https://arxiv.org/abs/2303.13496
ICCV 2023
Abstract
- 이 논문은 컴퓨터 비전에서 시각 인식 작업에 사용되는 standard pretrain-then-finetune paradigm을 재검토
- 모델을 초기화하는 간단한 Self-supervised MAE 방법을 사용하는 추가적인 pre-pretraining 단계를 도입
- MAE를 기반으로 한 pre-pretraining은 모델 및 데이터 크기 모두에 확장 가능하며, foundation 모델 학습에 적용할 수 있음
- pre-pretraining은 다양한 모델 규모, 데이터셋 크기 범위에 걸쳐 모델 수렴 및 downstream transfer 성능을 일관되게 향상
- image classification, video recognition, object detection, low-shot classification 및 zero-shot recognition을 포함하는 10가지 다양한 시각 인식 작업에서 평가
- 수십억 개의 이미지로 pretraining을 진행할 때에도 모델 초기화가 중요한 역할을 한다는 것을 밝혀냅
1. Introduction
-
시각 인식(visual recognition)에서의 pretrain-then-finetune paradigm은 image classification, video recognition, object detection, low-shot classification 및 zero-shot recognition과 같은
다양한 작업 범위에서 고성능 시각 인식 모델을 가능하게 함 -
본 논문에서는 standard pretraining 작업 이전에 pre-pretraining 초기 단계를 수행함으로써 다양한 다른 작업에서 시각 모델의 성능을 향상시킬 수 있다는 것을 보여줌
-
다음과 같은 두 가지 일반적인 pre-pretraining 작업을 결합
- weakly supervised pretraining: 텍스트나 이미지 해시태그와 같은 약한, 종종 noisy signal를 감독으로 사용
- self-supervised pretraining: 추가적인 감독 없이 데이터만 사용
-
두 형태의 pre-pretraining 모두 무작위로 초기화된 모델로 학습을 시작하며, 일반적인 목적의 시각 모델을 학습하는 데 효과적임이 입증
-
이 논문에서는 self-and weakly-supervised learning의 조합을 간단한 pre-pretraining framework에서 탐구
- 1> MAE를 이용해 self-supervised learning 진행
- 2> 이후 weakly-supervised learning를 진행
-
대규모 Pre-pretraining 연구는 모델 초기화가 웹 스케일 pre-training에서도 중요한 역할을 한다는 것을 밝혀냄
-
특히 다음과 같은 사실들을 보여줌
- (i) MAE는 모델 크기와 함께 확장되는 것뿐만 아니라 학습 데이터의 크기와도 확장
- (ii) Pre-pretraining은 크기가 다른 모델과 크기가 다른 데이터셋에 대해 모델 수렴과 downstream 성능을 모두 향상
- (iii) Pre-pretraining을 사용함으로써 Self-supervised learning과 대규모 weakly supervised learning의 이점을 결합하며, 다양한 시각 인식 작업에서 우수한 성능을 달성
2. Related Work
Supervised pretraining
- 대규모 레이블이 지정된 데이터셋에서 transferrable representation을 supervised pretraining하고 이를 downstream 작업에 활용하는 것은 컴퓨터 비전 분야에서 강력한 접근 방식으로 등장
- 그러나 이러한 representation은 종종 pretraining 데이터셋의 감독의 규모와 다양성에 제한을 받음
Self-supervised pretraining
- Self-supervised pretraining은 크기가 크고 잘 레이블된 데이터셋에 의존하지 않고 이러한 representation을 학습하는 유망한 대안
- Pretraining 중에 supervision이 부족하기 때문에 이러한 representation은 종종 downstream 작업과 일치시키기 위해 중요한 미세 조정이 필요
Weakly supervised pretraining (WSP)
- WSP는 supervised 및 self-supervised pretraining 사이의 중간 지점
- self-supervised pretraining과 같이 annotation을 완전히 무시하거나, supervised pretraining과 같이 철저한 레이블이 필요하지 않습
- 대신 WSP는 인터넷에서 사용 가능한 "free" annotation의 큰 양에 의존
- Noisy 레이블에 대한 다중 레이블 분류를 활용하는 접근 방식으로, SOTA 미세 조정 성능을 보이며 이미지-텍스트 데이터를 사용하여 zero-shot 능력을 획득할 수 있음
3. Setup
- 이 논문의 목표는 representation learning을 위한 pre-pretraining의 선행 조건으로서의 self-supervised pre-pretraining의 효과를 경험적으로 연구하는 것
Architecure
- 모든 실험에서 visual encoder로서 Vision Transformer (ViT)를 사용
- 매개변수 수에 따라 다양한 크기의 ViT 모델을 훈련합니다. 이에는 ViT-B (86M), ViT-L (307M), ViT-H (632M)가 포함
- 모든 모델에 대해 224 × 224 해상도로 pretraining을 진행
Pre-pretraining (MAE)
- MAE는 레이블을 사용하지 않고 이미지 데이터셋에서 visual representation을 학습하는데 사용되며, 다음과 같은 이유로 이 접근 방식을 선택
- 구현이 간단하며 대규모 ViT 모델 크기에 대해 패치 드롭을 통해 매우 효과적으로 확장
- 이미지의 75%를 무작위로 마스킹하고 모델이 마스킹된 입력 이미지를 최소화하여 재구성하도록 학습시켜 픽셀 재구성 오류(pixel reconstruction error)를 최소화
- 주어진 패치의 target 픽셀 값은 해당 패치 내 모든 픽셀의 평균과 표준 편차로 정규화
- ViT와 결합되면 MAE는 25%만 마스크 해제된 이미지 패치를 처리함으로써 학습할 수 있음
- 그런 다음 입력의 누락된 부분을 재구성하기 위해 별도로 작은 decoder가 사용
- 이러한 비대칭적인 디자인은 인코더의 학습을 매우 효율적으로 만들어 visual encoder 크기를 확장할 수 있게 함
Weakly-supervised pretraining (WSP)
- 모델을 학습시키기 위해 연관된 'weak' supervision이 있는 이미지를 활용
- 특히, 인터넷 이미지에 중점을 두고 그들과 연관된 텍스트 정보를 supervision 정보로 사용
- 텍스트 해시태그 정보를 활용하여 이산적(discrete)인 레이블 집합으로 변환
- 그런 다음, 다중 레이블 분류 loss을 사용하여 모델을 학습
MAE → WSP
- 첫 번째 단계에서는 이미지만 사용하여 MAE self-supervised learning을 사용하여 encoder를 먼저 학습
- 이러한 pre-pretraining 단계는 MAE에서 사용되는 마스킹 때문에 계산 효율성을 동시에 초기화
- 두 번째 단계에서는 이미지와 관련된 weak-supervision를 함께 사용하여 encoder를 pretraining
- 이 조합은 단독으로 사용하는 것보다 성능이 우수하며, 즉, MAE 모델 또는 처음부터 학습시킨 weakly-supervised 모델을 사용하는 것보다 성능이 더 뛰어남
4. Experiments
4.1. Datasets and training details
Pretraining dataset
- Instagram-3B (IG-3B)라는 Instagram 출처의 억 단위 다중 레이블 데이터 세트를 사용
- 28,000개의 클래스와 30억 개의 고유 이미지가 포함
- 레이블을 얻는 과정은 자동화된 프로세스를 통해 이루어짐
- 먼저, 관련 이미지 캡션에서 해시태그를 얻은 다음, 이 해시태그를를 따라 WordNet 동의어 집합으로 매핑
- 이 처리 후, 이미지와 해당 레이블이 포함된 weak 레이블 IG 데이터 세트를 얻게 됩
Evaluation datasets
- MAE → WSP 모델을 다양한 downstream 시각 인식 task에서 평가
- image classification: ImageNet-1k, iNaturalist-18
- object detection and segmentation: COCO, LVIS
- video classification: Kinetics-400, Something Something-v2
- zero-shot transfer: ImageNet-1k, Food-101
MAE pretraining details
- IG-3B 데이터에서 어떤 레이블도 사용하지 않고 MAE 모델을 학습
- 이미지의 75%를 마스크하고 데이터셋 전체에 대해 1 epoch 동안 모델을 학습
Supervised pretraining details
- IG-3B 데이터에서 해시태그를 레이블로 사용하여 supervised cross-entropy loss을 사용하여 모델을 학습
Using pre-pretraining
- 먼저 IG 데이터셋을 사용하여 MAE를 통해 모델을 처음부터 학습
- 그런 다음 MAE 인코더의 가중치를 사용하고 위에서 설명한 대로 supervised pretraining을 수행
- MAE → WSP에 대해 하이퍼파라미터 검색이 필요하지 않으므로 동일한 하이퍼파라미터 재사용
- 즉, IG-3B에서 1 epoch 동안 학습
Zero-shot training and evaluation details
- Zero-shot understanding capabilities을 부여하기 위해 LiT(Language-Image Transformer) 접근 방식을 사용
- LiT를 위해 IG-3B 데이터셋의 원본 (이미지, 캡션) 쌍을 사용
- 이미지 인코더를 freeze하고, 텍스트 인코더를 훈련하여 이미지 캡션을 인코딩
- CLIP loss를 사용하여 텍스트 임베딩을 연결된 이미지 임베딩과 일치시킴
4.2. Scaling MAE pretraining to large data
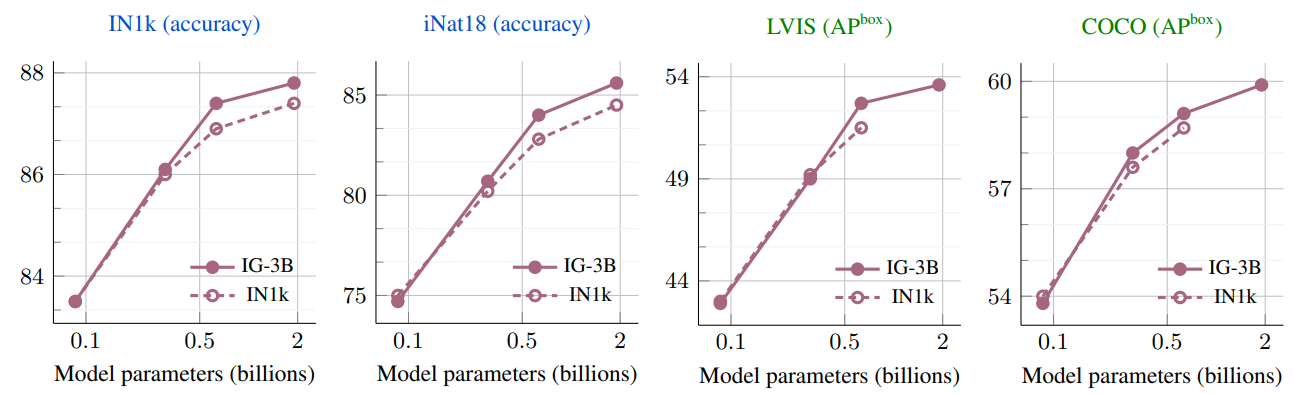
- 위 그림은 pretrained MAE의 성능을 downstream task에서 미세조정한 결과
- 훨씬 큰 IG-3B 데이터셋으로 pretraining한 경우 더 큰 모델이 더 나은 결과를 보임
- Pre-pretraining이 첫 번째 단계에서 MAE를 사용하기 때문에, 먼저 MAE가 대규모 IG-3B 데이터셋에서 어떻게 작동하는지 연구
- IG-3B 데이터를 사용하면 모든 vision task에서 IN1k 대비 일관된 개선을 제공하며, 모델이 커질수록 이득이 증가하는 것을 관찰
- IG-3B에서 pretrained ViT-2B 모델은 이미지 분류에서 최고 결과를 개선하며, 518×518 해상도에서 IN1k에서 88.4% (+0.6%)와 iNat18에서 89.3% (+2.5%)를 달성
- setting의 간결함을 강조하며, IG-3B에서 MAE를 학습할 때와 가장 큰 ViT-2B 모델에서도 동일한 하이퍼파라미터를 사용
- 어떠한 학습 불안정성도 경험하지 않거나 추가적인 조정이 필요하지 않음
4.3. MAE pre-pretraining
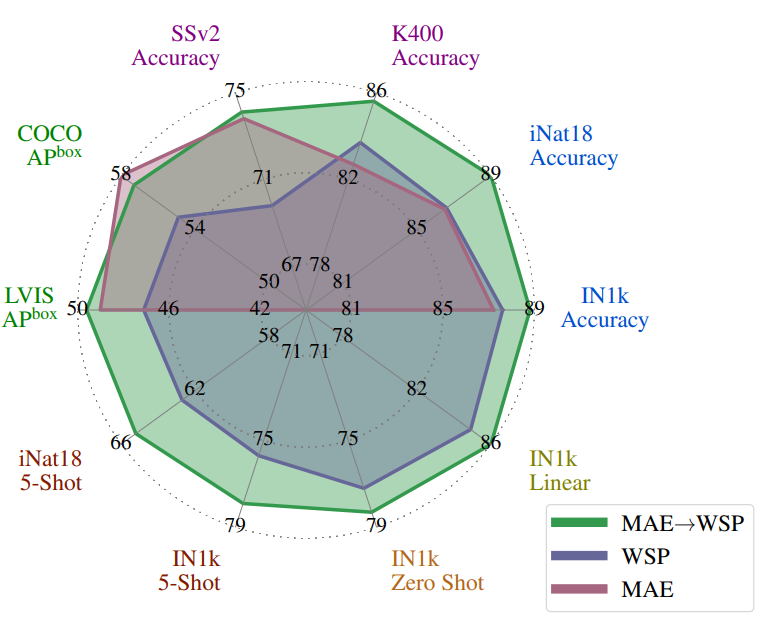
- 위 그림에서 처럼, MAE는 detection 및 완전한 미세조정 image classification와 같은 작업에서 강력한 성능을 보임
- 그러나 모델이 미세조정되지 않는 경우, 예를 들어 선형 분류기, zero-shot 또는 low-shot 분류와 같은 경우에는 MAE가 성능이 떨어짐

AI Research Engineer