모델로 다양한 작업과 도메인에 걸쳐 일반화를 가능하게 하는 핵심 구성 요소
- Self-Supervised Learning (SSL): 원시 Pixel 데이터와 Image 내 패턴의 자연스러운 동시 발생을 활용해 Foundation model을 학습시키는 강력한 방법
- 고품질 메타데이터가 필요한 Supervised learning 방식과 달리, SSL은 대규모 레이블 없는 Image 데이터로 학습 가능
- 무제한에 가까운 원시 데이터로 대규모 Vision Encoder 학습에 효과적
- DINOv2 Example: SSL의 강점을 보여주며, 다음에서 뛰어난 성과를 달성
- Image 이해 작업
- 조직병리학 같은 복잡한 도메인
- 입력 분포 변화에 강인하고, 강력한 전역/지역 Feature와 물리적 장면 이해를 위한 풍부한 Embedding 제공
- SSL의 장점
- 작업별 Fine-tuning 없이 다재다능하고 강인한 일반 Feature 생성
- 관측 데이터는 많지만 메타데이터가 부족한 도메인(예: 조직병리학, 생물학, 의료 영상, 원격 탐사, 천문학, 고에너지 물리학)에 적합
- 인간 개입 없이 웹 데이터 증가에 맞춰 평생 학습에 적합
Challenges in Scaling SSL
- SSL의 무제한 데이터로 큰 Foundation model을 만드는 잠재력에도, 스케일링은 다음 도전을 동반
- Data curation: 레이블 없는 데이터에서 유용한 데이터 선택 방법 불명확
- Optimization horizon: 코사인 스케줄은 사전에 학습 기간을 알아야 하며, 대규모 Image 데이터 학습에 어려움
- Feature degradation: ViT-Large(3억 Parameter) 이상 모델에서 긴 학습 시 Patch 유사도 맵에서 관찰되는 Dense Feature maps 성능 저하
- DINOv3 Solution: 이러한 문제를 해결해 SSL을 대규모로 발전시키며, 다양한 다운스트림 작업에서 최첨단 성능을 제공하는 범용 Vision Encoder 제공
Objectives of DINOv3
-
Versatile Foundational Models
- 작업과 도메인에 걸쳐 유연한 Foundation model 학습, Fine-tuning 없이 최첨단 성능 달성
- 단일 순방향 패스로 여러 작업에서 최첨단 결과 제공, 특히 엣지 디바이스에서 계산 효율성 증대
- 메타데이터 없이 웹 Image나 관측 데이터를 포함한 다양한 Image로 Pre-training해 도메인과 작업에 일반화
- 예: 고해상도 항공 Image에서 DINOv3 Feature의 PCA는 도로, 집, 녹지를 명확히 구분 (아래 Fig. 1(d))

-
Improved Dense Features
- Image 이해와 같은 고수준 의미 작업 및 깊이 추정, 3D 매칭 같은 기하학적 작업에 탁월한 Dense Feature maps 생성
- 대규모 모델과 긴 학습에서 Dense Feature maps 붕괴를 Gram anchoring strategy로 해결
- DINOv3는 DINOv2보다 고해상도에서도 더 깨끗한 Dense Feature maps 생성 (아래 Fig. 3)

-
DINOv3 Model Family
- 70억 Parameter 모델 학습 후, ViT-Small, Base, Large 및 ConvNeXt 기반 아키텍처로 Distillation
- Distillation으로 실용적 모델이 70억 모델에 근접한 성능 유지
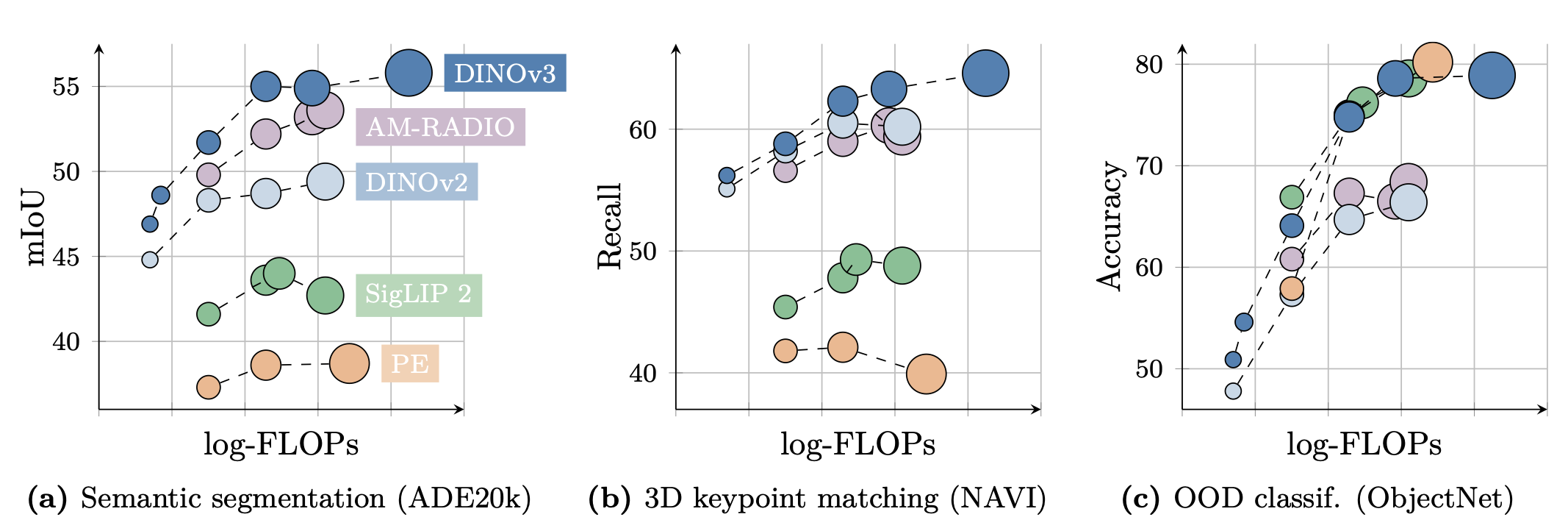
- Dense prediction tasks(예: COCO detection mAP 66.1, ADE20k mIoU 63.0)에서 경쟁 모델을 크게 앞지르며, Global tasks에서도 CLIP 파생 모델과 유사한 성능 (아래 Fig. 2)
Key Contributions
- Data Scaling
- 자동으로 curation 한 대규모 웹 데이터(170억)와 ImageNet-1k 같은 특화 데이터를 혼합해 모델의 일반화 성능을 극대화
- Model Architecture and Training
- 70억 Parameter의 맞춤 ViT 아키텍처 정의, 축형 RoPE Positional embedding과 위치 아티팩트 방지 정규화 기법 적용
- DINOv2의 다중 코사인 스케줄 대신 100만 반복 동안 고정 Hyperparameter 스케줄로 학습, 성능 개선
- Gram Anchoring
- Feature maps 노이즈를 제거하는 학습 단계 도입, 파라미터 및 비파라미터 Dense prediction tasks 성능 대폭 향상
- Distillation
- Single-teacher multi-student Distillation 기법 개발, 7B 모델의 지식을 실용적 소규모 모델로 전달
- 결과는 Dense prediction tasks에서 새로운 표준 정의, Global tasks에서 CLIP 파생 모델과 경쟁, 위성 영상에서 기존 접근법 초월 (Sec. 6, Sec. 8)
2. Related Work
Self-Supervised Learning (SSL)
- Self-Supervised Learning (SSL): 레이블 없이 학습하기 위해 인공적인 Pre-text tasks를 설계해 감독 신호를 제공
- Pre-text tasks 설계는 강력한 다운스트림 작업 표현을 학습하는 데 핵심
- 언어 도메인은 이산적 특성 덕분에 Word embeddings, Sentence representations, Plain language models 같은 Unsupervised Pre-training 방식에서 성공
- Computer vision은 신호의 연속적 특성 때문에 더 큰 도전 과제
- 초기 Computer vision SSL 접근법
- Image 일부에서 감독 신호 추출(예: Relative patch position 예측, Patch re-ordering, Inpainting)
- Image repainting, Image converting 예측 같은 작업
- Inpainting-based approaches: ViT 아키텍처의 유연성 덕분에 주목
- Image의 손상된 영역 재구성, Denoising auto-encoding 형태, BERT의 Masked token prediction과 개념적 유사
- Pixel-based Masked Auto-Encoders (MAE)는 다운스트림 작업 Fine-tuning에 강력한 초기화 제공
- Latent space 예측(JEPA: Joint-Embedding Predictive Architecture)은 Pixel space 예측보다 강력한 고수준 Feature maps 생성
- JEPA는 비디오 학습으로 확장
- Discriminative signals 기반 접근법: Image 간 차별적 신호 활용, 본 연구와 더 밀접
- 초기 딥러닝 연구에서 시작, Instance classification 기법으로 인기
- Contrastive objectives, Information-theoretic criteria, Self clustering-based 전략 발전
- iBOT는 Discriminative losses와 Masked reconstruction objectives 결합
- 이러한 방법들은 ImageNet 같은 표준 벤치마크에서 강력한 Feature maps 학습, 하지만 대규모 모델로 확장 시 도전 과제
Vision Foundation Models
- 딥러닝 혁명은 AlexNet의 ImageNet 성능 돌파로 시작
- 대규모 수동 레이블 ImageNet 데이터셋에서 학습한 Feature maps는 다양한 Transfer learning 작업에 효과적
- 초기 Vision Foundation models는 VGG, GoogleNet, ResNets 같은 아키텍처 개발에 초점
- 스케일링 효과로, 3억 레이블 Image JFT 데이터셋으로 감독 학습 데이터 확장, 성능 향상
- 감독 및 비감독 데이터 조합으로 스케일링 탐구
- ImageNet 감독 모델로 비감독 데이터에 Pseudo-labels 생성, 더 큰 네트워크 학습
- JFT 같은 대규모 감독 데이터셋으로 Transformer 아키텍처를 Vision에 적용(ViT)
- ViT-22B 같은 초대형 Encoder로 스케일링 확장
- Weakly-supervised training: Image와 관련된 메타데이터에서 주석 유도, 감독 학습 대안
- Image Caption 단어 예측, 문장 구조 활용, 메타데이터 Curation, Contrastive losses와 Caption 표현 공동 학습으로 발전
- Align, CLIP은 Weakly-supervised 알고리즘의 잠재력 극대화
- 오픈소스 재현 및 스케일링 노력
- Open-CLIP은 LAION 데이터셋으로 CLIP 재현
- MetaCLIP은 CLIP 절차 정밀 재현, SigLIP은 Sigmoid loss 사용, Perception Encoder(PE)는 86B 샘플로 학습
- 고품질 데이터와 대규모 컴Fu팅 자원이 최첨단 Foundation model의 핵심
- Unsupervised Image Pre-training 스케일링 연구는 상대적으로 적음
- YFCC 데이터셋 활용, 더 큰 데이터셋과 모델로 발전
- DINOv2는 SSL 모델로 오픈소스 CLIP 변형과 동등하거나 우수한 성능
- 최근 더 큰 모델 스케일링이나 Data curation 없이 성능 향상
Dense Transformer Features
-
현대 Vision 응용은 Pre-trained transformers의 Dense Feature maps 활용
- 멀티모달 모델, 생성 모델, 3D 이해, 비디오 이해, 로보틱스
- Detection, Segmentation, Depth estimation 같은 전통 Vision 작업은 정확한 지역 Descriptor 필요
-
Local SSL losses 개발: Dense Feature maps 품질 향상
- 비디오의 Spatio-temporal consistency, 동일 Image의 다른 Crop 간 공간적 정렬, 이웃 Patch 간 일관성 강제
- Clustered local patches 예측, Region proposals 기반 Contrastive learning
- ODIN, SlotCon은 Region proposals 전제 완화
- Register tokens 추가로 Dense Feature maps 개선, 학습 없이도 가능
-
Distillation-based agglomerative methods
- 다양한 감독 수준의 Image Encoder 결합
- AM-RADIO는 SAM, CLIP, DINOv2 결합, Perception Encoder는 SAM(v2)을 PEspatial로 Distillation
- Cosine similarity 기반 Student와 Teacher Patch 정렬, Gram matrices 불일치 감소로 효과
- 본 연구는 Gram objective로 Student와 Teacher Patch 간 Cosine similarity 규제, 초기 SSL 모델을 Teacher로 사용
-
Post-hoc improvements: SSL 학습 모델의 지역 Feature maps 개선
- Dense clustering objective로 Fine-tuning, Patch Feature 시간적 정렬, 비선형 Projection으로 컴팩트 클러스터 형성
- SSL Feature maps에 Self-supervised objectives의 Gradient 연결, Patch 가중 평균으로 Noisy Feature maps 개선
-
ViT Feature maps는 Patch화로 저해상도, 최근 고해상도 Feature maps 생성 연구
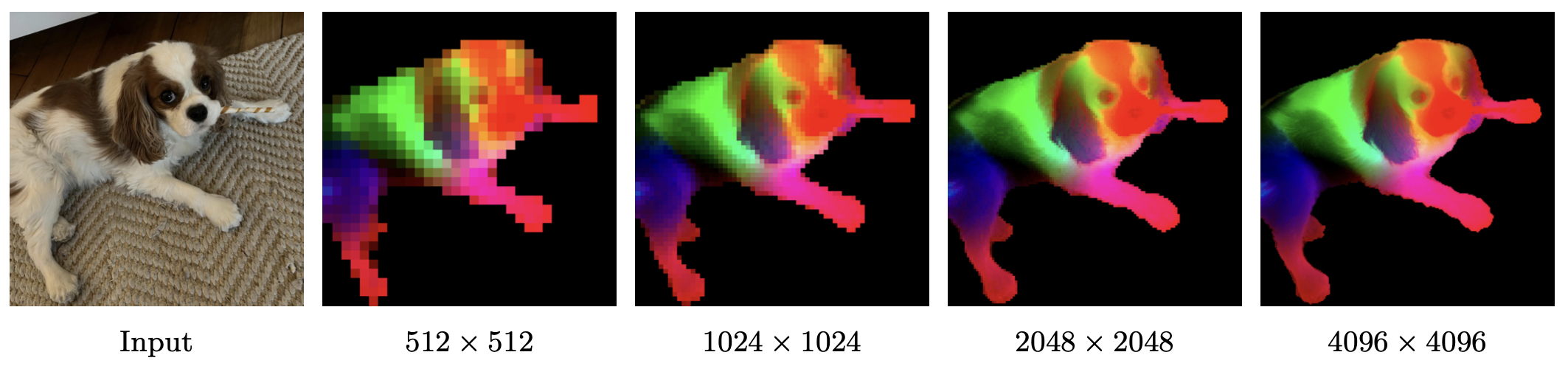
- 본 연구는 고품질 Dense Feature maps를 기본적으로 제공, 해상도 간 안정적이고 일관성 유지 (아래 Fig. 4)
3. Training at Scale Without Supervision
3.1. Data Preparation
-
Data scaling: 대규모 Foundation model 성공의 핵심 요인
- 단순히 학습 데이터 크기 증가만으로는 모델 품질과 다운스트림 벤치마크 성능 향상으로 이어지지 않음
- 성공적인 Data scaling은 신중한 Data curation 파이프라인 필요
- Data curation 목표: 데이터 다양성과 균형 개선 또는 실용적 응용 관련성 강화
-
DINOv3 접근법: 일반화 가능성과 성능 균형을 위해 두 가지 상호 보완적 Data curation 방식 결합
-
Data Collection and Curation
- Instagram 공개 포스트에서 수집한 약 170억 웹 Image 데이터 풀 활용
- 플랫폼 수준 콘텐츠 조정을 거쳐 유해 콘텐츠 방지
- 세 가지 데이터셋 구성
- Hierarchical k-means 기반 자동 Curation: DINOv2의 Image embeddings 사용, 5단계 클러스터링(2억, 800만, 80만, 10만, 2.5만 클러스터)
- 균형 샘플링으로 웹의 모든 시각적 개념을 포괄하는 LVD-1689M(16.89억 Image) 생성
- 클러스터 수를 단계적으로 줄여 시각적 다양성을 유지하고 계산 효율성 향상
- DINOv2의 Image embeddings를 활용해 데이터의 시각적 유사성 효과적으로 포착
- Retrieval-based curation: 다운스트림 작업 관련 시각적 개념을 커버하는 데이터셋 생성
- Raw public datasets: ImageNet1k, ImageNet22k, Mapillary Street-level Sequences 활용, 모델 성능 최적화
- Hierarchical k-means 기반 자동 Curation: DINOv2의 Image embeddings 사용, 5단계 클러스터링(2억, 800만, 80만, 10만, 2.5만 클러스터)
-
Data Sampling
- Pre-training 중 서로 다른 데이터 구성 요소 혼합하는 샘플러 사용
- 아래 두 가지 Batch sampling 방법 사용
- Homogeneous batches: 단일 데이터 소스(예: ImageNet-1k)에서 추출한 배치로, 특정 데이터의 특성을 집중 학습
- Heterogeneous batches: 다양한 데이터 소스를 비율에 따라 혼합한 배치로, 데이터 다양성을 높여 일반화 성능을 강화
- ImageNet1k 단독 Homogeneous batches는 10% 비율로 사용, 고품질 데이터로 성능 향상
-
Data Ablation
- Data curation 기술 영향 평가 위해 Ablation study 수행
- Clustering, Retrieval-based 방법 단독, 원시 데이터 풀과 비교
- 200k 반복 단축 스케줄로 모델 학습, 표준 다운스트림 작업 성능 비교
- 단일 Curation 기술은 모든 벤치마크에서 최적 아님, 전체 파이프라인은 두 세계의 장점 결합 (아래 Tab. 1)

3.2. Large-Scale Training with Self-Supervision
- SSL 모델의 특징: 흥미로운 특성 보여주나, 대규모 모델로 확장 시 Training stability 문제 또는 시각 세계의 복잡성 포착 실패
- DINOv2 Exception: 11억 Parameter, curation 데이터로 학습, CLIP 같은 Weakly-supervised models와 성능 동등
- 70억 Parameter로 확장 시 Global tasks에서 유망하나 Dense prediction 성능 저하
- DINOv3 목표: 모델과 데이터 스케일링으로 Global 및 Local properties 모두 개선된 강력한 Visual representations 학습
- Learning Objective
- SSL을 위해 Discriminative Self-Supervised 전략을 사용하며, Global 및 Local Loss를 결합하여 학습
- LDINO (Image-level Objective):
- Image 전체를 대상으로 학습, Global Features 추출
- LiBOT (Patch-level Latent Reconstruction Objective):
- Patch 단위의 잠재 표현 재구성, Local Features 강화
- Sinkhorn-Knopp Centering:
- DINO의 기존 Centering을 SwAV의 Sinkhorn-Knopp 알고리즘으로 대체, Feature 정규화 개선
- Dedicated Head:
- 각 Objective(, )에 전용 Head 사용, Feature Maps 특화
- Layer Normalization:
- 전용 Layer Normalization 적용으로 안정성 향상
- ImageNet kNN 분류 정확도 +0.2%
- Dense 작업 성능 개선: ADE20k Segmentation +1 mIoU, NYUv2 깊이 추정 -0.02 RMSE
- 전용 Layer Normalization 적용으로 안정성 향상
- LKoleo Regularizer:
- Koleo 정규화를 개선한 형태로, 배치 내 Feature Map이 공간적으로 균일하도록 유도
- 16개 샘플의 소규모 배치에서 분산 학습으로 구현, 안정성과 효율성 향상
- 초기 Training Loss:
- DINOv2의 Training Loss와의 차이:
- DINOv2의 Loss는 아래와 같음
- DINOv2의 Loss는 아래와 같음
- DINOv3에서는 Koleo를 개선한 loss에 고정 가중치 0.1을 사용해 안정성과 단순화 추구
- 는 소규모 배치에서 효율적이며, 고정 가중치로 Hyperparameter tuning 부담을 줄이고, Dense Feature 품질과 학습 안정성을 향상시킴
- DINOv2의 Training Loss와의 차이:
- Updated Model Architecture
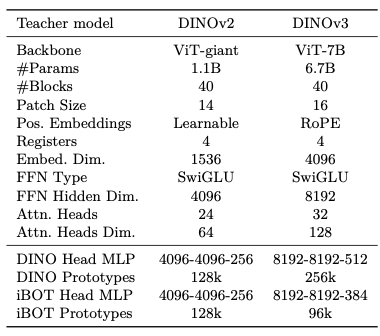
- 70억 Parameter로 모델 스케일링 (아래 Tab. 2, DINOv2 11억 Parameter와 비교)
- 맞춤 RoPE(Rotary Position Embedding) 변형
- RoPE는 원래 NLP에서 Transformer 모델이 토큰의 순서 정보를 학습하기 위해 사용된 Positional embedding 방식
- DINOv3에서는 이를 Vision 작업에 맞게 변형
- Patch 간 상대적 위치 정보를 효과적으로 학습해 Image의 공간적 구조를 더 잘 이해하고, 상세한 시각적 Feature를 추출하기 위함
- 각 Patch에 [-1,1] 정규화 좌표 할당
- 예: Image의 좌상단 Patch는 (-1, -1), 우하단 Patch는 (1, 1)로 좌표가 부여
3x3 Patch일 때의 Position 예시
(-1, -1) (0, -1) (1, -1)
(-1, 0) (0, 0) (1, 0)
(-1, 1) (0, 1) (1, 1)
- 예: Image의 좌상단 Patch는 (-1, -1), 우하단 Patch는 (1, 1)로 좌표가 부여
- Multi-head Attention에서 이 좌표를 사용해 Patch 간 Relative Positional Information를 Bias로 추가
- RoPE는 원래 NLP에서 Transformer 모델이 토큰의 순서 정보를 학습하기 위해 사용된 Positional embedding 방식
- RoPE-box jittering
- Image Pixel 데이터(224x224)를 변경하지 않고, Patch의 Relative Position 스케일만 조정
- [-1,1] 좌표 박스를 [-s,s](s ∈ [0.5,2])로 무작위 스케일링
- 예: s=0.5면 좌표 범위가 [-0.5, 0.5]로 축소, s=2면 [-2, 2]로 확대
- Image는 다양한 해상도(예: 256x256, 512x512)와 종횡비(가로세로 비율, 예: 정사각형 vs 직사각형)로 제공될 수 있음
- 고정된 좌표 시스템(항상 [-1, 1])만 사용하면, 모델이 특정 해상도나 종횡비에만 최적화될 위험이 있음
- RoPE-box Jittering은 좌표를 무작위로 스케일링해 모델이 다양한 해상도와 종횡비에 적응하도록 만듦
- Optimization
- 대규모 모델을 대규모 데이터셋으로 학습하는 것은 복잡한 실험 워크플로우
- 모델 용량과 학습 데이터 복잡성 간 상호작용은 사전에 평가하기 어려워 적절한 Optimization horizon 예측 불가능
- 모든 Parameter 스케줄링 제거
- Constant learning rate, Weight decay, Teacher EMA momentum 사용으로만 학습
- 장점
- 다운스트림 성능이 개선되는 한 학습 지속 가능
- 최적화 Hyperparameter 수 감소로 적절한 선택 용이
- 학습 시작을 위해 Learning rate와 Teacher temperature에 Linear warmup 사용
- AdamW 최적화, 총 배치 크기 4096 Image, 256 GPU 분할
- Multi-crop strategy
- Image당 2 Global crops, 8 Local crops
- Global/Local crops는 각각 256/112 Pixel 정사각 Image
- Patch 크기 변경으로 DINOv2와 동일한 Image당 Sequence length
- 배치당 총 370만 토큰
4. Gram Anchoring: A Regularization for Dense Features
4.1. Loss of Patch-Level Consistency Over Training
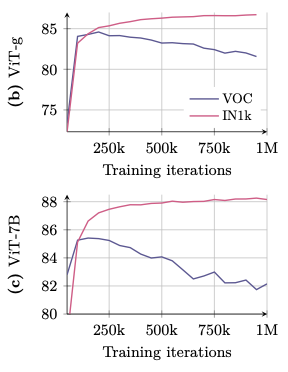
- 장기 학습 시 Global benchmarks 성능 개선, 그러나 Dense tasks 성능 저하 (아래 Figs. 5b, 5c)
-
현상 분석
- DINOv2 학습 및 70억 Parameter 스케일링에서 유사 현상 관찰, 해결되지 않음
- ImageNet-1k에서 CLS token으로 Linear classifier 학습, Top-1 accuracy 보고
- Pascal VOC에서 Patch Feature maps로 Linear layer 학습, mIoU 보고
- ViT-g 및 ViT-7B에서 Classification accuracy 단조 증가, Segmentation 성능은 약 200k 반복 후 저하, ViT-7B는 초기 수준 이하
-
Patch Feature maps 품질 분석
- Patch 간 Cosine Similarity 시각화를 사용하는 이유:
- 지역적 일관성 평가: Cosine Similarity는 Patch Feature vector 간 방향성 유사성을 측정해 Dense Feature Maps의 지역적 일관성(Patch-level Consistency)과 Semantic 품질을 직관적으로 보여줌
- Dense Feature 품질 확인: Segmentation, 깊이 추정 등에서 중요한 지역 세부 정보의 유지 여부를 평가. 높은 유사성은 Patch 간 의미적/기하학적 관계를 반영
- Patch 간 Cosine Similarity 시각화를 사용하는 이유:
-
Patch 간 Cosine similarity 시각화 (아래 Fig. 6)
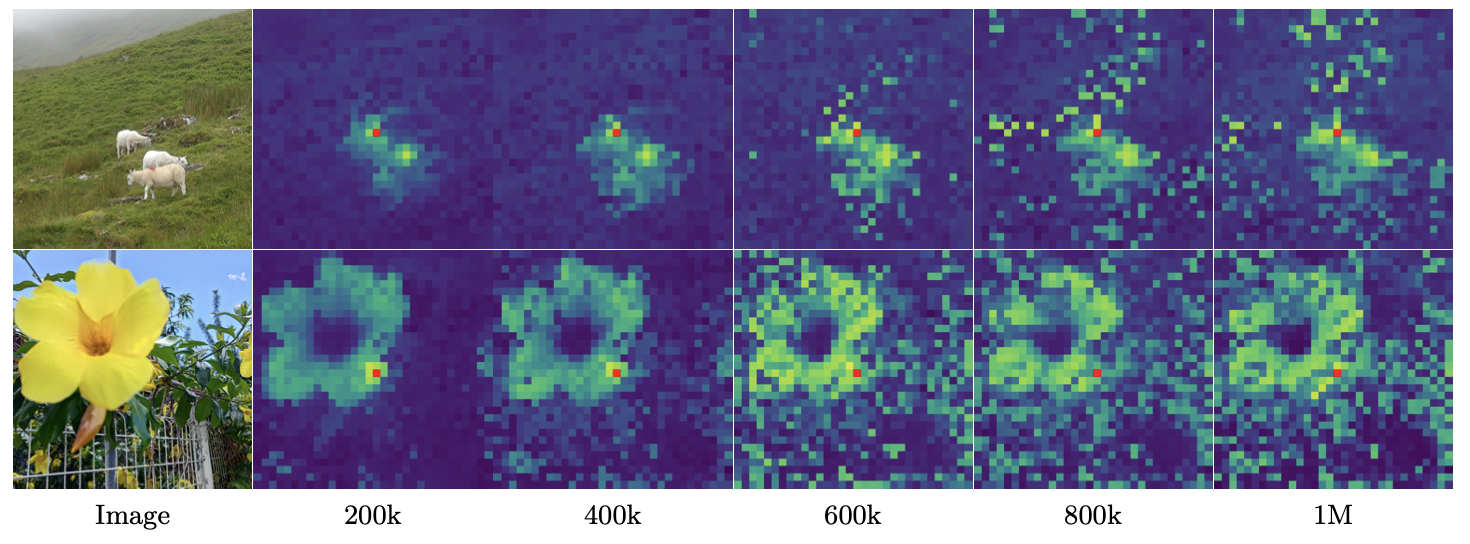
- 200k 반복
- Smooth하고 잘 지역화된 Similarity maps, 일관된 Patch-level representations
- 600k 반복 이후
- Similarity maps 품질 저하, 참조 Patch와 무관한 Patch의 높은 유사성 증가
- Patch-level consistency 손실이 Dense task 성능 저하와 상관관계
- 200k 반복
-
Patch 불규칙성
- 모델 학습 중 Feature map이 일정하지 않게 변동하는 문제
- Register tokens: Patch의 크기(Norm)를 안정화해 일관성을 유지
- Cosine similarity 증가
- CLS token(전체 Image 대표)과 Patch 간 Cosine similarity가 높아지며, Patch의 지역적 특성(Locality)이 줄어드는 현상 발생
- Locality 감소: Patch가 지역적 세부 정보를 잃으면, 예를 들어 객체의 경계나 세부 구조를 구분하는 작업(예: Segmentation)에서 성능이 저하
-
해결책: Patch Feature maps 규제 및 Patch-level consistency 보존을 위한 Gram anchoring 목표 제안
4.2. Gram Anchoring Objective
-
관찰: 강력한 Discriminative features 학습과 Local consistency 유지 간 상대적 독립성
- Global DINO loss와 Local iBOT loss 결합으로 문제 일부 해결, 그러나 학습 진행 시 Global representations 지배로 불균형
-
Gram anchoring 제안
- 의미: Gram anchoring은 학습 중 Patch 간 일관성(Locality)이 떨어지는 문제를 해결하기 위해, Feature map의 품질을 유지하도록 강제하는 방법
- 효과: Feature maps 자체를 바꾸지 않고, 초기 고품질 상태를 기준으로 Patch 간 관계를 안정화해 Dense 작업 성능을 크게 향상시킴
-
Gram matrix based loss
- Gram Matrix: Image의 Patch feature matrix (P: Patch 수, d: feature 차원)에 대해, Gram matrix는 로 계산되어 Patch 간 쌍별 내적(Similarity)을 나타냄
- 즉, Feature maps의 Patch 간 관계를 나타내는 matrix
- Student 모델의 Gram matrix를 초기 고품질 Teacher 모델의 Gram matrix 에 맞춰 Patch 일관성을 유지
- Loss function:
-
적용 방식
- Global crops에만 계산, 효율성을 위해 100만 반복 후 적용
- 늦게 적용해도 저하된 Local Feature maps 복구
- Gram teacher 10k 반복마다 EMA Teacher와 동일하게 갱신
-
Refinement step:
-
영향 분석 (아래 Fig. 7)
- Gram objective 적용 시 iBOT loss 빠르게 감소, 안정된 Gram teacher가 iBOT objective 안정화
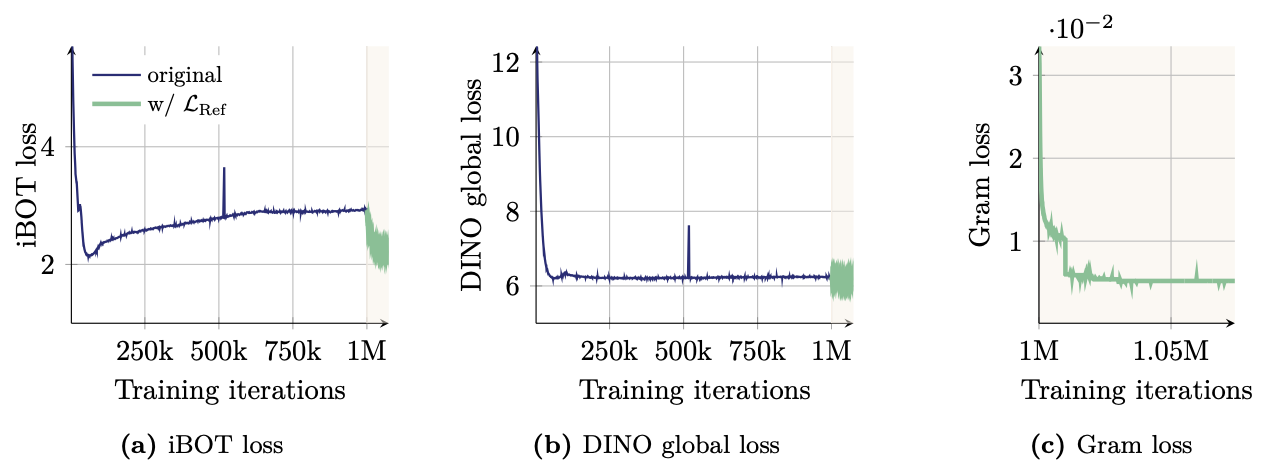
- DINO loss에는 큰 영향 없음, Gram 및 iBOT objectives는 Feature maps에 유사한 영향, DINO loss는 다르게 작용
-
성능 향상 (아래 Fig. 8)
- Gram anchoring 도입 후 10k 반복 내 Dense tasks 성능 즉각적 개선
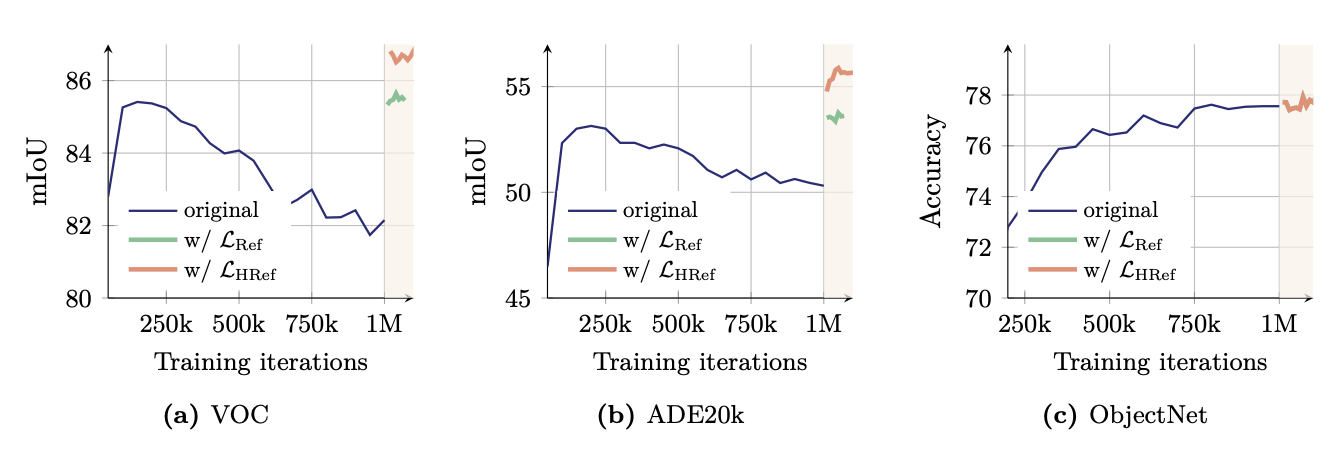
- (a) VOC와 (b) ADE20k의 mIoU는 학습 반복이 250k 이후 감소하지만, Gram anchoring( 또는 )을 적용하면 1M 반복 근처에서 성능이 급격히 회복
- (c) ObjectNet에서는 원래 성능이 유지되거나 약간 개선
- ObjectNet의 특성: ObjectNet은 Global Image 분류 작업으로, CLS token(전체 Image 요약) 기반 성능에 더 의존하며 Patch 수준의 지역적 일관성(Locality)에 덜 민감
4.3. Leveraging Higher-Resolution Features
-
관찰: Patch Feature maps 가중 평균으로 Outlier patches 평활화, Patch-level consistency 강화
- 고해상도 Image 입력으로 더 세밀한 Feature maps 생성
-
Gram teacher 개선
- 방법: Gram teacher에 원래 2배 해상도의 Image를 넣고, 계산된 Feature maps를 Bicubic interpolation으로 다시 2배 작게 줄여(다운샘플링) 사용
- 효과: 다운샘플링 후에도 고해상도 Image에서 얻은 Patch 간 일관성(Patch-level consistency)이 유지되어 더 정밀한 Feature를 학습 (아래 Fig. 9a)
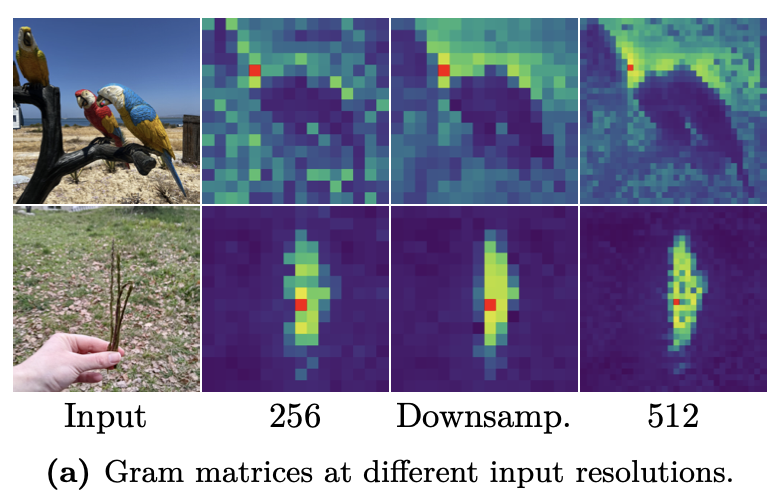
- Rotary Positional Embeddings(RoPE)로 다양한 해상도 Image 처리 가능
-
Refinement objective (LHRef)
- 방법: 다운샘플링된 고해상도 Feature maps의 Gram matrix를 로 사용하고, 이를 기반으로 Loss를 정의해 Student 모델에 적용
- 효과: Student 모델이 고해상도에서 평활화된 Patch 일관성(Patch consistency)을 학습하도록 유도, 더 정밀한 Feature를 전달
-
성능 향상 (아래 Fig. 8, 9b)
- LHRef로 Dense tasks 예측 개선, LRef 대비 추가 이점(예: ADE20k +2 mIoU)
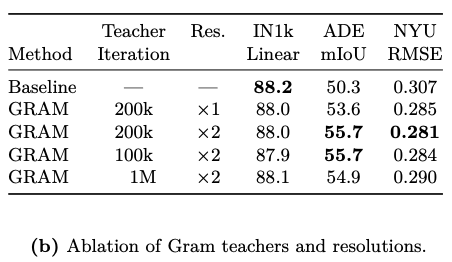
-
학습 초기 100k 또는 200k 반복 시점의 Gram teacher를 사용하면 성능이 비슷하게 잘 나왔지만, 100만 반복 시점의 teacher는 Patch 일관성(Patch-level consistency)이 떨어져 성능이 나빠짐
-
초기 학습 단계(100k~200k)에서 추출한 고품질 Feature가 이후 학습에서 변질되므로, 이를 기준으로 삼는 것이 더 효과적
-
정성적 평가 (아래 Fig. 10)
- 초기 학습과 고해상도 Gram anchoring Refinement의 Gram matrices 시각화

- Feature correlations 크게 개선, 고해상도 Refinement로 Patch-level consistency 향상
5. Post-Training
5.1. Resolution Scaling
- 초기 학습
- 모델은 256 해상도로 학습해 속도와 효율성을 균형 있게 유지하며, DINOv2와 비슷한 입력 길이를 맞춤 -> Patch 크기 16
- 고해상도 적응
- Recent Application들이 512×512 이상의 고해상도 Image를 요구하므로, Mixed resolutions(Global size 512/768, Local size 112~336)을 사용해 10k 반복 추가 학습
- High-resolution adaptation step
- 방법: 다양한 해상도에서 성능을 유지하기 위해 Mixed resolutions를 사용하며, Global size(512, 768)와 Local size(112, 168, 224, 336)를 혼합해 학습
- 과정: 추가로 10,000번 반복 학습을 진행해 모델이 고해상도 Image도 잘 처리하도록 조정
- Gram anchoring 적용
- 7B Teacher를 Gram teacher로 사용
- Gram anchoring 없으면 Dense prediction tasks 성능 크게 저하
- Feature correlations를 공간 위치 간 일관되게 유지, 고해상도 입력 복잡성 처리에 중요
- 결과 (아래 Fig. 11)
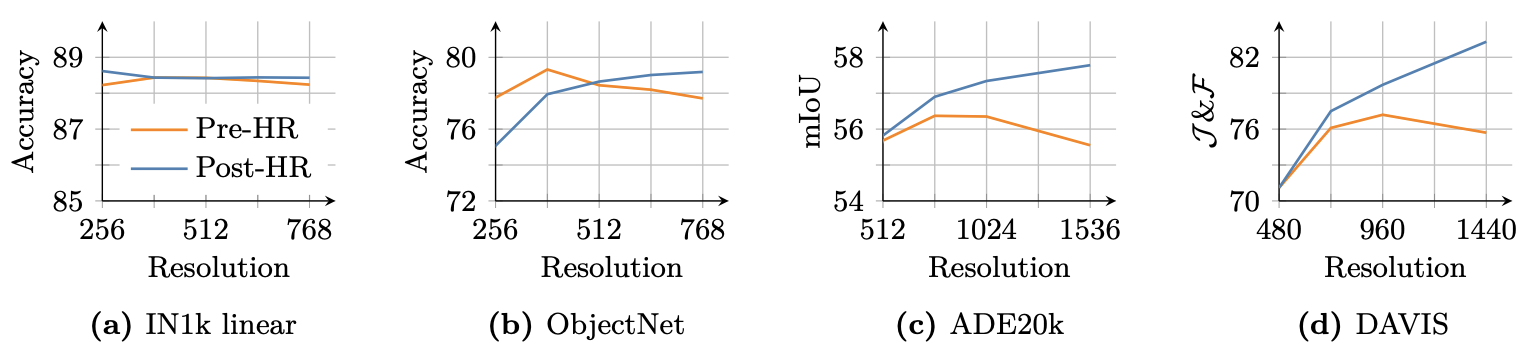
- 효과
- 짧은 고해상도 학습으로 모델 품질이 크게 좋아지고, 다양한 크기의 입력에 잘 적응하며(ImageNet 소폭 향상, ObjectNet 저해상도 약간 감소/고해상도 개선), ADE20k와 DAVIS에서 Local feature 품질이 올라감
- 성능
- 최대 768 해상도를 넘어 4k 이상에서도 안정적인 Feature maps를 제공, 고해상도 작업에 강력
5.2. Model Distillation
-
A Family of Models for Multiple Use-Cases
- 방법
- ViT-7B 모델을 ViT-S(21M), ViT-B(86M), ViT-L(0.3B), ViT-S+(29M), ViT-H+(0.8B)로 Knowledge distillation해 다양한 용도에 맞춘 소형 모델을 생성
- 효과
- 고정된 7B Teacher로 학습해 관리와 효율성을 높이고, 계산량을 줄여 뛰어난 성능(Frontier-level)을 제공하며, 실험과 배포에 유용 (아래 Tab. 14)
- 방법
-
Efficient Multi-Student Distillation
- 대규모 Teacher 추론 비용이 Student보다 훨씬 높음 (아래 Fig. 16a)
-
Parallel distillation pipeline (아래 Fig. 12)
-
다중 Student 동시 학습, 모든 노드에서 Teacher 추론 공유
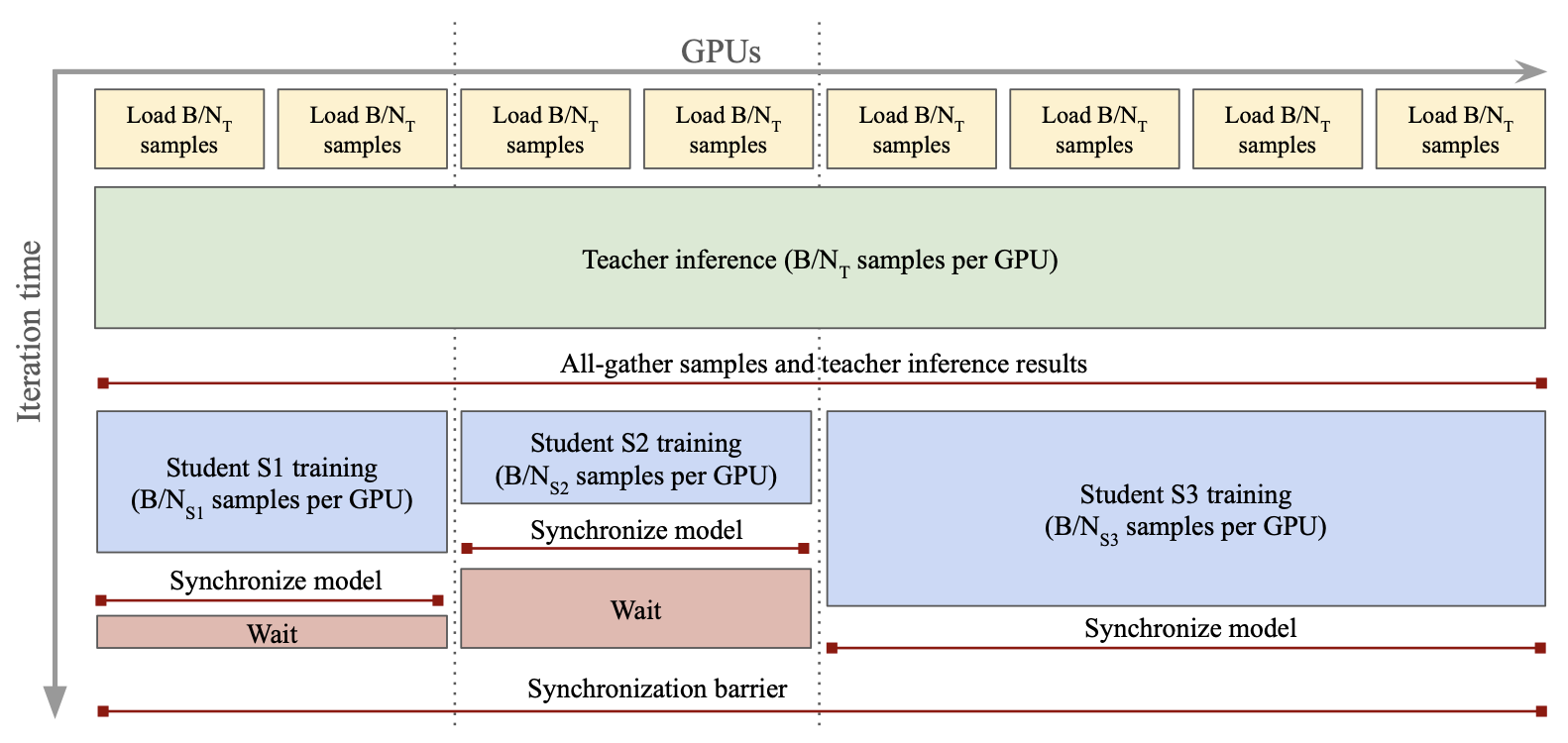
-
방법: Parallel distillation pipeline은 여러 Student 모델을 동시에 학습하며, 모든 GPU 노드에서 Teacher 모델의 추론 결과를 공유하고, 각 Student에 GPU를 할당(B/NT × CT로 Teacher 비용 분산, B/NSi × CSi로 Student 학습)해 계산 효율성을 높임
-
효과: All-gather와 NCCL로 데이터 동기화하고 GPU 수를 조정해 반복 시간을 균일화하며 속도를 극대화, ViT-7B에서 다중 소형 모델을 효율적으로 생성
-
의미: 추가 Student 모델을 더해도 전체 Teacher 추론 비용이 고정되어 자원 활용을 최적화, 실용적인 모델 배포를 지원
-
5.3. Aligning DINOv3 with Text
- Open-vocabulary image-text alignment
- 목표: 유연하고 확장 가능한 다중 모달(Multimodal) 이해를 목표로, Image와 Text를 자유롭게 연결해 다양한 상황에 적용
- 효과와 한계: CLIP은 전체 정렬과 Zero-shot이 뛰어나지만 세부 지역 대응이 약하며, DINOv3는 자율 학습 모델로 정밀한 Text-Image 연관성을 효율적으로 제공
- DINOv3 Text alignment
- 방법: LiT 학습 방식을 따라 고정된 시각 모델(Frozen visual backbone)에 Transformer 2 Layer를 추가하고, Patch Embedding과 CLS token을 평균화해 Text Embedding과 연결
- 과정: Image의 Global과 Local Feature를 Text에 정렬하며, Contrastive objective로 Image와 Caption을 쌍으로 학습, 동일한 데이터 Curation으로 일관성 유지
- 효과: Dense 작업(예: Segmentation) 성능을 높이고, 비교 가능성을 보장하며 정밀한 Image-Text 매칭 제공
- LiT ?
- Image와 Text를 함께 학습시키는 방법으로, DINOv3에서 시각 모델과 Text Encoder를 결합해 Image-Text 정렬을 개선
- 고정된 시각 모델(Frozen visual backbone)을 기반으로 Text를 학습시켜 효율적이며, 다중 모달(Multimodal) 이해를 강화
6. Results
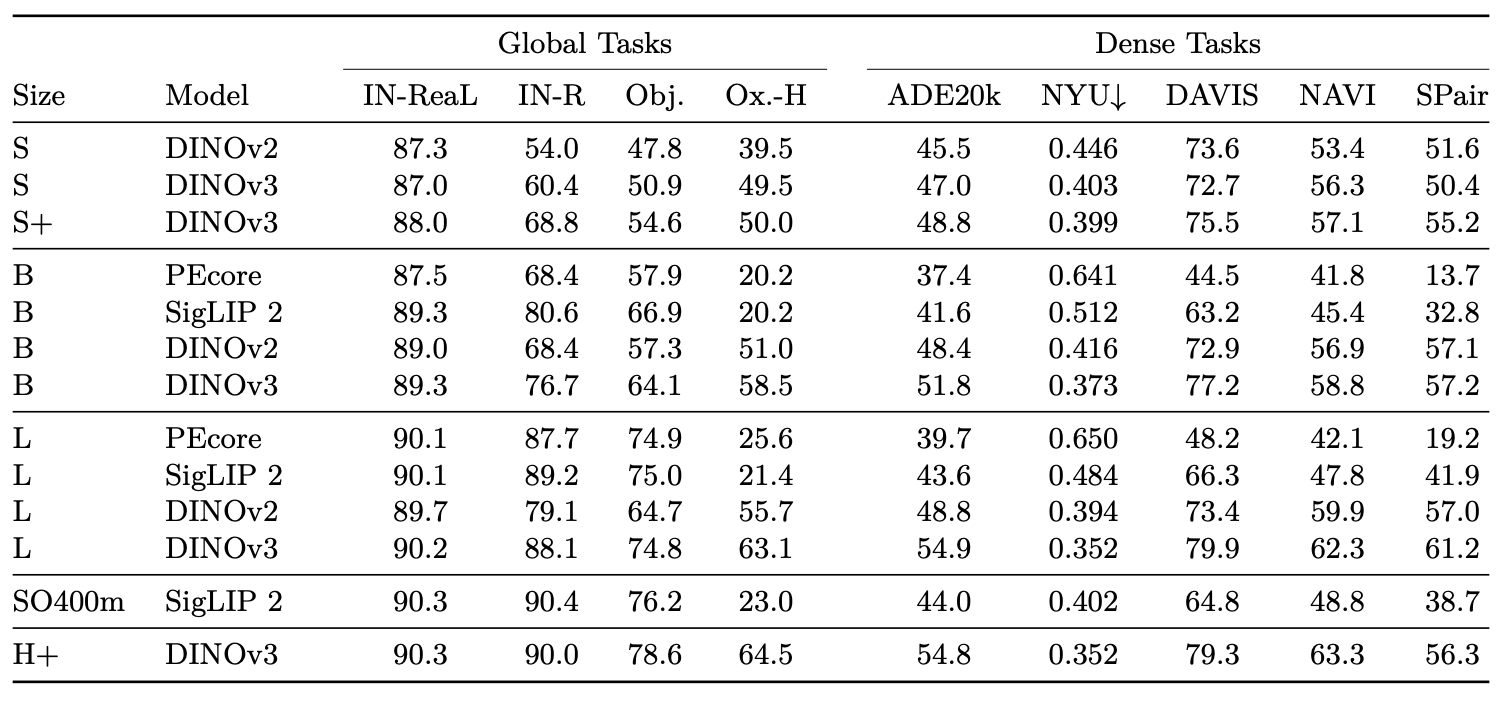
6.1. DINOv3 provides Exceptional Dense Features
- DINOv3 7B 모델을 다양한 Computer vision 작업에서 평가, 특별히 명시되지 않으면 Frozen representations 사용
- Finetuning 없이 강력한 성능 확인
- 평가 구조
- Dense 및 Global image representations 품질 조사 (Sec. 6.1, 6.2)
- DINOv3 기반 복잡한 Computer vision 시스템 개발 (Sec. 6.3)
- Baselines: Weakly-supervised (Perception Encoder Core, SigLIP 2), Self-supervised (DINOv2 with registers, Web-DINO, Franca), Agglomerative models (AM-RADIOv2.5, DFN, SAM, PEspatial)
6.1.1. Qualitative Analysis
-
Dense Feature maps를 PCA로 3차원 투영, RGB 매핑 (아래 Fig. 13)
- PCA의 부호 모호성과 주성분-색상 매핑 탐색, 가장 시각적으로 설득력 있는 결과 보고

- PCA의 부호 모호성과 주성분-색상 매핑 탐색, 가장 시각적으로 설득력 있는 결과 보고
-
DINOv3 Feature maps: 다른 Vision 백본 대비 선명, 노이즈 적고 우수한 Semantic coherence
6.1.2 Dense Linear Probing
- Frozen Patch Feature maps에 Linear transform 학습
- Fine-tuning 없이 Pre-training된 Encoder의 Frozen Feature maps에 간단한 Linear layer만 학습시켜 성능을 평가
- Decoder는 복잡한 네트워크가 아닌 Linear transform
- Semantic segmentation: ADE20k, Cityscapes, PASCAL VOC 2012, mIoU 보고 (Tab. 3)
- DINOv3
- Self-supervised baselines 대비 6 mIoU 이상 우수
- Weakly-supervised baselines 대비 13 포인트 이상 우수
- PEspatial 대비 6 포인트, AM-RADIOv2.5 대비 3 포인트 우수
- Cityscapes
- mIoU 81.1로 AM-RADIOv2.5 대비 2.5 포인트, 기타 백본 대비 5.5 포인트 우수
- DINOv3
- Monocular depth estimation: NYU, KITTI
- DINOv3: 모든 모델 큰 차이로 앞섬, DINOv2 대비 KITTI에서 0.278 RMSE 개선
- 결론
- DINOv3의 Dense Feature maps는 객체 카테고리, 마스크, 상대적 깊이를 선형적으로 잘 구분하며 뛰어난 표현력(Representational power)을 보여줌
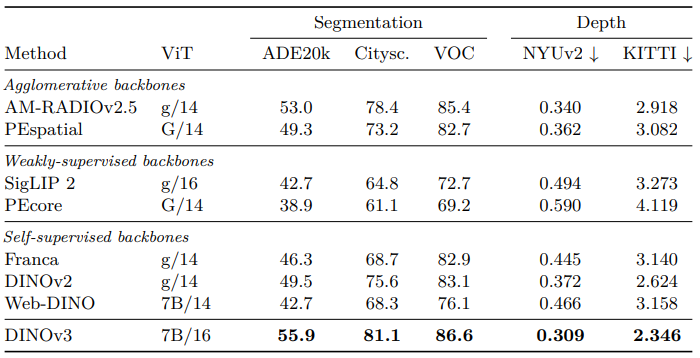
- DINOv3의 Dense Feature maps는 객체 카테고리, 마스크, 상대적 깊이를 선형적으로 잘 구분하며 뛰어난 표현력(Representational power)을 보여줌
6.2 DINOv3 has Robust and Versatile Global Image Descriptors
6.2.1. Image Classification with Linear Probing
-
DINOv3의 CLS token에 Linear classifier 학습, Classification benchmarks 평가
-
데이터셋
- ImageNet-V2, ReaL: Overfitting 테스트
- Rendition, Sketch: Stylized/Artificial Image
- Adversarial, ObjectNet: 어려운 예제
- Corruptions: Image 손상 Robustness 테스트
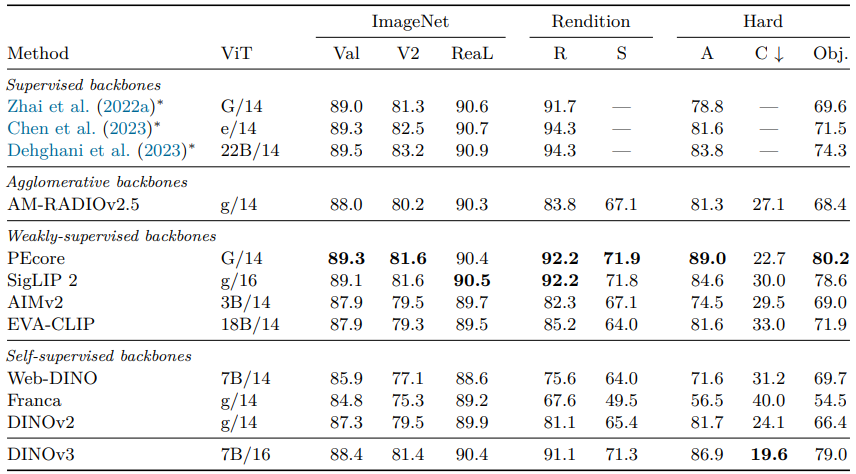
- 결과
- DINOv2 대비 ImageNet-R(+10%), Sketch(+6%), ObjectNet(+13%) 개선
- Weakly-supervised 모델(SigLIP 2, PE)과 비교: ImageNet-A, ObjectNet에서 ViT-22B 앞섬, PE에 근소 뒤짐, SigLIPv2 앞섬
- ImageNet validation 점수는 SigLIPv2, PE보다 0.7-0.9 포인트 낮음, 하지만 ImageNet-V2, ReaL에서 유사
- ImageNet-C에서 최고 Robustness 달성
- SSL 모델로 Weakly-supervised/Supervised 모델과 동등한 성능, 순수 Image 학습으로 확장 가능성 입증
-
Fine-grained Classification
- 데이터셋: Places205 (장면 인식), iNaturalist 2018/2021 (식물/동물 종 인식), 12개 소규모 데이터셋 평균 (Fine-S)
- 결과: DINOv3는 iNaturalist21에서 89.8%로 PEcore(87.0%)를 앞섬, Weakly-supervised 방법들과 경쟁력 있는 성능 보여줌
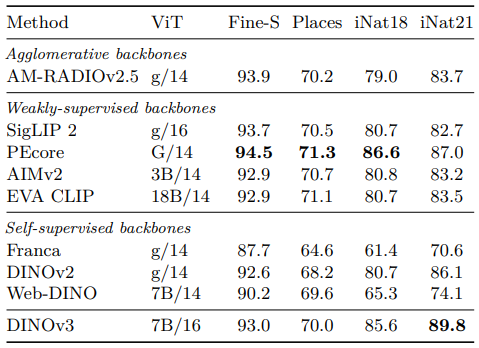
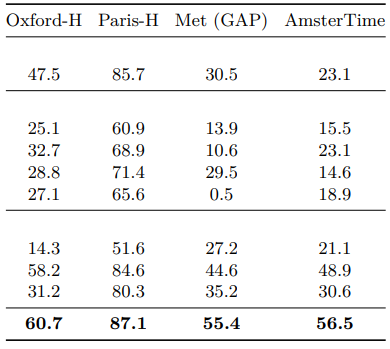
6.2.2. Instance Recognition
- Non-parametric retrieval: CLS token의 Cosine similarity로 데이터베이스 Image 순위 매김
- 데이터셋
- Oxford, Paris: Landmark recognition
- Met: Metropolitan Museum 예술품
- AmsterTime: 암스테르담 현대/역사적 거리 Image
- 지표: Oxford, Paris, AmsterTime은 mAP, Met은 Global average precision
- 결과
- DINOv3: Met(+10.8 포인트), AmsterTime(+7.6 포인트)에서 DINOv2 큰 차이로 앞섬
- Weakly-supervised models 뒤처짐, AM-RADIO(DINOv2 Distillation) 예외
- Landmark 및 예술/역사적 Image Retrieval에서 Robustness와 Versatility 입증
6.3. DINOv3 is a Foundation for Complex Computer Vision Systems
- 경량 Linear adapters/Non-parametric algorithms로 Feature maps 품질 평가, DINOv3의 전체 잠재력 평가 부족
- 복잡한 다운스트림 Decoder 학습, 작업별 강력한 Baseline 비교
- 탐구 작업
- Object detection (Plain-DETR)
- Semantic segmentation (Mask2Former)
- Monocular depth estimation (Depth Anything)
- 3D understanding (Visual Geometry Grounded Transformer)
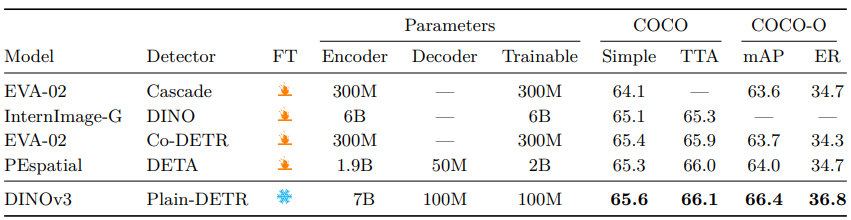
6.3.1. Object Detection
- 목표: Image에서 사전 정의된 카테고리 객체의 Bounding boxes 제공, 정밀 Localization과 Recognition 필요
- 데이터셋 및 지표
- COCO-VAL2017, COCO-O(6개 Distribution shift 설정)
- mAP(IoU [0.5:0.05:0.95]), COCO-O는 Effective robustness(ER)
- COCO(118k Image) 보완 위해 Objects365 Pre-training
- 구현: Plain-DETR 기반, Transformer encoder 별도 모듈로 유지, DINOv3 Frozen backbone
- Objects365에서 22 에포크(해상도 1536), 1 에포크(2048), COCO에서 12 에포크(2048)
- 추론 시 해상도 2048, 선택적 TTA(1536-2880)
- 결과 (Tab. 10)
- 경량 Detector(100M Parameter)로 SOTA 성능
- COCO-O에서 Robustness 활용, 기존 모델(300M 이상 Parameter) 앞섬
- Frozen backbone으로 다중 작업 지원, 계산 요구량 감소
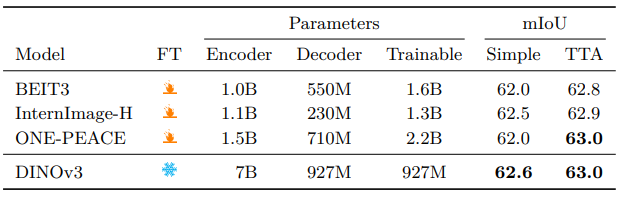
6.3.2. Semantic Segmentation
- 목표: Per-pixel prediction, 객체 인스턴스 구분 불필요
- 데이터셋 및 지표
- ADE20k(150 카테고리, 20k 학습/2k 검증), mIoU
- COCO-Stuff(164k, 171 카테고리), Hypersim(77k, 40 카테고리) Pre-training
- 구현
- ViT-Adapter와 Mask2Former 결합, DINOv3 Frozen backbone
- Injector 제거, Embedding dimensions 1024→2048
- COCO-Stuff 80k, Hypersim 10k, ADE20k 20k 반복 학습, 해상도 896
- 추론: Single-scale(학습 해상도) 또는 Multi-scale(×0.9-1.1)
- 결과 (Tab. 11, 24)
- ONE-PEACE와 동등 SOTA(63.0 mIoU), COCO-Stuff, VOC 2012에서 기존 모델 앞섬
- ViT의 16 Pixel Patch로 인한 Coarse granularity, 고해상도 Feature maps(4096, 512 토큰)로 향후 무거운 Decoder 불필요 예상
7. Evaluating the Full Family of DINOv3 Models
7.1. A Vision Transformer for Every Use Case
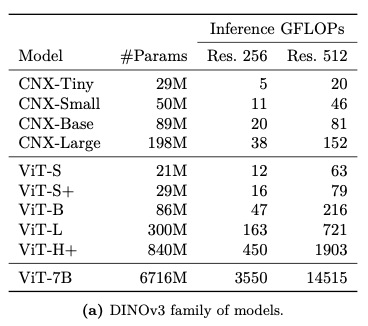
- DINOv3 ViT family: ViT-S(소형, 자원 제약 장치용)부터 ViT-H+(840M Parameter, 고성능 응용)까지
- 비교 대상: DINOv2, SigLIP 2, Perception Encoder
- 공정한 비교 위해 Patch 크기 16은 512×512, Patch 크기 14는 448×448 입력
- Dense prediction tasks
- ADE20k: ViT-L, DINOv2 대비 6 mIoU 이상 개선, ViT-B 3 mIoU 개선
- Depth estimation: 경쟁 모델 대비 일관된 성능 향상
- DINOv3의 Local Feature maps, Fine-grained spatial details 포착에 탁월
- Global recognition benchmarks
- ObjectNet, ImageNet-1k에서 경쟁력 있는 성능
- Dense task 성능 향상이 Global task 정확도 손실 없이 달성
- Distillation 효과
- ViT-H+와 ViT-7B 비교 (Fig. 16b), 8배 작은 모델이 유사 성능
- 고품질 Teacher로 소형 모델이 동등 성능 달성, 대규모 모델 학습의 가치 입증
- 결론: DINOv3 ViT, Dense 및 Global vision tasks 모두에서 균형 잡힌 Robust solution
7.2. Efficient ConvNeXts for Resource-Constrained Environments
- DINOv3 ConvNeXt(CNX): ViT-7B에서 Distillation, T/S/B/L 크기
- FLOPs 효율적, Convolutional computations 최적화 장치 적합
- Transformer 대비 Quantization 용이
- 비교 대상: Supervised ConvNeXt(ImageNet-22k)
- 결과 (Tab. 15)
- In-distribution classification(256 해상도): CNX-T -0.7 IN-ReAL로 Supervised 모델에 약간 뒤짐
- 512 해상도: Supervised ConvNeXt 성능 저하, DINOv3 CNX는 입력 해상도 증가로 성능 향상
- OOD classification(IN-R, ObjectNet): 모든 크기에서 큰 격차, DINOv3 CNX Robustness 우수
- Dense tasks: CNX-T +17.9 mIoU(42.7 vs 24.8), CNX-L +14.5 mIoU(47.8 vs 33.3)
- 의의
- 자원 제약 환경에서 고성능과 효율성 결합
- ViT-7B(CLS token 기반 Transformer)에서 ConvNeXt(Convolutional, CLS token 없음)로의 Non-trivial Distillation 성공
7.3. Zero-shot Inference with DINOv3-based dino.txt
- Text alignment: ViT-L의 CLS token 및 Patch Feature maps를 Text encoder와 정렬 (dino.txt)
- 평가
- Global alignment: CLIP 프로토콜로 ImageNet-1k, ImageNet-Adversarial, ImageNet-Rendition, ObjectNet에서 Zero-shot classification accuracy
- Image-text retrieval: COCO2017, Recall@1(I→T, T→I)
- Patch-level alignment: ADE20k, Cityscapes에서 Open-vocabulary segmentation, mIoU
- 결과 (Tab. 16)
- DINOv2 대비 모든 벤치마크에서 큰 성능 향상
- Global alignment: CLIP, EVA-02-CLIP 앞섬, SigLIP2, Perception Encoder 약간 뒤짐
- Dense alignment: DINOv3의 Clean Feature maps로 ADE20k, Cityscapes에서 우수한 성능
10. Conclusion
- DINOv3: Self-supervised learning 분야에서 중대한 발전, 다양한 도메인에서 Visual representations 학습 방식 혁신
- 신중한 Data preparation, 설계, 최적화를 통해 데이터셋과 모델 크기 스케일링
- Self-supervised learning: 수동 주석 의존성 제거
- Gram anchoring method: 장기 학습 중 Dense Feature maps 저하 완화, Robust 및 Reliable performance 보장
- Post-hoc polishing strategies
- High-resolution post-training 및 Distillation 구현
- Image encoder Finetuning 없이 다양한 Visual tasks에서 SOTA 성능 달성
- DINOv3 suite: 새로운 벤치마크 설정, 자원 제약, 배포 시나리오, 응용 사례에 걸쳐 Versatile solution 제공
- Computer vision 및 그 이상에서 SOTA 발전을 위한 Self-supervised learning의 잠재력 입증
